 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Intersection of Context-Free and Regular Languages
Sep 14, 2022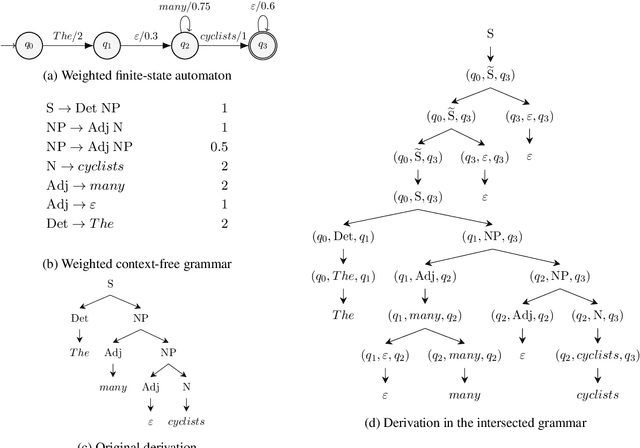
The Bar-Hillel construction is a classic result in formal language theory. It shows, by construction, that the intersection between a context-free language and a regular language is itself context-free. However, neither its original formulation (Bar-Hillel et al., 1961) nor its weighted extension (Nederhof and Satta, 2003) can handle automata with $\epsilon$-arcs. In this short note, we generalize the Bar-Hillel construction to correctly compute the intersection even when the automaton contains $\epsilon$-arcs. We further prove that our generalized construction leads to a grammar that encodes the structure of both the input automaton and grammar while retaining the asymptotic size of the original construction.
On the Role of Negative Precedent in Legal Outcome Prediction
Aug 17, 2022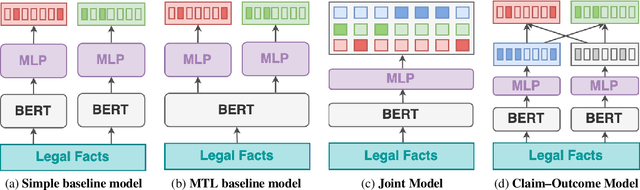
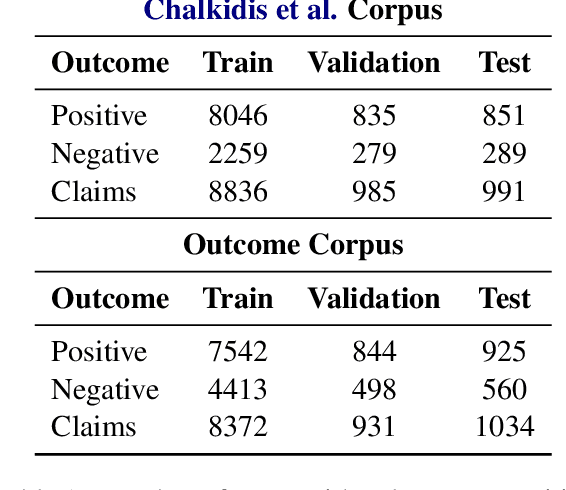
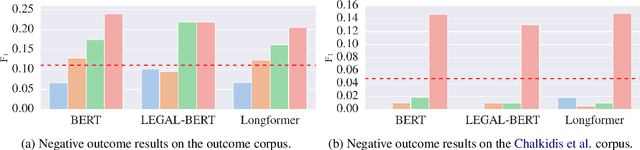
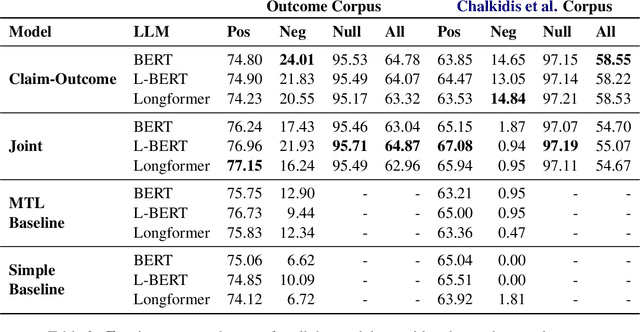
Every legal case sets a precedent by developing the law in one of the following two ways. It either expands its scope, in which case it sets positive precedent, or it narrows it down, in which case it sets negative precedent. While legal outcome prediction, which is nothing other than the prediction of positive precedents, is an increasingly popular task in AI, we are the first to investigate negative precedent prediction by focusing on negative outcomes. We discover an asymmetry in existing models' ability to predict positive and negative outcomes. Where state-of-the-art outcome prediction models predicts positive outcomes at 75.06 F1, they predicts negative outcomes at only 10.09 F1, worse than a random baseline. To address this performance gap, we develop two new models inspired by the dynamics of a court process. Our first model significantly improves positive outcome prediction score to 77.15 F1 and our second model more than doubles the negative outcome prediction performance to 24.01 F1. Despite this improvement, shifting focus to negative outcomes reveals that there is still plenty of room to grow when it comes to modelling law.
Learning Transductions to Test Systematic Compositionality
Aug 17, 2022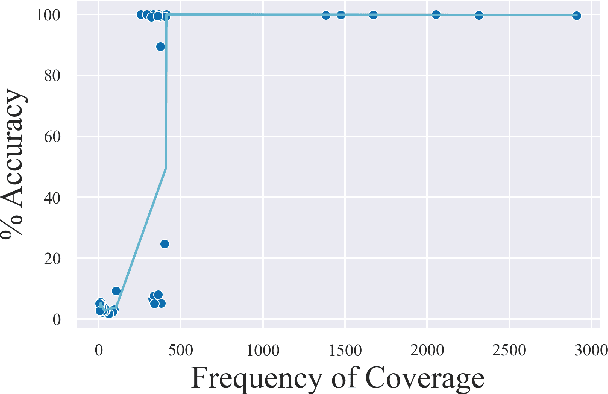
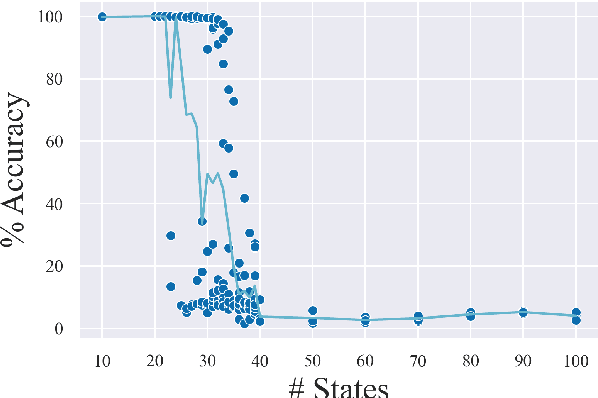
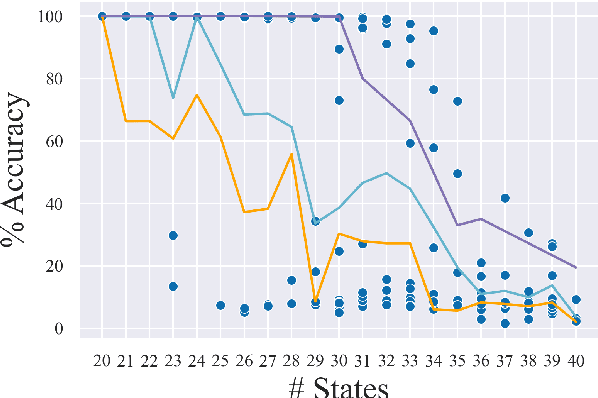
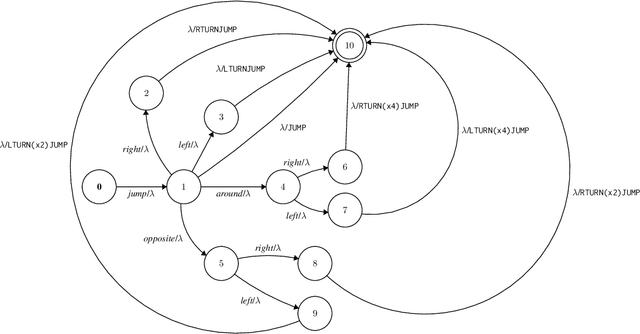
Recombining known primitive concepts into larger novel combinations is a quintessentially human cognitive capability. Whether large neural models in NLP acquire this ability while learning from data is an open question. In this paper, we look at this problem from the perspective of formal languages. We use deterministic finite-state transducers to make an unbounded number of datasets with controllable properties governing compositionality. By randomly sampling over many transducers, we explore which of their properties (number of states, alphabet size, number of transitions etc.) contribute to learnability of a compositional relation by a neural network. In general, we find that the models either learn the relations completely or not at all. The key is transition coverage, setting a soft learnability limit at 400 examples per transition.
Visual Comparison of Language Model Adaptation
Aug 17, 2022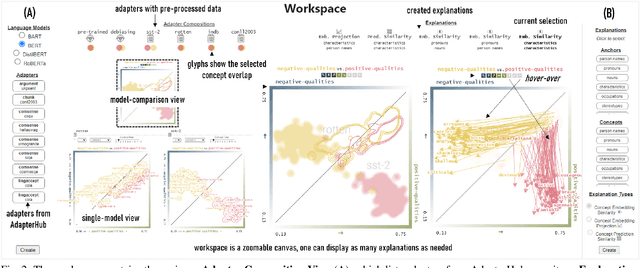
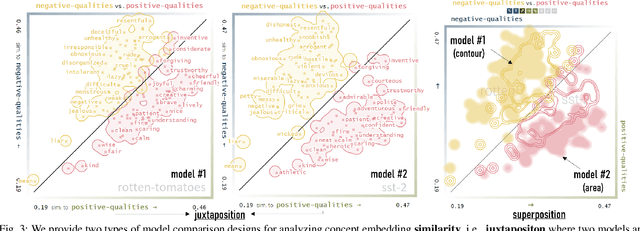
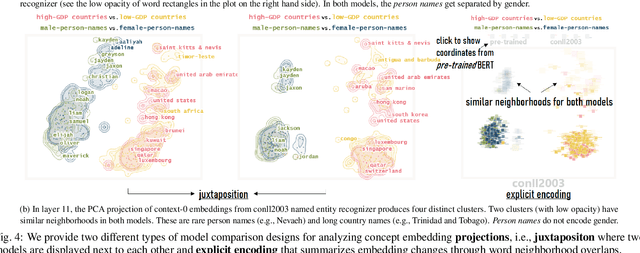
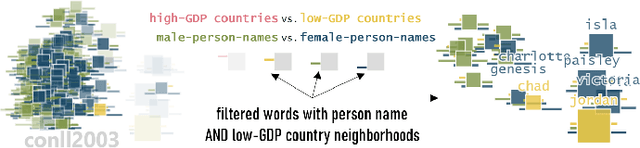
Neural language models are widely used; however, their model parameters often need to be adapted to the specific domains and tasks of an application, which is time- and resource-consuming. Thus, adapters have recently been introduced as a lightweight alternative for model adaptation. They consist of a small set of task-specific parameters with a reduced training time and simple parameter composition. The simplicity of adapter training and composition comes along with new challenges, such as maintaining an overview of adapter properties and effectively comparing their produced embedding spaces. To help developers overcome these challenges, we provide a twofold contribution. First, in close collaboration with NLP researchers, we conducted a requirement analysis for an approach supporting adapter evaluation and detected, among others, the need for both intrinsic (i.e., embedding similarity-based) and extrinsic (i.e., prediction-based) explanation methods. Second, motivated by the gathered requirements, we designed a flexible visual analytics workspace that enables the comparison of adapter properties. In this paper, we discuss several design iterations and alternatives for interactive, comparative visual explanation methods. Our comparative visualizations show the differences in the adapted embedding vectors and prediction outcomes for diverse human-interpretable concepts (e.g., person names, human qualities). We evaluate our workspace through case studies and show that, for instance, an adapter trained on the language debiasing task according to context-0 (decontextualized) embeddings introduces a new type of bias where words (even gender-independent words such as countries) become more similar to female than male pronouns. We demonstrate that these are artifacts of context-0 embeddings.
Probing via Prompting
Jul 04, 2022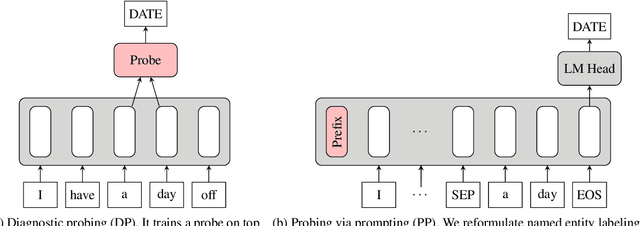

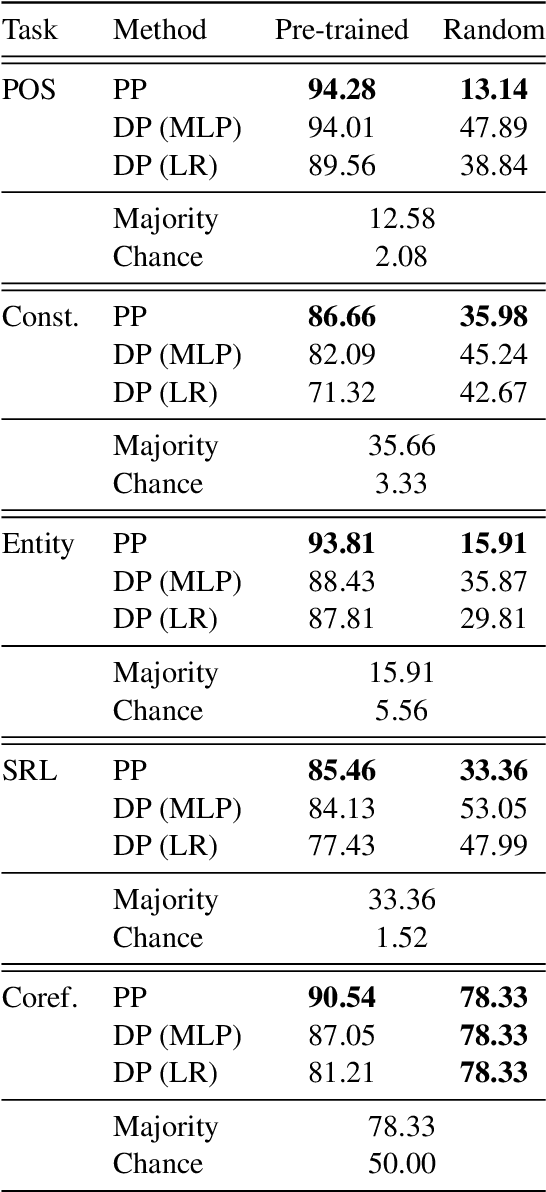
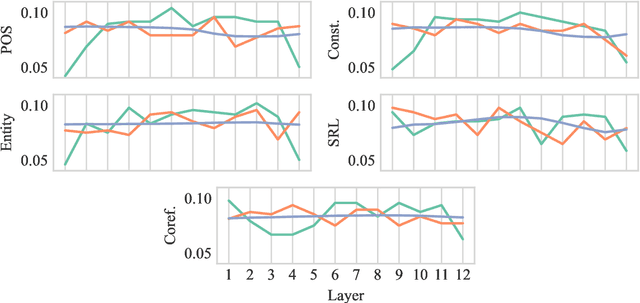
Probing is a popular method to discern what linguistic information is contained in the representations of pre-trained language models. However, the mechanism of selecting the probe model has recently been subject to intense debate, as it is not clear if the probes are merely extracting information or modeling the linguistic property themselves. To address this challenge, this paper introduces a novel model-free approach to probing, by formulating probing as a prompting task. We conduct experiments on five probing tasks and show that our approach is comparable or better at extracting information than diagnostic probes while learning much less on its own. We further combine the probing via prompting approach with attention head pruning to analyze where the model stores the linguistic information in its architecture. We then examine the usefulness of a specific linguistic property for pre-training by removing the heads that are essential to that property and evaluating the resulting model's performance on language modeling.
The SIGMORPHON 2022 Shared Task on Morpheme Segmentation
Jun 15, 2022
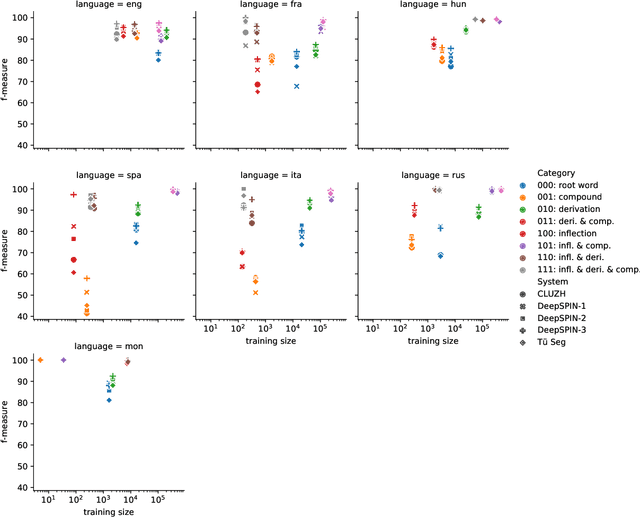
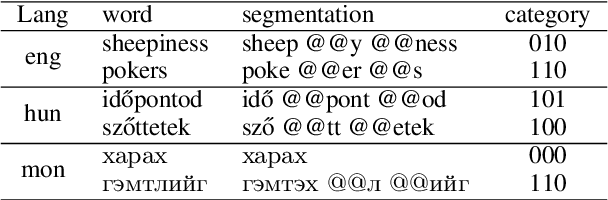
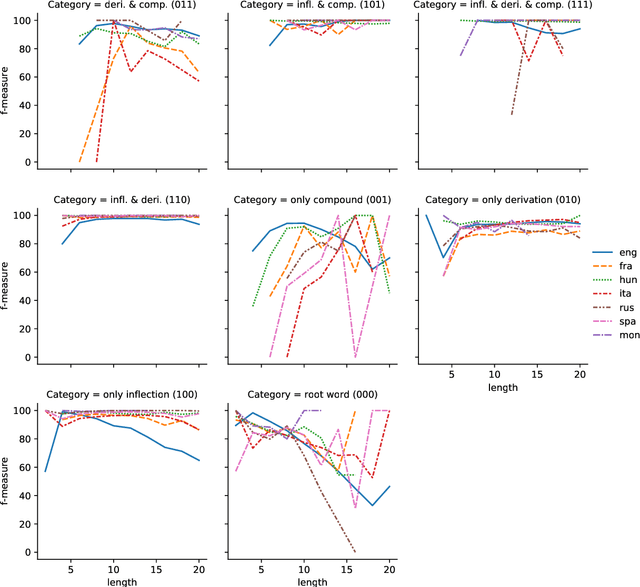
The SIGMORPHON 2022 shared task on morpheme segmentation challenged systems to decompose a word into a sequence of morphemes and covered most types of morphology: compounds, derivations, and inflections. Subtask 1, word-level morpheme segmentation, covered 5 million words in 9 languages (Czech, English, Spanish, Hungarian, French, Italian, Russian, Latin, Mongolian) and received 13 system submissions from 7 teams and the best system averaged 97.29% F1 score across all languages, ranging English (93.84%) to Latin (99.38%). Subtask 2, sentence-level morpheme segmentation, covered 18,735 sentences in 3 languages (Czech, English, Mongolian), received 10 system submissions from 3 teams, and the best systems outperformed all three state-of-the-art subword tokenization methods (BPE, ULM, Morfessor2) by 30.71% absolute. To facilitate error analysis and support any type of future studies, we released all system predictions, the evaluation script, and all gold standard datasets.
Cluster-based Evaluation of Automatically Generated Text
Jun 01, 2022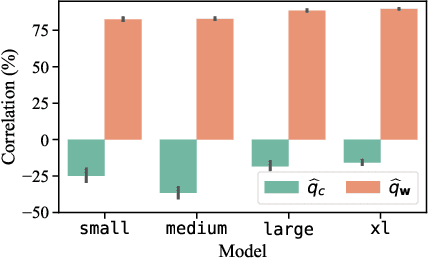
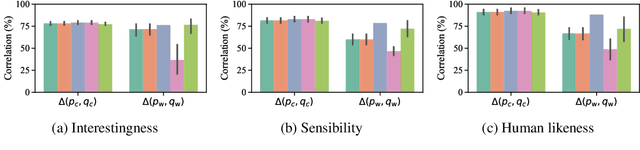
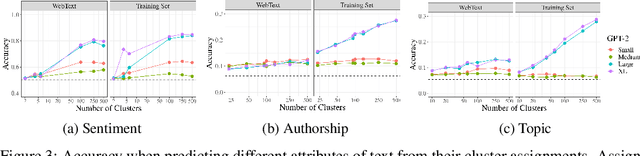
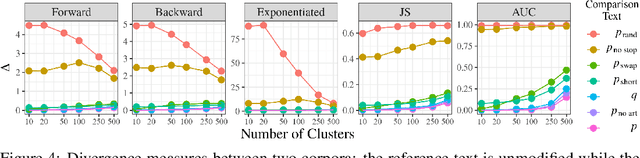
While probabilistic language generators have improved dramatically over the last few years, the automatic evaluation metrics used to assess them have not kept pace with this progress. In the domain of language generation, a good metric must correlate highly with human judgements. Yet, with few exceptions, there is a lack of such metrics in the literature. In this work, we analyse the general paradigm of language generator evaluation. We first discuss the computational and qualitative issues with using automatic evaluation metrics that operate on probability distributions over strings, the backbone of most language generators. We then propose the use of distributions over clusters instead, where we cluster strings based on their text embeddings (obtained from a pretrained language model). While we find the biases introduced by this substitution to be quite strong, we observe that, empirically, this methodology leads to metric estimators with higher correlation with human judgements, while simultaneously reducing estimator variance. We finish the paper with a probing analysis, which leads us to conclude that -- by encoding syntactic- and coherence-level features of text, while ignoring surface-level features -- these clusters may simply be better equipped to evaluate state-of-the-art language models.
Naturalistic Causal Probing for Morpho-Syntax
May 14, 2022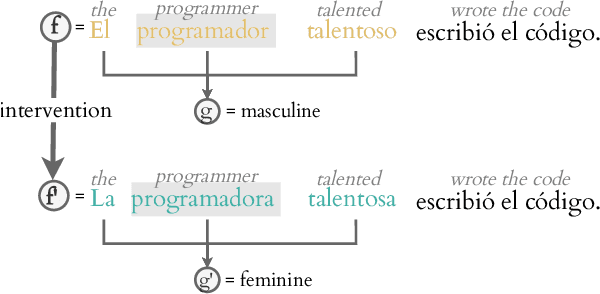
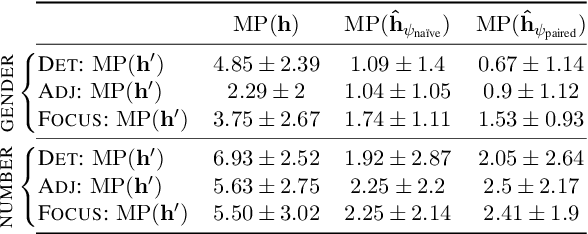
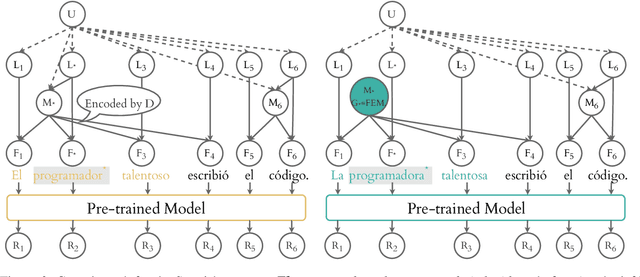
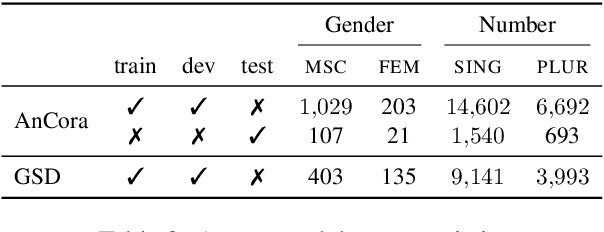
Probing has become a go-to methodology for interpreting and analyzing deep neural models in natural language processing. Yet recently, there has been much debate around the limitations and weaknesses of probes. In this work, we suggest a naturalistic strategy for input-level intervention on real world data in Spanish, which is a language with gender marking. Using our approach, we isolate morpho-syntactic features from counfounders in sentences, e.g. topic, which will then allow us to causally probe pre-trained models. We apply this methodology to analyze causal effects of gender and number on contextualized representations extracted from pre-trained models -- BERT, RoBERTa and GPT-2. Our experiments suggest that naturalistic intervention can give us stable estimates of causal effects, which varies across different words in a sentence. We further show the utility of our estimator in investigating gender bias in adjectives, and answering counterfactual questions in masked prediction. Our probing experiments highlights the importance of conducting causal probing in determining if a particular property is encoded in representations.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
A Structured Span Selector
May 08, 2022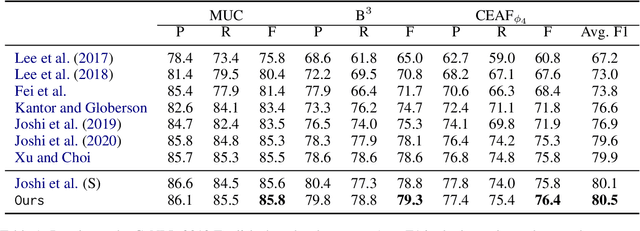
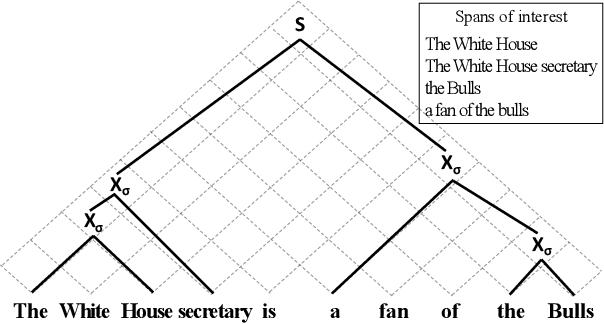
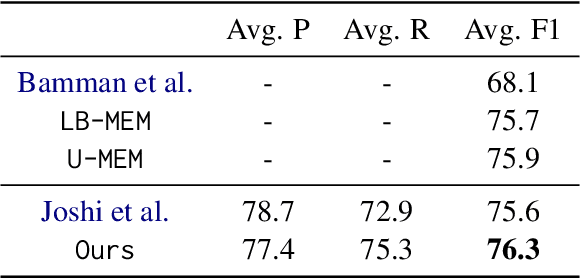
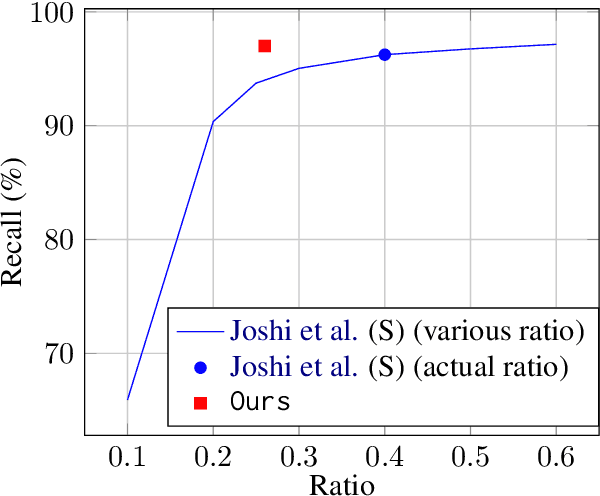
Many natural language processing tasks, e.g., coreference resolution and semantic role labeling, require selecting text spans and making decisions about them. A typical approach to such tasks is to score all possible spans and greedily select spans for task-specific downstream processing. This approach, however, does not incorporate any inductive bias about what sort of spans ought to be selected, e.g., that selected spans tend to be syntactic constituents. In this paper, we propose a novel grammar-based structured span selection model which learns to make use of the partial span-level annotation provided for such problems. Compared to previous approaches, our approach gets rid of the heuristic greedy span selection scheme, allowing us to model the downstream task on an optimal set of spans. We evaluate our model on two popular span prediction tasks: coreference resolution and semantic role labeling; and show improvements on both.