 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProBF: Learning Probabilistic Safety Certificates with Barrier Functions
Dec 24, 2021
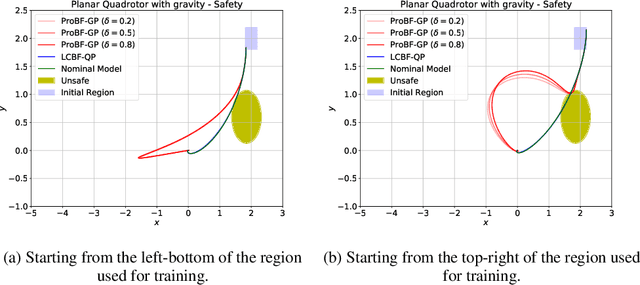
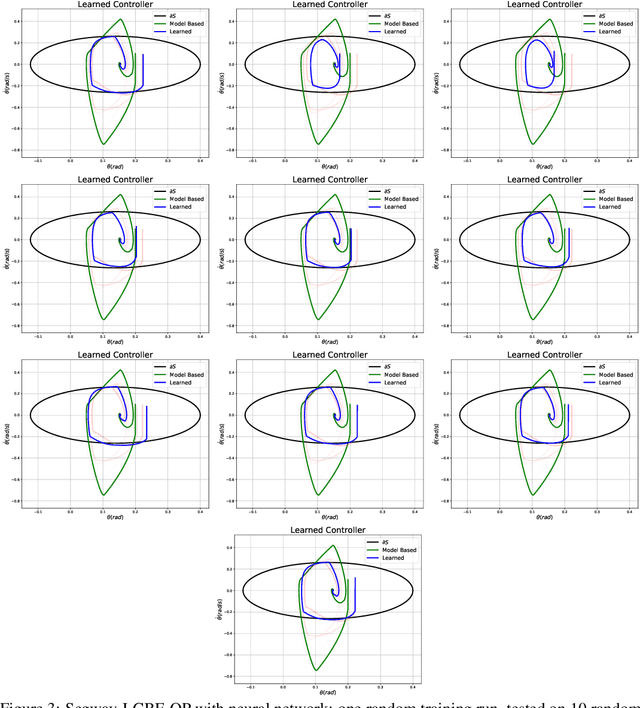
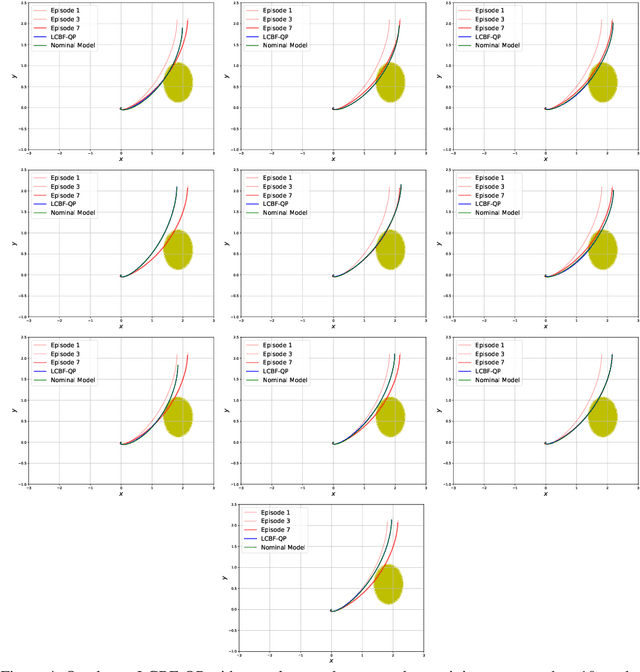
Safety-critical applications require controllers/policies that can guarantee safety with high confidence. The control barrier function is a useful tool to guarantee safety if we have access to the ground-truth system dynamics. In practice, we have inaccurate knowledge of the system dynamics, which can lead to unsafe behaviors due to unmodeled residual dynamics. Learning the residual dynamics with deterministic machine learning models can prevent the unsafe behavior but can fail when the predictions are imperfect. In this situation, a probabilistic learning method that reasons about the uncertainty of its predictions can help provide robust safety margins. In this work, we use a Gaussian process to model the projection of the residual dynamics onto a control barrier function. We propose a novel optimization procedure to generate safe controls that can guarantee safety with high probability. The safety filter is provided with the ability to reason about the uncertainty of the predictions from the GP. We show the efficacy of this method through experiments on Segway and Quadrotor simulations. Our proposed probabilistic approach is able to reduce the number of safety violations significantly as compared to the deterministic approach with a neural network.
Vitruvion: A Generative Model of Parametric CAD Sketches
Sep 29, 2021
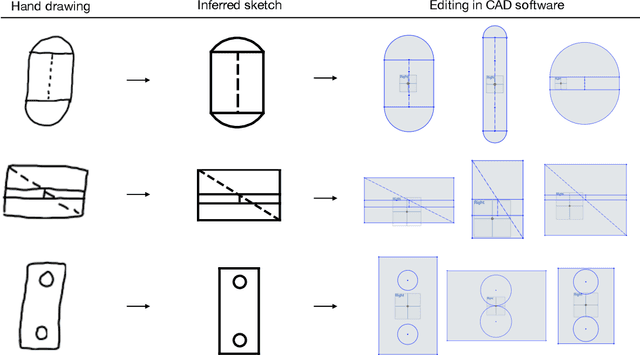
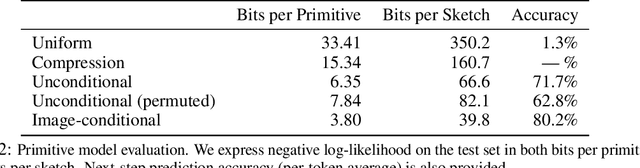
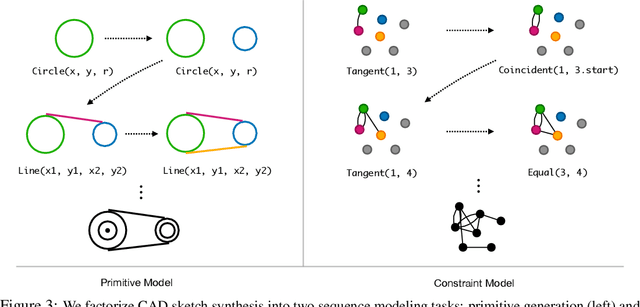
Parametric computer-aided design (CAD) tools are the predominant way that engineers specify physical structures, from bicycle pedals to airplanes to printed circuit boards. The key characteristic of parametric CAD is that design intent is encoded not only via geometric primitives, but also by parameterized constraints between the elements. This relational specification can be viewed as the construction of a constraint program, allowing edits to coherently propagate to other parts of the design. Machine learning offers the intriguing possibility of accelerating the design process via generative modeling of these structures, enabling new tools such as autocompletion, constraint inference, and conditional synthesis. In this work, we present such an approach to generative modeling of parametric CAD sketches, which constitute the basic computational building blocks of modern mechanical design. Our model, trained on real-world designs from the SketchGraphs dataset, autoregressively synthesizes sketches as sequences of primitives, with initial coordinates, and constraints that reference back to the sampled primitives. As samples from the model match the constraint graph representation used in standard CAD software, they may be directly imported, solved, and edited according to downstream design tasks. In addition, we condition the model on various contexts, including partial sketches (primers) and images of hand-drawn sketches. Evaluation of the proposed approach demonstrates its ability to synthesize realistic CAD sketches and its potential to aid the mechanical design workflow.
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
Jul 13, 2021

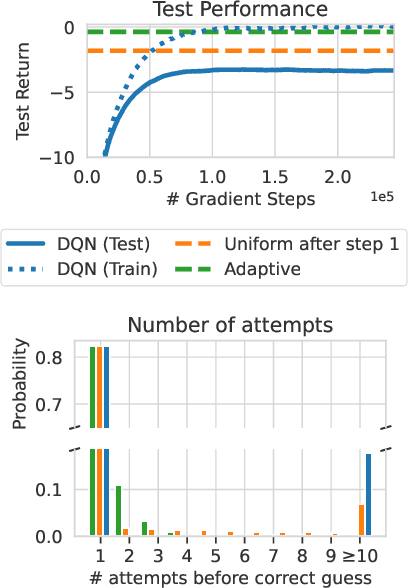
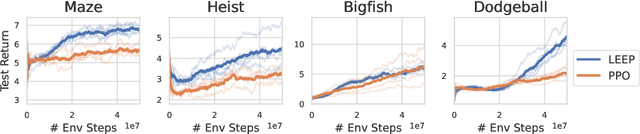
Generalization is a central challenge for the deployment of reinforcement learning (RL) systems in the real world. In this paper, we show that the sequential structure of the RL problem necessitates new approaches to generalization beyond the well-studied techniques used in supervised learning. While supervised learning methods can generalize effectively without explicitly accounting for epistemic uncertainty, we show that, perhaps surprisingly, this is not the case in RL. We show that generalization to unseen test conditions from a limited number of training conditions induces implicit partial observability, effectively turning even fully-observed MDPs into POMDPs. Informed by this observation, we recast the problem of generalization in RL as solving the induced partially observed Markov decision process, which we call the epistemic POMDP. We demonstrate the failure modes of algorithms that do not appropriately handle this partial observability, and suggest a simple ensemble-based technique for approximately solving the partially observed problem. Empirically, we demonstrate that our simple algorithm derived from the epistemic POMDP achieves significant gains in generalization over current methods on the Procgen benchmark suite.
Amortized Synthesis of Constrained Configurations Using a Differentiable Surrogate
Jun 16, 2021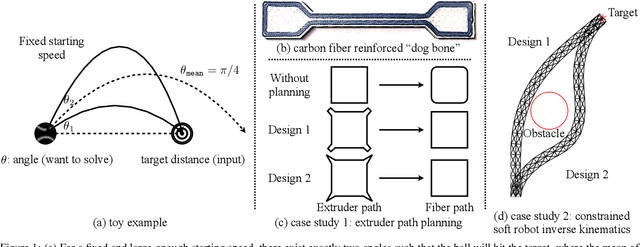

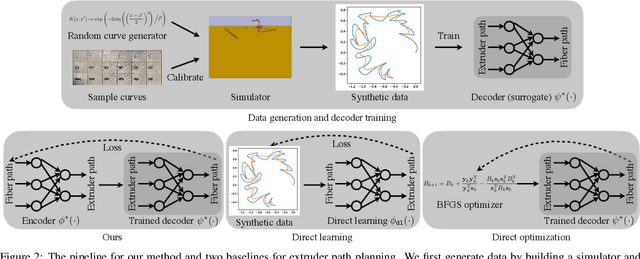
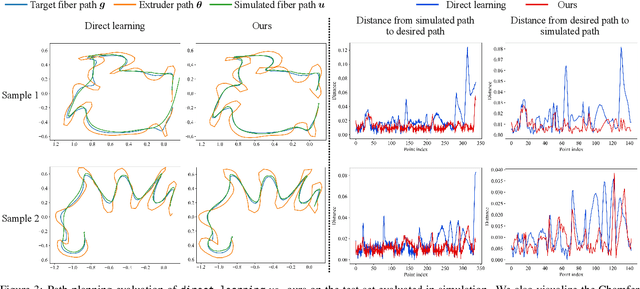
In design, fabrication, and control problems, we are often faced with the task of synthesis, in which we must generate an object or configuration that satisfies a set of constraints while maximizing one or more objective functions. The synthesis problem is typically characterized by a physical process in which many different realizations may achieve the goal. This many-to-one map presents challenges to the supervised learning of feed-forward synthesis, as the set of viable designs may have a complex structure. In addition, the non-differentiable nature of many physical simulations prevents direct optimization. We address both of these problems with a two-stage neural network architecture that we may consider to be an autoencoder. We first learn the decoder: a differentiable surrogate that approximates the many-to-one physical realization process. We then learn the encoder, which maps from goal to design, while using the fixed decoder to evaluate the quality of the realization. We evaluate the approach on two case studies: extruder path planning in additive manufacturing and constrained soft robot inverse kinematics. We compare our approach to direct optimization of design using the learned surrogate, and to supervised learning of the synthesis problem. We find that our approach produces higher quality solutions than supervised learning, while being competitive in quality with direct optimization, at a greatly reduced computational cost.
Active multi-fidelity Bayesian online changepoint detection
Mar 26, 2021
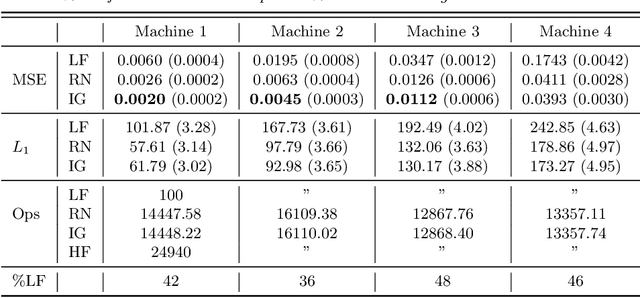
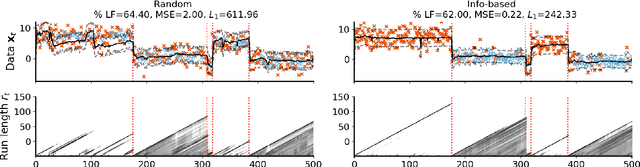
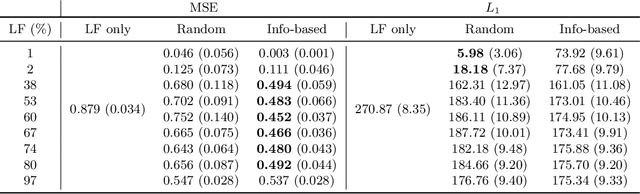
Online algorithms for detecting changepoints, or abrupt shifts in the behavior of a time series, are often deployed with limited resources, e.g., to edge computing settings such as mobile phones or industrial sensors. In these scenarios it may be beneficial to trade the cost of collecting an environmental measurement against the quality or "fidelity" of this measurement and how the measurement affects changepoint estimation. For instance, one might decide between inertial measurements or GPS to determine changepoints for motion. A Bayesian approach to changepoint detection is particularly appealing because we can represent our posterior uncertainty about changepoints and make active, cost-sensitive decisions about data fidelity to reduce this posterior uncertainty. Moreover, the total cost could be dramatically lowered through active fidelity switching, while remaining robust to changes in data distribution. We propose a multi-fidelity approach that makes cost-sensitive decisions about which data fidelity to collect based on maximizing information gain with respect to changepoints. We evaluate this framework on synthetic, video, and audio data and show that this information-based approach results in accurate predictions while reducing total cost.
Randomized Automatic Differentiation
Jul 20, 2020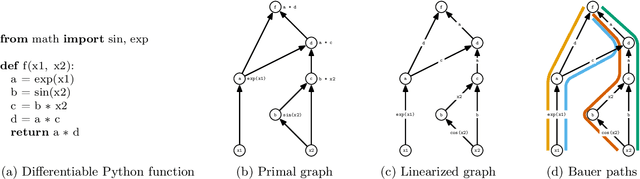
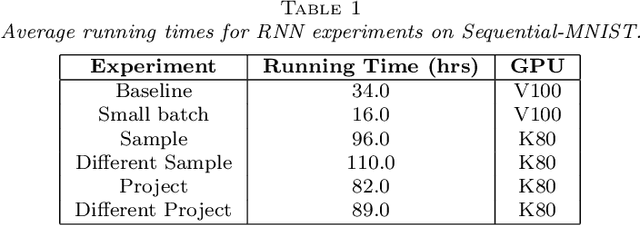

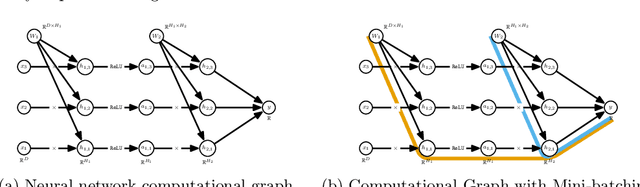
The successes of deep learning, variational inference, and many other fields have been aided by specialized implementations of reverse-mode automatic differentiation (AD) to compute gradients of mega-dimensional objectives. The AD techniques underlying these tools were designed to compute exact gradients to numerical precision, but modern machine learning models are almost always trained with stochastic gradient descent. Why spend computation and memory on exact (minibatch) gradients only to use them for stochastic optimization? We develop a general framework and approach for randomized automatic differentiation (RAD), which allows unbiased gradient estimates to be computed with reduced memory in return for variance. We examine limitations of the general approach, and argue that we must leverage problem specific structure to realize benefits. We develop RAD techniques for a variety of simple neural network architectures, and show that for a fixed memory budget, RAD converges in fewer iterations than using a small batch size for feedforward networks, and in a similar number for recurrent networks. We also show that RAD can be applied to scientific computing, and use it to develop a low-memory stochastic gradient method for optimizing the control parameters of a linear reaction-diffusion PDE representing a fission reactor.
SketchGraphs: A Large-Scale Dataset for Modeling Relational Geometry in Computer-Aided Design
Jul 16, 2020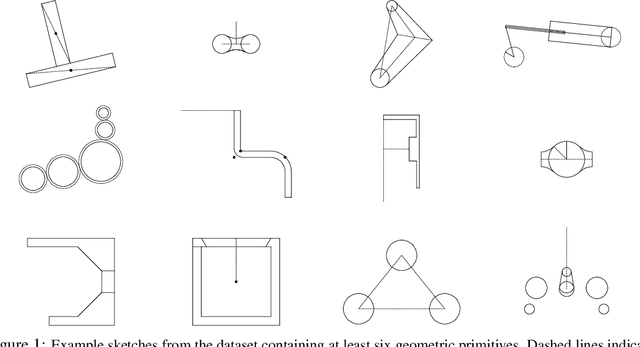
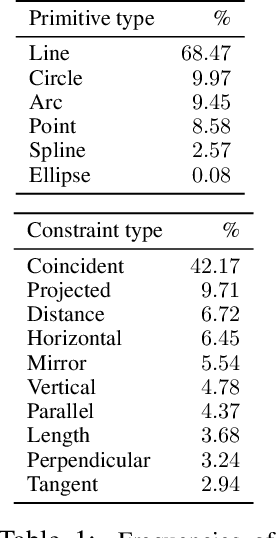
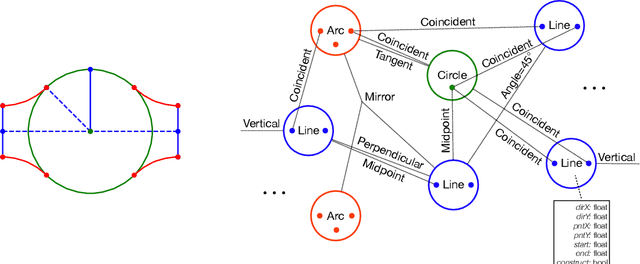
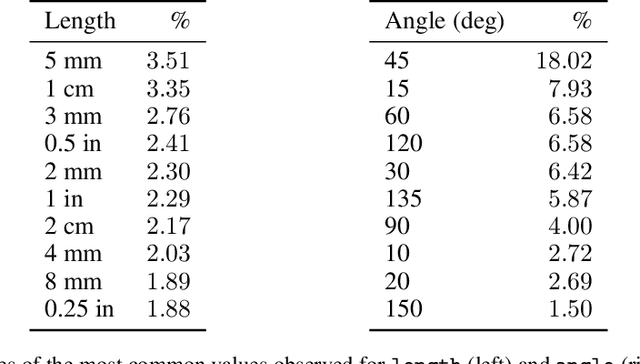
Parametric computer-aided design (CAD) is the dominant paradigm in mechanical engineering for physical design. Distinguished by relational geometry, parametric CAD models begin as two-dimensional sketches consisting of geometric primitives (e.g., line segments, arcs) and explicit constraints between them (e.g., coincidence, perpendicularity) that form the basis for three-dimensional construction operations. Training machine learning models to reason about and synthesize parametric CAD designs has the potential to reduce design time and enable new design workflows. Additionally, parametric CAD designs can be viewed as instances of constraint programming and they offer a well-scoped test bed for exploring ideas in program synthesis and induction. To facilitate this research, we introduce SketchGraphs, a collection of 15 million sketches extracted from real-world CAD models coupled with an open-source data processing pipeline. Each sketch is represented as a geometric constraint graph where edges denote designer-imposed geometric relationships between primitives, the nodes of the graph. We demonstrate and establish benchmarks for two use cases of the dataset: generative modeling of sketches and conditional generation of likely constraints given unconstrained geometry.
Learning Composable Energy Surrogates for PDE Order Reduction
May 15, 2020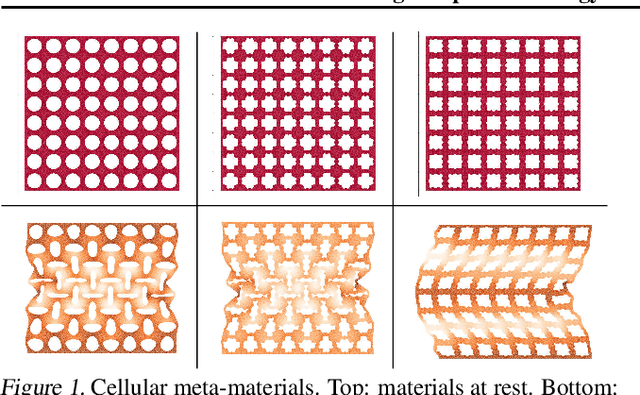
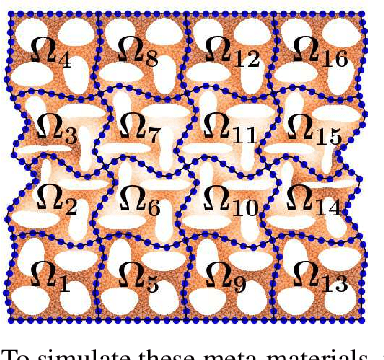
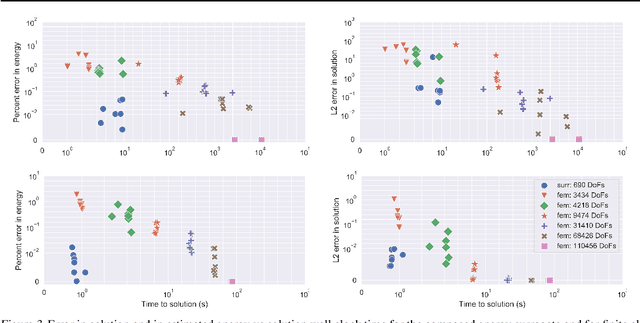
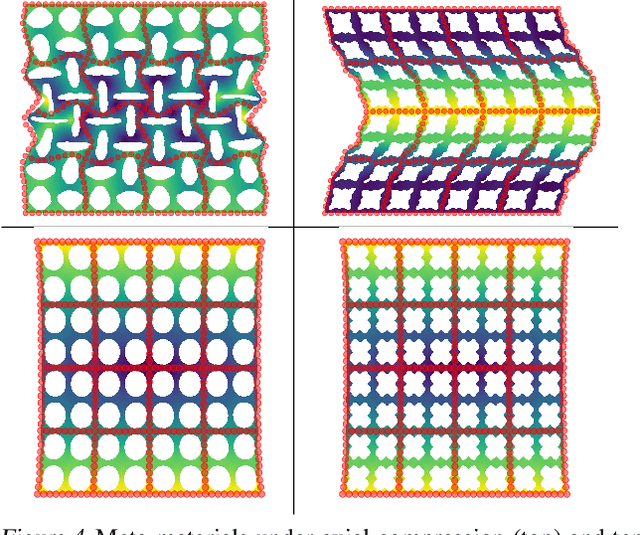
Meta-materials are an important emerging class of engineered materials in which complex macroscopic behaviour--whether electromagnetic, thermal, or mechanical--arises from modular substructure. Simulation and optimization of these materials are computationally challenging, as rich substructures necessitate high-fidelity finite element meshes to solve the governing PDEs. To address this, we leverage parametric modular structure to learn component-level surrogates, enabling cheaper high-fidelity simulation. We use a neural network to model the stored potential energy in a component given boundary conditions. This yields a structured prediction task: macroscopic behavior is determined by the minimizer of the system's total potential energy, which can be approximated by composing these surrogate models. Composable energy surrogates thus permit simulation in the reduced basis of component boundaries. Costly ground-truth simulation of the full structure is avoided, as training data are generated by performing finite element analysis with individual components. Using dataset aggregation to choose training boundary conditions allows us to learn energy surrogates which produce accurate macroscopic behavior when composed, accelerating simulation of parametric meta-materials.
SUMO: Unbiased Estimation of Log Marginal Probability for Latent Variable Models
Apr 01, 2020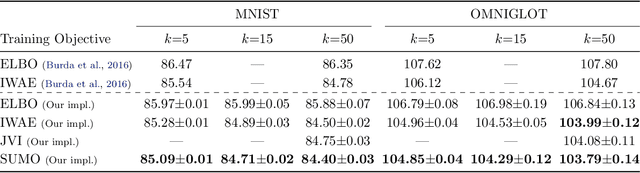

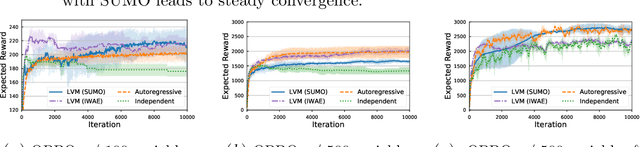
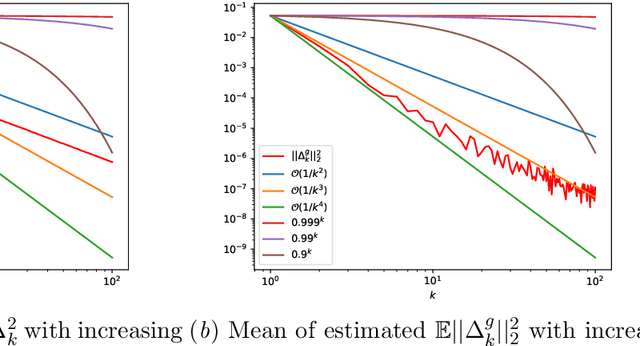
Standard variational lower bounds used to train latent variable models produce biased estimates of most quantities of interest. We introduce an unbiased estimator of the log marginal likelihood and its gradients for latent variable models based on randomized truncation of infinite series. If parameterized by an encoder-decoder architecture, the parameters of the encoder can be optimized to minimize its variance of this estimator. We show that models trained using our estimator give better test-set likelihoods than a standard importance-sampling based approach for the same average computational cost. This estimator also allows use of latent variable models for tasks where unbiased estimators, rather than marginal likelihood lower bounds, are preferred, such as minimizing reverse KL divergences and estimating score functions.
On the Difficulty of Warm-Starting Neural Network Training
Oct 18, 2019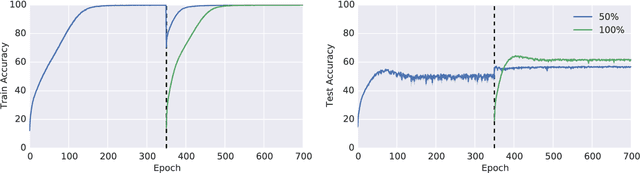
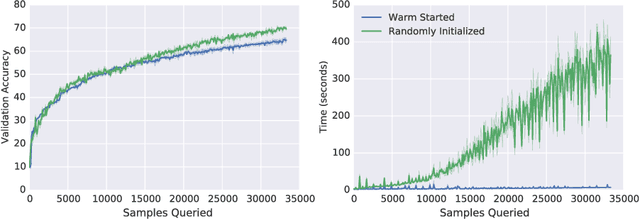
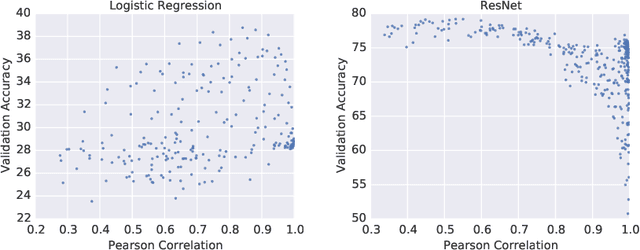
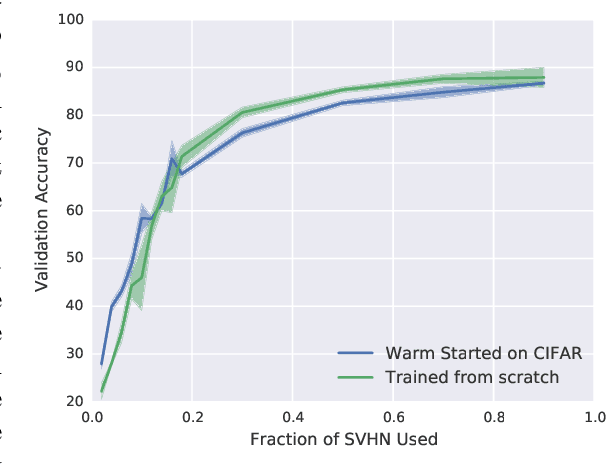
In many real-world deployments of machine learning systems, data arrive piecemeal. These learning scenarios may be passive, where data arrive incrementally due to structural properties of the problem (e.g., daily financial data) or active, where samples are selected according to a measure of their quality (e.g., experimental design). In both of these cases, we are building a sequence of models that incorporate an increasing amount of data. We would like each of these models in the sequence to be performant and take advantage of all the data that are available to that point. Conventional intuition suggests that when solving a sequence of related optimization problems of this form, it should be possible to initialize using the solution of the previous iterate---to "warm start" the optimization rather than initialize from scratch---and see reductions in wall-clock time. However, in practice this warm-starting seems to yield poorer generalization performance than models that have fresh random initializations, even though the final training losses are similar. While it appears that some hyperparameter settings allow a practitioner to close this generalization gap, they seem to only do so in regimes that damage the wall-clock gains of the warm start. Nevertheless, it is highly desirable to be able to warm-start neural network training, as it would dramatically reduce the resource usage associated with the construction of performant deep learning systems. In this work, we take a closer look at this empirical phenomenon and try to understand when and how it occurs. Although the present investigation did not lead to a solution, we hope that a thorough articulation of the problem will spur new research that may lead to improved methods that consume fewer resources during training.