 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASE: Graph Attention Sampling with Edges Fusion for Solving Vehicle Routing Problems
May 21, 2024



Learning-based methods have become increasingly popular for solving vehicle routing problems due to their near-optimal performance and fast inference speed. Among them, the combination of deep reinforcement learning and graph representation allows for the abstraction of node topology structures and features in an encoder-decoder style. Such an approach makes it possible to solve routing problems end-to-end without needing complicated heuristic operators designed by domain experts. Existing research studies have been focusing on novel encoding and decoding structures via various neural network models to enhance the node embedding representation. Despite the sophisticated approaches applied, there is a noticeable lack of consideration for the graph-theoretic properties inherent to routing problems. Moreover, the potential ramifications of inter-nodal interactions on the decision-making efficacy of the models have not been adequately explored. To bridge this gap, we propose an adaptive Graph Attention Sampling with the Edges Fusion framework (GASE),where nodes' embedding is determined through attention calculation from certain highly correlated neighbourhoods and edges, utilizing a filtered adjacency matrix. In detail, the selections of particular neighbours and adjacency edges are led by a multi-head attention mechanism, contributing directly to the message passing and node embedding in graph attention sampling networks. Furthermore, we incorporate an adaptive actor-critic algorithm with policy improvements to expedite the training convergence. We then conduct comprehensive experiments against baseline methods on learning-based VRP tasks from different perspectives. Our proposed model outperforms the existing methods by 2.08\%-6.23\% and shows stronger generalization ability, achieving state-of-the-art performance on randomly generated instances and real-world datasets.
Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery
Dec 23, 2023Object detection in aerial imagery presents a significant challenge due to large scale variations among objects. This paper proposes an evolutionary reinforcement learning agent, integrated within a coarse-to-fine object detection framework, to optimize the scale for more effective detection of objects in such images. Specifically, a set of patches potentially containing objects are first generated. A set of rewards measuring the localization accuracy, the accuracy of predicted labels, and the scale consistency among nearby patches are designed in the agent to guide the scale optimization. The proposed scale-consistency reward ensures similar scales for neighboring objects of the same category. Furthermore, a spatial-semantic attention mechanism is designed to exploit the spatial semantic relations between patches. The agent employs the proximal policy optimization strategy in conjunction with the evolutionary strategy, effectively utilizing both the current patch status and historical experience embedded in the agent. The proposed model is compared with state-of-the-art methods on two benchmark datasets for object detection on drone imagery. It significantly outperforms all the compared methods.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Dec 05, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
Mask Attack Detection Using Vascular-weighted Motion-robust rPPG Signals
May 25, 2023Detecting 3D mask attacks to a face recognition system is challenging. Although genuine faces and 3D face masks show significantly different remote photoplethysmography (rPPG) signals, rPPG-based face anti-spoofing methods often suffer from performance degradation due to unstable face alignment in the video sequence and weak rPPG signals. To enhance the rPPG signal in a motion-robust way, a landmark-anchored face stitching method is proposed to align the faces robustly and precisely at the pixel-wise level by using both SIFT keypoints and facial landmarks. To better encode the rPPG signal, a weighted spatial-temporal representation is proposed, which emphasizes the face regions with rich blood vessels. In addition, characteristics of rPPG signals in different color spaces are jointly utilized. To improve the generalization capability, a lightweight EfficientNet with a Gated Recurrent Unit (GRU) is designed to extract both spatial and temporal features from the rPPG spatial-temporal representation for classification. The proposed method is compared with the state-of-the-art methods on five benchmark datasets under both intra-dataset and cross-dataset evaluations. The proposed method shows a significant and consistent improvement in performance over other state-of-the-art rPPG-based methods for face spoofing detection.
Boosting the Discriminant Power of Naive Bayes
Sep 20, 2022



Naive Bayes has been widely used in many applications because of its simplicity and ability in handling both numerical data and categorical data. However, lack of modeling of correlations between features limits its performance. In addition, noise and outliers in the real-world dataset also greatly degrade the classification performance. In this paper, we propose a feature augmentation method employing a stack auto-encoder to reduce the noise in the data and boost the discriminant power of naive Bayes. The proposed stack auto-encoder consists of two auto-encoders for different purposes. The first encoder shrinks the initial features to derive a compact feature representation in order to remove the noise and redundant information. The second encoder boosts the discriminant power of the features by expanding them into a higher-dimensional space so that different classes of samples could be better separated in the higher-dimensional space. By integrating the proposed feature augmentation method with the regularized naive Bayes, the discrimination power of the model is greatly enhanced. The proposed method is evaluated on a set of machine-learning benchmark datasets. The experimental results show that the proposed method significantly and consistently outperforms the state-of-the-art naive Bayes classifiers.
A Max-relevance-min-divergence Criterion for Data Discretization with Applications on Naive Bayes
Sep 20, 2022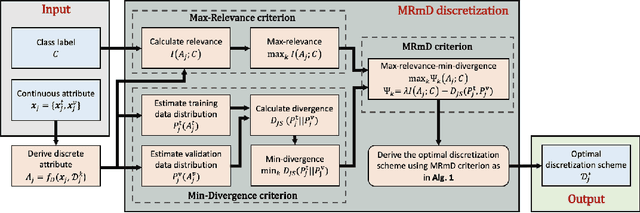
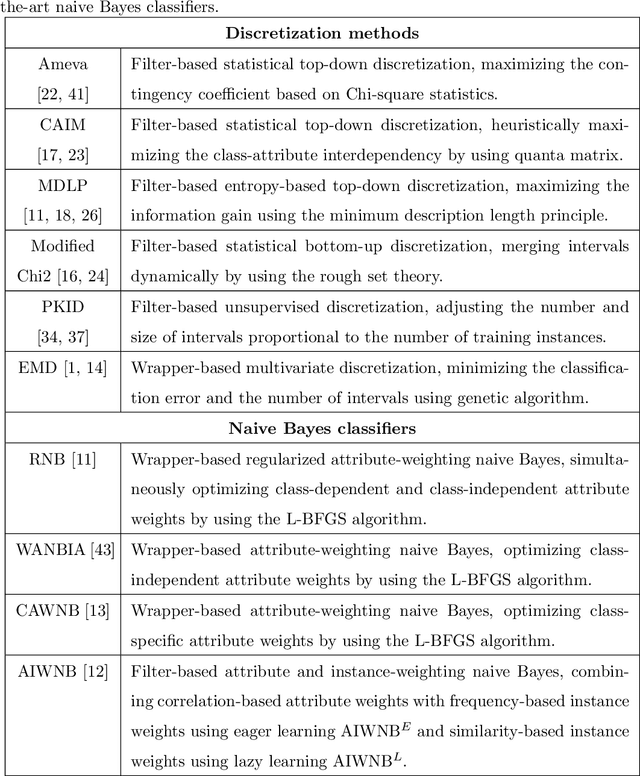
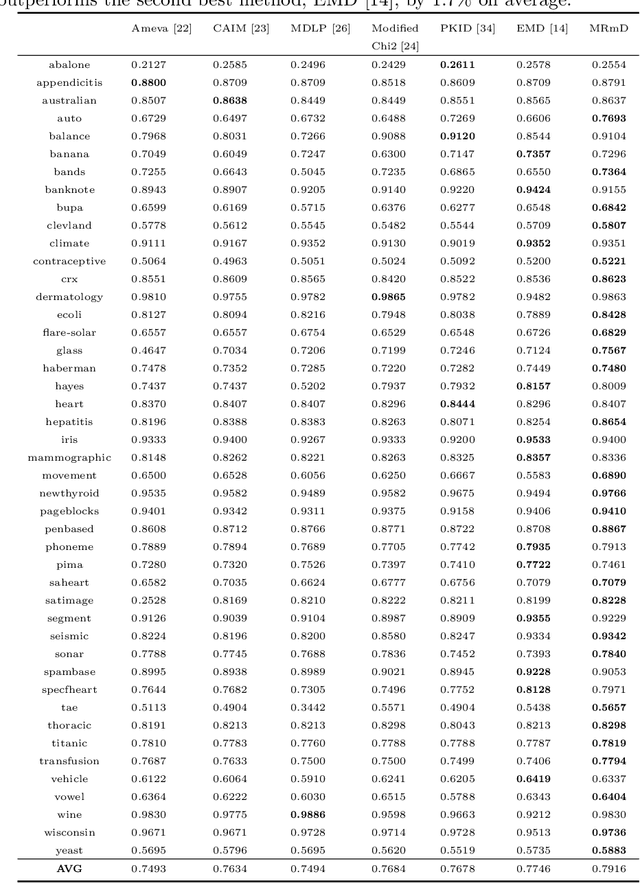
In many classification models, data is discretized to better estimate its distribution. Existing discretization methods often target at maximizing the discriminant power of discretized data, while overlooking the fact that the primary target of data discretization in classification is to improve the generalization performance. As a result, the data tend to be over-split into many small bins since the data without discretization retain the maximal discriminant information. Thus, we propose a Max-Dependency-Min-Divergence (MDmD) criterion that maximizes both the discriminant information and generalization ability of the discretized data. More specifically, the Max-Dependency criterion maximizes the statistical dependency between the discretized data and the classification variable while the Min-Divergence criterion explicitly minimizes the JS-divergence between the training data and the validation data for a given discretization scheme. The proposed MDmD criterion is technically appealing, but it is difficult to reliably estimate the high-order joint distributions of attributes and the classification variable. We hence further propose a more practical solution, Max-Relevance-Min-Divergence (MRmD) discretization scheme, where each attribute is discretized separately, by simultaneously maximizing the discriminant information and the generalization ability of the discretized data. The proposed MRmD is compared with the state-of-the-art discretization algorithms under the naive Bayes classification framework on 45 machine-learning benchmark datasets. It significantly outperforms all the compared methods on most of the datasets.
One-shot Visual Reasoning on RPMs with an Application to Video Frame Prediction
Nov 24, 2021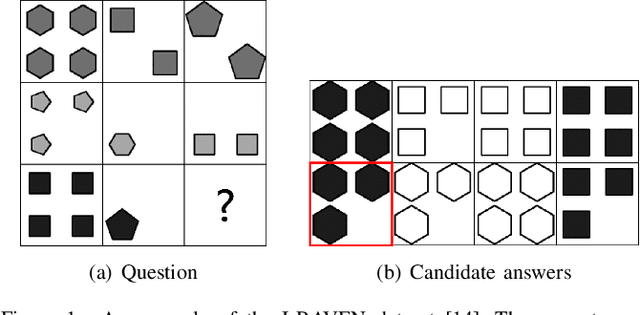
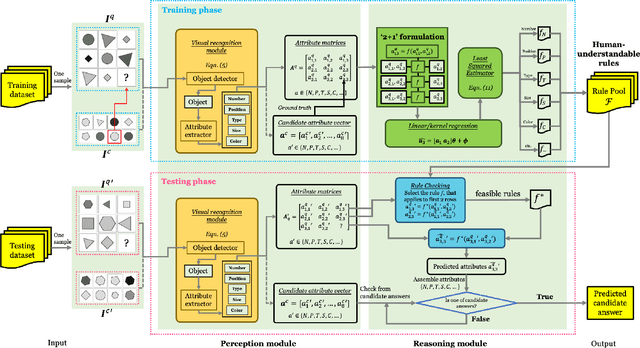

Raven's Progressive Matrices (RPMs) are frequently used in evaluating human's visual reasoning ability. Researchers have made considerable effort in developing a system which could automatically solve the RPM problem, often through a black-box end-to-end Convolutional Neural Network (CNN) for both visual recognition and logical reasoning tasks. Towards the objective of developing a highly explainable solution, we propose a One-shot Human-Understandable ReaSoner (Os-HURS), which is a two-step framework including a perception module and a reasoning module, to tackle the challenges of real-world visual recognition and subsequent logical reasoning tasks, respectively. For the reasoning module, we propose a "2+1" formulation that can be better understood by humans and significantly reduces the model complexity. As a result, a precise reasoning rule can be deduced from one RPM sample only, which is not feasible for existing solution methods. The proposed reasoning module is also capable of yielding a set of reasoning rules, precisely modeling the human knowledge in solving the RPM problem. To validate the proposed method on real-world applications, an RPM-like One-shot Frame-prediction (ROF) dataset is constructed, where visual reasoning is conducted on RPMs constructed using real-world video frames instead of synthetic images. Experimental results on various RPM-like datasets demonstrate that the proposed Os-HURS achieves a significant and consistent performance gain compared with the state-of-the-art models.
A Semi-Supervised Adaptive Discriminative Discretization Method Improving Discrimination Power of Regularized Naive Bayes
Nov 22, 2021



Recently, many improved naive Bayes methods have been developed with enhanced discrimination capabilities. Among them, regularized naive Bayes (RNB) produces excellent performance by balancing the discrimination power and generalization capability. Data discretization is important in naive Bayes. By grouping similar values into one interval, the data distribution could be better estimated. However, existing methods including RNB often discretize the data into too few intervals, which may result in a significant information loss. To address this problem, we propose a semi-supervised adaptive discriminative discretization framework for naive Bayes, which could better estimate the data distribution by utilizing both labeled data and unlabeled data through pseudo-labeling techniques. The proposed method also significantly reduces the information loss during discretization by utilizing an adaptive discriminative discretization scheme, and hence greatly improves the discrimination power of classifiers. The proposed RNB+, i.e., regularized naive Bayes utilizing the proposed discretization framework, is systematically evaluated on a wide range of machine-learning datasets. It significantly and consistently outperforms state-of-the-art NB classifiers.
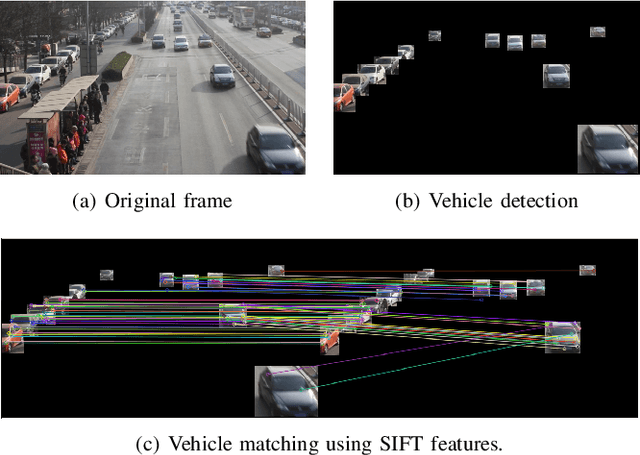
Spatio-temporal Parking Behaviour Forecasting and Analysis Before and During COVID-19
Aug 15, 2021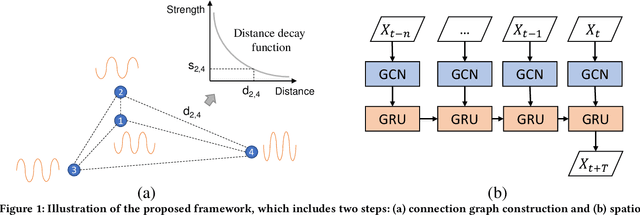

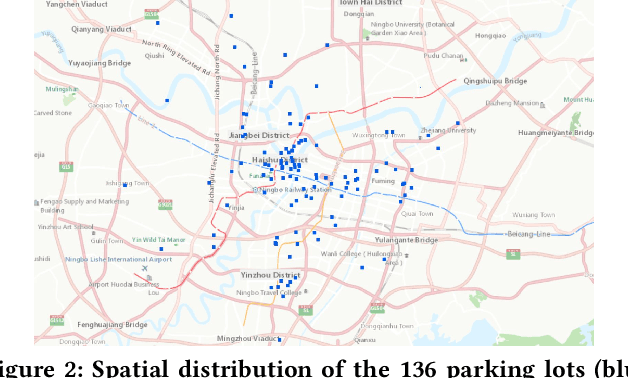

Parking demand forecasting and behaviour analysis have received increasing attention in recent years because of their critical role in mitigating traffic congestion and understanding travel behaviours. However, previous studies usually only consider temporal dependence but ignore the spatial correlations among parking lots for parking prediction. This is mainly due to the lack of direct physical connections or observable interactions between them. Thus, how to quantify the spatial correlation remains a significant challenge. To bridge the gap, in this study, we propose a spatial-aware parking prediction framework, which includes two steps, i.e. spatial connection graph construction and spatio-temporal forecasting. A case study in Ningbo, China is conducted using parking data of over one million records before and during COVID-19. The results show that the approach is superior on parking occupancy forecasting than baseline methods, especially for the cases with high temporal irregularity such as during COVID-19. Our work has revealed the impact of the pandemic on parking behaviour and also accentuated the importance of modelling spatial dependence in parking behaviour forecasting, which can benefit future studies on epidemiology and human travel behaviours.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021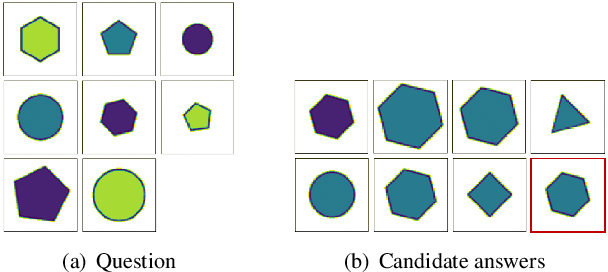

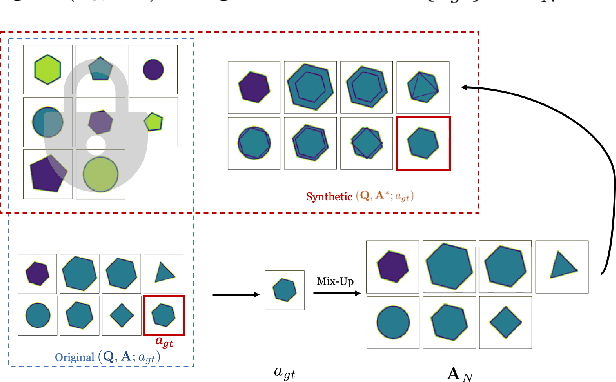
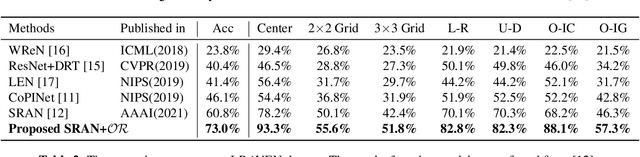
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.