 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Complex Visual Generation via Closed-Loop Verified Reasoning
May 14, 2026Despite rapid advancements, current text-to-image (T2I) models predominantly rely on a single-step generation paradigm, which struggles with complex semantics and faces diminishing returns from parameter scaling. While recent multi-step reasoning approaches show promise, they are hindered by ungrounded planning hallucinations lacking verification, monolithic post-hoc reflection, long-context optimization instabilities, and prohibitive inference latency. To overcome these bottlenecks, we propose the Closed-Loop Visual Reasoning (CLVR) framework, a comprehensive system that deeply couples visual-language logical planning with pixel-level diffusion generation. CLVR introduces an automated data engine with step-level visual verification to synthesize reliable reasoning trajectories, and proposes Proxy Prompt Reinforcement Learning (PPRL) to resolve long-context optimization instabilities by distilling interleaved multimodal histories into explicit reward signals for accurate causal attribution. Furthermore, to mitigate the severe latency bottleneck caused by iterative denoising, we propose $Δ$-Space Weight Merge (DSWM), a theoretically grounded method that fuses alignment weights with off-the-shelf distillation priors, reducing the per-step inference cost to just 4 NFEs without requiring expensive re-distillation. Extensive experiments demonstrate that CLVR outperforms existing open-source baselines across multiple benchmarks and approaches the performance of proprietary commercial models, unlocking general test-time scaling capabilities for complex visual generation.
Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild
Sep 26, 2023



While humans can use parts of their arms other than the hands for manipulations like gathering and supporting, whether robots can effectively learn and perform the same type of operations remains relatively unexplored. As these manipulations require joint-level control to regulate the complete poses of the robots, we develop AirExo, a low-cost, adaptable, and portable dual-arm exoskeleton, for teleoperation and demonstration collection. As collecting teleoperated data is expensive and time-consuming, we further leverage AirExo to collect cheap in-the-wild demonstrations at scale. Under our in-the-wild learning framework, we show that with only 3 minutes of the teleoperated demonstrations, augmented by diverse and extensive in-the-wild data collected by AirExo, robots can learn a policy that is comparable to or even better than one learned from teleoperated demonstrations lasting over 20 minutes. Experiments demonstrate that our approach enables the model to learn a more general and robust policy across the various stages of the task, enhancing the success rates in task completion even with the presence of disturbances. Project website: https://airexo.github.io/
Deep Learning-based Biological Anatomical Landmark Detection in Colonoscopy Videos
Aug 06, 2021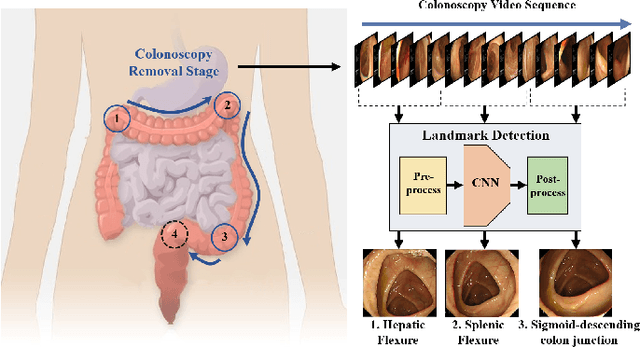
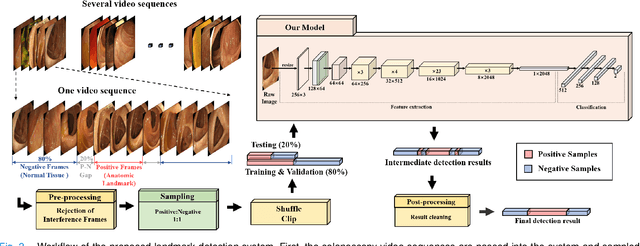
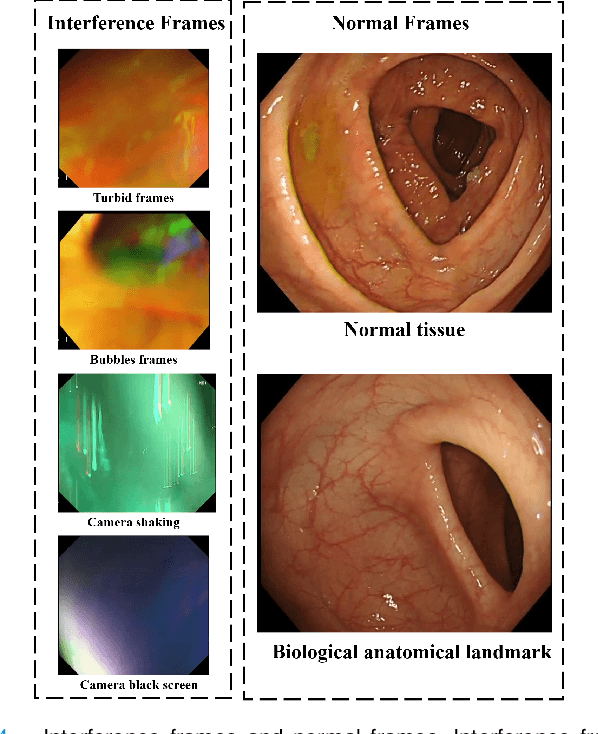
Colonoscopy is a standard imaging tool for visualizing the entire gastrointestinal (GI) tract of patients to capture lesion areas. However, it takes the clinicians excessive time to review a large number of images extracted from colonoscopy videos. Thus, automatic detection of biological anatomical landmarks within the colon is highly demanded, which can help reduce the burden of clinicians by providing guidance information for the locations of lesion areas. In this article, we propose a novel deep learning-based approach to detect biological anatomical landmarks in colonoscopy videos. First, raw colonoscopy video sequences are pre-processed to reject interference frames. Second, a ResNet-101 based network is used to detect three biological anatomical landmarks separately to obtain the intermediate detection results. Third, to achieve more reliable localization of the landmark periods within the whole video period, we propose to post-process the intermediate detection results by identifying the incorrectly predicted frames based on their temporal distribution and reassigning them back to the correct class. Finally, the average detection accuracy reaches 99.75\%. Meanwhile, the average IoU of 0.91 shows a high degree of similarity between our predicted landmark periods and ground truth. The experimental results demonstrate that our proposed model is capable of accurately detecting and localizing biological anatomical landmarks from colonoscopy videos.