 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-based R-CNNs for Fine-grained Category Detection
Jul 15, 2014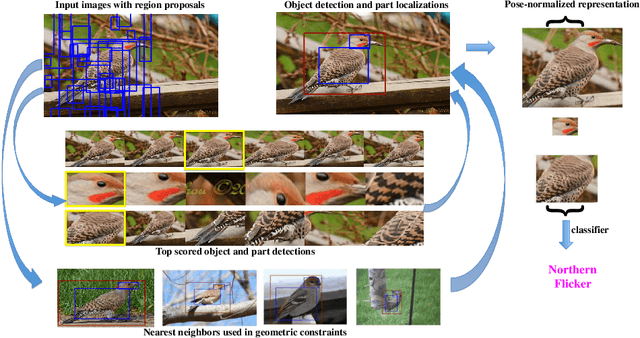
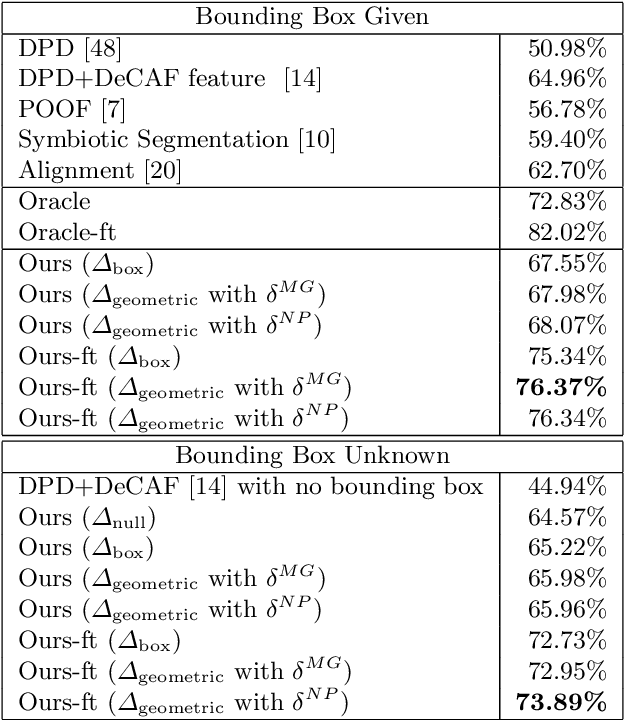

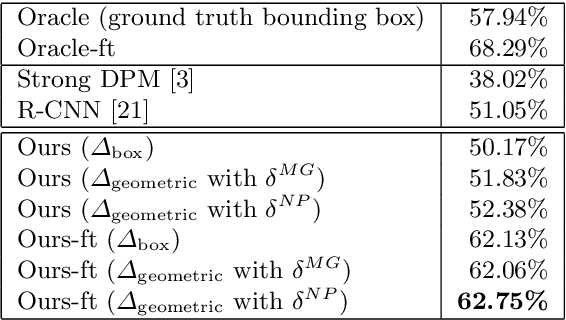
Semantic part localization can facilitate fine-grained categorization by explicitly isolating subtle appearance differences associated with specific object parts. Methods for pose-normalized representations have been proposed, but generally presume bounding box annotations at test time due to the difficulty of object detection. We propose a model for fine-grained categorization that overcomes these limitations by leveraging deep convolutional features computed on bottom-up region proposals. Our method learns whole-object and part detectors, enforces learned geometric constraints between them, and predicts a fine-grained category from a pose-normalized representation. Experiments on the Caltech-UCSD bird dataset confirm that our method outperforms state-of-the-art fine-grained categorization methods in an end-to-end evaluation without requiring a bounding box at test time.
Simultaneous Detection and Segmentation
Jul 07, 2014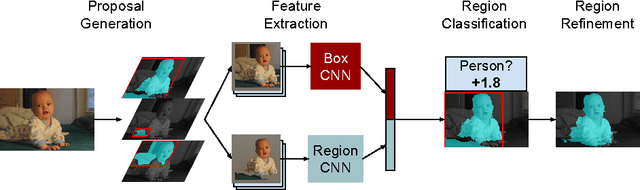
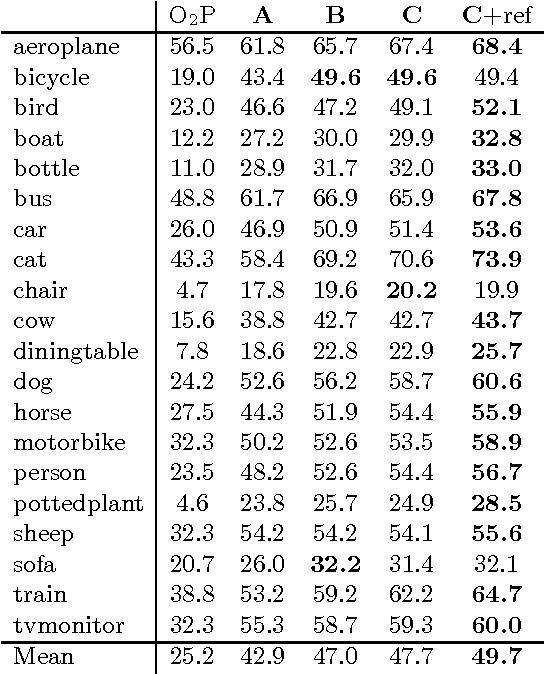
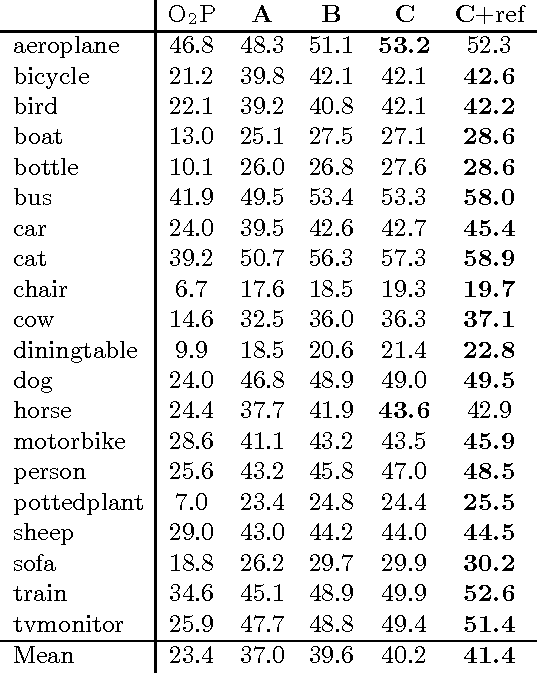
We aim to detect all instances of a category in an image and, for each instance, mark the pixels that belong to it. We call this task Simultaneous Detection and Segmentation (SDS). Unlike classical bounding box detection, SDS requires a segmentation and not just a box. Unlike classical semantic segmentation, we require individual object instances. We build on recent work that uses convolutional neural networks to classify category-independent region proposals (R-CNN [16]), introducing a novel architecture tailored for SDS. We then use category-specific, top- down figure-ground predictions to refine our bottom-up proposals. We show a 7 point boost (16% relative) over our baselines on SDS, a 5 point boost (10% relative) over state-of-the-art on semantic segmentation, and state-of-the-art performance in object detection. Finally, we provide diagnostic tools that unpack performance and provide directions for future work.
Caffe: Convolutional Architecture for Fast Feature Embedding
Jun 20, 2014

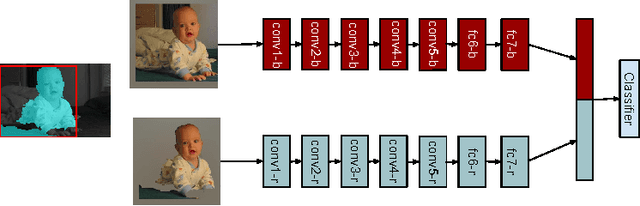
Caffe provides multimedia scientists and practitioners with a clean and modifiable framework for state-of-the-art deep learning algorithms and a collection of reference models. The framework is a BSD-licensed C++ library with Python and MATLAB bindings for training and deploying general-purpose convolutional neural networks and other deep models efficiently on commodity architectures. Caffe fits industry and internet-scale media needs by CUDA GPU computation, processing over 40 million images a day on a single K40 or Titan GPU ($\approx$ 2.5 ms per image). By separating model representation from actual implementation, Caffe allows experimentation and seamless switching among platforms for ease of development and deployment from prototyping machines to cloud environments. Caffe is maintained and developed by the Berkeley Vision and Learning Center (BVLC) with the help of an active community of contributors on GitHub. It powers ongoing research projects, large-scale industrial applications, and startup prototypes in vision, speech, and multimedia.
R-CNNs for Pose Estimation and Action Detection
Jun 19, 2014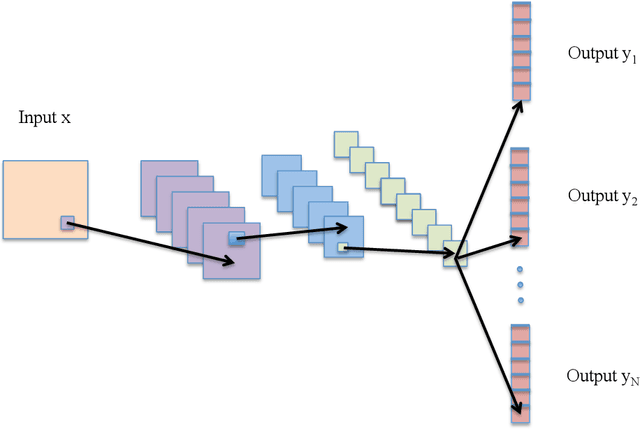



We present convolutional neural networks for the tasks of keypoint (pose) prediction and action classification of people in unconstrained images. Our approach involves training an R-CNN detector with loss functions depending on the task being tackled. We evaluate our method on the challenging PASCAL VOC dataset and compare it to previous leading approaches. Our method gives state-of-the-art results for keypoint and action prediction. Additionally, we introduce a new dataset for action detection, the task of simultaneously localizing people and classifying their actions, and present results using our approach.
On learning to localize objects with minimal supervision
May 15, 2014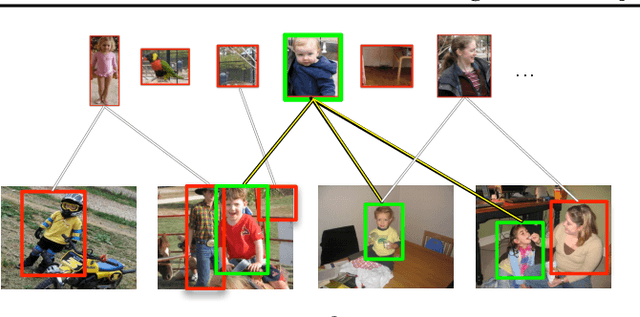
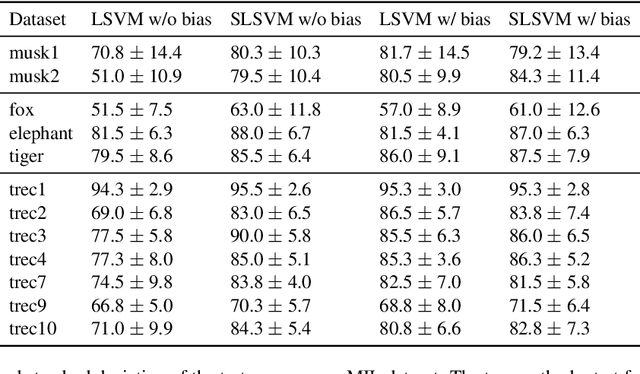
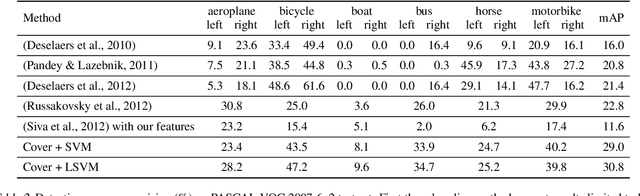
Learning to localize objects with minimal supervision is an important problem in computer vision, since large fully annotated datasets are extremely costly to obtain. In this paper, we propose a new method that achieves this goal with only image-level labels of whether the objects are present or not. Our approach combines a discriminative submodular cover problem for automatically discovering a set of positive object windows with a smoothed latent SVM formulation. The latter allows us to leverage efficient quasi-Newton optimization techniques. Our experiments demonstrate that the proposed approach provides a 50% relative improvement in mean average precision over the current state-of-the-art on PASCAL VOC 2007 detection.
DenseNet: Implementing Efficient ConvNet Descriptor Pyramids
Apr 07, 2014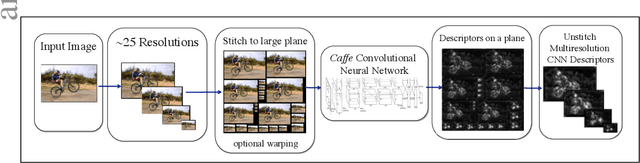
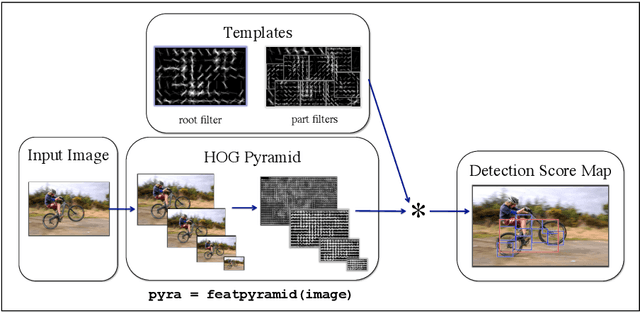
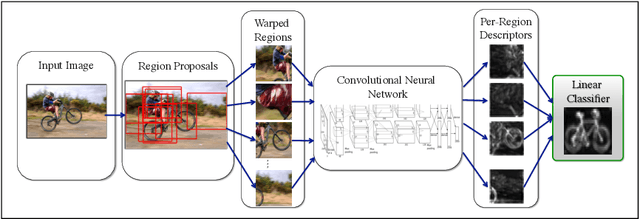
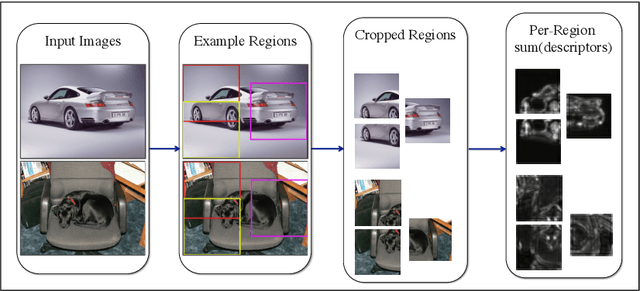
Convolutional Neural Networks (CNNs) can provide accurate object classification. They can be extended to perform object detection by iterating over dense or selected proposed object regions. However, the runtime of such detectors scales as the total number and/or area of regions to examine per image, and training such detectors may be prohibitively slow. However, for some CNN classifier topologies, it is possible to share significant work among overlapping regions to be classified. This paper presents DenseNet, an open source system that computes dense, multiscale features from the convolutional layers of a CNN based object classifier. Future work will involve training efficient object detectors with DenseNet feature descriptors.