 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model
Jul 09, 2019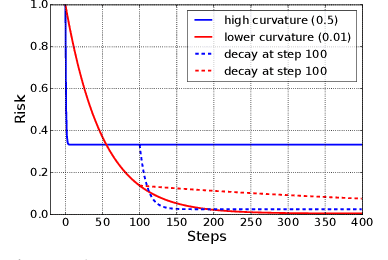
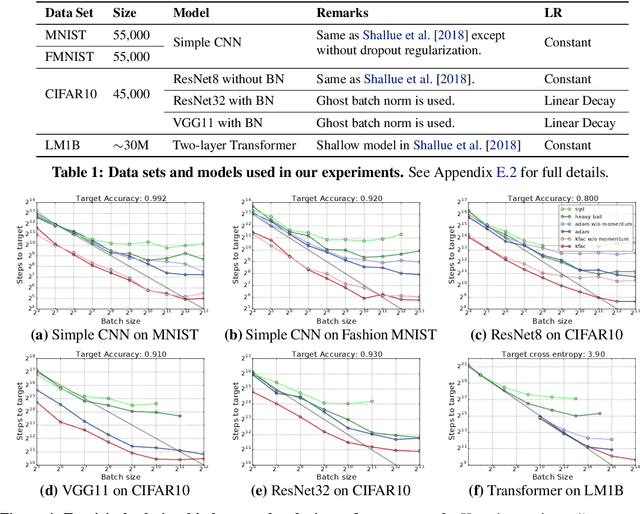
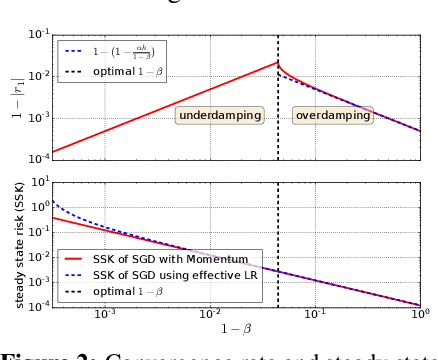
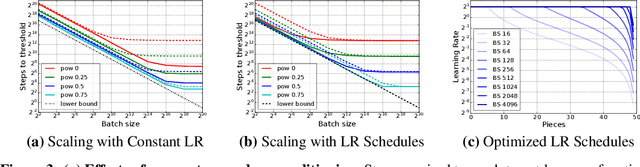
Increasing the batch size is a popular way to speed up neural network training, but beyond some critical batch size, larger batch sizes yield diminishing returns. In this work, we study how the critical batch size changes based on properties of the optimization algorithm, including acceleration and preconditioning, through two different lenses: large scale experiments, and analysis of a simple noisy quadratic model (NQM). We experimentally demonstrate that optimization algorithms that employ preconditioning, specifically Adam and K-FAC, result in much larger critical batch sizes than stochastic gradient descent with momentum. We also demonstrate that the NQM captures many of the essential features of real neural network training, despite being drastically simpler to work with. The NQM predicts our results with preconditioned optimizers, previous results with accelerated gradient descent, and other results around optimal learning rates and large batch training, making it a useful tool to generate testable predictions about neural network optimization.
Fast Convergence of Natural Gradient Descent for Overparameterized Neural Networks
May 27, 2019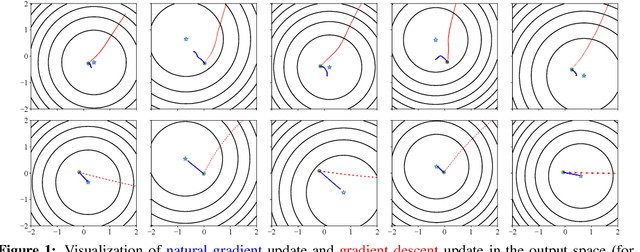
Natural gradient descent has proven effective at mitigating the effects of pathological curvature in neural network optimization, but little is known theoretically about its convergence properties, especially for \emph{nonlinear} networks. In this work, we analyze \emph{for the first time} the speed of convergence for natural gradient descent on nonlinear neural networks with the squared-error loss. We identify two conditions which guarantee the efficient convergence from random initializations: (1) the Jacobian matrix (of network's output for all training cases with respect to the parameters) is full row rank, and (2) the Jacobian matrix is stable for small perturbations around the initialization. For two-layer ReLU neural networks (i.e., with one hidden layer), we prove that these two conditions do in fact hold throughout the training, under the assumptions of nondegenerate inputs and overparameterization. We further extend our analysis to more general loss functions. Lastly, we show that K-FAC, an approximate natural gradient descent method, also converges to global minima under the same assumptions.
EigenDamage: Structured Pruning in the Kronecker-Factored Eigenbasis
May 15, 2019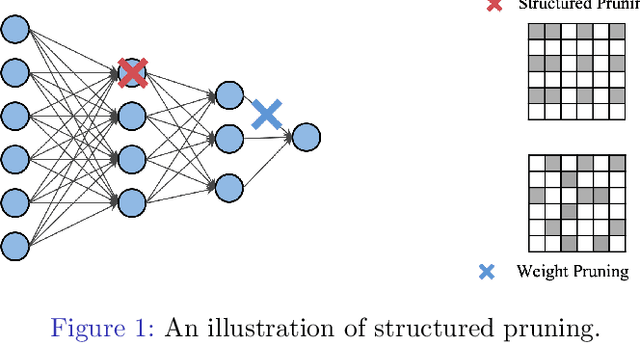
Reducing the test time resource requirements of a neural network while preserving test accuracy is crucial for running inference on resource-constrained devices. To achieve this goal, we introduce a novel network reparameterization based on the Kronecker-factored eigenbasis (KFE), and then apply Hessian-based structured pruning methods in this basis. As opposed to existing Hessian-based pruning algorithms which do pruning in parameter coordinates, our method works in the KFE where different weights are approximately independent, enabling accurate pruning and fast computation. We demonstrate empirically the effectiveness of the proposed method through extensive experiments. In particular, we highlight that the improvements are especially significant for more challenging datasets and networks. With negligible loss of accuracy, an iterative-pruning version gives a 10$\times$ reduction in model size and a 8$\times$ reduction in FLOPs on wide ResNet32.
Functional Variational Bayesian Neural Networks
Mar 14, 2019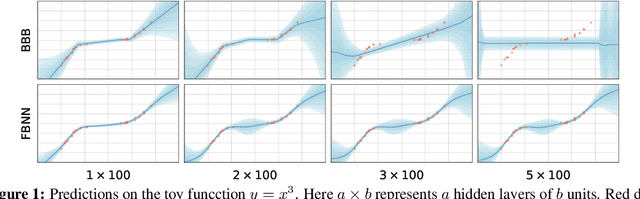
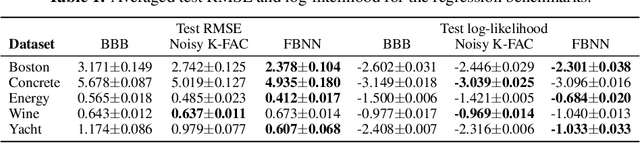

Variational Bayesian neural networks (BNNs) perform variational inference over weights, but it is difficult to specify meaningful priors and approximate posteriors in a high-dimensional weight space. We introduce functional variational Bayesian neural networks (fBNNs), which maximize an Evidence Lower BOund (ELBO) defined directly on stochastic processes, i.e. distributions over functions. We prove that the KL divergence between stochastic processes equals the supremum of marginal KL divergences over all finite sets of inputs. Based on this, we introduce a practical training objective which approximates the functional ELBO using finite measurement sets and the spectral Stein gradient estimator. With fBNNs, we can specify priors entailing rich structures, including Gaussian processes and implicit stochastic processes. Empirically, we find fBNNs extrapolate well using various structured priors, provide reliable uncertainty estimates, and scale to large datasets.
Self-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response Functions
Mar 07, 2019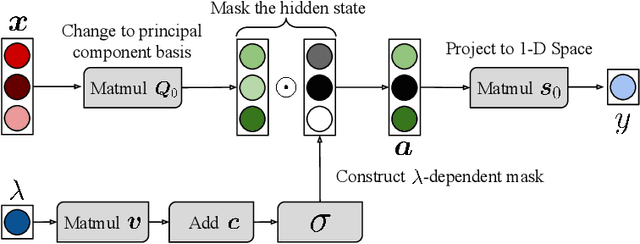
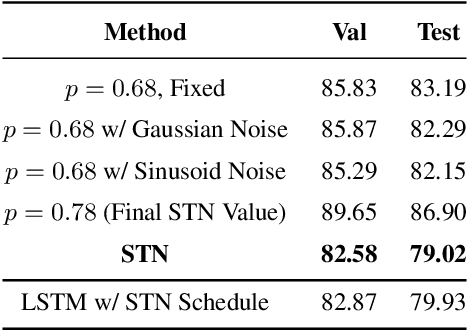
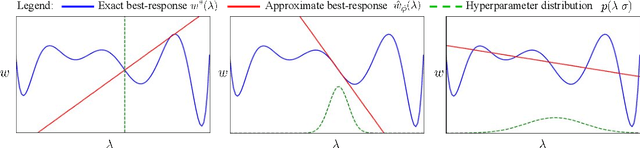
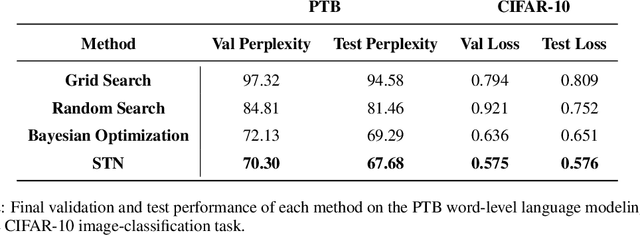
Hyperparameter optimization can be formulated as a bilevel optimization problem, where the optimal parameters on the training set depend on the hyperparameters. We aim to adapt regularization hyperparameters for neural networks by fitting compact approximations to the best-response function, which maps hyperparameters to optimal weights and biases. We show how to construct scalable best-response approximations for neural networks by modeling the best-response as a single network whose hidden units are gated conditionally on the regularizer. We justify this approximation by showing the exact best-response for a shallow linear network with L2-regularized Jacobian can be represented by a similar gating mechanism. We fit this model using a gradient-based hyperparameter optimization algorithm which alternates between approximating the best-response around the current hyperparameters and optimizing the hyperparameters using the approximate best-response function. Unlike other gradient-based approaches, we do not require differentiating the training loss with respect to the hyperparameters, allowing us to tune discrete hyperparameters, data augmentation hyperparameters, and dropout probabilities. Because the hyperparameters are adapted online, our approach discovers hyperparameter schedules that can outperform fixed hyperparameter values. Empirically, our approach outperforms competing hyperparameter optimization methods on large-scale deep learning problems. We call our networks, which update their own hyperparameters online during training, Self-Tuning Networks (STNs).
Eigenvalue Corrected Noisy Natural Gradient
Nov 30, 2018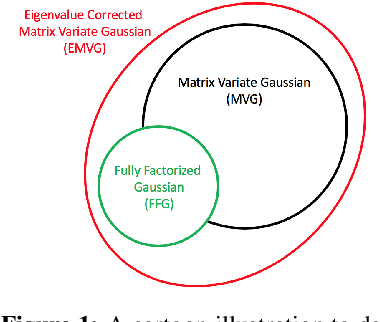
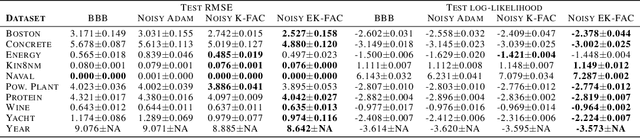
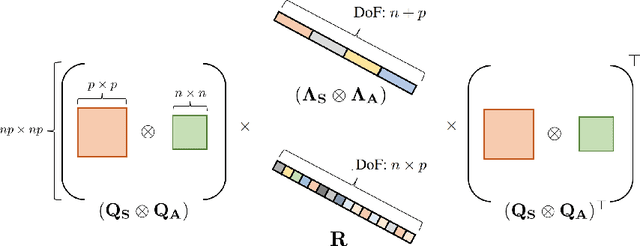
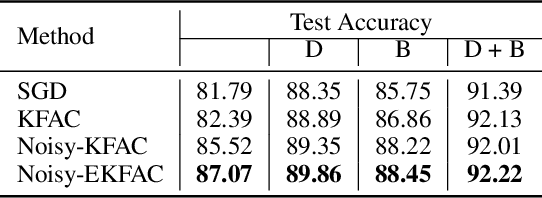
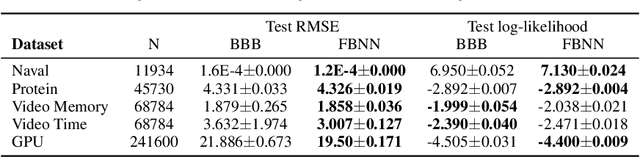
Variational Bayesian neural networks combine the flexibility of deep learning with Bayesian uncertainty estimation. However, inference procedures for flexible variational posteriors are computationally expensive. A recently proposed method, noisy natural gradient, is a surprisingly simple method to fit expressive posteriors by adding weight noise to regular natural gradient updates. Noisy K-FAC is an instance of noisy natural gradient that fits a matrix-variate Gaussian posterior with minor changes to ordinary K-FAC. Nevertheless, a matrix-variate Gaussian posterior does not capture an accurate diagonal variance. In this work, we extend on noisy K-FAC to obtain a more flexible posterior distribution called eigenvalue corrected matrix-variate Gaussian. The proposed method computes the full diagonal re-scaling factor in Kronecker-factored eigenbasis. Empirically, our approach consistently outperforms existing algorithms (e.g., noisy K-FAC) on regression and classification tasks.
Sorting out Lipschitz function approximation
Nov 13, 2018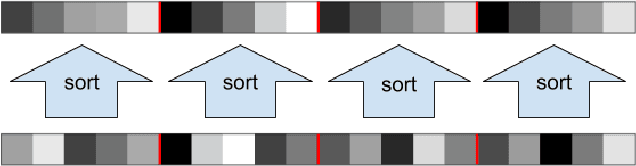
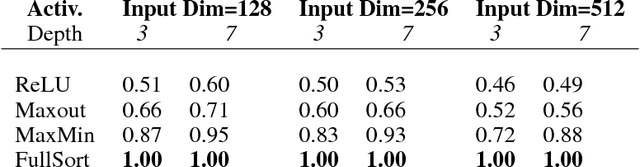
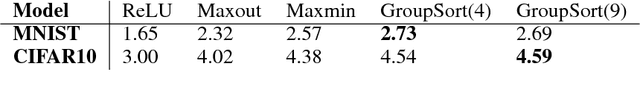
Training neural networks subject to a Lipschitz constraint is useful for generalization bounds, provable adversarial robustness, interpretable gradients, and Wasserstein distance estimation. By the composition property of Lipschitz functions, it suffices to ensure that each individual affine transformation or nonlinear activation function is 1-Lipschitz. The challenge is to do this while maintaining the expressive power. We identify a necessary property for such an architecture: each of the layers must preserve the gradient norm during backpropagation. Based on this, we propose to combine a gradient norm preserving activation function, GroupSort, with norm-constrained weight matrices. We show that norm-constrained GroupSort architectures are universal Lipschitz function approximators. Empirically, we show that norm-constrained GroupSort networks achieve tighter estimates of Wasserstein distance than their ReLU counterparts and can achieve provable adversarial robustness guarantees with little cost to accuracy.
Three Mechanisms of Weight Decay Regularization
Oct 29, 2018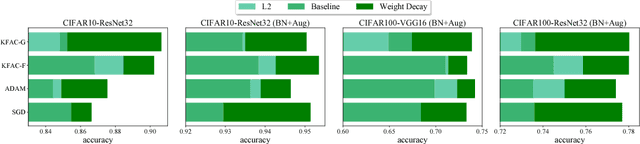
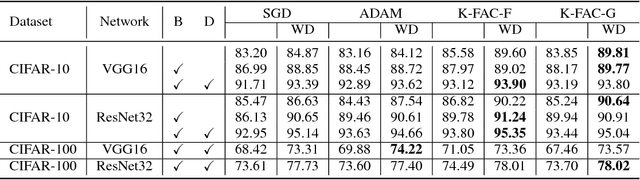
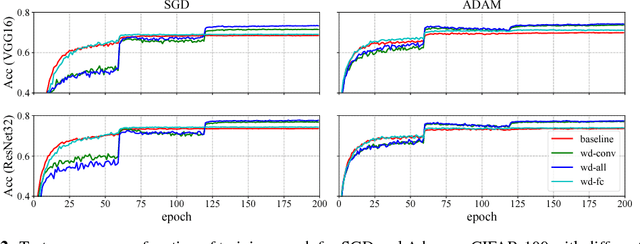
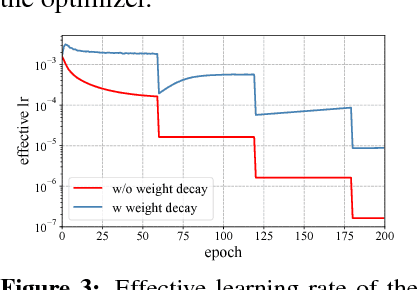
Weight decay is one of the standard tricks in the neural network toolbox, but the reasons for its regularization effect are poorly understood, and recent results have cast doubt on the traditional interpretation in terms of $L_2$ regularization. Literal weight decay has been shown to outperform $L_2$ regularization for optimizers for which they differ. We empirically investigate weight decay for three optimization algorithms (SGD, Adam, and K-FAC) and a variety of network architectures. We identify three distinct mechanisms by which weight decay exerts a regularization effect, depending on the particular optimization algorithm and architecture: (1) increasing the effective learning rate, (2) approximately regularizing the input-output Jacobian norm, and (3) reducing the effective damping coefficient for second-order optimization. Our results provide insight into how to improve the regularization of neural networks.
Reversible Recurrent Neural Networks
Oct 25, 2018

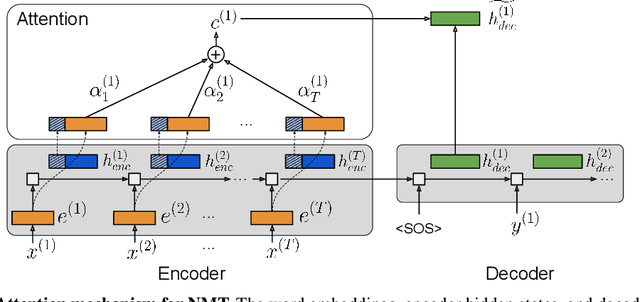
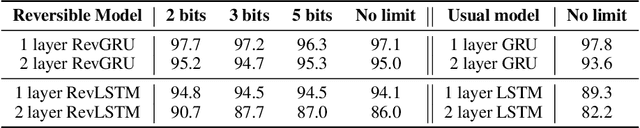
Recurrent neural networks (RNNs) provide state-of-the-art performance in processing sequential data but are memory intensive to train, limiting the flexibility of RNN models which can be trained. Reversible RNNs---RNNs for which the hidden-to-hidden transition can be reversed---offer a path to reduce the memory requirements of training, as hidden states need not be stored and instead can be recomputed during backpropagation. We first show that perfectly reversible RNNs, which require no storage of the hidden activations, are fundamentally limited because they cannot forget information from their hidden state. We then provide a scheme for storing a small number of bits in order to allow perfect reversal with forgetting. Our method achieves comparable performance to traditional models while reducing the activation memory cost by a factor of 10--15. We extend our technique to attention-based sequence-to-sequence models, where it maintains performance while reducing activation memory cost by a factor of 5--10 in the encoder, and a factor of 10--15 in the decoder.
Isolating Sources of Disentanglement in Variational Autoencoders
Oct 22, 2018
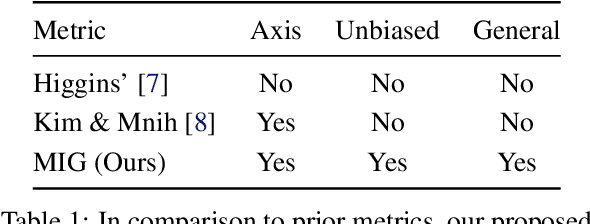
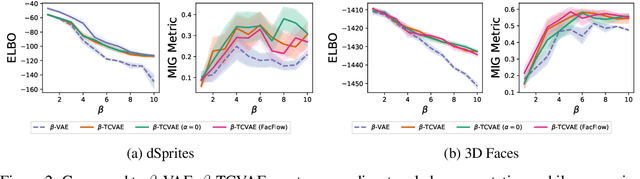
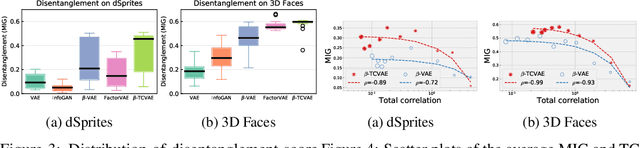
We decompose the evidence lower bound to show the existence of a term measuring the total correlation between latent variables. We use this to motivate our $\beta$-TCVAE (Total Correlation Variational Autoencoder), a refinement of the state-of-the-art $\beta$-VAE objective for learning disentangled representations, requiring no additional hyperparameters during training. We further propose a principled classifier-free measure of disentanglement called the mutual information gap (MIG). We perform extensive quantitative and qualitative experiments, in both restricted and non-restricted settings, and show a strong relation between total correlation and disentanglement, when the latent variables model is trained using our framework.