 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColBERTSaR: Sparsified ColBERT Index via Product Quantization
Jun 04, 2026While ColBERT is an effective neural retrieval architecture, it requires a heavy index structure to support candidate set retrieval based on approximated token embeddings, gathering and decompressing document token embeddings, and applying the MaxSim operation. Indexes in PLAID and similar ColBERT implementations require five to ten times the disk storage of the original raw text, which limits their scalability. Furthermore, prior work has identified that the gathering and decompression stages are the primary inefficiencies at query time. Limiting the number of document tokens that must be gathered by thresholding and score approximation does not eliminate the need for the entire index to support ad hoc queries. In this work, we propose an embedding quantization approach that turns a ColBERT index into a true inverted index. We show that, theoretically, ColBERT with embedding quantization is equivalent to learned-sparse retrieval except for the scoring mechanism. Empirically, we demonstrate that our index is 50-70% smaller than a one-bit PLAID index while retaining retrieval effectiveness.
A Brief Comparison of Training-Free Multi-Vector Sequence Compression Methods
Mar 23, 2026While multi-vector retrieval models outperform single-vector models of comparable size in retrieval quality, their practicality is limited by substantially larger index sizes, driven by the additional sequence-length dimension in their document embeddings. Because document embedding size dictates both memory overhead and query latency, compression is essential for deployment. In this work, we present an evaluation of training-free methods targeting the token sequence length, a dimension unique to multi-vector retrieval. Our findings suggest that token merging is strictly superior to token pruning for reducing index size while maintaining retrieval effectiveness.
Multi-Vector Index Compression in Any Modality
Feb 24, 2026We study efficient multi-vector retrieval for late interaction in any modality. Late interaction has emerged as a dominant paradigm for information retrieval in text, images, visual documents, and videos, but its computation and storage costs grow linearly with document length, making it costly for image-, video-, and audio-rich corpora. To address this limitation, we explore query-agnostic methods for compressing multi-vector document representations under a constant vector budget. We introduce four approaches for index compression: sequence resizing, memory tokens, hierarchical pooling, and a novel attention-guided clustering (AGC). AGC uses an attention-guided mechanism to identify the most semantically salient regions of a document as cluster centroids and to weight token aggregation. Evaluating these methods on retrieval tasks spanning text (BEIR), visual-document (ViDoRe), and video (MSR-VTT, MultiVENT 2.0), we show that attention-guided clustering consistently outperforms other parameterized compression methods (sequence resizing and memory tokens), provides greater flexibility in index size than non-parametric hierarchical clustering, and achieves competitive or improved performance compared to a full, uncompressed index. The source code is available at: github.com/hanxiangqin/omni-col-press.
semantic-features: A User-Friendly Tool for Studying Contextual Word Embeddings in Interpretable Semantic Spaces
Jun 06, 2025



We introduce semantic-features, an extensible, easy-to-use library based on Chronis et al. (2023) for studying contextualized word embeddings of LMs by projecting them into interpretable spaces. We apply this tool in an experiment where we measure the contextual effect of the choice of dative construction (prepositional or double object) on the semantic interpretation of utterances (Bresnan, 2007). Specifically, we test whether "London" in "I sent London the letter." is more likely to be interpreted as an animate referent (e.g., as the name of a person) than in "I sent the letter to London." To this end, we devise a dataset of 450 sentence pairs, one in each dative construction, with recipients being ambiguous with respect to person-hood vs. place-hood. By applying semantic-features, we show that the contextualized word embeddings of three masked language models show the expected sensitivities. This leaves us optimistic about the usefulness of our tool.
Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever
Sep 04, 2024



Multi-vector dense models, such as ColBERT, have proven highly effective in information retrieval. ColBERT's late interaction scoring approximates the joint query-document attention seen in cross-encoders while maintaining inference efficiency closer to traditional dense retrieval models, thanks to its bi-encoder architecture and recent optimizations in indexing and search. In this paper, we introduce a novel architecture and a training framework to support long context window and multilingual retrieval. Our new model, Jina-ColBERT-v2, demonstrates strong performance across a range of English and multilingual retrieval tasks,
LSTMSE-Net: Long Short Term Speech Enhancement Network for Audio-visual Speech Enhancement
Sep 03, 2024


In this paper, we propose long short term memory speech enhancement network (LSTMSE-Net), an audio-visual speech enhancement (AVSE) method. This innovative method leverages the complementary nature of visual and audio information to boost the quality of speech signals. Visual features are extracted with VisualFeatNet (VFN), and audio features are processed through an encoder and decoder. The system scales and concatenates visual and audio features, then processes them through a separator network for optimized speech enhancement. The architecture highlights advancements in leveraging multi-modal data and interpolation techniques for robust AVSE challenge systems. The performance of LSTMSE-Net surpasses that of the baseline model from the COG-MHEAR AVSE Challenge 2024 by a margin of 0.06 in scale-invariant signal-to-distortion ratio (SISDR), $0.03$ in short-time objective intelligibility (STOI), and $1.32$ in perceptual evaluation of speech quality (PESQ). The source code of the proposed LSTMSE-Net is available at \url{https://github.com/mtanveer1/AVSEC-3-Challenge}.
When does data augmentation help generalization in NLP?
Apr 30, 2020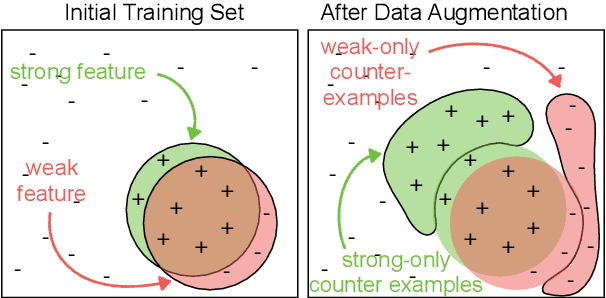

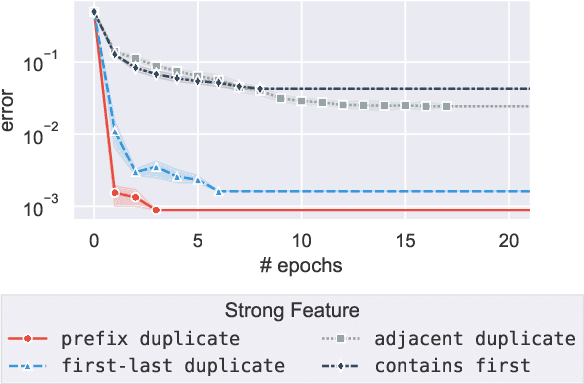
Neural models often exploit superficial ("weak") features to achieve good performance, rather than deriving the more general ("strong") features that we'd prefer a model to use. Overcoming this tendency is a central challenge in areas such as representation learning and ML fairness. Recent work has proposed using data augmentation--that is, generating training examples on which these weak features fail--as a means of encouraging models to prefer the stronger features. We design a series of toy learning problems to investigate the conditions under which such data augmentation is helpful. We show that augmenting with training examples on which the weak feature fails ("counterexamples") does succeed in preventing the model from relying on the weak feature, but often does not succeed in encouraging the model to use the stronger feature in general. We also find in many cases that the number of counterexamples needed to reach a given error rate is independent of the amount of training data, and that this type of data augmentation becomes less effective as the target strong feature becomes harder to learn.