 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
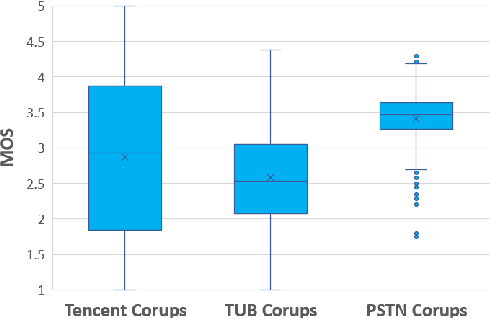

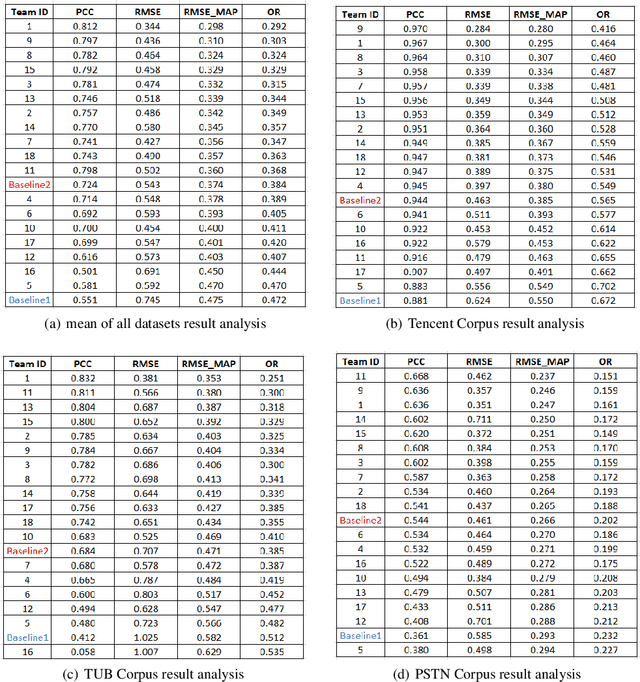
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.
ICASSP 2022 Acoustic Echo Cancellation Challenge
Feb 27, 2022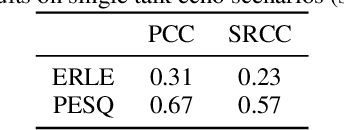
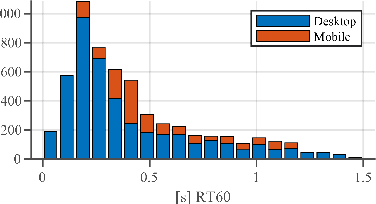
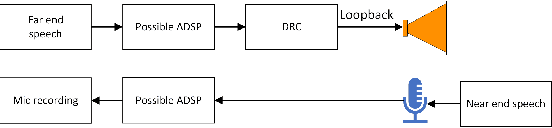

The ICASSP 2022 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and still a top issue in audio communication. This is the third AEC challenge and it is enhanced by including mobile scenarios, adding speech recognition rate in the challenge goal metrics, and making the default sample rate 48 kHz. In this challenge, we open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We also open source an online subjective test framework and provide an online objective metric service for researchers to quickly test their results. The winners of this challenge are selected based on the average Mean Opinion Score achieved across all different single talk and double talk scenarios, and the speech recognition word acceptance rate.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.
Aura: Privacy-preserving augmentation to improve test set diversity in noise suppression applications
Oct 08, 2021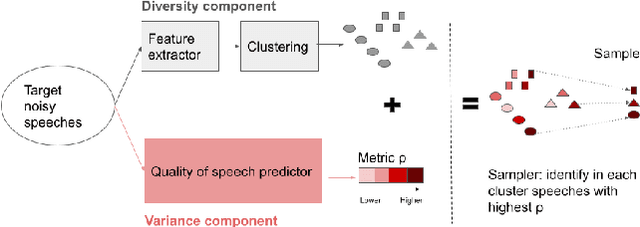
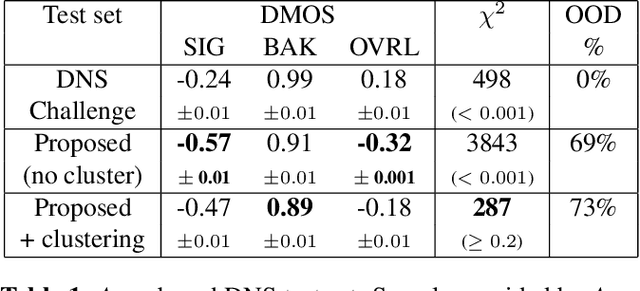
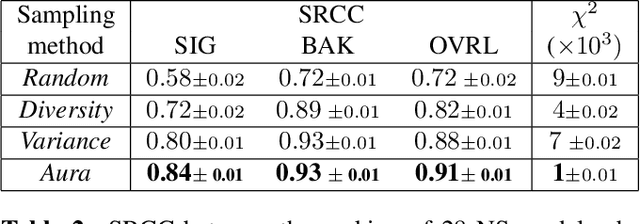
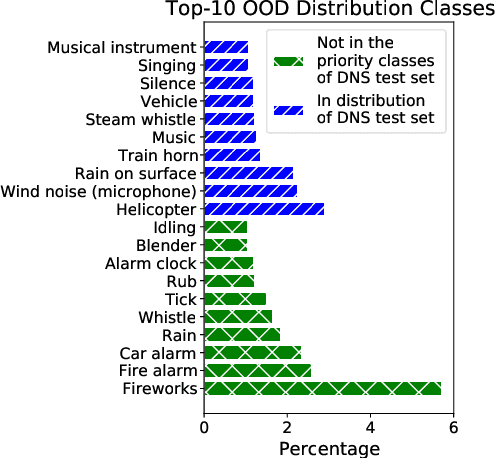
Noise suppression models running in production environments are commonly trained on publicly available datasets. However, this approach leads to regressions in production environments due to the lack of training/testing on representative customer data. Moreover, due to privacy reasons, developers cannot listen to customer content. This `ears-off' situation motivates augmenting existing datasets in a privacy-preserving manner. In this paper, we present Aura, a solution to make existing noise suppression test sets more challenging and diverse while limiting the sampling budget. Aura is `ears-off' because it relies on a feature extractor and a metric of speech quality, DNSMOS P.835, both pre-trained on data obtained from public sources. As an application of \aura, we augment a current benchmark test set in noise suppression by sampling audio files from a new batch of data of 20K clean speech clips from Librivox mixed with noise clips obtained from AudioSet. Aura makes the existing benchmark test set harder by 100% in DNSMOS P.835, a 26 improvement in Spearman's rank correlation coefficient (SRCC) compared to random sampling and, identifies 73% out-of-distribution samples to augment the test set.
Performance optimizations on deep noise suppression models
Oct 08, 2021
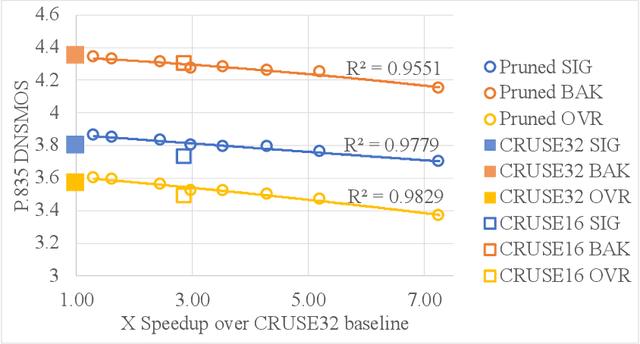
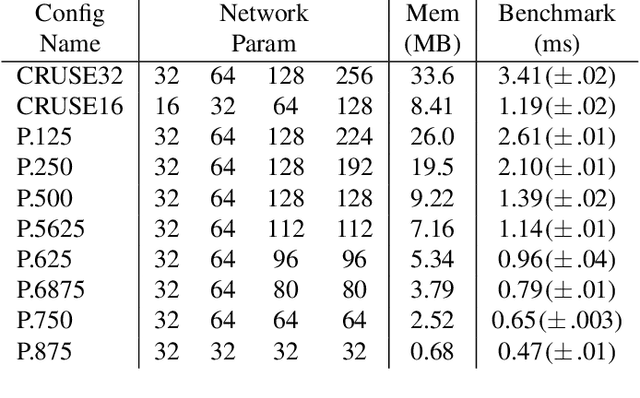
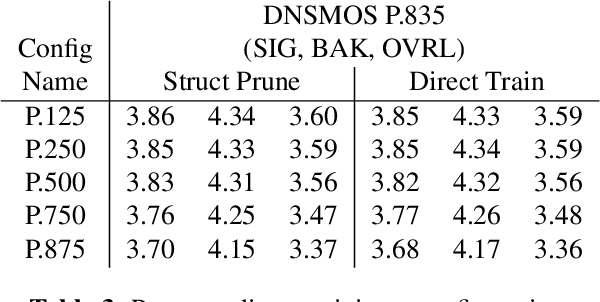
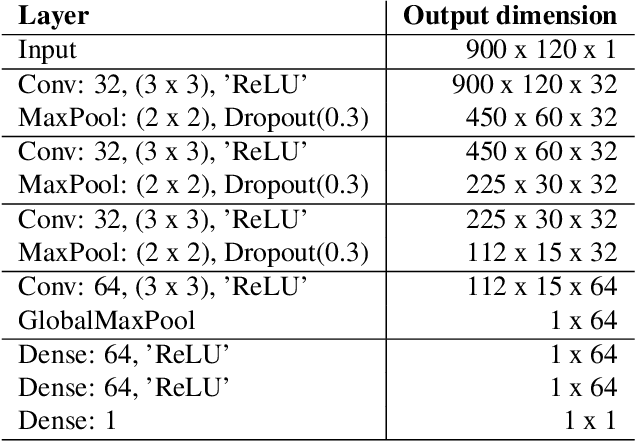
We study the role of magnitude structured pruning as an architecture search to speed up the inference time of a deep noise suppression (DNS) model. While deep learning approaches have been remarkably successful in enhancing audio quality, their increased complexity inhibits their deployment in real-time applications. We achieve up to a 7.25X inference speedup over the baseline, with a smooth model performance degradation. Ablation studies indicate that our proposed network re-parameterization (i.e., size per layer) is the major driver of the speedup, and that magnitude structured pruning does comparably to directly training a model in the smaller size. We report inference speed because a parameter reduction does not necessitate speedup, and we measure model quality using an accurate non-intrusive objective speech quality metric.
DNSMOS P.835: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors
Oct 08, 2021
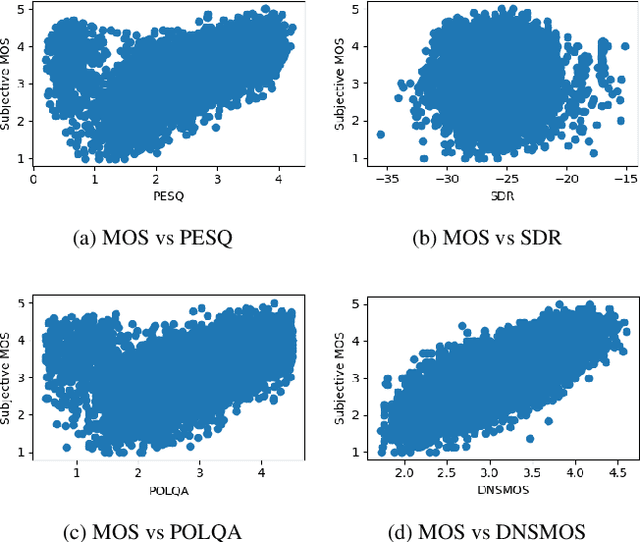
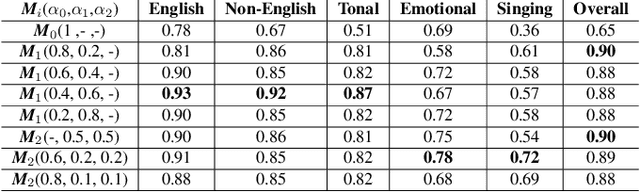
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. We have recently developed a non-intrusive speech quality metric called Deep Noise Suppression Mean Opinion Score (DNSMOS) using the scores from ITU-T Rec. P.808 subjective evaluation. The P.808 scores reflect the overall quality of the audio clip. ITU-T Rec. P.835 subjective evaluation framework gives the standalone quality scores of speech and background noise in addition to the overall quality. In this work, we train an objective metric based on P.835 human ratings that outputs 3 scores: i) speech quality (SIG), ii) background noise quality (BAK), and iii) the overall quality (OVRL) of the audio. The developed metric is highly correlated with human ratings, with a Pearson's Correlation Coefficient (PCC)=0.94 for SIG and PCC=0.98 for BAK and OVRL. This is the first non-intrusive P.835 predictor we are aware of. DNSMOS P.835 is made publicly available as an Azure service.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021
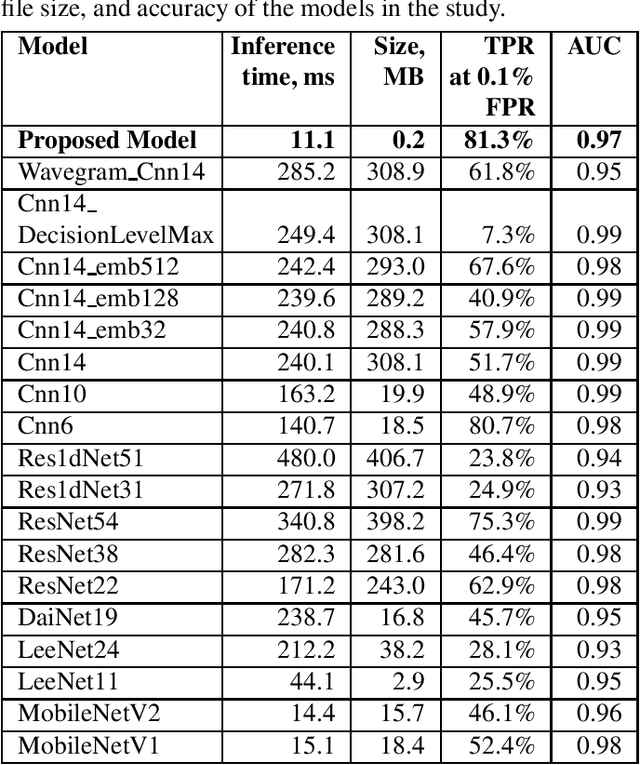
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
AECMOS: A speech quality assessment metric for echo impairment
Oct 08, 2021
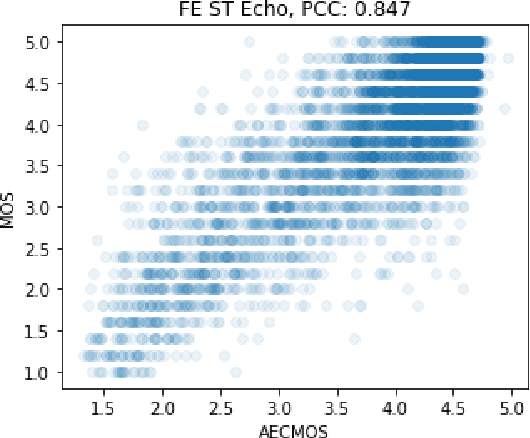
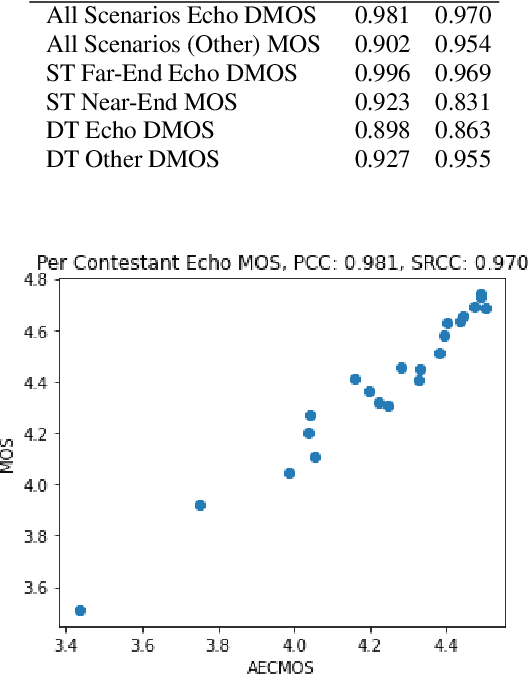
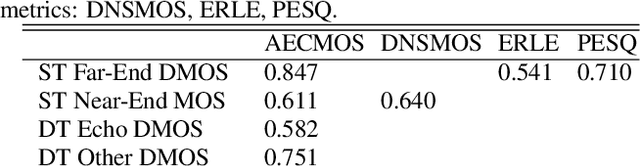
Traditionally, the quality of acoustic echo cancellers is evaluated using intrusive speech quality assessment measures such as ERLE \cite{g168} and PESQ \cite{p862}, or by carrying out subjective laboratory tests. Unfortunately, the former are not well correlated with human subjective measures, while the latter are time and resource consuming to carry out. We provide a new tool for speech quality assessment for echo impairment which can be used to evaluate the performance of acoustic echo cancellers. More precisely, we develop a neural network model to evaluate call quality degradations in two separate categories: echo and degradations from other sources. We show that our model is accurate as measured by correlation with human subjective quality ratings. Our tool can be used effectively to stack rank echo cancellation models. AECMOS is being made publicly available as an Azure service.
Speech Quality Assessment in Crowdsourcing: Comparison Category Rating Method
Apr 09, 2021
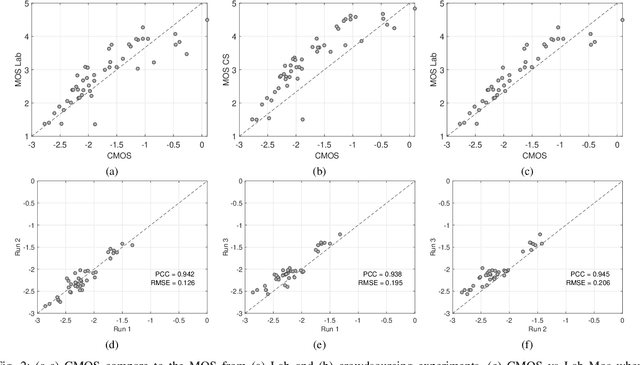
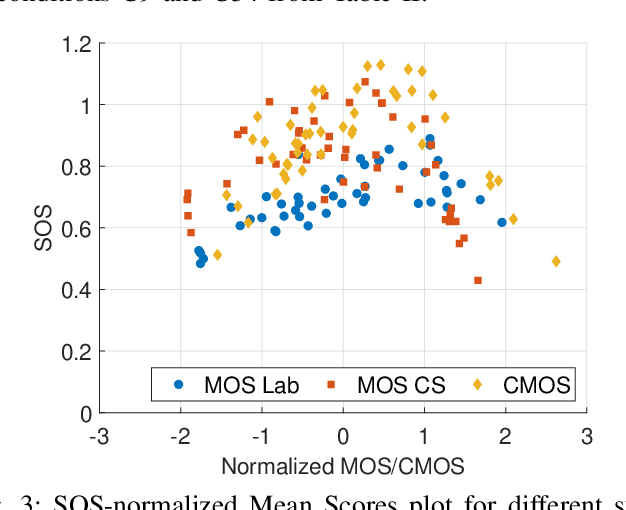

Traditionally, Quality of Experience (QoE) for a communication system is evaluated through a subjective test. The most common test method for speech QoE is the Absolute Category Rating (ACR), in which participants listen to a set of stimuli, processed by the underlying test conditions, and rate their perceived quality for each stimulus on a specific scale. The Comparison Category Rating (CCR) is another standard approach in which participants listen to both reference and processed stimuli and rate their quality compared to the other one. The CCR method is particularly suitable for systems that improve the quality of input speech. This paper evaluates an adaptation of the CCR test procedure for assessing speech quality in the crowdsourcing set-up. The CCR method was introduced in the ITU-T Rec. P.800 for laboratory-based experiments. We adapted the test for the crowdsourcing approach following the guidelines from ITU-T Rec. P.800 and P.808. We show that the results of the CCR procedure via crowdsourcing are highly reproducible. We also compared the CCR test results with widely used ACR test procedures obtained in the laboratory and crowdsourcing. Our results show that the CCR procedure in crowdsourcing is a reliable and valid test method.
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.