 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMETEOR: A Massive Dense & Heterogeneous Behavior Dataset for Autonomous Driving
Sep 30, 2021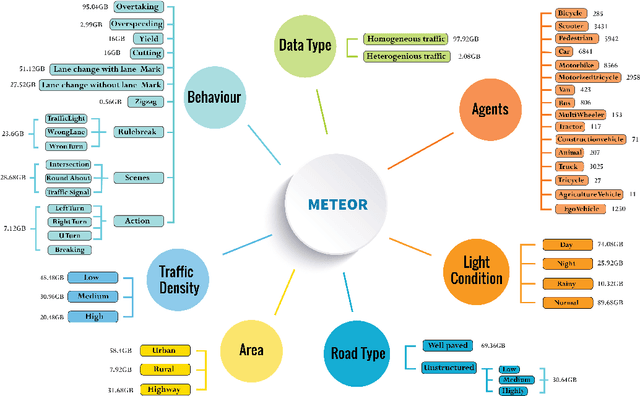

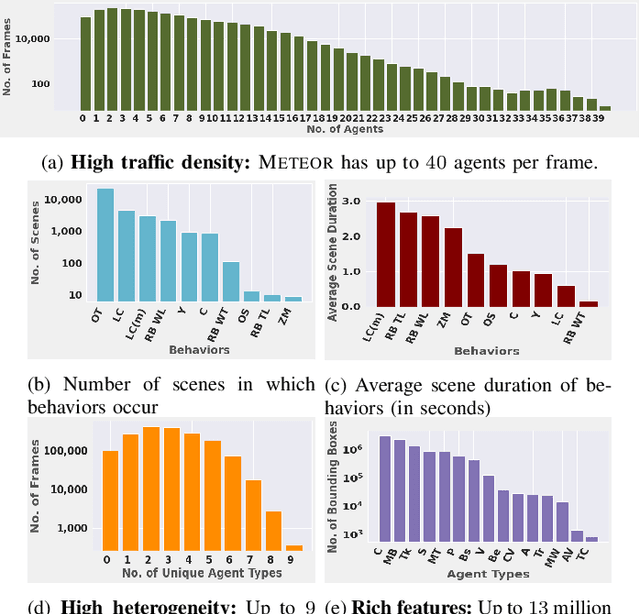
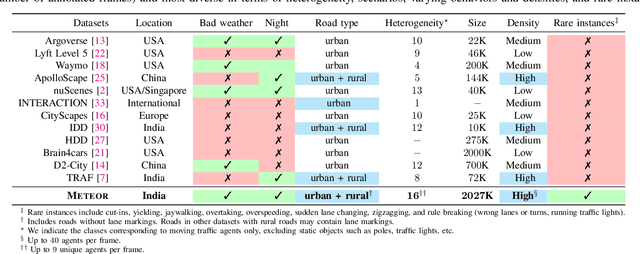
We present a new and complex traffic dataset, METEOR, which captures traffic patterns in unstructured scenarios in India. METEOR consists of more than 1000 one-minute video clips, over 2 million annotated frames with ego-vehicle trajectories, and more than 13 million bounding boxes for surrounding vehicles or traffic agents. METEOR is a unique dataset in terms of capturing the heterogeneity of microscopic and macroscopic traffic characteristics. Furthermore, we provide annotations for rare and interesting driving behaviors such as cut-ins, yielding, overtaking, overspeeding, zigzagging, sudden lane changing, running traffic signals, driving in the wrong lanes, taking wrong turns, lack of right-of-way rules at intersections, etc. We also present diverse traffic scenarios corresponding to rainy weather, nighttime driving, driving in rural areas with unmarked roads, and high-density traffic scenarios. We use our novel dataset to evaluate the performance of object detection and behavior prediction algorithms. We show that state-of-the-art object detectors fail in these challenging conditions and also propose a new benchmark test: action-behavior prediction with a baseline mAP score of 70.74.
GamePlan: Game-Theoretic Multi-Agent Planning with Human Drivers at Intersections, Roundabouts, and Merging
Sep 04, 2021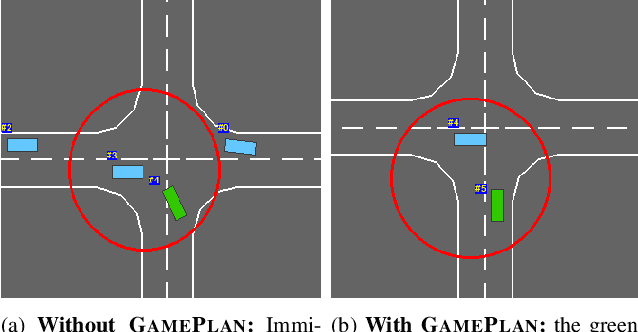

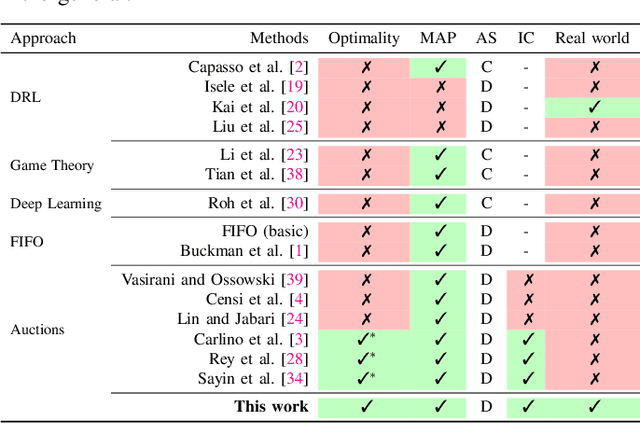

We present a new method for multi-agent planning involving human drivers and autonomous vehicles (AVs) in unsignaled intersections, roundabouts, and during merging. In multi-agent planning, the main challenge is to predict the actions of other agents, especially human drivers, as their intentions are hidden from other agents. Our algorithm uses game theory to develop a new auction, called \model, that directly determines the optimal action for each agent based on their driving style (which is observable via commonly available sensors like lidars and cameras). GamePlan assigns a higher priority to more aggressive or impatient drivers and a lower priority to more conservative or patient drivers; we theoretically prove that such an approach, although counter-intuitive, is game-theoretically optimal. Our approach successfully prevents collisions and deadlocks. We compare our approach with prior state-of-the-art auction techniques including economic auctions, time-based auctions (first-in first-out), and random bidding and show that each of these methods result in collisions among agents when taking into account driver behavior. We additionally compare with methods based on deep reinforcement learning, deep learning, and game theory and present our benefits over these approaches. Finally, we show that our approach can be implemented in the real-world with human drivers.
M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
Apr 30, 2021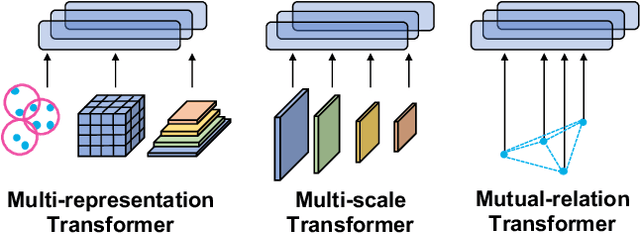

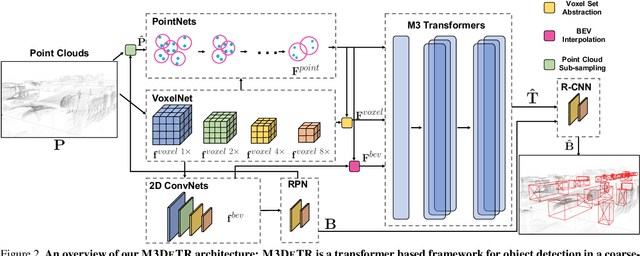
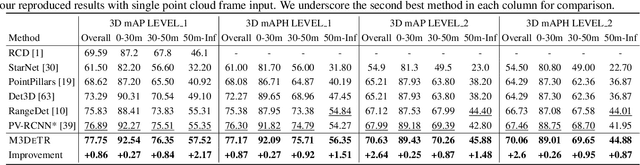
We present a novel architecture for 3D object detection, M3DeTR, which combines different point cloud representations (raw, voxels, bird-eye view) with different feature scales based on multi-scale feature pyramids. M3DeTR is the first approach that unifies multiple point cloud representations, feature scales, as well as models mutual relationships between point clouds simultaneously using transformers. We perform extensive ablation experiments that highlight the benefits of fusing representation and scale, and modeling the relationships. Our method achieves state-of-the-art performance on the KITTI 3D object detection dataset and Waymo Open Dataset. Results show that M3DeTR improves the baseline significantly by 1.48% mAP for all classes on Waymo Open Dataset. In particular, our approach ranks 1st on the well-known KITTI 3D Detection Benchmark for both car and cyclist classes, and ranks 1st on Waymo Open Dataset with single frame point cloud input.
GANav: Group-wise Attention Network for Classifying Navigable Regions in Unstructured Outdoor Environments
Mar 07, 2021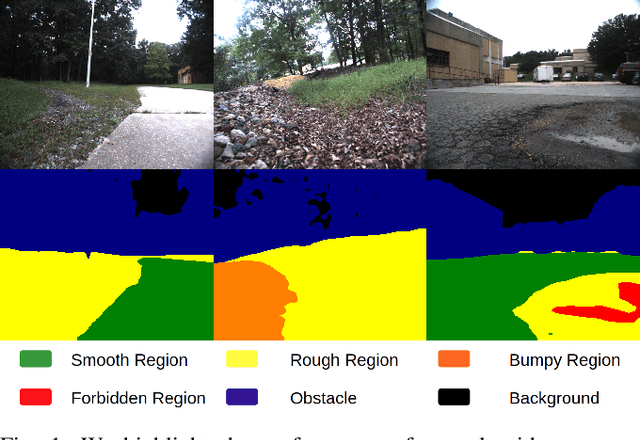
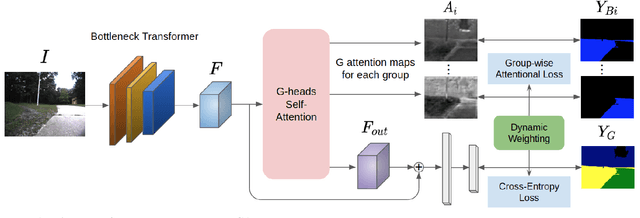
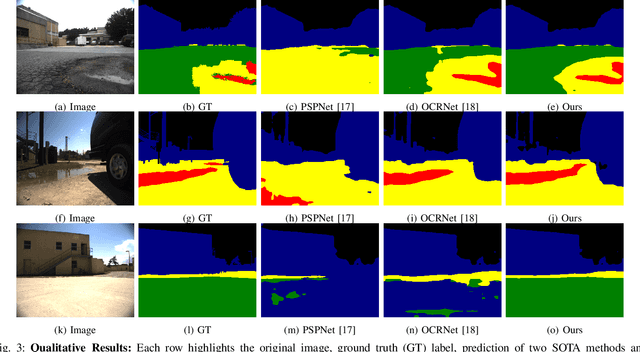

We present a new learning-based method for identifying safe and navigable regions in off-road terrains and unstructured environments from RGB images. Our approach consists of classifying groups of terrain classes based on their navigability levels using coarse-grained semantic segmentation. We propose a bottleneck transformer-based deep neural network architecture that uses a novel group-wise attention mechanism to distinguish between navigability levels of different terrains.Our group-wise attention heads enable the network to explicitly focus on the different groups and improve the accuracy. In addition, we propose a dynamic weighted cross entropy loss function to handle the long-tailed nature of the dataset. We show through extensive evaluations on the RUGD and RELLIS-3D datasets that our learning algorithm improves the accuracy of visual perception in off-road terrains for navigation. We compare our approach with prior work on these datasets and achieve an improvement over the state-of-the-art mIoU by 6.74-39.1% on RUGD and 3.82-10.64% on RELLIS-3D.
SAfE: Self-Attention Based Unsupervised Road Safety Classification in Hazardous Environments
Nov 27, 2020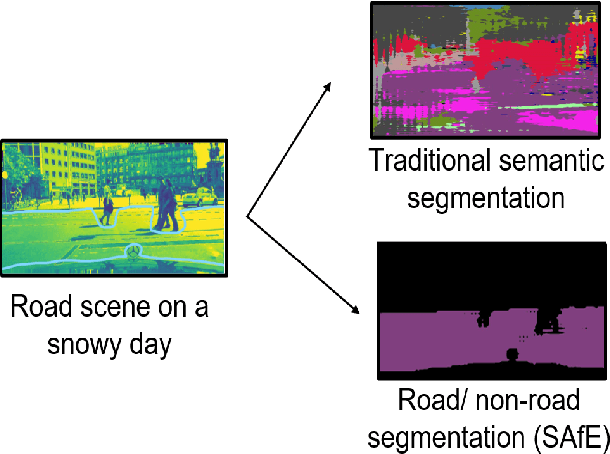
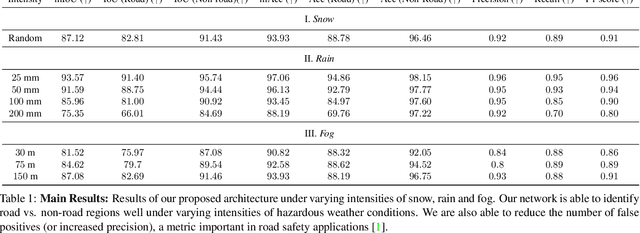


We present a novel approach SAfE that can identify parts of an outdoor scene that are safe for driving, based on attention models. Our formulation is designed for hazardous weather conditions that can impair the visibility of human drivers as well as autonomous vehicles, increasing the risk of accidents. Our approach is unsupervised and uses domain adaptation, with entropy minimization and attention transfer discriminators, to leverage the large amounts of labeled data corresponding to clear weather conditions. Our attention transfer discriminator uses attention maps from the clear weather image to help the network learn relevant regions to attend to, on the images from the hazardous weather dataset. We conduct experiments on CityScapes simulated datasets depicting various weather conditions such as rain, fog and snow under different intensities, and additionally on Berkeley Deep Drive. Our result show that using attention models improves the standard unsupervised domain adaptation performance by 29.29%. Furthermore, we also compare with unsupervised domain adaptation methods and show an improvement of at least 12.02% (mIoU) over the state-of-the-art.
StylePredict: Machine Theory of Mind for Human Driver Behavior From Trajectories
Nov 11, 2020
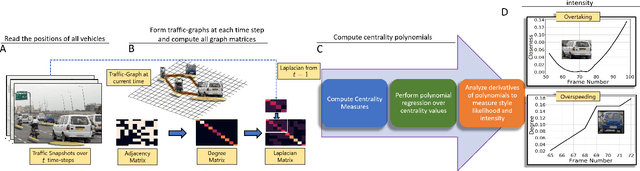

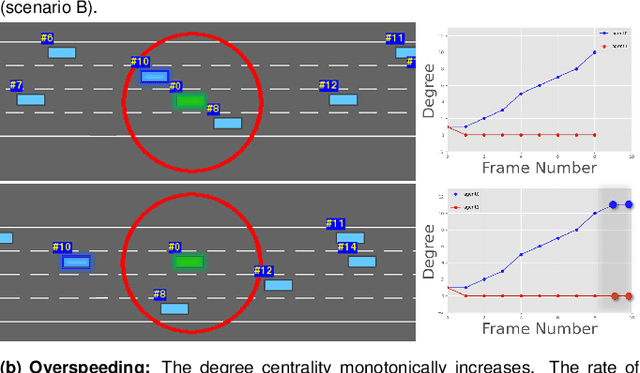
Studies have shown that autonomous vehicles (AVs) behave conservatively in a traffic environment composed of human drivers and do not adapt to local conditions and socio-cultural norms. It is known that socially aware AVs can be designed if there exist a mechanism to understand the behaviors of human drivers. We present a notion of Machine Theory of Mind (M-ToM) to infer the behaviors of human drivers by observing the trajectory of their vehicles. Our M-ToM approach, called StylePredict, is based on trajectory analysis of vehicles, which has been investigated in robotics and computer vision. StylePredict mimics human ToM to infer driver behaviors, or styles, using a computational mapping between the extracted trajectory of a vehicle in traffic and the driver behaviors using graph-theoretic techniques, including spectral analysis and centrality functions. We use StylePredict to analyze driver behavior in different cultures in the USA, China, India, and Singapore, based on traffic density, heterogeneity, and conformity to traffic rules and observe an inverse correlation between longitudinal (overspeeding) and lateral (overtaking, lane-changes) driving styles.
B-GAP: Behavior-Guided Action Prediction for Autonomous Navigation
Nov 07, 2020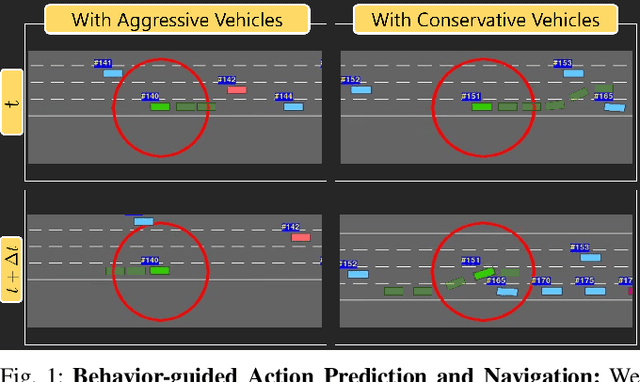

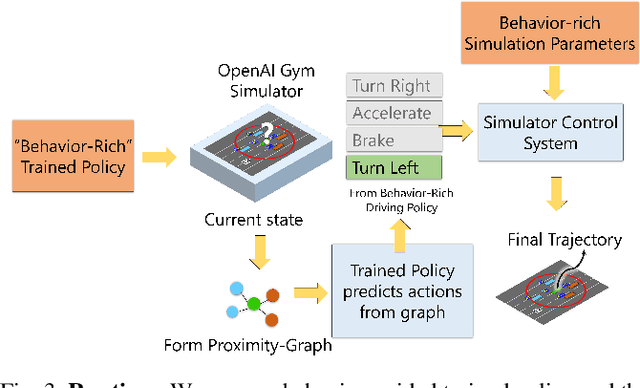
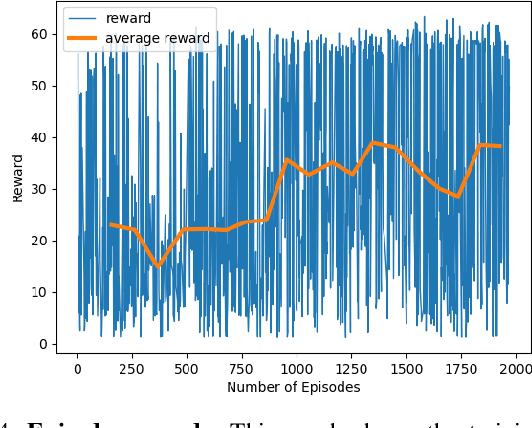
We present a novel learning algorithm for action prediction and local navigation for autonomous driving. Our approach classifies the driver behavior of other vehicles or road-agents (aggressive or conservative) and takes that into account for decision making and safe driving. We present a behavior-driven simulator that can generate trajectories corresponding to different levels of aggressive behaviors and use our simulator to train a policy using graph convolutional networks. We use a reinforcement learning-based navigation scheme that uses a proximity graph of traffic agents and computes a safe trajectory for the ego-vehicle that accounts for aggressive driver maneuvers such as overtaking, over-speeding, weaving, and sudden lane changes. We have integrated our algorithm with OpenAI gym-based "Highway-Env" simulator and demonstrate the benefits in terms of improved navigation in different scenarios.
BoMuDA: Boundless Multi-Source Domain Adaptive Segmentation in Unconstrained Environments
Oct 13, 2020

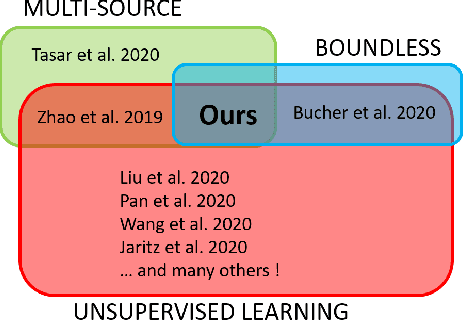
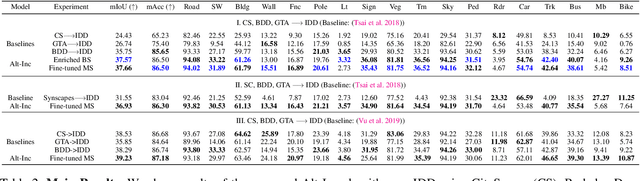
We present an unsupervised multi-source domain adaptive semantic segmentation approach in unstructured and unconstrained traffic environments. We propose a novel training strategy that alternates between single-source domain adaptation (DA) and multi-source distillation, and also between setting up an improvised cost function and optimizing it. In each iteration, the single-source DA first learns a neural network on a selected source, which is followed by a multi-source fine-tuning step using the remaining sources. We call this training routine the Alternating-Incremental ("Alt-Inc") algorithm. Furthermore, our approach is also boundless i.e. it can explicitly classify categories that do not belong to the training dataset (as opposed to labeling such objects as "unknown"). We have conducted extensive experiments and ablation studies using the Indian Driving Dataset, CityScapes, Berkeley DeepDrive, GTA V, and the Synscapes datasets, and we show that our unsupervised approach outperforms other unsupervised and semi-supervised SOTA benchmarks by 5.17% - 42.9% with a reduced model size by up to 5.2x.
Emotions Don't Lie: A Deepfake Detection Method using Audio-Visual Affective Cues
Mar 17, 2020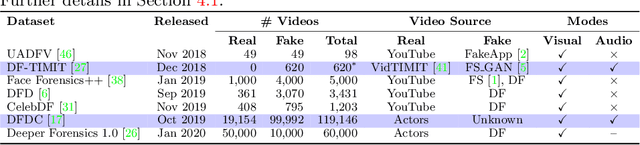
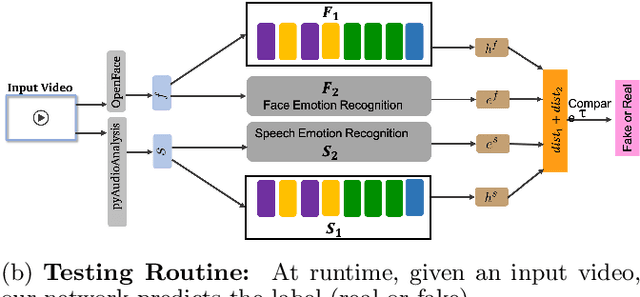
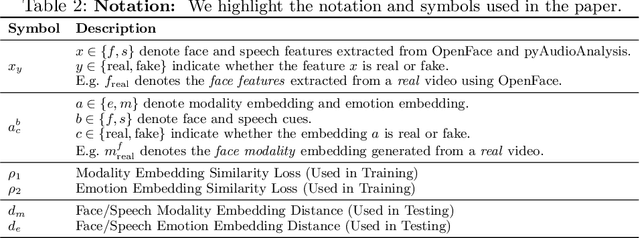

We present a learning-based multimodal method for detecting real and deepfake videos. To maximize information for learning, we extract and analyze the similarity between the two audio and visual modalities from within the same video. Additionally, we extract and compare affective cues corresponding to emotion from the two modalities within a video to infer whether the input video is "real" or "fake". We propose a deep learning network, inspired by the Siamese network architecture and the triplet loss. To validate our model, we report the AUC metric on two large-scale, audio-visual deepfake detection datasets, DeepFake-TIMIT Dataset and DFDC. We compare our approach with several SOTA deepfake detection methods and report per-video AUC of 84.4% on the DFDC and 96.6% on the DF-TIMIT datasets, respectively.
EmotiCon: Context-Aware Multimodal Emotion Recognition using Frege's Principle
Mar 14, 2020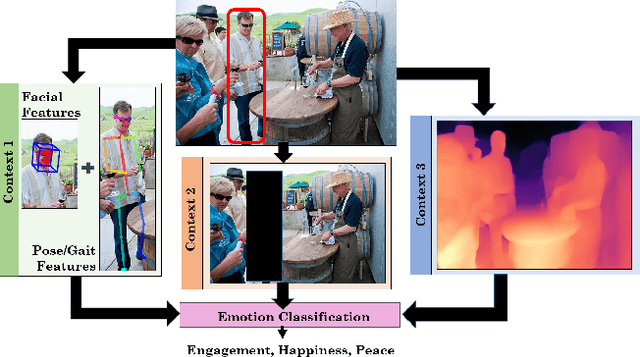
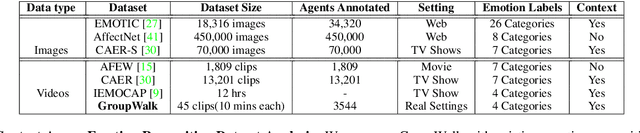
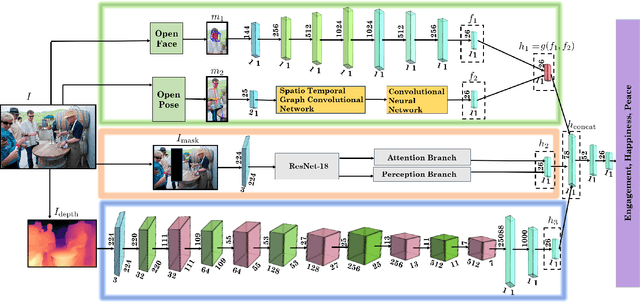
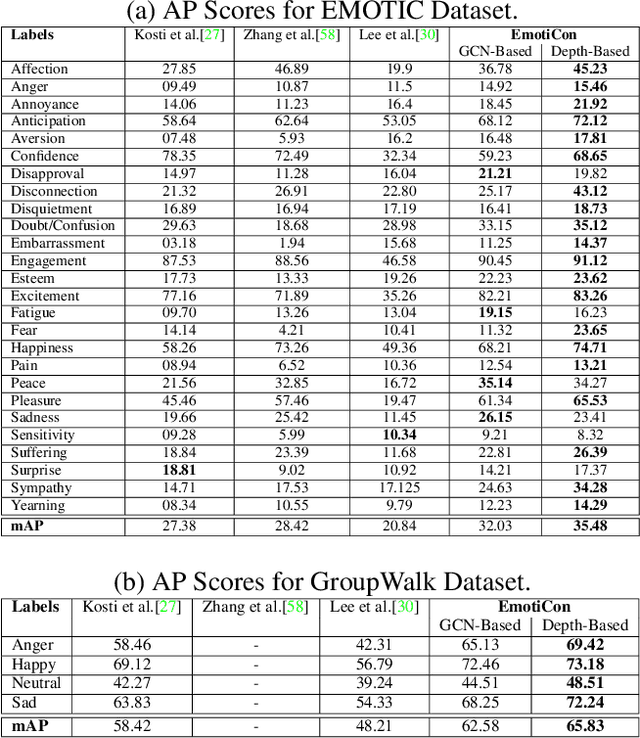
We present EmotiCon, a learning-based algorithm for context-aware perceived human emotion recognition from videos and images. Motivated by Frege's Context Principle from psychology, our approach combines three interpretations of context for emotion recognition. Our first interpretation is based on using multiple modalities(e.g. faces and gaits) for emotion recognition. For the second interpretation, we gather semantic context from the input image and use a self-attention-based CNN to encode this information. Finally, we use depth maps to model the third interpretation related to socio-dynamic interactions and proximity among agents. We demonstrate the efficiency of our network through experiments on EMOTIC, a benchmark dataset. We report an Average Precision (AP) score of 35.48 across 26 classes, which is an improvement of 7-8 over prior methods. We also introduce a new dataset, GroupWalk, which is a collection of videos captured in multiple real-world settings of people walking. We report an AP of 65.83 across 4 categories on GroupWalk, which is also an improvement over prior methods.