 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Prompting in Instruction-tuned LLMs for Joint Argumentative Component Detection
Mar 03, 2026Argumentative component detection (ACD) is a core subtask of Argument(ation) Mining (AM) and one of its most challenging aspects, as it requires jointly delimiting argumentative spans and classifying them into components such as claims and premises. While research on this subtask remains relatively limited compared to other AM tasks, most existing approaches formulate it as a simplified sequence labeling problem, component classification, or a pipeline of component segmentation followed by classification. In this paper, we propose a novel approach based on instruction-tuned Large Language Models (LLMs) using compact instruction-based prompts, and reframe ACD as a language generation task, enabling arguments to be identified directly from plain text without relying on pre-segmented components. Experiments on standard benchmarks show that our approach achieves higher performance compared to state-of-the-art systems. To the best of our knowledge, this is one of the first attempts to fully model ACD as a generative task, highlighting the potential of instruction tuning for complex AM problems.
PEACE 2.0: Grounded Explanations and Counter-Speech for Combating Hate Expressions
Feb 19, 2026The increasing volume of hate speech on online platforms poses significant societal challenges. While the Natural Language Processing community has developed effective methods to automatically detect the presence of hate speech, responses to it, called counter-speech, are still an open challenge. We present PEACE 2.0, a novel tool that, besides analysing and explaining why a message is considered hateful or not, also generates a response to it. More specifically, PEACE 2.0 has three main new functionalities: leveraging a Retrieval-Augmented Generation (RAG) pipeline i) to ground HS explanations into evidence and facts, ii) to automatically generate evidence-grounded counter-speech, and iii) exploring the characteristics of counter-speech replies. By integrating these capabilities, PEACE 2.0 enables in-depth analysis and response generation for both explicit and implicit hateful messages.
Stakeholder Suite: A Unified AI Framework for Mapping Actors, Topics and Arguments in Public Debates
Dec 19, 2025Public debates surrounding infrastructure and energy projects involve complex networks of stakeholders, arguments, and evolving narratives. Understanding these dynamics is crucial for anticipating controversies and informing engagement strategies, yet existing tools in media intelligence largely rely on descriptive analytics with limited transparency. This paper presents Stakeholder Suite, a framework deployed in operational contexts for mapping actors, topics, and arguments within public debates. The system combines actor detection, topic modeling, argument extraction and stance classification in a unified pipeline. Tested on multiple energy infrastructure projects as a case study, the approach delivers fine-grained, source-grounded insights while remaining adaptable to diverse domains. The framework achieves strong retrieval precision and stance accuracy, producing arguments judged relevant in 75% of pilot use cases. Beyond quantitative metrics, the tool has proven effective for operational use: helping project teams visualize networks of influence, identify emerging controversies, and support evidence-based decision-making.
Beating Harmful Stereotypes Through Facts: RAG-based Counter-speech Generation
Oct 14, 2025Counter-speech generation is at the core of many expert activities, such as fact-checking and hate speech, to counter harmful content. Yet, existing work treats counter-speech generation as pure text generation task, mainly based on Large Language Models or NGO experts. These approaches show severe drawbacks due to the limited reliability and coherence in the generated countering text, and in scalability, respectively. To close this gap, we introduce a novel framework to model counter-speech generation as knowledge-wise text generation process. Our framework integrates advanced Retrieval-Augmented Generation (RAG) pipelines to ensure the generation of trustworthy counter-speech for 8 main target groups identified in the hate speech literature, including women, people of colour, persons with disabilities, migrants, Muslims, Jews, LGBT persons, and other. We built a knowledge base over the United Nations Digital Library, EUR-Lex and the EU Agency for Fundamental Rights, comprising a total of 32,792 texts. We use the MultiTarget-CONAN dataset to empirically assess the quality of the generated counter-speech, both through standard metrics (i.e., JudgeLM) and a human evaluation. Results show that our framework outperforms standard LLM baselines and competitive approach, on both assessments. The resulting framework and the knowledge base pave the way for studying trustworthy and sound counter-speech generation, in hate speech and beyond.
Effectiveness of Counter-Speech against Abusive Content: A Multidimensional Annotation and Classification Study
Jun 13, 2025Counter-speech (CS) is a key strategy for mitigating online Hate Speech (HS), yet defining the criteria to assess its effectiveness remains an open challenge. We propose a novel computational framework for CS effectiveness classification, grounded in social science concepts. Our framework defines six core dimensions - Clarity, Evidence, Emotional Appeal, Rebuttal, Audience Adaptation, and Fairness - which we use to annotate 4,214 CS instances from two benchmark datasets, resulting in a novel linguistic resource released to the community. In addition, we propose two classification strategies, multi-task and dependency-based, achieving strong results (0.94 and 0.96 average F1 respectively on both expert- and user-written CS), outperforming standard baselines, and revealing strong interdependence among dimensions.
CasiMedicos-Arg: A Medical Question Answering Dataset Annotated with Explanatory Argumentative Structures
Oct 07, 2024Explaining Artificial Intelligence (AI) decisions is a major challenge nowadays in AI, in particular when applied to sensitive scenarios like medicine and law. However, the need to explain the rationale behind decisions is a main issue also for human-based deliberation as it is important to justify \textit{why} a certain decision has been taken. Resident medical doctors for instance are required not only to provide a (possibly correct) diagnosis, but also to explain how they reached a certain conclusion. Developing new tools to aid residents to train their explanation skills is therefore a central objective of AI in education. In this paper, we follow this direction, and we present, to the best of our knowledge, the first multilingual dataset for Medical Question Answering where correct and incorrect diagnoses for a clinical case are enriched with a natural language explanation written by doctors. These explanations have been manually annotated with argument components (i.e., premise, claim) and argument relations (i.e., attack, support), resulting in the Multilingual CasiMedicos-Arg dataset which consists of 558 clinical cases in four languages (English, Spanish, French, Italian) with explanations, where we annotated 5021 claims, 2313 premises, 2431 support relations, and 1106 attack relations. We conclude by showing how competitive baselines perform over this challenging dataset for the argument mining task.
* 9 pages
Is Safer Better? The Impact of Guardrails on the Argumentative Strength of LLMs in Hate Speech Countering
Oct 04, 2024The potential effectiveness of counterspeech as a hate speech mitigation strategy is attracting increasing interest in the NLG research community, particularly towards the task of automatically producing it. However, automatically generated responses often lack the argumentative richness which characterises expert-produced counterspeech. In this work, we focus on two aspects of counterspeech generation to produce more cogent responses. First, by investigating the tension between helpfulness and harmlessness of LLMs, we test whether the presence of safety guardrails hinders the quality of the generations. Secondly, we assess whether attacking a specific component of the hate speech results in a more effective argumentative strategy to fight online hate. By conducting an extensive human and automatic evaluation, we show how the presence of safety guardrails can be detrimental also to a task that inherently aims at fostering positive social interactions. Moreover, our results show that attacking a specific component of the hate speech, and in particular its implicit negative stereotype and its hateful parts, leads to higher-quality generations.
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024



Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Argument Quality Assessment in the Age of Instruction-Following Large Language Models
Mar 24, 2024


The computational treatment of arguments on controversial issues has been subject to extensive NLP research, due to its envisioned impact on opinion formation, decision making, writing education, and the like. A critical task in any such application is the assessment of an argument's quality - but it is also particularly challenging. In this position paper, we start from a brief survey of argument quality research, where we identify the diversity of quality notions and the subjectiveness of their perception as the main hurdles towards substantial progress on argument quality assessment. We argue that the capabilities of instruction-following large language models (LLMs) to leverage knowledge across contexts enable a much more reliable assessment. Rather than just fine-tuning LLMs towards leaderboard chasing on assessment tasks, they need to be instructed systematically with argumentation theories and scenarios as well as with ways to solve argument-related problems. We discuss the real-world opportunities and ethical issues emerging thereby.
A Dataset Independent Set of Baselines for Relation Prediction in Argument Mining
Feb 14, 2020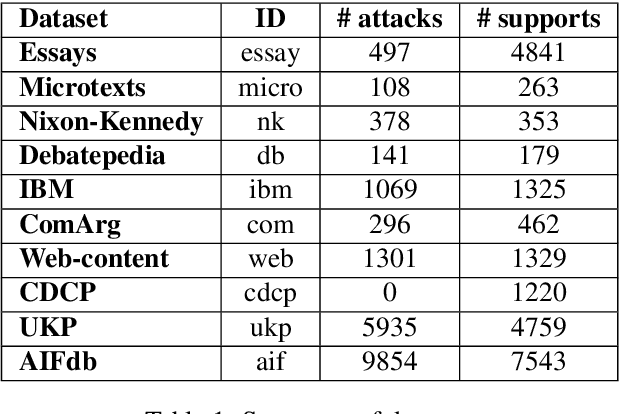
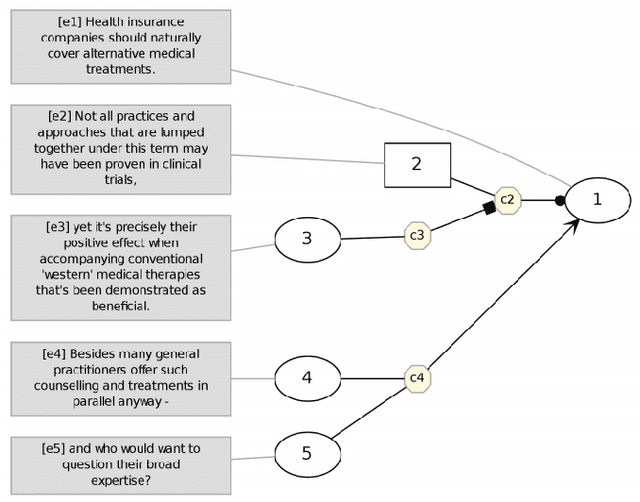
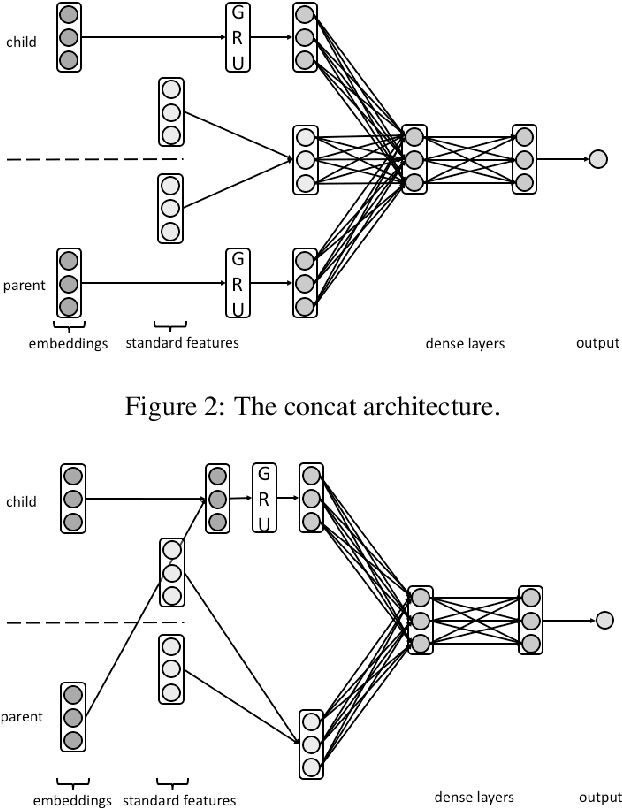
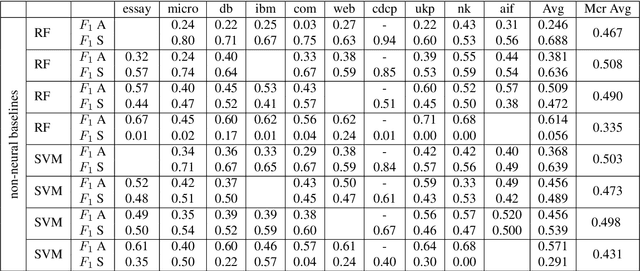
Argument Mining is the research area which aims at extracting argument components and predicting argumentative relations (i.e.,support and attack) from text. In particular, numerous approaches have been proposed in the literature to predict the relations holding between the arguments, and application-specific annotated resources were built for this purpose. Despite the fact that these resources have been created to experiment on the same task, the definition of a single relation prediction method to be successfully applied to a significant portion of these datasets is an open research problem in Argument Mining. This means that none of the methods proposed in the literature can be easily ported from one resource to another. In this paper, we address this problem by proposing a set of dataset independent strong neural baselines which obtain homogeneous results on all the datasets proposed in the literature for the argumentative relation prediction task. Thus, our baselines can be employed by the Argument Mining community to compare more effectively how well a method performs on the argumentative relation prediction task.