 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Object Generation with Reversible Inductive Construction
Jul 18, 2019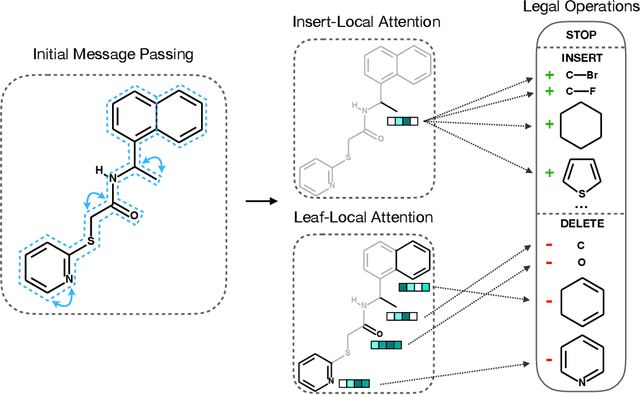
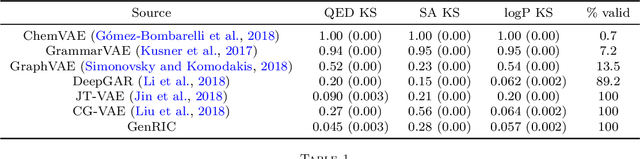

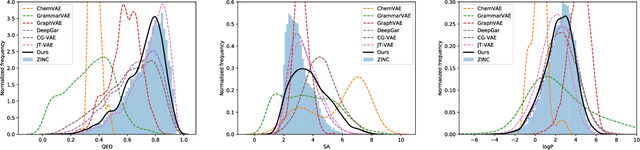
The success of generative modeling in continuous domains has led to a surge of interest in generating discrete data such as molecules, source code, and graphs. However, construction histories for these discrete objects are typically not unique and so generative models must reason about intractably large spaces in order to learn. Additionally, structured discrete domains are often characterized by strict constraints on what constitutes a valid object and generative models must respect these requirements in order to produce useful novel samples. Here, we present a generative model for discrete objects employing a Markov chain where transitions are restricted to a set of local operations that preserve validity. Building off of generative interpretations of denoising autoencoders, the Markov chain alternates between producing 1) a sequence of corrupted objects that are valid but not from the data distribution, and 2) a learned reconstruction distribution that attempts to fix the corruptions while also preserving validity. This approach constrains the generative model to only produce valid objects, requires the learner to only discover local modifications to the objects, and avoids marginalization over an unknown and potentially large space of construction histories. We evaluate the proposed approach on two highly structured discrete domains, molecules and Laman graphs, and find that it compares favorably to alternative methods at capturing distributional statistics for a host of semantically relevant metrics.
A Theoretical Connection Between Statistical Physics and Reinforcement Learning
Jun 24, 2019
Sequential decision making in the presence of uncertainty and stochastic dynamics gives rise to distributions over state/action trajectories in reinforcement learning (RL) and optimal control problems. This observation has led to a variety of connections between RL and inference in probabilistic graphical models (PGMs). Here we explore a different dimension to this relationship, examining reinforcement learning using the tools and abstractions of statistical physics. The central object in the statistical physics abstraction is the idea of a partition function $\mathcal{Z}$, and here we construct a partition function from the ensemble of possible trajectories that an agent might take in a Markov decision process. Although value functions and $Q$-functions can be derived from this partition function and interpreted via average energies, the $\mathcal{Z}$-function provides an object with its own Bellman equation that can form the basis of alternative dynamic programming approaches. Moreover, when the MDP dynamics are deterministic, the Bellman equation for $\mathcal{Z}$ is linear, allowing direct solutions that are unavailable for the nonlinear equations associated with traditional value functions. The policies learned via these $\mathcal{Z}$-based Bellman updates are tightly linked to Boltzmann-like policy parameterizations. In addition to sampling actions proportionally to the exponential of the expected cumulative reward as Boltzmann policies would, these policies take entropy into account favoring states from which many outcomes are possible.
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
May 28, 2019
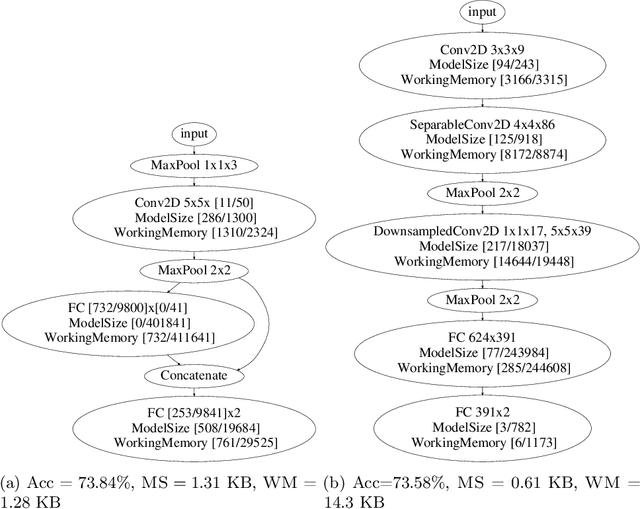
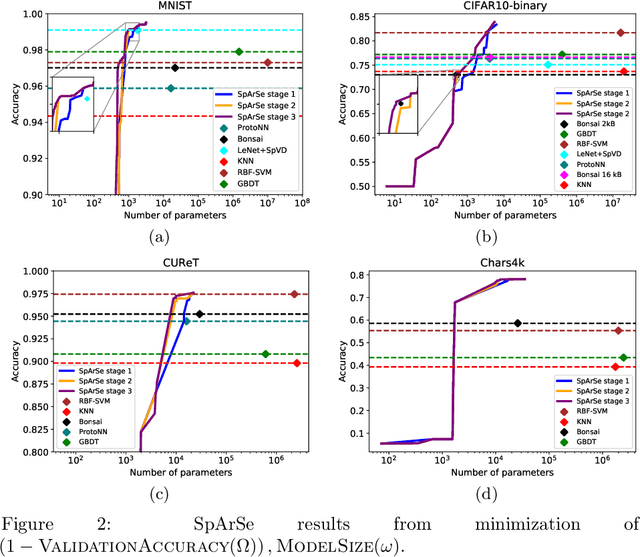
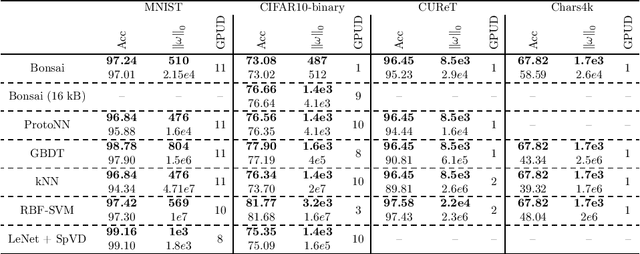
The vast majority of processors in the world are actually microcontroller units (MCUs), which find widespread use performing simple control tasks in applications ranging from automobiles to medical devices and office equipment. The Internet of Things (IoT) promises to inject machine learning into many of these every-day objects via tiny, cheap MCUs. However, these resource-impoverished hardware platforms severely limit the complexity of machine learning models that can be deployed. For example, although convolutional neural networks (CNNs) achieve state-of-the-art results on many visual recognition tasks, CNN inference on MCUs is challenging due to severe finite memory limitations. To circumvent the memory challenge associated with CNNs, various alternatives have been proposed that do fit within the memory budget of an MCU, albeit at the cost of prediction accuracy. This paper challenges the idea that CNNs are not suitable for deployment on MCUs. We demonstrate that it is possible to automatically design CNNs which generalize well, while also being small enough to fit onto memory-limited MCUs. Our Sparse Architecture Search method combines neural architecture search with pruning in a single, unified approach, which learns superior models on four popular IoT datasets. The CNNs we find are more accurate and up to $4.35\times$ smaller than previous approaches, while meeting the strict MCU working memory constraint.
Efficient Optimization of Loops and Limits with Randomized Telescoping Sums
May 16, 2019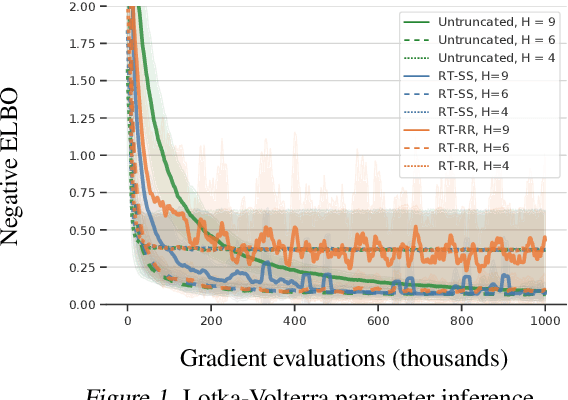
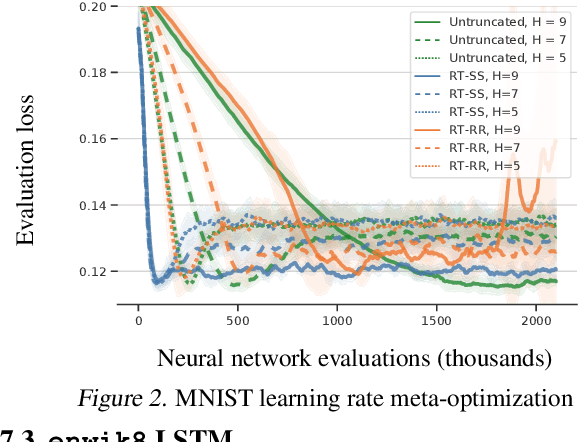
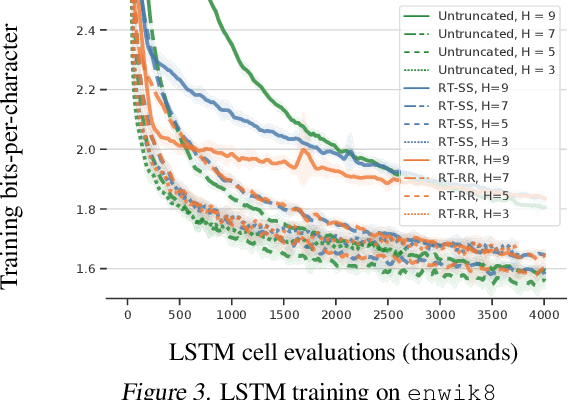
We consider optimization problems in which the objective requires an inner loop with many steps or is the limit of a sequence of increasingly costly approximations. Meta-learning, training recurrent neural networks, and optimization of the solutions to differential equations are all examples of optimization problems with this character. In such problems, it can be expensive to compute the objective function value and its gradient, but truncating the loop or using less accurate approximations can induce biases that damage the overall solution. We propose randomized telescope (RT) gradient estimators, which represent the objective as the sum of a telescoping series and sample linear combinations of terms to provide cheap unbiased gradient estimates. We identify conditions under which RT estimators achieve optimization convergence rates independent of the length of the loop or the required accuracy of the approximation. We also derive a method for tuning RT estimators online to maximize a lower bound on the expected decrease in loss per unit of computation. We evaluate our adaptive RT estimators on a range of applications including meta-optimization of learning rates, variational inference of ODE parameters, and training an LSTM to model long sequences.
Predicting Electron-Ionization Mass Spectrometry using Neural Networks
Nov 21, 2018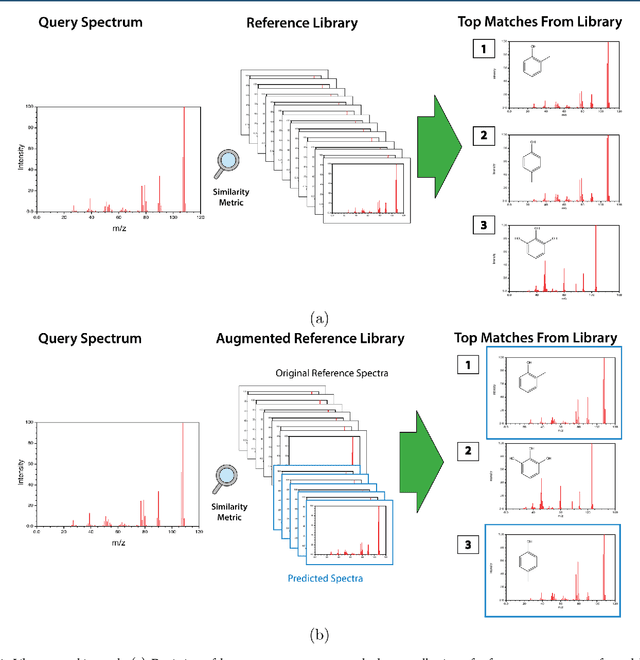
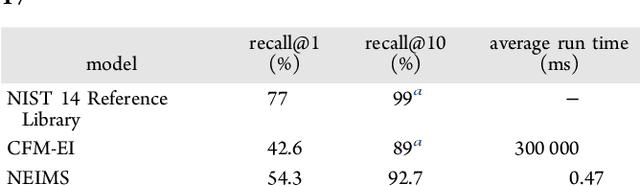
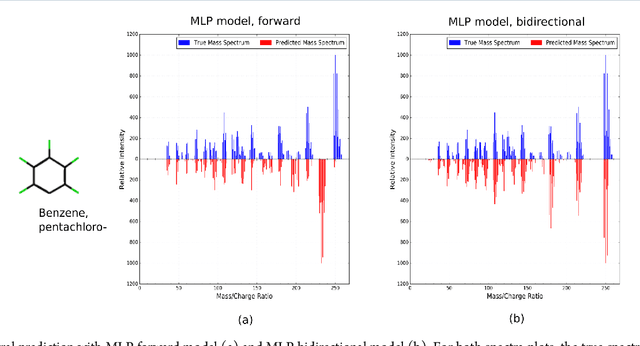
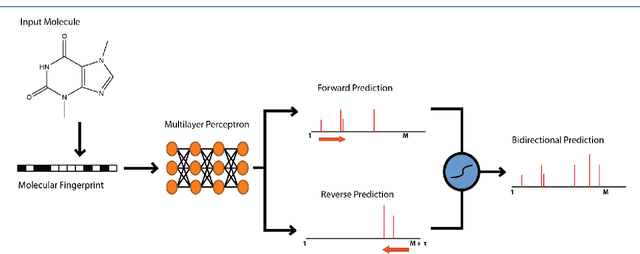
When confronted with a substance of unknown identity, researchers often perform mass spectrometry on the sample and compare the observed spectrum to a library of previously-collected spectra to identify the molecule. While popular, this approach will fail to identify molecules that are not in the existing library. In response, we propose to improve the library's coverage by augmenting it with synthetic spectra that are predicted using machine learning. We contribute a lightweight neural network model that quickly predicts mass spectra for small molecules. Achieving high accuracy predictions requires a novel neural network architecture that is designed to capture typical fragmentation patterns from electron ionization. We analyze the effects of our modeling innovations on library matching performance and compare our models to prior machine learning-based work on spectrum prediction.
Approximate Inference for Constructing Astronomical Catalogs from Images
Oct 12, 2018

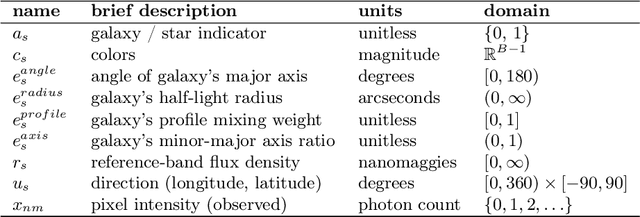
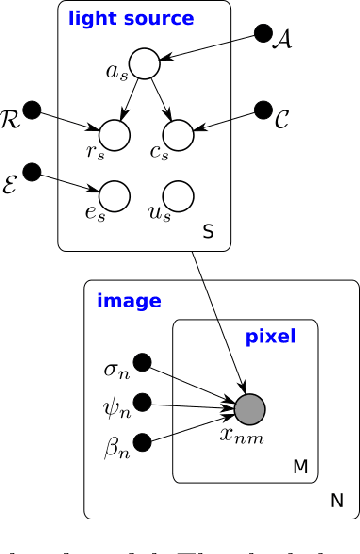
We present a new, fully generative model for constructing astronomical catalogs from optical telescope image sets. Each pixel intensity is treated as a Poisson random variable with a rate parameter that depends on the latent properties of stars and galaxies. These latent properties are themselves random, with prior distributions fitted by empirical Bayes. We compare two procedures for posterior inference. One procedure is based on Markov chain Monte Carlo (MCMC) while the other is based on variational inference (VI). We demonstrate that the MCMC procedure excels at quantifying uncertainty while the VI procedure is 1000x faster. For the error metric we consider, both procedures outperform the current state-of-the-art method for measuring the colors, shapes, and morphologies of stars and galaxies. On a supercomputer, the VI procedure efficiently uses 665,000 CPU cores (1.3 million hardware threads) to construct an astronomical catalog from 50 terabytes of images
Motivating the Rules of the Game for Adversarial Example Research
Jul 20, 2018

Advances in machine learning have led to broad deployment of systems with impressive performance on important problems. Nonetheless, these systems can be induced to make errors on data that are surprisingly similar to examples the learned system handles correctly. The existence of these errors raises a variety of questions about out-of-sample generalization and whether bad actors might use such examples to abuse deployed systems. As a result of these security concerns, there has been a flurry of recent papers proposing algorithms to defend against such malicious perturbations of correctly handled examples. It is unclear how such misclassifications represent a different kind of security problem than other errors, or even other attacker-produced examples that have no specific relationship to an uncorrupted input. In this paper, we argue that adversarial example defense papers have, to date, mostly considered abstract, toy games that do not relate to any specific security concern. Furthermore, defense papers have not yet precisely described all the abilities and limitations of attackers that would be relevant in practical security. Towards this end, we establish a taxonomy of motivations, constraints, and abilities for more plausible adversaries. Finally, we provide a series of recommendations outlining a path forward for future work to more clearly articulate the threat model and perform more meaningful evaluation.
Compressibility and Generalization in Large-Scale Deep Learning
May 21, 2018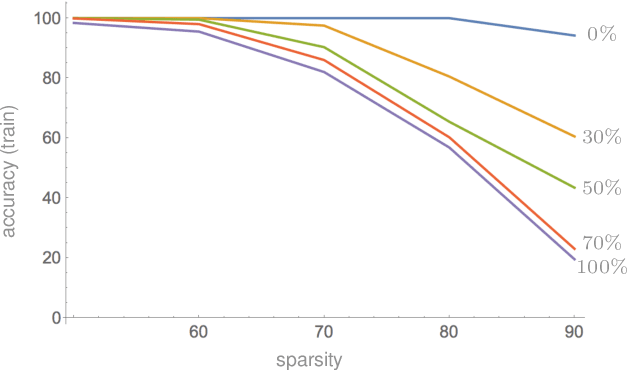
Modern neural networks are highly overparameterized, with capacity to substantially overfit to training data. Nevertheless, these networks often generalize well in practice. It has also been observed that trained networks can often be "compressed" to much smaller representations. The purpose of this paper is to connect these two empirical observations. Our main technical result is a generalization bound for compressed networks based on the compressed size. Combined with off-the-shelf compression algorithms, the bound leads to state of the art generalization guarantees; in particular, we provide the first non-vacuous generalization guarantees for realistic architectures applied to the ImageNet classification problem. As additional evidence connecting compression and generalization, we show that compressibility of models that tend to overfit is limited: We establish an absolute limit on expected compressibility as a function of expected generalization error, where the expectations are over the random choice of training examples. The bounds are complemented by empirical results that show an increase in overfitting implies an increase in the number of bits required to describe a trained network.
Estimating the Spectral Density of Large Implicit Matrices
Feb 09, 2018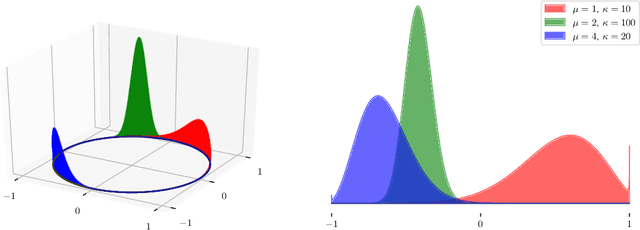
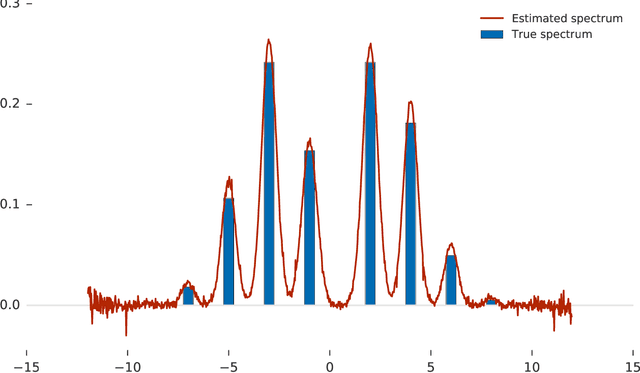
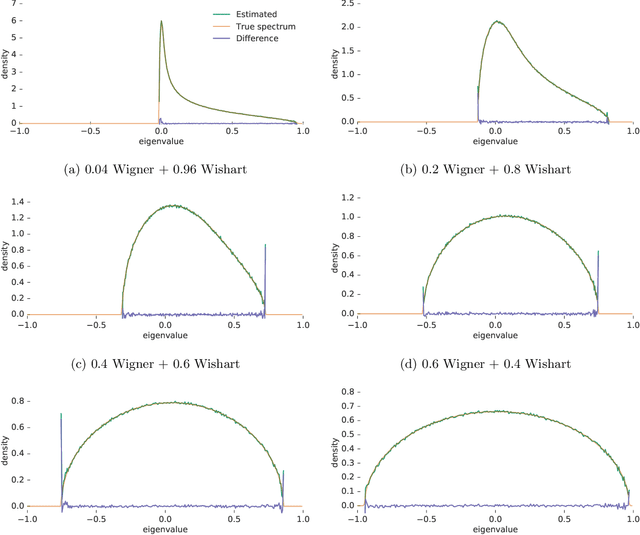
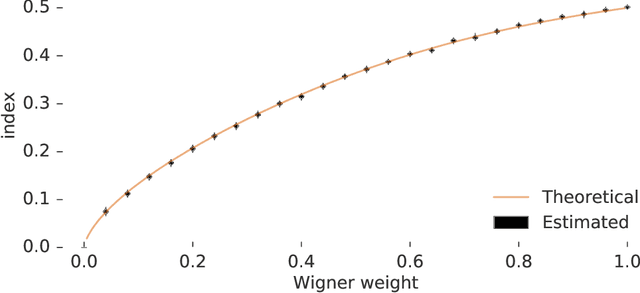
Many important problems are characterized by the eigenvalues of a large matrix. For example, the difficulty of many optimization problems, such as those arising from the fitting of large models in statistics and machine learning, can be investigated via the spectrum of the Hessian of the empirical loss function. Network data can be understood via the eigenstructure of a graph Laplacian matrix using spectral graph theory. Quantum simulations and other many-body problems are often characterized via the eigenvalues of the solution space, as are various dynamic systems. However, naive eigenvalue estimation is computationally expensive even when the matrix can be represented; in many of these situations the matrix is so large as to only be available implicitly via products with vectors. Even worse, one may only have noisy estimates of such matrix vector products. In this work, we combine several different techniques for randomized estimation and show that it is possible to construct unbiased estimators to answer a broad class of questions about the spectra of such implicit matrices, even in the presence of noise. We validate these methods on large-scale problems in which graph theory and random matrix theory provide ground truth.
Automatic chemical design using a data-driven continuous representation of molecules
Dec 05, 2017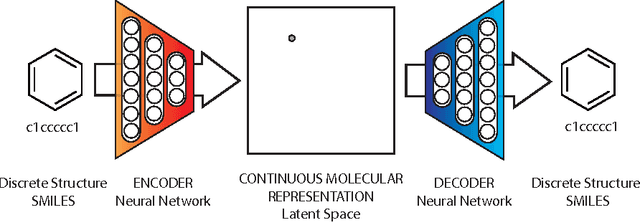
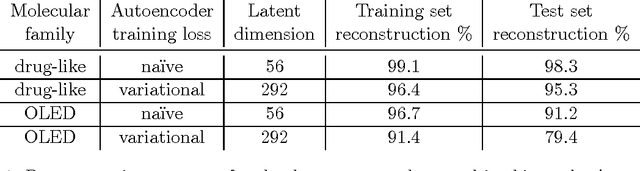
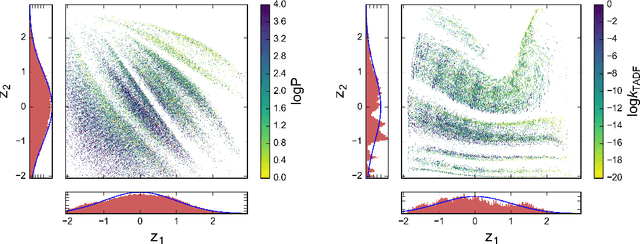
We report a method to convert discrete representations of molecules to and from a multidimensional continuous representation. This model allows us to generate new molecules for efficient exploration and optimization through open-ended spaces of chemical compounds. A deep neural network was trained on hundreds of thousands of existing chemical structures to construct three coupled functions: an encoder, a decoder and a predictor. The encoder converts the discrete representation of a molecule into a real-valued continuous vector, and the decoder converts these continuous vectors back to discrete molecular representations. The predictor estimates chemical properties from the latent continuous vector representation of the molecule. Continuous representations allow us to automatically generate novel chemical structures by performing simple operations in the latent space, such as decoding random vectors, perturbing known chemical structures, or interpolating between molecules. Continuous representations also allow the use of powerful gradient-based optimization to efficiently guide the search for optimized functional compounds. We demonstrate our method in the domain of drug-like molecules and also in the set of molecules with fewer that nine heavy atoms.