 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Roleplay-doh: Enabling Domain-Experts to Create LLM-simulated Patients via Eliciting and Adhering to Principles
Jul 01, 2024



Recent works leverage LLMs to roleplay realistic social scenarios, aiding novices in practicing their social skills. However, simulating sensitive interactions, such as in mental health, is challenging. Privacy concerns restrict data access, and collecting expert feedback, although vital, is laborious. To address this, we develop Roleplay-doh, a novel human-LLM collaboration pipeline that elicits qualitative feedback from a domain-expert, which is transformed into a set of principles, or natural language rules, that govern an LLM-prompted roleplay. We apply this pipeline to enable senior mental health supporters to create customized AI patients for simulated practice partners for novice counselors. After uncovering issues in GPT-4 simulations not adhering to expert-defined principles, we also introduce a novel principle-adherence prompting pipeline which shows 30\% improvements in response quality and principle following for the downstream task. Via a user study with 25 counseling experts, we demonstrate that the pipeline makes it easy and effective to create AI patients that more faithfully resemble real patients, as judged by creators and third-party counselors.
Multi-Level Feedback Generation with Large Language Models for Empowering Novice Peer Counselors
Mar 21, 2024Realistic practice and tailored feedback are key processes for training peer counselors with clinical skills. However, existing mechanisms of providing feedback largely rely on human supervision. Peer counselors often lack mechanisms to receive detailed feedback from experienced mentors, making it difficult for them to support the large number of people with mental health issues who use peer counseling. Our work aims to leverage large language models to provide contextualized and multi-level feedback to empower peer counselors, especially novices, at scale. To achieve this, we co-design with a group of senior psychotherapy supervisors to develop a multi-level feedback taxonomy, and then construct a publicly available dataset with comprehensive feedback annotations of 400 emotional support conversations. We further design a self-improvement method on top of large language models to enhance the automatic generation of feedback. Via qualitative and quantitative evaluation with domain experts, we demonstrate that our method minimizes the risk of potentially harmful and low-quality feedback generation which is desirable in such high-stakes scenarios.
Expressive Communication: A Common Framework for Evaluating Developments in Generative Models and Steering Interfaces
Nov 29, 2021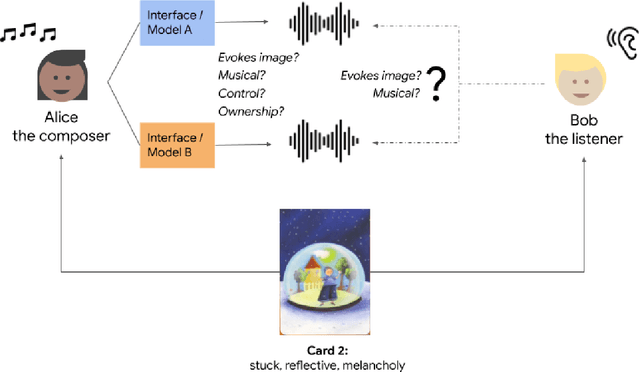
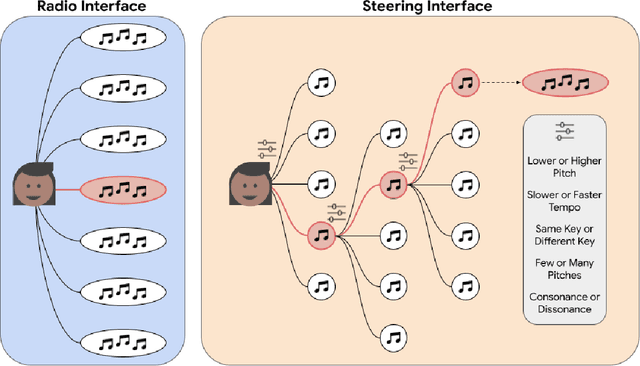

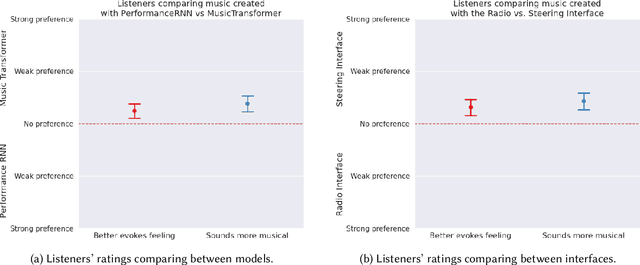
There is an increasing interest from ML and HCI communities in empowering creators with better generative models and more intuitive interfaces with which to control them. In music, ML researchers have focused on training models capable of generating pieces with increasing long-range structure and musical coherence, while HCI researchers have separately focused on designing steering interfaces that support user control and ownership. In this study, we investigate through a common framework how developments in both models and user interfaces are important for empowering co-creation where the goal is to create music that communicates particular imagery or ideas (e.g., as is common for other purposeful tasks in music creation like establishing mood or creating accompanying music for another media). Our study is distinguished in that it measures communication through both composer's self-reported experiences, and how listeners evaluate this communication through the music. In an evaluation study with 26 composers creating 100+ pieces of music and listeners providing 1000+ head-to-head comparisons, we find that more expressive models and more steerable interfaces are important and complementary ways to make a difference in composers communicating through music and supporting their creative empowerment.