 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISS++: Image as Stepping Stone for Text-Guided 3D Shape Generation
Mar 24, 2023



In this paper, we present a new text-guided 3D shape generation approach (ISS++) that uses images as a stepping stone to bridge the gap between text and shape modalities for generating 3D shapes without requiring paired text and 3D data. The core of our approach is a two-stage feature-space alignment strategy that leverages a pre-trained single-view reconstruction (SVR) model to map CLIP features to shapes: to begin with, map the CLIP image feature to the detail-rich 3D shape space of the SVR model, then map the CLIP text feature to the 3D shape space through encouraging the CLIP-consistency between rendered images and the input text. Besides, to extend beyond the generative capability of the SVR model, we design a text-guided 3D shape stylization module that can enhance the output shapes with novel structures and textures. Further, we exploit pre-trained text-to-image diffusion models to enhance the generative diversity, fidelity, and stylization capability. Our approach is generic, flexible, and scalable, and it can be easily integrated with various SVR models to expand the generative space and improve the generative fidelity. Extensive experimental results demonstrate that our approach outperforms the state-of-the-art methods in terms of generative quality and consistency with the input text. Codes and models are released at https://github.com/liuzhengzhe/ISS-Image-as-Stepping-Stone-for-Text-Guided-3D-Shape-Generation.
Neural Wavelet-domain Diffusion for 3D Shape Generation, Inversion, and Manipulation
Feb 01, 2023



This paper presents a new approach for 3D shape generation, inversion, and manipulation, through a direct generative modeling on a continuous implicit representation in wavelet domain. Specifically, we propose a compact wavelet representation with a pair of coarse and detail coefficient volumes to implicitly represent 3D shapes via truncated signed distance functions and multi-scale biorthogonal wavelets. Then, we design a pair of neural networks: a diffusion-based generator to produce diverse shapes in the form of the coarse coefficient volumes and a detail predictor to produce compatible detail coefficient volumes for introducing fine structures and details. Further, we may jointly train an encoder network to learn a latent space for inverting shapes, allowing us to enable a rich variety of whole-shape and region-aware shape manipulations. Both quantitative and qualitative experimental results manifest the compelling shape generation, inversion, and manipulation capabilities of our approach over the state-of-the-art methods.
ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation
Sep 22, 2022

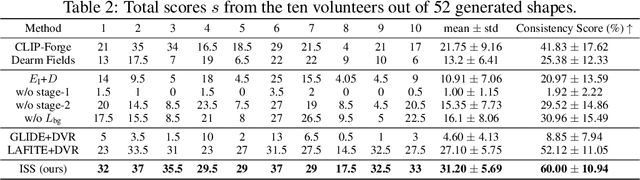

Text-guided 3D shape generation remains challenging due to the absence of large paired text-shape data, the substantial semantic gap between these two modalities, and the structural complexity of 3D shapes. This paper presents a new framework called Image as Stepping Stone (ISS) for the task by introducing 2D image as a stepping stone to connect the two modalities and to eliminate the need for paired text-shape data. Our key contribution is a two-stage feature-space-alignment approach that maps CLIP features to shapes by harnessing a pre-trained single-view reconstruction (SVR) model with multi-view supervisions: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space and optimize the mapping by encouraging CLIP consistency between the input text and the rendered images. Further, we formulate a text-guided shape stylization module to dress up the output shapes with novel textures. Beyond existing works on 3D shape generation from text, our new approach is general for creating shapes in a broad range of categories, without requiring paired text-shape data. Experimental results manifest that our approach outperforms the state-of-the-arts and our baselines in terms of fidelity and consistency with text. Further, our approach can stylize the generated shapes with both realistic and fantasy structures and textures.
Neural Wavelet-domain Diffusion for 3D Shape Generation
Sep 19, 2022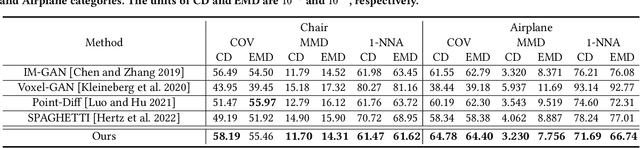
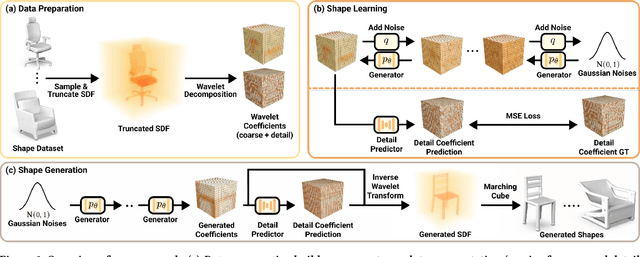
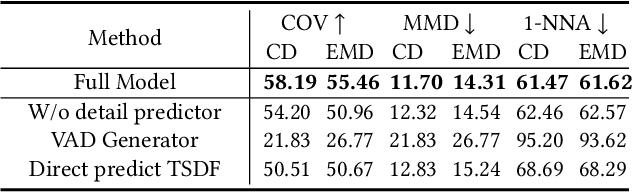

This paper presents a new approach for 3D shape generation, enabling direct generative modeling on a continuous implicit representation in wavelet domain. Specifically, we propose a compact wavelet representation with a pair of coarse and detail coefficient volumes to implicitly represent 3D shapes via truncated signed distance functions and multi-scale biorthogonal wavelets, and formulate a pair of neural networks: a generator based on the diffusion model to produce diverse shapes in the form of coarse coefficient volumes; and a detail predictor to further produce compatible detail coefficient volumes for enriching the generated shapes with fine structures and details. Both quantitative and qualitative experimental results manifest the superiority of our approach in generating diverse and high-quality shapes with complex topology and structures, clean surfaces, and fine details, exceeding the 3D generation capabilities of the state-of-the-art models.
Neural Template: Topology-aware Reconstruction and Disentangled Generation of 3D Meshes
Jun 10, 2022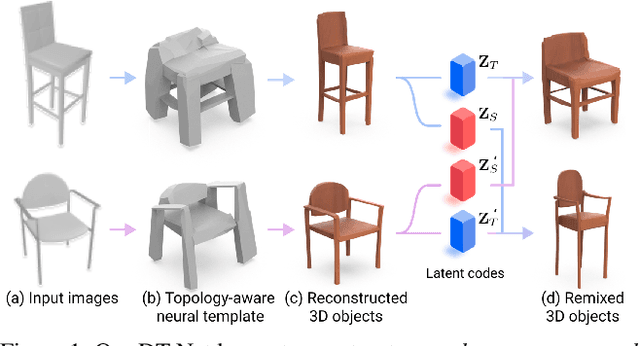
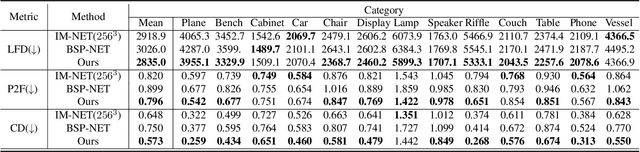
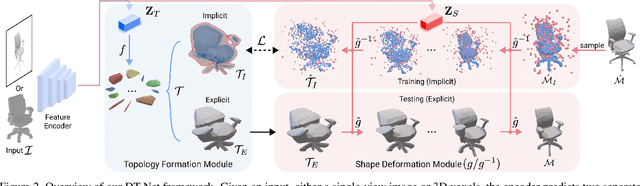
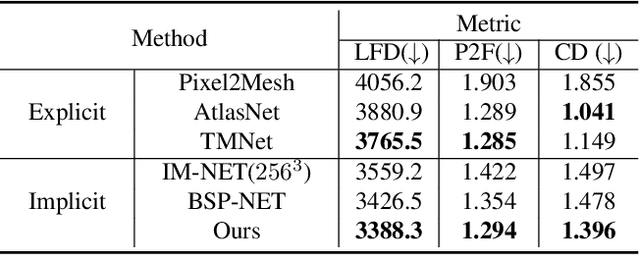
This paper introduces a novel framework called DTNet for 3D mesh reconstruction and generation via Disentangled Topology. Beyond previous works, we learn a topology-aware neural template specific to each input then deform the template to reconstruct a detailed mesh while preserving the learned topology. One key insight is to decouple the complex mesh reconstruction into two sub-tasks: topology formulation and shape deformation. Thanks to the decoupling, DT-Net implicitly learns a disentangled representation for the topology and shape in the latent space. Hence, it can enable novel disentangled controls for supporting various shape generation applications, e.g., remix the topologies of 3D objects, that are not achievable by previous reconstruction works. Extensive experimental results demonstrate that our method is able to produce high-quality meshes, particularly with diverse topologies, as compared with the state-of-the-art methods.
Point Set Self-Embedding
Feb 28, 2022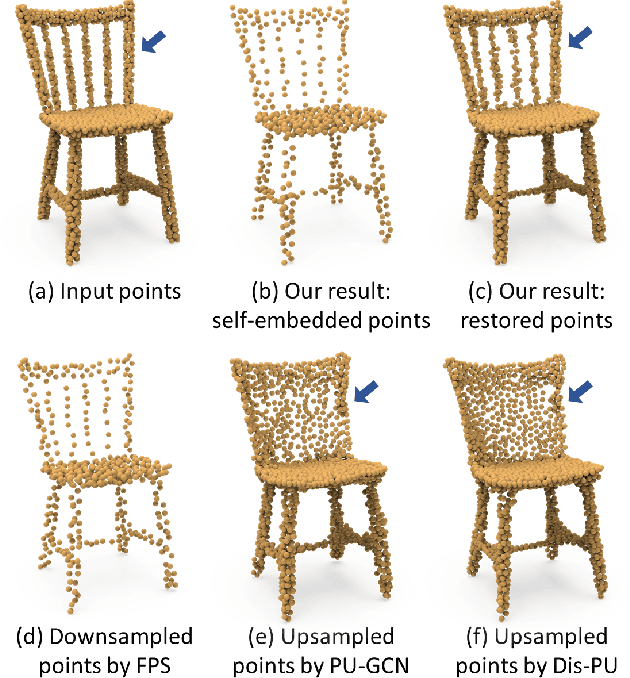
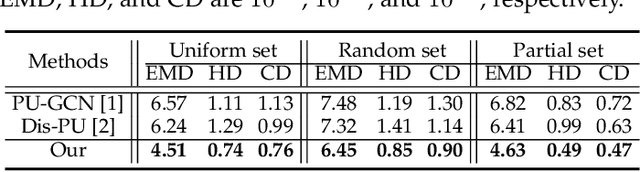


This work presents an innovative method for point set self-embedding, that encodes the structural information of a dense point set into its sparser version in a visual but imperceptible form. The self-embedded point set can function as the ordinary downsampled one and be visualized efficiently on mobile devices. Particularly, we can leverage the self-embedded information to fully restore the original point set for detailed analysis on remote servers. This task is challenging since both the self-embedded point set and the restored point set should resemble the original one. To achieve a learnable self-embedding scheme, we design a novel framework with two jointly-trained networks: one to encode the input point set into its self-embedded sparse point set and the other to leverage the embedded information for inverting the original point set back. Further, we develop a pair of up-shuffle and down-shuffle units in the two networks, and formulate loss terms to encourage the shape similarity and point distribution in the results. Extensive qualitative and quantitative results demonstrate the effectiveness of our method on both synthetic and real-scanned datasets.
PC2-PU: Patch Correlation and Position Correction for Effective Point Cloud Upsampling
Sep 20, 2021
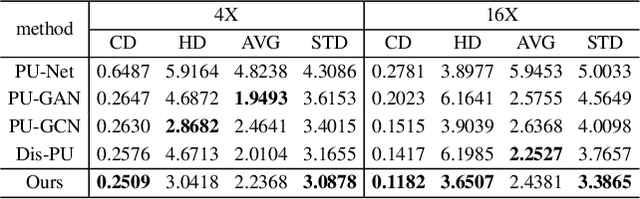

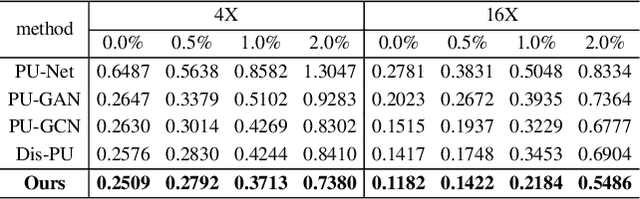
Point cloud upsampling is to densify a sparse point set acquired from 3D sensors, providing a denser representation for underlying surface. However, existing methods perform upsampling on a single patch, ignoring the coherence and relation of the entire surface, thus limiting the upsampled capability. Also, they mainly focus on a clean input, thus the performance is severely compromised when handling scenarios with extra noises. In this paper, we present a novel method for more effective point cloud upsampling, achieving a more robust and improved performance. To this end, we incorporate two thorough considerations. i) Instead of upsampling each small patch independently as previous works, we take adjacent patches as input and introduce a Patch Correlation Unit to explore the shape correspondence between them for effective upsampling. ii)We propose a Position Correction Unit to mitigate the effects of outliers and noisy points. It contains a distance-aware encoder to dynamically adjust the generated points to be close to the underlying surface. Extensive experiments demonstrate that our proposed method surpasses previous upsampling methods on both clean and noisy inputs.
SP-GAN: Sphere-Guided 3D Shape Generation and Manipulation
Aug 10, 2021
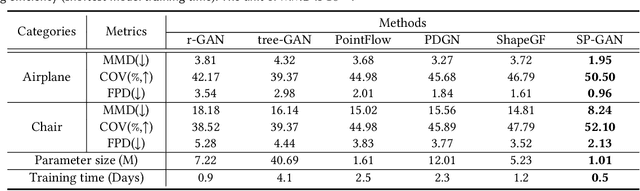
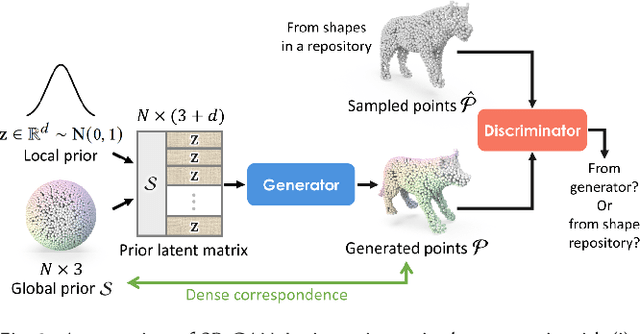
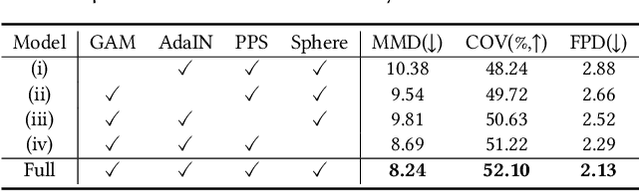
We present SP-GAN, a new unsupervised sphere-guided generative model for direct synthesis of 3D shapes in the form of point clouds. Compared with existing models, SP-GAN is able to synthesize diverse and high-quality shapes with fine details and promote controllability for part-aware shape generation and manipulation, yet trainable without any parts annotations. In SP-GAN, we incorporate a global prior (uniform points on a sphere) to spatially guide the generative process and attach a local prior (a random latent code) to each sphere point to provide local details. The key insight in our design is to disentangle the complex 3D shape generation task into a global shape modeling and a local structure adjustment, to ease the learning process and enhance the shape generation quality. Also, our model forms an implicit dense correspondence between the sphere points and points in every generated shape, enabling various forms of structure-aware shape manipulations such as part editing, part-wise shape interpolation, and multi-shape part composition, etc., beyond the existing generative models. Experimental results, which include both visual and quantitative evaluations, demonstrate that our model is able to synthesize diverse point clouds with fine details and less noise, as compared with the state-of-the-art models.
* SIGGRAPH 2021, website https://liruihui.github.io/publication/SP-GAN/
Point Cloud Upsampling via Disentangled Refinement
Jun 09, 2021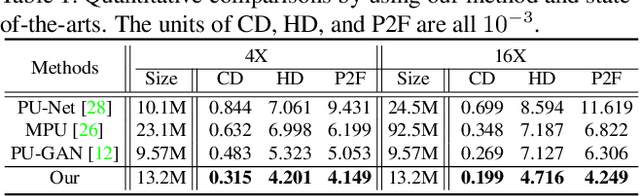
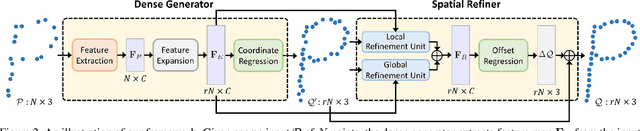
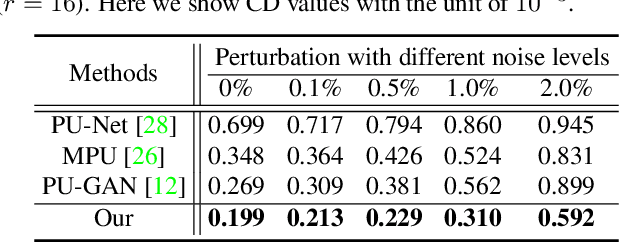
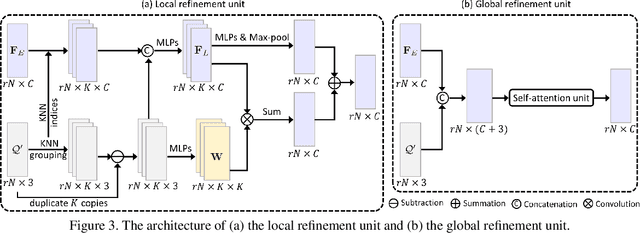
Point clouds produced by 3D scanning are often sparse, non-uniform, and noisy. Recent upsampling approaches aim to generate a dense point set, while achieving both distribution uniformity and proximity-to-surface, and possibly amending small holes, all in a single network. After revisiting the task, we propose to disentangle the task based on its multi-objective nature and formulate two cascaded sub-networks, a dense generator and a spatial refiner. The dense generator infers a coarse but dense output that roughly describes the underlying surface, while the spatial refiner further fine-tunes the coarse output by adjusting the location of each point. Specifically, we design a pair of local and global refinement units in the spatial refiner to evolve a coarse feature map. Also, in the spatial refiner, we regress a per-point offset vector to further adjust the coarse outputs in fine-scale. Extensive qualitative and quantitative results on both synthetic and real-scanned datasets demonstrate the superiority of our method over the state-of-the-arts.
PointAugment: an Auto-Augmentation Framework for Point Cloud Classification
Mar 20, 2020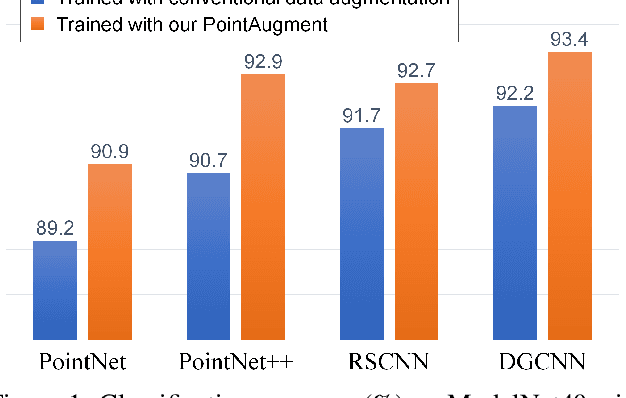
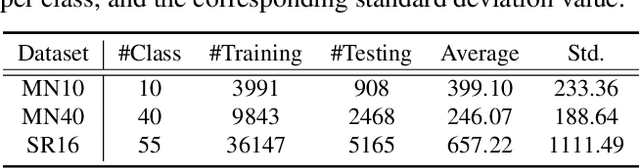
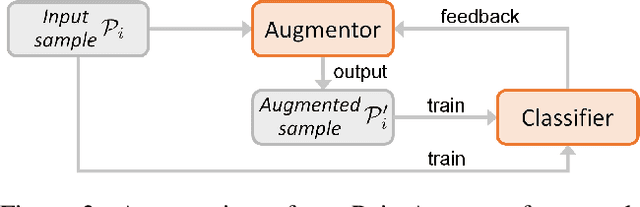
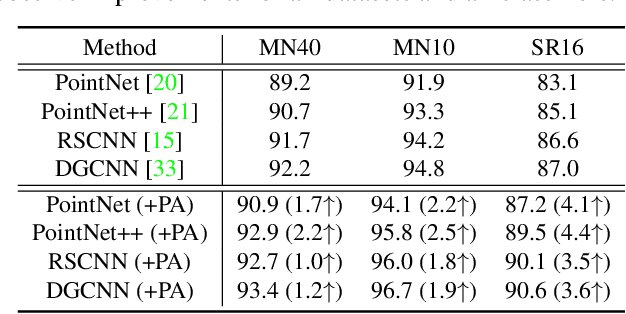
We present PointAugment, a new auto-augmentation framework that automatically optimizes and augments point cloud samples to enrich the data diversity when we train a classification network. Different from existing auto-augmentation methods for 2D images, PointAugment is sample-aware and takes an adversarial learning strategy to jointly optimize an augmentor network and a classifier network, such that the augmentor can learn to produce augmented samples that best fit the classifier. Moreover, we formulate a learnable point augmentation function with a shape-wise transformation and a point-wise displacement, and carefully design loss functions to adopt the augmented samples based on the learning progress of the classifier. Extensive experiments also confirm PointAugment's effectiveness and robustness to improve the performance of various networks on shape classification and retrieval.