 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Meta4XNLI: A Crosslingual Parallel Corpus for Metaphor Detection and Interpretation
Apr 10, 2024Metaphors, although occasionally unperceived, are ubiquitous in our everyday language. Thus, it is crucial for Language Models to be able to grasp the underlying meaning of this kind of figurative language. In this work, we present Meta4XNLI, a novel parallel dataset for the tasks of metaphor detection and interpretation that contains metaphor annotations in both Spanish and English. We investigate language models' metaphor identification and understanding abilities through a series of monolingual and cross-lingual experiments by leveraging our proposed corpus. In order to comprehend how these non-literal expressions affect models' performance, we look over the results and perform an error analysis. Additionally, parallel data offers many potential opportunities to investigate metaphor transferability between these languages and the impact of translation on the development of multilingual annotated resources.
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
Apr 08, 2024



Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Evaluating Shortest Edit Script Methods for Contextual Lemmatization
Mar 25, 2024Modern contextual lemmatizers often rely on automatically induced Shortest Edit Scripts (SES), namely, the number of edit operations to transform a word form into its lemma. In fact, different methods of computing SES have been proposed as an integral component in the architecture of several state-of-the-art contextual lemmatizers currently available. However, previous work has not investigated the direct impact of SES in the final lemmatization performance. In this paper we address this issue by focusing on lemmatization as a token classification task where the only input that the model receives is the word-label pairs in context, where the labels correspond to previously induced SES. Thus, by modifying in our lemmatization system only the SES labels that the model needs to learn, we may then objectively conclude which SES representation produces the best lemmatization results. We experiment with seven languages of different morphological complexity, namely, English, Spanish, Basque, Russian, Czech, Turkish and Polish, using multilingual and language-specific pre-trained masked language encoder-only models as a backbone to build our lemmatizers. Comprehensive experimental results, both in- and out-of-domain, indicate that computing the casing and edit operations separately is beneficial overall, but much more clearly for languages with high-inflected morphology. Notably, multilingual pre-trained language models consistently outperform their language-specific counterparts in every evaluation setting.
Basque and Spanish Counter Narrative Generation: Data Creation and Evaluation
Mar 14, 2024



Counter Narratives (CNs) are non-negative textual responses to Hate Speech (HS) aiming at defusing online hatred and mitigating its spreading across media. Despite the recent increase in HS content posted online, research on automatic CN generation has been relatively scarce and predominantly focused on English. In this paper, we present CONAN-EUS, a new Basque and Spanish dataset for CN generation developed by means of Machine Translation (MT) and professional post-edition. Being a parallel corpus, also with respect to the original English CONAN, it allows to perform novel research on multilingual and crosslingual automatic generation of CNs. Our experiments on CN generation with mT5, a multilingual encoder-decoder model, show that generation greatly benefits from training on post-edited data, as opposed to relying on silver MT data only. These results are confirmed by their correlation with a qualitative manual evaluation, demonstrating that manually revised training data remains crucial for the quality of the generated CNs. Furthermore, multilingual data augmentation improves results over monolingual settings for structurally similar languages such as English and Spanish, while being detrimental for Basque, a language isolate. Similar findings occur in zero-shot crosslingual evaluations, where model transfer (fine-tuning in English and generating in a different target language) outperforms fine-tuning mT5 on machine translated data for Spanish but not for Basque. This provides an interesting insight into the asymmetry in the multilinguality of generative models, a challenging topic which is still open to research.
Explanatory Argument Extraction of Correct Answers in Resident Medical Exams
Dec 01, 2023



Developing the required technology to assist medical experts in their everyday activities is currently a hot topic in the Artificial Intelligence research field. Thus, a number of large language models (LLMs) and automated benchmarks have recently been proposed with the aim of facilitating information extraction in Evidence-Based Medicine (EBM) using natural language as a tool for mediating in human-AI interaction. The most representative benchmarks are limited to either multiple-choice or long-form answers and are available only in English. In order to address these shortcomings, in this paper we present a new dataset which, unlike previous work: (i) includes not only explanatory arguments for the correct answer, but also arguments to reason why the incorrect answers are not correct; (ii) the explanations are written originally by medical doctors to answer questions from the Spanish Residency Medical Exams. Furthermore, this new benchmark allows us to setup a novel extractive task which consists of identifying the explanation of the correct answer written by medical doctors. An additional benefit of our setting is that we can leverage the extractive QA paradigm to automatically evaluate performance of LLMs without resorting to costly manual evaluation by medical experts. Comprehensive experimentation with language models for Spanish shows that sometimes multilingual models fare better than monolingual ones, even outperforming models which have been adapted to the medical domain. Furthermore, results across the monolingual models are mixed, with supposedly smaller and inferior models performing competitively. In any case, the obtained results show that our novel dataset and approach can be an effective technique to help medical practitioners in identifying relevant evidence-based explanations for medical questions.
Optimal Strategies to Perform Multilingual Analysis of Social Content for a Novel Dataset in the Tourism Domain
Nov 20, 2023



The rising influence of social media platforms in various domains, including tourism, has highlighted the growing need for efficient and automated natural language processing (NLP) approaches to take advantage of this valuable resource. However, the transformation of multilingual, unstructured, and informal texts into structured knowledge often poses significant challenges. In this work, we evaluate and compare few-shot, pattern-exploiting and fine-tuning machine learning techniques on large multilingual language models (LLMs) to establish the best strategy to address the lack of annotated data for 3 common NLP tasks in the tourism domain: (1) Sentiment Analysis, (2) Named Entity Recognition, and (3) Fine-grained Thematic Concept Extraction (linked to a semantic resource). Furthermore, we aim to ascertain the quantity of annotated examples required to achieve good performance in those 3 tasks, addressing a common challenge encountered by NLP researchers in the construction of domain-specific datasets. Extensive experimentation on a newly collected and annotated multilingual (French, English, and Spanish) dataset composed of tourism-related tweets shows that current few-shot learning techniques allow us to obtain competitive results for all three tasks with very little annotation data: 5 tweets per label (15 in total) for Sentiment Analysis, 10% of the tweets for location detection (around 160) and 13% (200 approx.) of the tweets annotated with thematic concepts, a highly fine-grained sequence labeling task based on an inventory of 315 classes. This comparative analysis, grounded in a novel dataset, paves the way for applying NLP to new domain-specific applications, reducing the need for manual annotations and circumventing the complexities of rule-based, ad hoc solutions.
GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction
Oct 06, 2023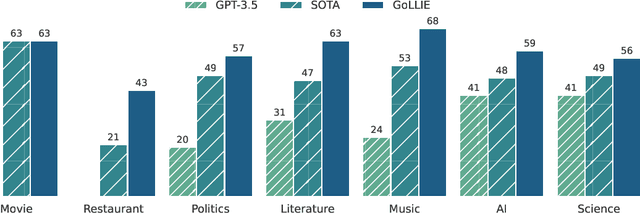
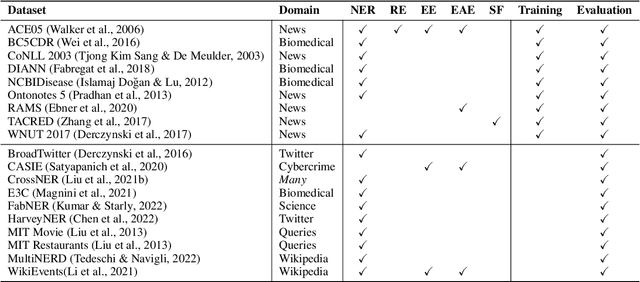

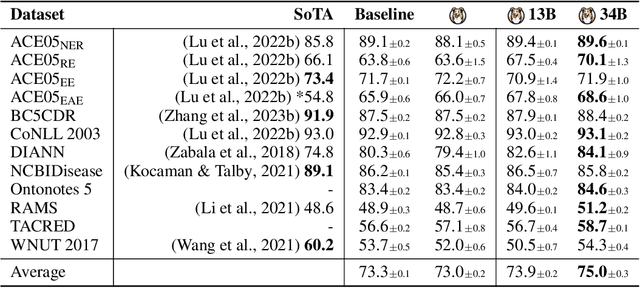
Large Language Models (LLMs) combined with instruction tuning have made significant progress when generalizing to unseen tasks. However, they have been less successful in Information Extraction (IE), lagging behind task-specific models. Typically, IE tasks are characterized by complex annotation guidelines which describe the task and give examples to humans. Previous attempts to leverage such information have failed, even with the largest models, as they are not able to follow the guidelines out-of-the-box. In this paper we propose GoLLIE (Guideline-following Large Language Model for IE), a model able to improve zero-shot results on unseen IE tasks by virtue of being fine-tuned to comply with annotation guidelines. Comprehensive evaluation empirically demonstrates that GoLLIE is able to generalize to and follow unseen guidelines, outperforming previous attempts at zero-shot information extraction. The ablation study shows that detailed guidelines is key for good results.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023

Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.
A Modular Approach for Multilingual Timex Detection and Normalization using Deep Learning and Grammar-based methods
Apr 27, 2023



Detecting and normalizing temporal expressions is an essential step for many NLP tasks. While a variety of methods have been proposed for detection, best normalization approaches rely on hand-crafted rules. Furthermore, most of them have been designed only for English. In this paper we present a modular multilingual temporal processing system combining a fine-tuned Masked Language Model for detection, and a grammar-based normalizer. We experiment in Spanish and English and compare with HeidelTime, the state-of-the-art in multilingual temporal processing. We obtain best results in gold timex normalization, timex detection and type recognition, and competitive performance in the combined TempEval-3 relaxed value metric. A detailed error analysis shows that detecting only those timexes for which it is feasible to provide a normalization is highly beneficial in this last metric. This raises the question of which is the best strategy for timex processing, namely, leaving undetected those timexes for which is not easy to provide normalization rules or aiming for high coverage.