 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage model acceptability judgements are not always robust to context
Dec 18, 2022Targeted syntactic evaluations of language models ask whether models show stable preferences for syntactically acceptable content over minimal-pair unacceptable inputs. Most targeted syntactic evaluation datasets ask models to make these judgements with just a single context-free sentence as input. This does not match language models' training regime, in which input sentences are always highly contextualized by the surrounding corpus. This mismatch raises an important question: how robust are models' syntactic judgements in different contexts? In this paper, we investigate the stability of language models' performance on targeted syntactic evaluations as we vary properties of the input context: the length of the context, the types of syntactic phenomena it contains, and whether or not there are violations of grammaticality. We find that model judgements are generally robust when placed in randomly sampled linguistic contexts. However, they are substantially unstable for contexts containing syntactic structures matching those in the critical test content. Among all tested models (GPT-2 and five variants of OPT), we significantly improve models' judgements by providing contexts with matching syntactic structures, and conversely significantly worsen them using unacceptable contexts with matching but violated syntactic structures. This effect is amplified by the length of the context, except for unrelated inputs. We show that these changes in model performance are not explainable by simple features matching the context and the test inputs, such as lexical overlap and dependency overlap. This sensitivity to highly specific syntactic features of the context can only be explained by the models' implicit in-context learning abilities.
On the Effect of Anticipation on Reading Times
Nov 25, 2022Over the past two decades, numerous studies have demonstrated how less predictable (i.e. higher surprisal) words take more time to read. In general, these previous studies implicitly assumed the reading process to be purely responsive: readers observe a new word and allocate time to read it as required. These results, however, are also compatible with a reading time that is anticipatory: readers could, e.g., allocate time to a future word based on their expectation about it. In this work, we examine the anticipatory nature of reading by looking at how people's predictions about upcoming material influence reading times. Specifically, we test anticipation by looking at the effects of surprisal and contextual entropy on four reading-time datasets: two self-paced and two eye-tracking. In three of four datasets tested, we find that the entropy predicts reading times as well as (or better than) the surprisal. We then hypothesise four cognitive mechanisms through which the contextual entropy could impact RTs -- three of which we design experiments to analyse. Overall, our results support a view of reading that is both anticipatory and responsive.
Towards Human-Agent Communication via the Information Bottleneck Principle
Jun 30, 2022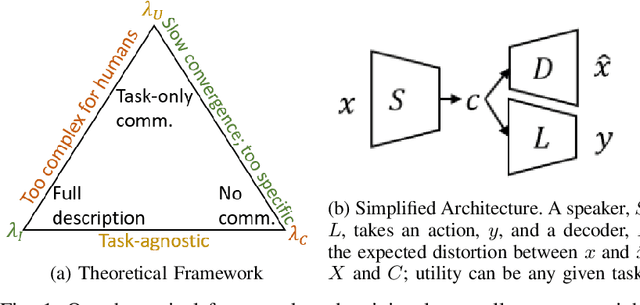
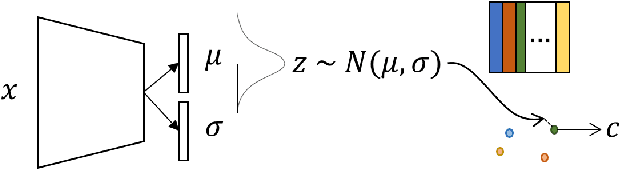
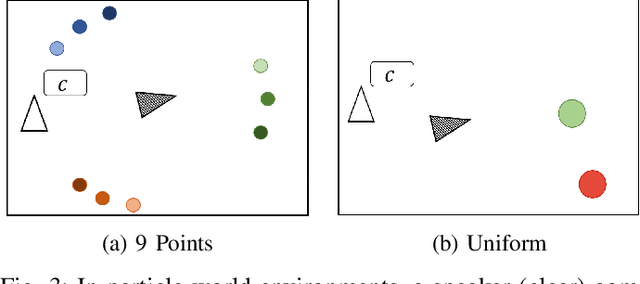

Emergent communication research often focuses on optimizing task-specific utility as a driver for communication. However, human languages appear to evolve under pressure to efficiently compress meanings into communication signals by optimizing the Information Bottleneck tradeoff between informativeness and complexity. In this work, we study how trading off these three factors -- utility, informativeness, and complexity -- shapes emergent communication, including compared to human communication. To this end, we propose Vector-Quantized Variational Information Bottleneck (VQ-VIB), a method for training neural agents to compress inputs into discrete signals embedded in a continuous space. We train agents via VQ-VIB and compare their performance to previously proposed neural architectures in grounded environments and in a Lewis reference game. Across all neural architectures and settings, taking into account communicative informativeness benefits communication convergence rates, and penalizing communicative complexity leads to human-like lexicon sizes while maintaining high utility. Additionally, we find that VQ-VIB outperforms other discrete communication methods. This work demonstrates how fundamental principles that are believed to characterize human language evolution may inform emergent communication in artificial agents.
Assessing Group-level Gender Bias in Professional Evaluations: The Case of Medical Student End-of-Shift Feedback
Jun 01, 2022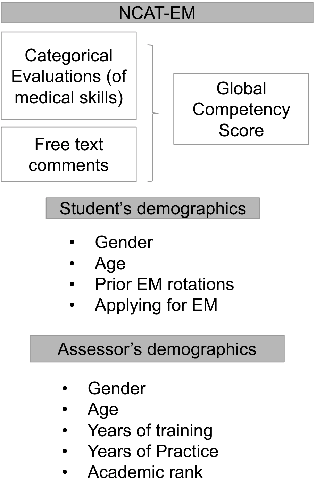
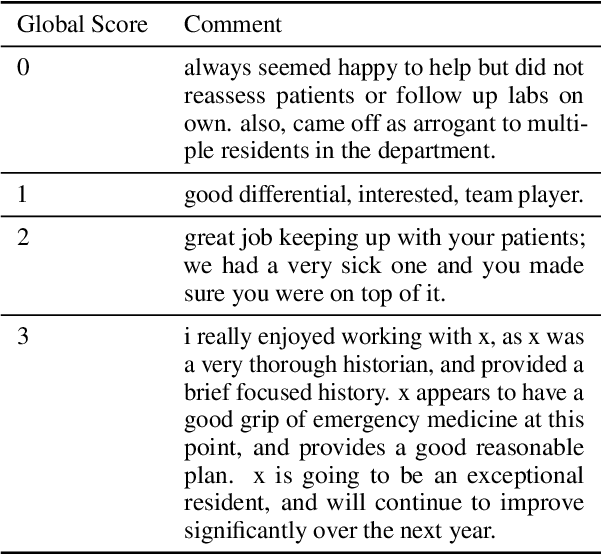
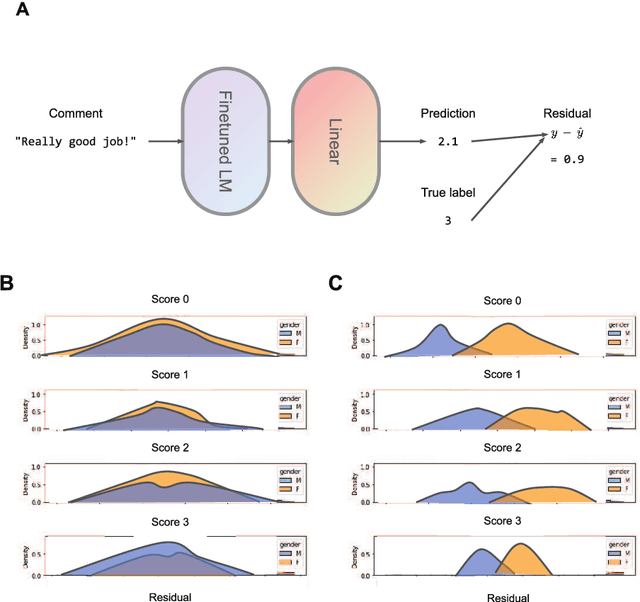
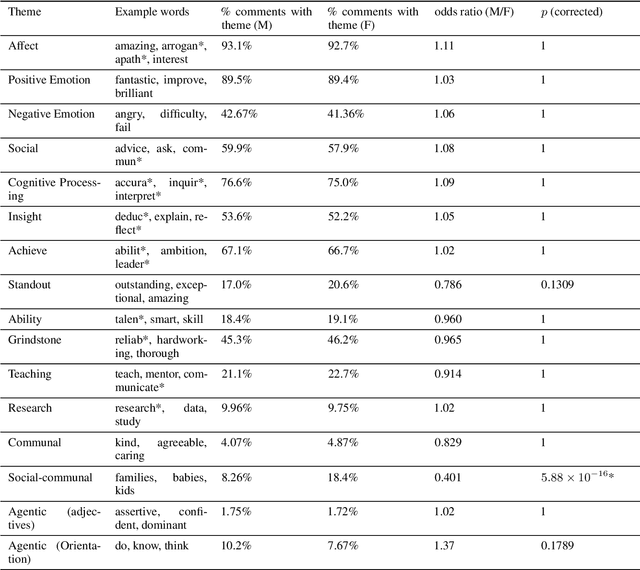
Although approximately 50% of medical school graduates today are women, female physicians tend to be underrepresented in senior positions, make less money than their male counterparts and receive fewer promotions. There is a growing body of literature demonstrating gender bias in various forms of evaluation in medicine, but this work was mainly conducted by looking for specific words using fixed dictionaries such as LIWC and focused on recommendation letters. We use a dataset of written and quantitative assessments of medical student performance on individual shifts of work, collected across multiple institutions, to investigate the extent to which gender bias exists in a day-to-day context for medical students. We investigate differences in the narrative comments given to male and female students by both male or female faculty assessors, using a fine-tuned BERT model. This allows us to examine whether groups are written about in systematically different ways, without relying on hand-crafted wordlists or topic models. We compare these results to results from the traditional LIWC method and find that, although we find no evidence of group-level gender bias in this dataset, terms related to family and children are used more in feedback given to women.
When Does Syntax Mediate Neural Language Model Performance? Evidence from Dropout Probes
Apr 20, 2022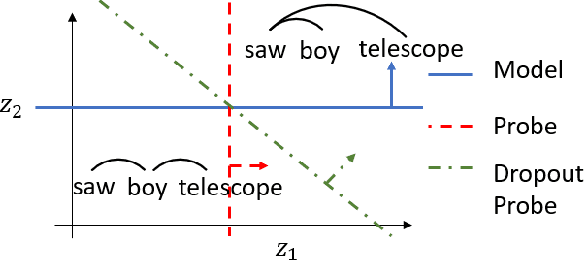
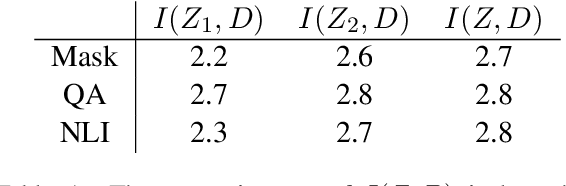
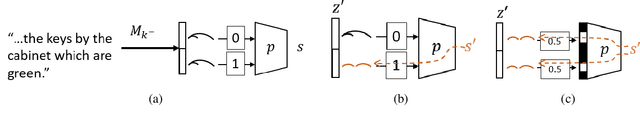

Recent causal probing literature reveals when language models and syntactic probes use similar representations. Such techniques may yield "false negative" causality results: models may use representations of syntax, but probes may have learned to use redundant encodings of the same syntactic information. We demonstrate that models do encode syntactic information redundantly and introduce a new probe design that guides probes to consider all syntactic information present in embeddings. Using these probes, we find evidence for the use of syntax in models where prior methods did not, allowing us to boost model performance by injecting syntactic information into representations.
Analyzing Wrap-Up Effects through an Information-Theoretic Lens
Mar 31, 2022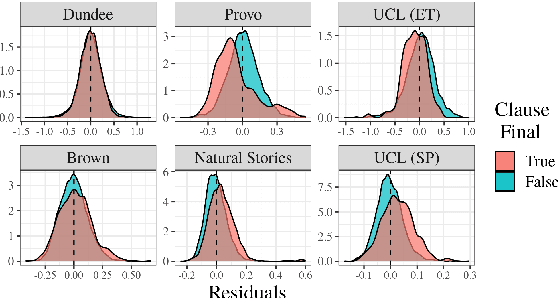
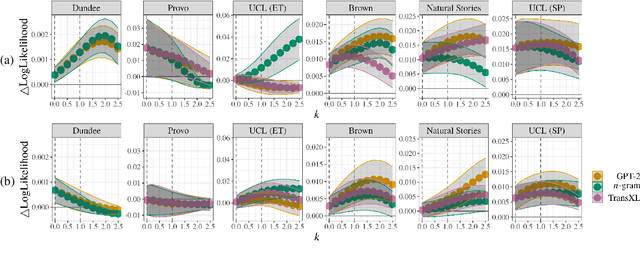
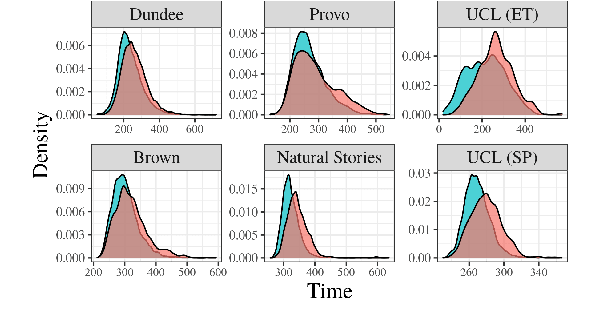
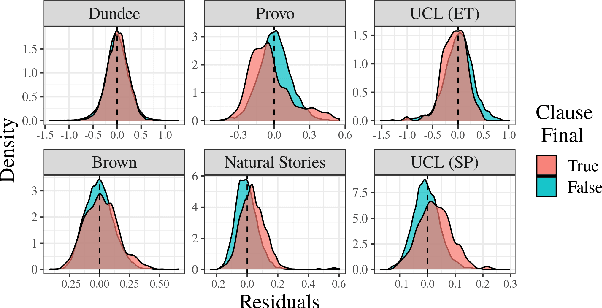
Numerous analyses of reading time (RT) data have been implemented -- all in an effort to better understand the cognitive processes driving reading comprehension. However, data measured on words at the end of a sentence -- or even at the end of a clause -- is often omitted due to the confounding factors introduced by so-called "wrap-up effects," which manifests as a skewed distribution of RTs for these words. Consequently, the understanding of the cognitive processes that might be involved in these wrap-up effects is limited. In this work, we attempt to learn more about these processes by examining the relationship between wrap-up effects and information-theoretic quantities, such as word and context surprisals. We find that the distribution of information in prior contexts is often predictive of sentence- and clause-final RTs (while not of sentence-medial RTs). This lends support to several prior hypotheses about the processes involved in wrap-up effects.
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021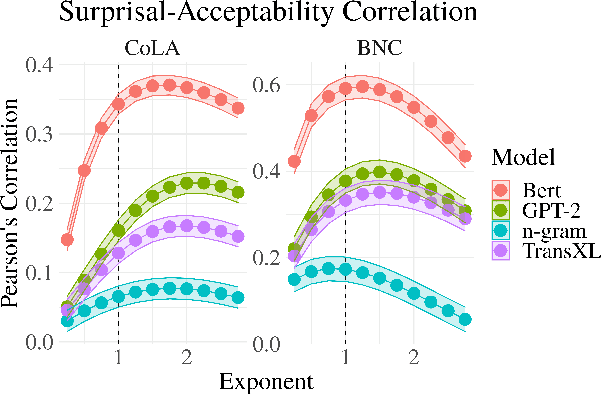
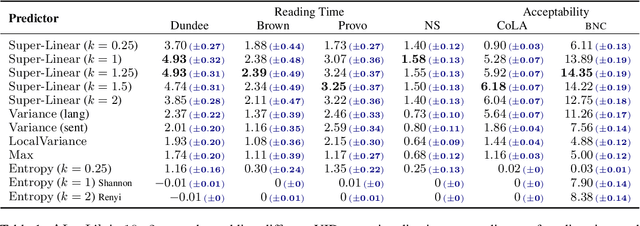
The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Controlled Evaluation of Grammatical Knowledge in Mandarin Chinese Language Models
Sep 22, 2021
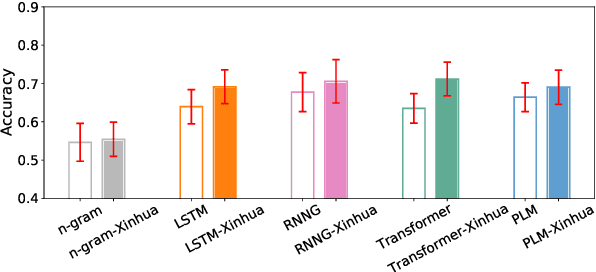
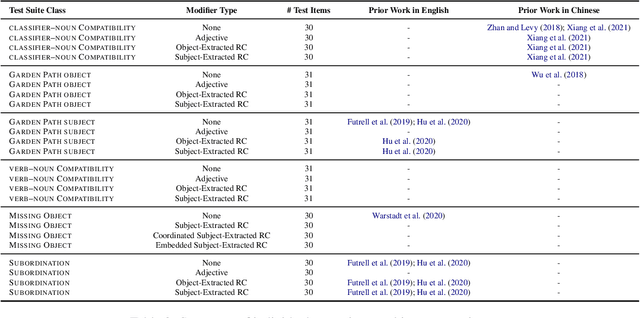
Prior work has shown that structural supervision helps English language models learn generalizations about syntactic phenomena such as subject-verb agreement. However, it remains unclear if such an inductive bias would also improve language models' ability to learn grammatical dependencies in typologically different languages. Here we investigate this question in Mandarin Chinese, which has a logographic, largely syllable-based writing system; different word order; and sparser morphology than English. We train LSTMs, Recurrent Neural Network Grammars, Transformer language models, and Transformer-parameterized generative parsing models on two Mandarin Chinese datasets of different sizes. We evaluate the models' ability to learn different aspects of Mandarin grammar that assess syntactic and semantic relationships. We find suggestive evidence that structural supervision helps with representing syntactic state across intervening content and improves performance in low-data settings, suggesting that the benefits of hierarchical inductive biases in acquiring dependency relationships may extend beyond English.
Scalable pragmatic communication via self-supervision
Aug 12, 2021

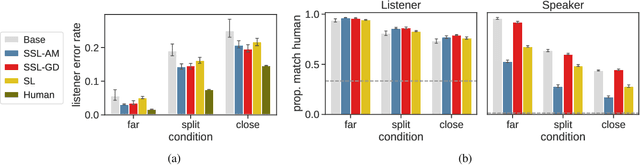
Models of context-sensitive communication often use the Rational Speech Act framework (RSA; Frank & Goodman, 2012), which formulates listeners and speakers in a cooperative reasoning process. However, the standard RSA formulation can only be applied to small domains, and large-scale applications have relied on imitating human behavior. Here, we propose a new approach to scalable pragmatics, building upon recent theoretical results (Zaslavsky et al., 2020) that characterize pragmatic reasoning in terms of general information-theoretic principles. Specifically, we propose an architecture and learning process in which agents acquire pragmatic policies via self-supervision instead of imitating human data. This work suggests a new principled approach for equipping artificial agents with pragmatic skills via self-supervision, which is grounded both in pragmatic theory and in information theory.
Structural Guidance for Transformer Language Models
Jul 30, 2021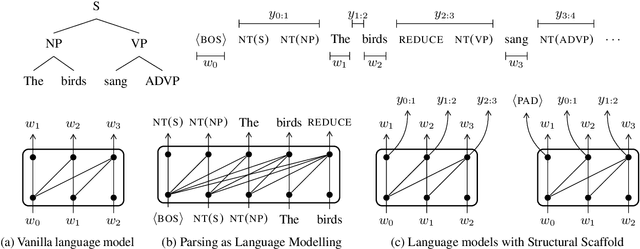
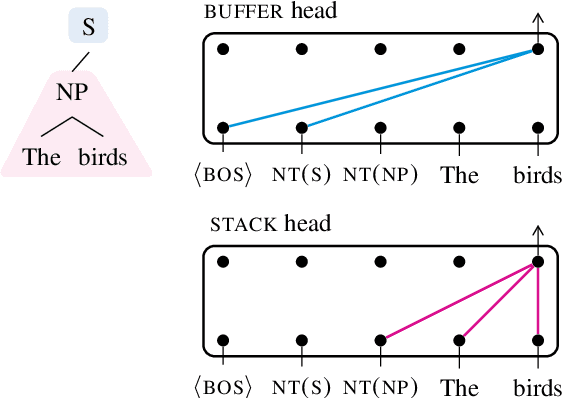
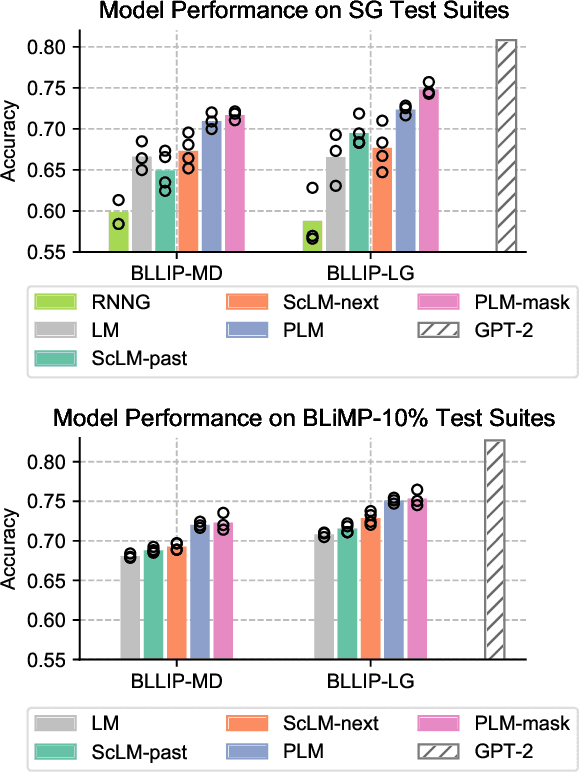
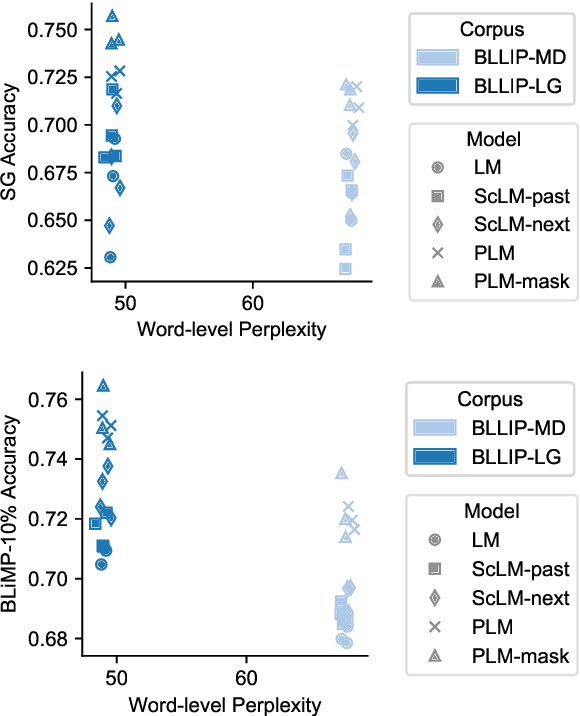
Transformer-based language models pre-trained on large amounts of text data have proven remarkably successful in learning generic transferable linguistic representations. Here we study whether structural guidance leads to more human-like systematic linguistic generalization in Transformer language models without resorting to pre-training on very large amounts of data. We explore two general ideas. The "Generative Parsing" idea jointly models the incremental parse and word sequence as part of the same sequence modeling task. The "Structural Scaffold" idea guides the language model's representation via additional structure loss that separately predicts the incremental constituency parse. We train the proposed models along with a vanilla Transformer language model baseline on a 14 million-token and a 46 million-token subset of the BLLIP dataset, and evaluate models' syntactic generalization performances on SG Test Suites and sized BLiMP. Experiment results across two benchmarks suggest converging evidence that generative structural supervisions can induce more robust and humanlike linguistic generalization in Transformer language models without the need for data intensive pre-training.