 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Learning Probabilistic Models of Black-Box AI Capabilities
Dec 20, 2025



Black-box AI (BBAI) systems such as foundational models are increasingly being used for sequential decision making. To ensure that such systems are safe to operate and deploy, it is imperative to develop efficient methods that can provide a sound and interpretable representation of the BBAI's capabilities. This paper shows that PDDL-style representations can be used to efficiently learn and model an input BBAI's planning capabilities. It uses the Monte-Carlo tree search paradigm to systematically create test tasks, acquire data, and prune the hypothesis space of possible symbolic models. Learned models describe a BBAI's capabilities, the conditions under which they can be executed, and the possible outcomes of executing them along with their associated probabilities. Theoretical results show soundness, completeness and convergence of the learned models. Empirical results with multiple BBAI systems illustrate the scope, efficiency, and accuracy of the presented methods.
$\forall$uto$\exists$$\lor\!\land$L: Autonomous Evaluation of LLMs for Truth Maintenance and Reasoning Tasks
Oct 11, 2024



This paper presents $\forall$uto$\exists$$\lor\!\land$L, a novel benchmark for scaling Large Language Model (LLM) assessment in formal tasks with clear notions of correctness, such as truth maintenance in translation and logical reasoning. $\forall$uto$\exists$$\lor\!\land$L is the first benchmarking paradigm that offers several key advantages necessary for scaling objective evaluation of LLMs without human labeling: (a) ability to evaluate LLMs of increasing sophistication by auto-generating tasks at different levels of difficulty; (b) auto-generation of ground truth that eliminates dependence on expensive and time-consuming human annotation; (c) the use of automatically generated, randomized datasets that mitigate the ability of successive LLMs to overfit to static datasets used in many contemporary benchmarks. Empirical analysis shows that an LLM's performance on $\forall$uto$\exists$$\lor\!\land$L is highly indicative of its performance on a diverse array of other benchmarks focusing on translation and reasoning tasks, making it a valuable autonomous evaluation paradigm in settings where hand-curated datasets can be hard to obtain and/or update.
Using Explainable AI and Hierarchical Planning for Outreach with Robots
Mar 31, 2024



Understanding how robots plan and execute tasks is crucial in today's world, where they are becoming more prevalent in our daily lives. However, teaching non-experts the complexities of robot planning can be challenging. This work presents an open-source platform that simplifies the process using a visual interface that completely abstracts the complex internals of hierarchical planning that robots use for performing task and motion planning. Using the principles developed in the field of explainable AI, this intuitive platform enables users to create plans for robots to complete tasks, and provides helpful hints and natural language explanations for errors. The platform also has a built-in simulator to demonstrate how robots execute submitted plans. This platform's efficacy was tested in a user study on university students with little to no computer science background. Our results show that this platform is highly effective in teaching novice users the intuitions of robot task planning.
Can LLMs Converse Formally? Automatically Assessing LLMs in Translating and Interpreting Formal Specifications
Mar 27, 2024



Stakeholders often describe system requirements using natural language which are then converted to formal syntax by a domain-expert leading to increased design costs. This paper assesses the capabilities of Large Language Models (LLMs) in converting between natural language descriptions and formal specifications. Existing work has evaluated the capabilities of LLMs in generating formal syntax such as source code but such experiments are typically hand-crafted and use problems that are likely to be in the training set of LLMs, and often require human-annotated datasets. We propose an approach that can use two copies of an LLM in conjunction with an off-the-shelf verifier to automatically evaluate its translation abilities without any additional human input. Our approach generates formal syntax using language grammars to automatically generate a dataset. We conduct an empirical evaluation to measure the accuracy of this translation task and show that SOTA LLMs cannot adequately solve this task, limiting their current utility in the design of complex systems.
Epistemic Exploration for Generalizable Planning and Learning in Non-Stationary Settings
Feb 13, 2024

This paper introduces a new approach for continual planning and model learning in non-stationary stochastic environments expressed using relational representations. Such capabilities are essential for the deployment of sequential decision-making systems in the uncertain, constantly evolving real world. Working in such practical settings with unknown (and non-stationary) transition systems and changing tasks, the proposed framework models gaps in the agent's current state of knowledge and uses them to conduct focused, investigative explorations. Data collected using these explorations is used for learning generalizable probabilistic models for solving the current task despite continual changes in the environment dynamics. Empirical evaluations on several benchmark domains show that this approach significantly outperforms planning and RL baselines in terms of sample complexity in non-stationary settings. Theoretical results show that the system reverts to exhibit desirable convergence properties when stationarity holds.
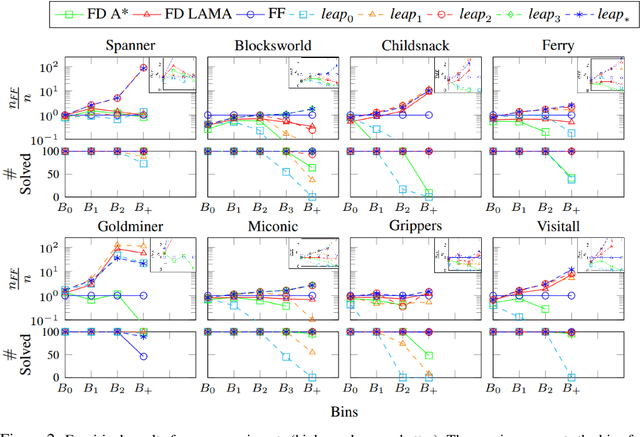
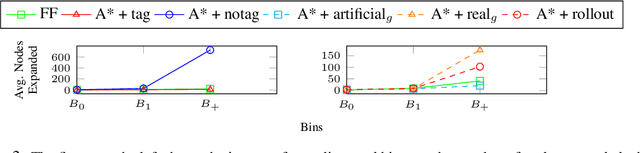
Autonomous Capability Assessment of Black-Box Sequential Decision-Making Systems
Jun 07, 2023It is essential for users to understand what their AI systems can and can't do in order to use them safely. However, the problem of enabling users to assess AI systems with evolving sequential decision making (SDM) capabilities is relatively understudied. This paper presents a new approach for modeling the capabilities of black-box AI systems that can plan and act, along with the possible effects and requirements for executing those capabilities in stochastic settings. We present an active-learning approach that can effectively interact with a black-box SDM system and learn an interpretable probabilistic model describing its capabilities. Theoretical analysis of the approach identifies the conditions under which the learning process is guaranteed to converge to the correct model of the agent; empirical evaluations on different agents and simulated scenarios show that this approach is few-shot generalizable and can effectively describe the capabilities of arbitrary black-box SDM agents in a sample-efficient manner.
Relational Abstractions for Generalized Reinforcement Learning on Symbolic Problems
Apr 27, 2022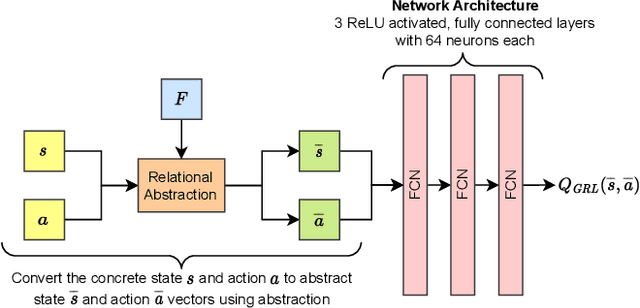
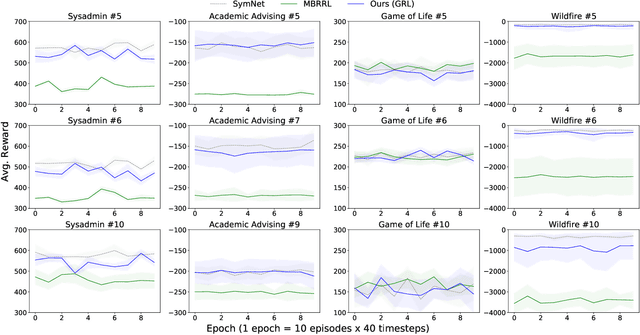
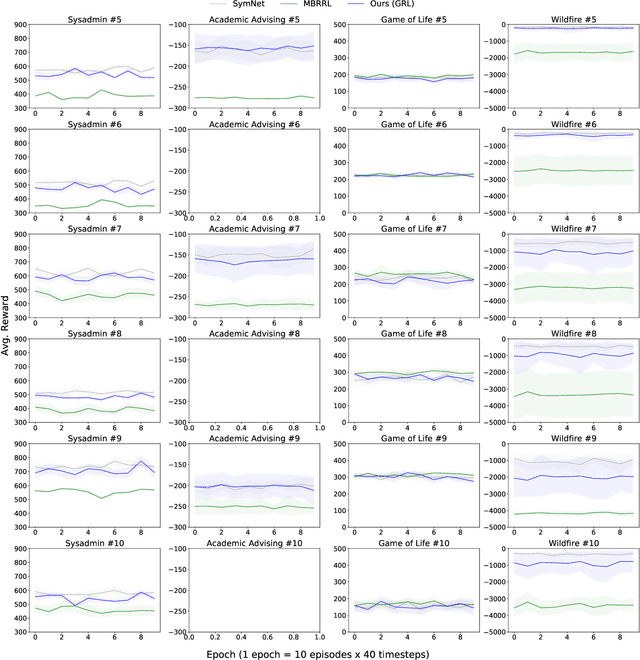
Reinforcement learning in problems with symbolic state spaces is challenging due to the need for reasoning over long horizons. This paper presents a new approach that utilizes relational abstractions in conjunction with deep learning to learn a generalizable Q-function for such problems. The learned Q-function can be efficiently transferred to related problems that have different object names and object quantities, and thus, entirely different state spaces. We show that the learned generalized Q-function can be utilized for zero-shot transfer to related problems without an explicit, hand-coded curriculum. Empirical evaluations on a range of problems show that our method facilitates efficient zero-shot transfer of learned knowledge to much larger problem instances containing many objects.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

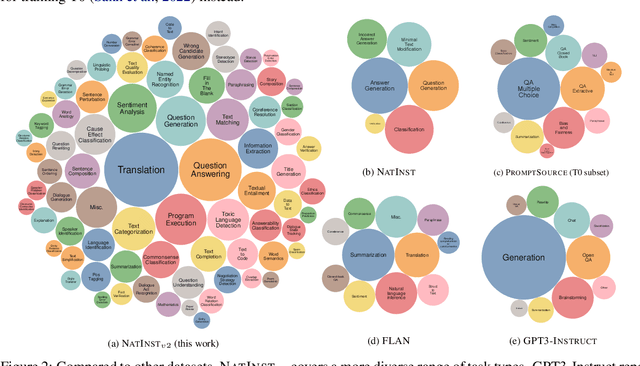
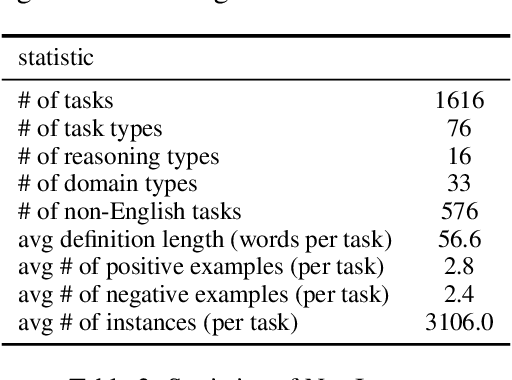
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
Preliminary Results on Using Abstract AND-OR Graphs for Generalized Solving of Stochastic Shortest Path Problems
Apr 08, 2022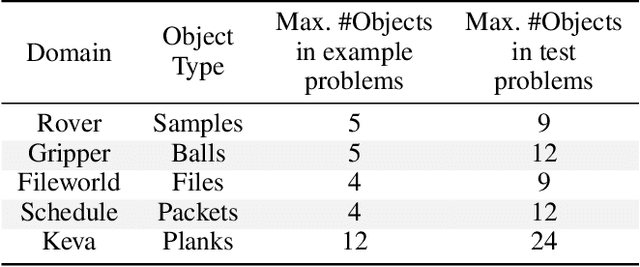
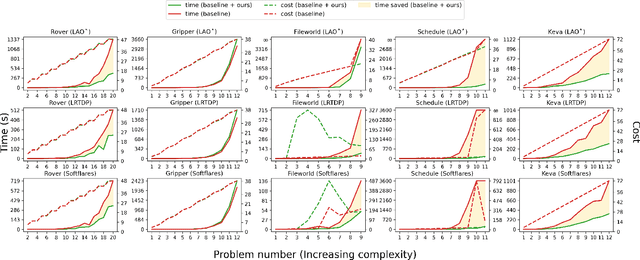
Several goal-oriented problems in the real-world can be naturally expressed as Stochastic Shortest Path Problems (SSPs). However, a key difficulty for computing solutions for problems in the SSP framework is that the computational requirements often make finding solutions to even moderately sized problems intractable. Solutions to many of such problems can often be expressed as generalized policies that are quite easy to compute from small examples and are readily applicable to problems with a larger number of objects and/or different object names. In this paper, we provide a preliminary study on using canonical abstractions to compute such generalized policies and represent them as AND-OR graphs that translate to simple non-deterministic, memoryless controllers. Such policy structures naturally lend themselves to a hierarchical approach for solving problems and we show that our approach can be embedded in any SSP solver to compute hierarchically optimal policies. We conducted an empirical evaluation on some well-known planning benchmarks and difficult robotics domains and show that our approach is promising, often computing optimal policies significantly faster than state-of-art SSP solvers.
Learning Generalized Relational Heuristic Networks for Model-Agnostic Planning
Jul 10, 2020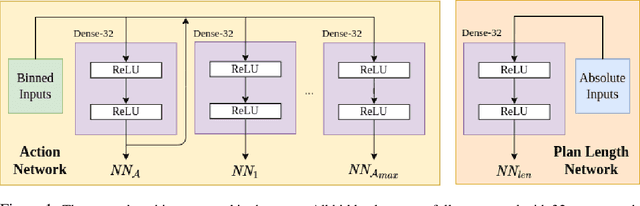
Computing goal-directed behavior (sequential decision-making, or planning) is essential to designing efficient AI systems. Due to the computational complexity of planning, current approaches rely primarily upon hand-coded symbolic domain models and hand-coded heuristic-function generators for efficiency. Learned heuristics for such problems have been of limited utility as they are difficult to apply to problems with objects and object quantities that are significantly different from those in the training data. This paper develops a new approach for learning generalized heuristics in the absence of symbolic domain models using deep neural networks that utilize an input predicate vocabulary but are agnostic to object names and quantities. It uses an abstract state representation to facilitate data efficient, generalizable learning. Empirical evaluation on a range of benchmark domains show that in contrast to prior approaches, generalized heuristics computed by this method can be transferred easily to problems with different objects and with object quantities much larger than those in the training data.