 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCumulative Path-Level Semantic Reasoning for Inductive Knowledge Graph Completion
Jan 09, 2026Conventional Knowledge Graph Completion (KGC) methods aim to infer missing information in incomplete Knowledge Graphs (KGs) by leveraging existing information, which struggle to perform effectively in scenarios involving emerging entities. Inductive KGC methods can handle the emerging entities and relations in KGs, offering greater dynamic adaptability. While existing inductive KGC methods have achieved some success, they also face challenges, such as susceptibility to noisy structural information during reasoning and difficulty in capturing long-range dependencies in reasoning paths. To address these challenges, this paper proposes the Cumulative Path-Level Semantic Reasoning for inductive knowledge graph completion (CPSR) framework, which simultaneously captures both the structural and semantic information of KGs to enhance the inductive KGC task. Specifically, the proposed CPSR employs a query-dependent masking module to adaptively mask noisy structural information while retaining important information closely related to the targets. Additionally, CPSR introduces a global semantic scoring module that evaluates both the individual contributions and the collective impact of nodes along the reasoning path within KGs. The experimental results demonstrate that CPSR achieves state-of-the-art performance.
Watch Closely: Mitigating Object Hallucinations in Large Vision-Language Models with Disentangled Decoding
Dec 22, 2025Large Vision-Language Models (LVLMs) bridge the gap between visual and linguistic modalities, demonstrating strong potential across a variety of domains. However, despite significant progress, LVLMs still suffer from severe hallucination issues in object recognition tasks. These models often fail to accurately identify certain objects, leading to text generation that appears fluent but does not correspond to the visual content, which can have serious consequences in real-world applications. Recently, several methods have been proposed to alleviate LVLM hallucinations, but most focus solely on reducing hallucinations in the language modality. To mitigate hallucinations in both the language and visual modalities, we introduce Hallucination Disentangled Decoding (HDD) method that requires no training. HDD enhances the original image by segmenting it and selecting images that augment the original, while also utilizing a blank image to eliminate language prior hallucinations in both the original and segmented images. This design not only reduces the model's dependence on language priors but also enhances its visual performance. (Code: https://github.com/rickeyhhh/Hallucination-Disentangled-Decoding)
CG-SSD: Corner Guided Single Stage 3D Object Detection from LiDAR Point Cloud
Mar 05, 2022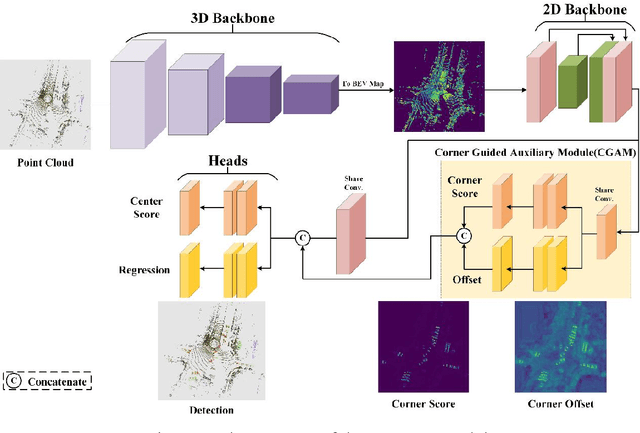
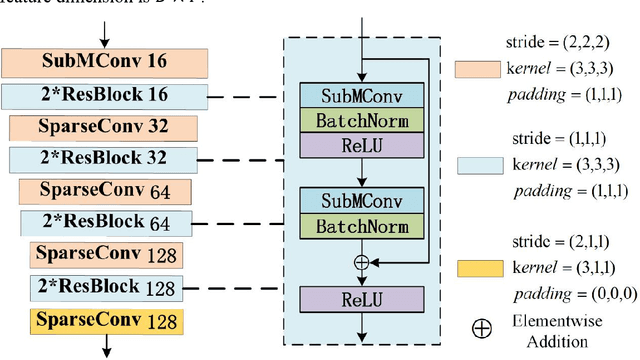
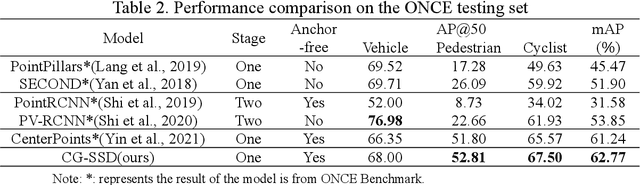
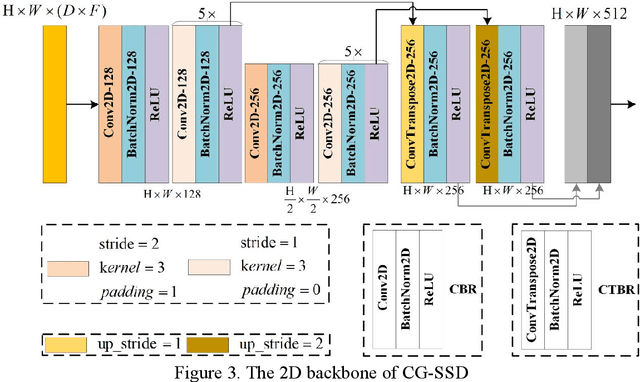
At present, the anchor-based or anchor-free models that use LiDAR point clouds for 3D object detection use the center assigner strategy to infer the 3D bounding boxes. However, in a real world scene, the LiDAR can only acquire a limited object surface point clouds, but the center point of the object does not exist. Obtaining the object by aggregating the incomplete surface point clouds will bring a loss of accuracy in direction and dimension estimation. To address this problem, we propose a corner-guided anchor-free single-stage 3D object detection model (CG-SSD ).Firstly, 3D sparse convolution backbone network composed of residual layers and sub-manifold sparse convolutional layers are used to construct bird's eye view (BEV) features for further deeper feature mining by a lite U-shaped network; Secondly, a novel corner-guided auxiliary module (CGAM) is proposed to incorporate corner supervision signals into the neural network. CGAM is explicitly designed and trained to detect partially visible and invisible corners to obtains a more accurate object feature representation, especially for small or partial occluded objects; Finally, the deep features from both the backbone networks and CGAM module are concatenated and fed into the head module to predict the classification and 3D bounding boxes of the objects in the scene. The experiments demonstrate CG-SSD achieves the state-of-art performance on the ONCE benchmark for supervised 3D object detection using single frame point cloud data, with 62.77%mAP. Additionally, the experiments on ONCE and Waymo Open Dataset show that CGAM can be extended to most anchor-based models which use the BEV feature to detect objects, as a plug-in and bring +1.17%-+14.27%AP improvement.