 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
Risk Management for Mitigating Benchmark Failure Modes: BenchRisk
Oct 24, 2025Large language model (LLM) benchmarks inform LLM use decisions (e.g., "is this LLM safe to deploy for my use case and context?"). However, benchmarks may be rendered unreliable by various failure modes that impact benchmark bias, variance, coverage, or people's capacity to understand benchmark evidence. Using the National Institute of Standards and Technology's risk management process as a foundation, this research iteratively analyzed 26 popular benchmarks, identifying 57 potential failure modes and 196 corresponding mitigation strategies. The mitigations reduce failure likelihood and/or severity, providing a frame for evaluating "benchmark risk," which is scored to provide a metaevaluation benchmark: BenchRisk. Higher scores indicate that benchmark users are less likely to reach an incorrect or unsupported conclusion about an LLM. All 26 scored benchmarks present significant risk within one or more of the five scored dimensions (comprehensiveness, intelligibility, consistency, correctness, and longevity), which points to important open research directions for the field of LLM benchmarking. The BenchRisk workflow allows for comparison between benchmarks; as an open-source tool, it also facilitates the identification and sharing of risks and their mitigations.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Structured Model Pruning of Convolutional Networks on Tensor Processing Units
Jul 21, 2021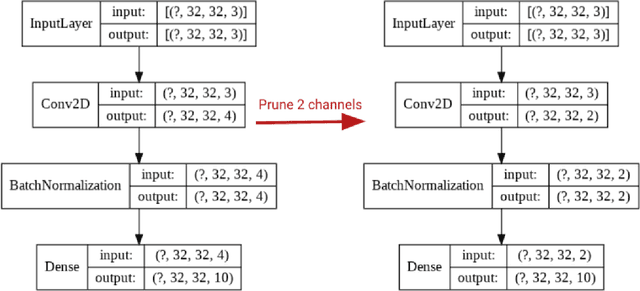
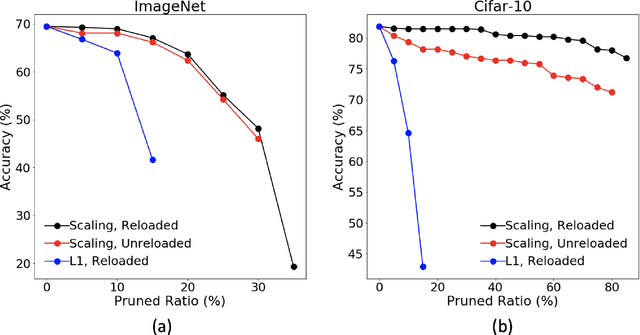
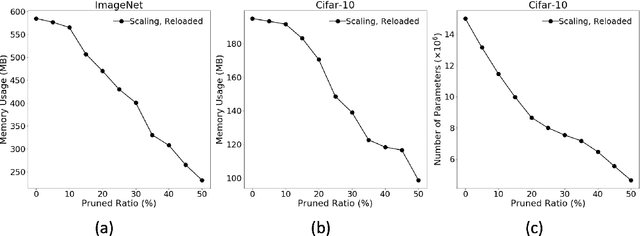
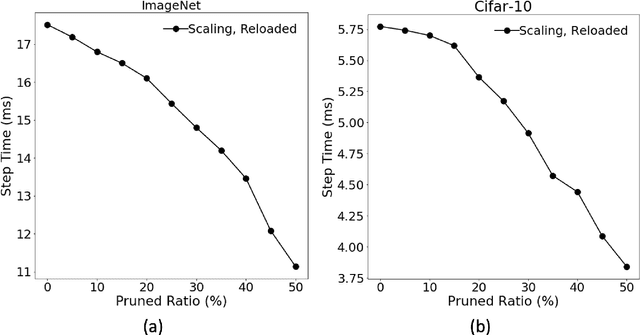
The deployment of convolutional neural networks is often hindered by high computational and storage requirements. Structured model pruning is a promising approach to alleviate these requirements. Using the VGG-16 model as an example, we measure the accuracy-efficiency trade-off for various structured model pruning methods and datasets (CIFAR-10 and ImageNet) on Tensor Processing Units (TPUs). To measure the actual performance of models, we develop a structured model pruning library for TensorFlow2 to modify models in place (instead of adding mask layers). We show that structured model pruning can significantly improve model memory usage and speed on TPUs without losing accuracy, especially for small datasets (e.g., CIFAR-10).