 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022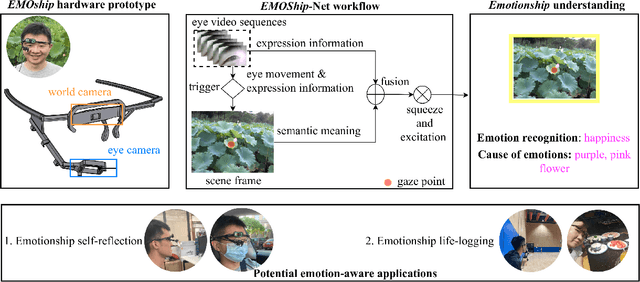

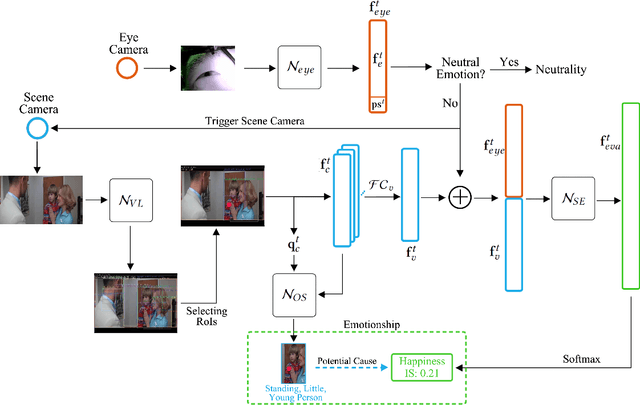
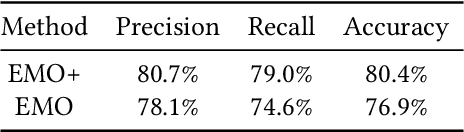
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
Beyond BatchNorm: Towards a General Understanding of Normalization in Deep Learning
Jul 08, 2021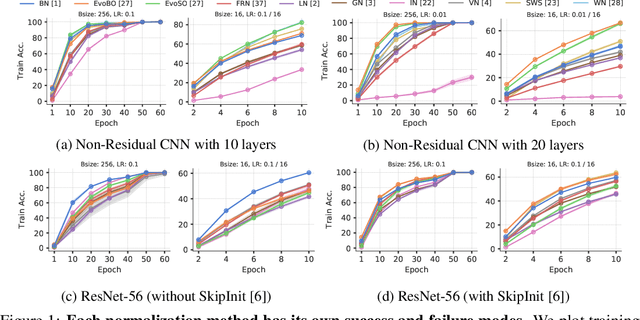

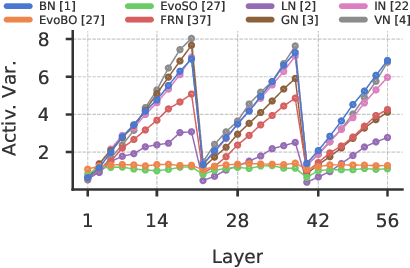
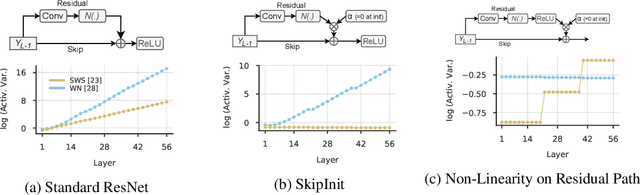
Inspired by BatchNorm, there has been an explosion of normalization layers for deep neural networks (DNNs). However, these alternative normalization layers have seen minimal use, partially due to a lack of guiding principles that can help identify when these layers can serve as a replacement for BatchNorm. To address this problem, we take a theoretical approach, generalizing the known beneficial mechanisms of BatchNorm to several recently proposed normalization techniques. Our generalized theory leads to the following set of principles: (i) similar to BatchNorm, activations-based normalization layers can prevent exponential growth of activations in ResNets, but parametric layers require explicit remedies; (ii) use of GroupNorm can ensure informative forward propagation, with different samples being assigned dissimilar activations, but increasing group size results in increasingly indistinguishable activations for different samples, explaining slow convergence speed in models with LayerNorm; (iii) small group sizes result in large gradient norm in earlier layers, hence explaining training instability issues in Instance Normalization and illustrating a speed-stability tradeoff in GroupNorm. Overall, our analysis reveals a unified set of mechanisms that underpin the success of normalization methods in deep learning, providing us with a compass to systematically explore the vast design space of DNN normalization layers.
MemX: An Attention-Aware Smart Eyewear System for Personalized Moment Auto-capture
May 03, 2021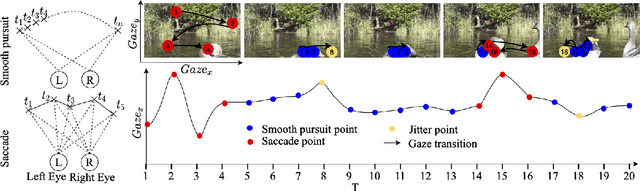

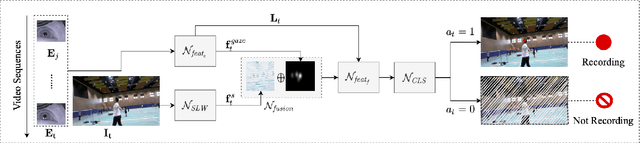
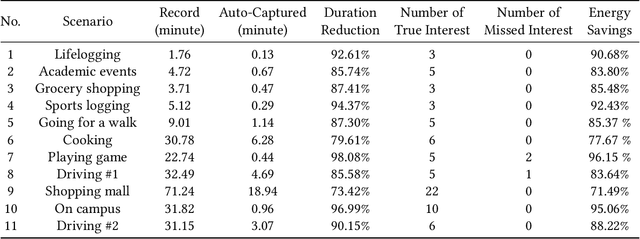
This work presents MemX: a biologically-inspired attention-aware eyewear system developed with the goal of pursuing the long-awaited vision of a personalized visual Memex. MemX captures human visual attention on the fly, analyzes the salient visual content, and records moments of personal interest in the form of compact video snippets. Accurate attentive scene detection and analysis on resource-constrained platforms is challenging because these tasks are computation and energy intensive. We propose a new temporal visual attention network that unifies human visual attention tracking and salient visual content analysis. Attention tracking focuses computation-intensive video analysis on salient regions, while video analysis makes human attention detection and tracking more accurate. Using the YouTube-VIS dataset and 30 participants, we experimentally show that MemX significantly improves the attention tracking accuracy over the eye-tracking-alone method, while maintaining high system energy efficiency. We have also conducted 11 in-field pilot studies across a range of daily usage scenarios, which demonstrate the feasibility and potential benefits of MemX.
A Reinforcement-Learning-Based Energy-Efficient Framework for Multi-Task Video Analytics Pipeline
May 02, 2021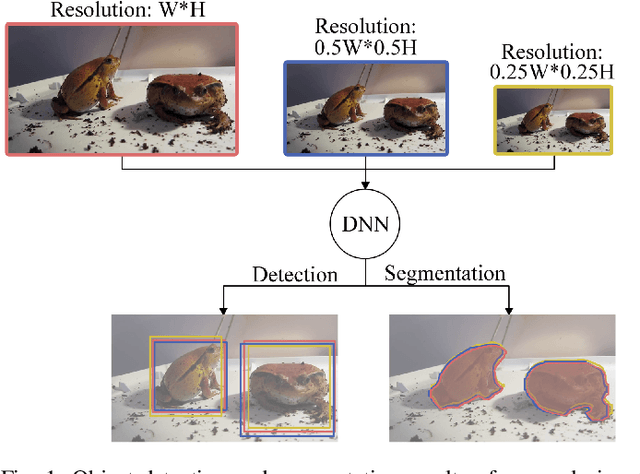
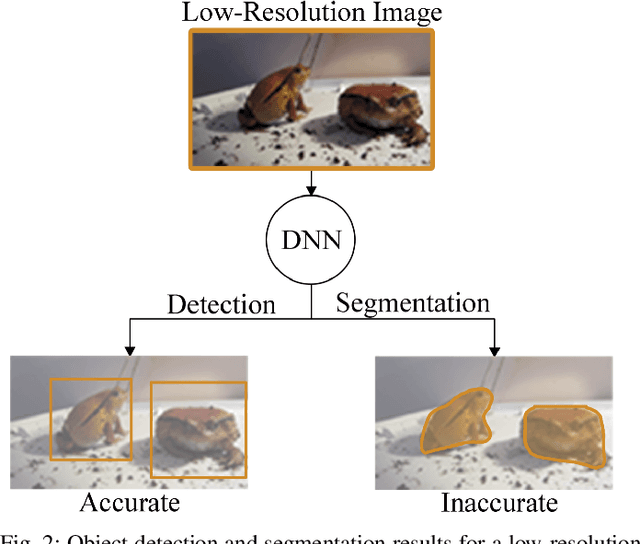
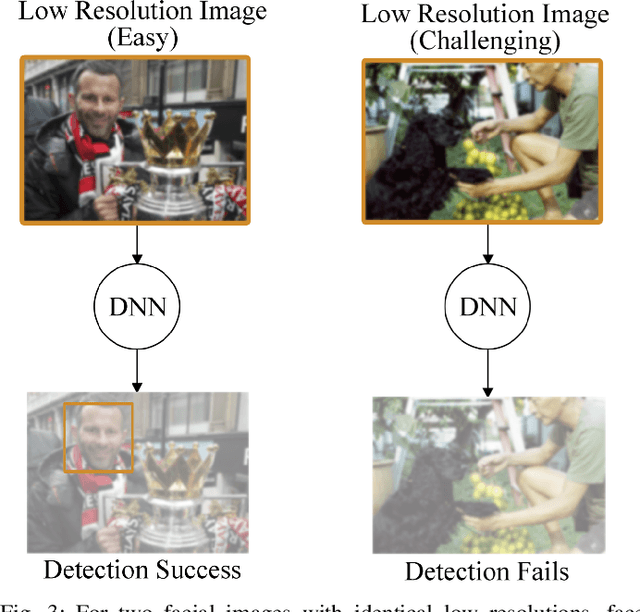
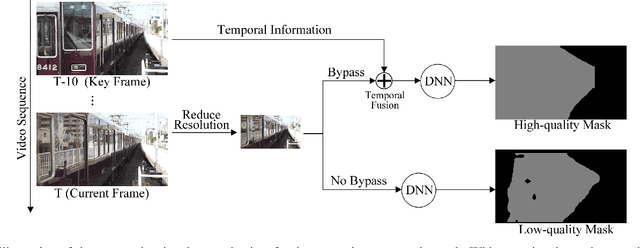
Deep-learning-based video processing has yielded transformative results in recent years. However, the video analytics pipeline is energy-intensive due to high data rates and reliance on complex inference algorithms, which limits its adoption in energy-constrained applications. Motivated by the observation of high and variable spatial redundancy and temporal dynamics in video data streams, we design and evaluate an adaptive-resolution optimization framework to minimize the energy use of multi-task video analytics pipelines. Instead of heuristically tuning the input data resolution of individual tasks, our framework utilizes deep reinforcement learning to dynamically govern the input resolution and computation of the entire video analytics pipeline. By monitoring the impact of varying resolution on the quality of high-dimensional video analytics features, hence the accuracy of video analytics results, the proposed end-to-end optimization framework learns the best non-myopic policy for dynamically controlling the resolution of input video streams to globally optimize energy efficiency. Governed by reinforcement learning, optical flow is incorporated into the framework to minimize unnecessary spatio-temporal redundancy that leads to re-computation, while preserving accuracy. The proposed framework is applied to video instance segmentation which is one of the most challenging computer vision tasks, and achieves better energy efficiency than all baseline methods of similar accuracy on the YouTube-VIS dataset.
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021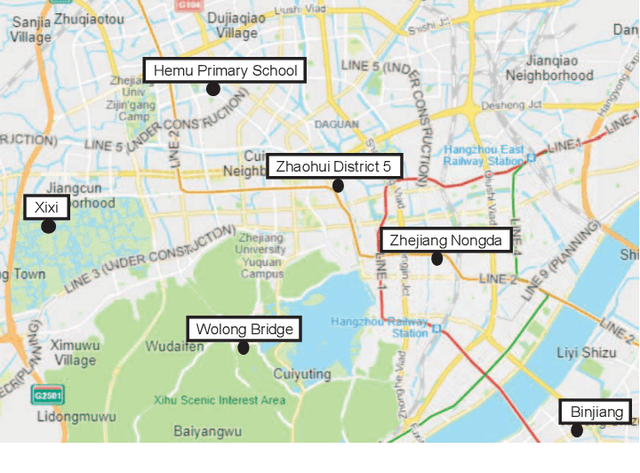
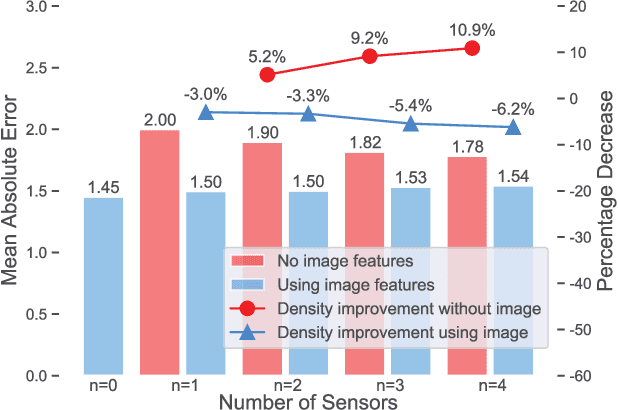
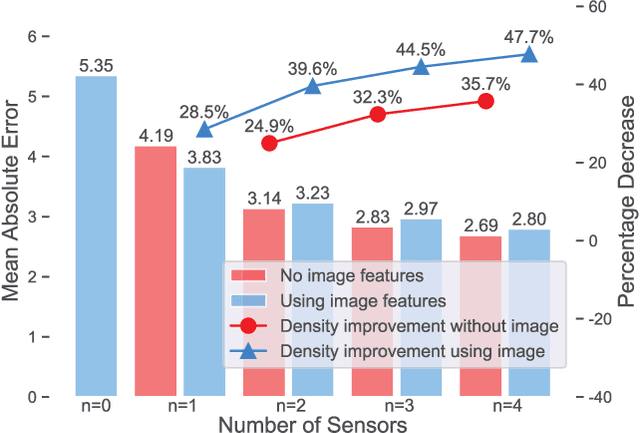
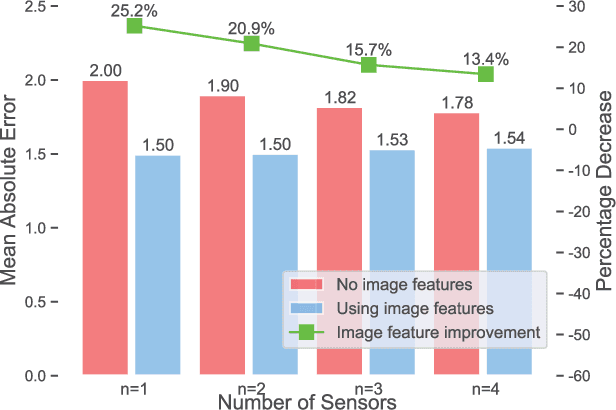
Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.
Rethinking Quadratic Regularizers: Explicit Movement Regularization for Continual Learning
Feb 04, 2021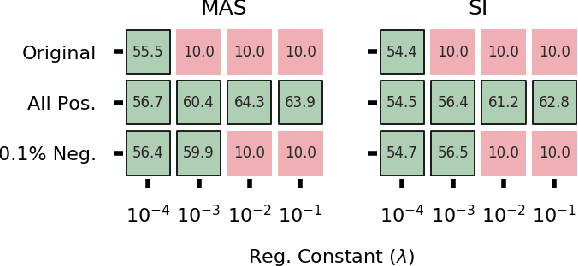
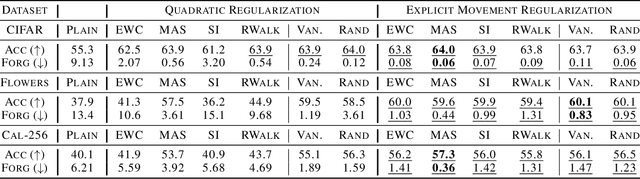
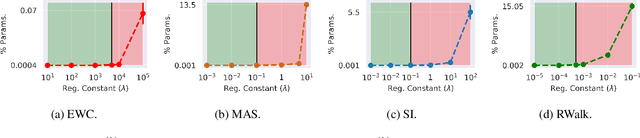
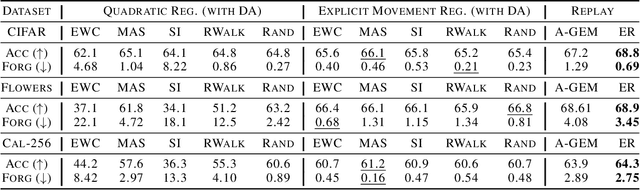
Quadratic regularizers are often used for mitigating catastrophic forgetting in deep neural networks (DNNs), but are unable to compete with recent continual learning methods. To understand this behavior, we analyze parameter updates under quadratic regularization and demonstrate such regularizers prevent forgetting of past tasks by implicitly performing a weighted average between current and previous values of model parameters. Our analysis shows the inferior performance of quadratic regularizers arises from (a) dependence of weighted averaging on training hyperparameters, which often results in unstable training and (b) assignment of lower importance to deeper layers, which are generally the cause for forgetting in DNNs. To address these limitations, we propose Explicit Movement Regularization (EMR), a continual learning algorithm that modifies quadratic regularization to remove the dependence of weighted averaging on training hyperparameters and uses a relative measure for importance to avoid problems caused by lower importance assignment to deeper layers. Compared to quadratic regularization, EMR achieves 6.2% higher average accuracy and 4.5% lower average forgetting.
A Gradient Flow Framework For Analyzing Network Pruning
Oct 02, 2020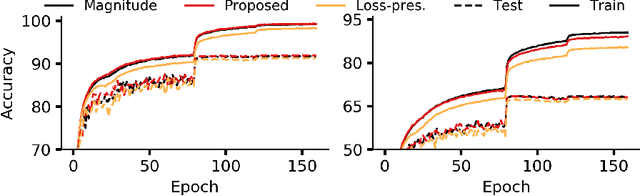
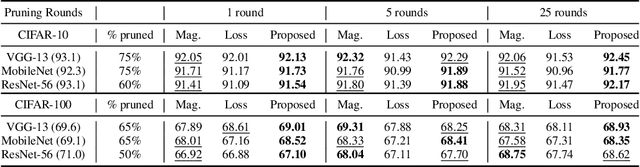
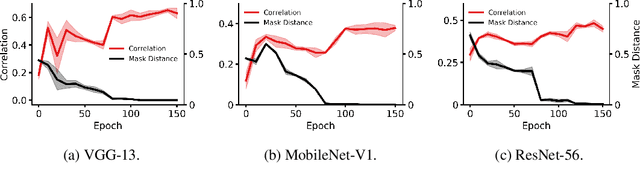
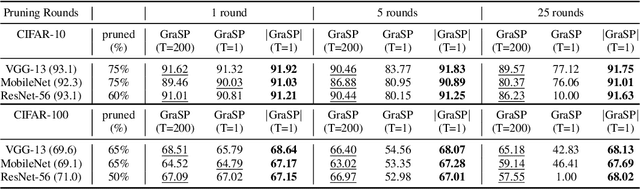
Recent network pruning methods focus on pruning models early-on in training. To estimate the impact of removing a parameter, these methods use importance measures that were originally designed to prune trained models. Despite lacking justification for their use early-on in training, such measures result in surprisingly low accuracy loss. To better explain this behavior, we develop a general gradient flow based framework that unifies state-of-the-art importance measures through the norm of model parameters. We use this framework to determine the relationship between pruning measures and evolution of model parameters, establishing several results related to pruning models early-on in training: (i) magnitude-based pruning removes parameters that contribute least to reduction in loss, resulting in models that converge faster than magnitude-agnostic methods; (ii) loss-preservation based pruning preserves first-order model evolution dynamics and is therefore appropriate for pruning minimally trained models; and (iii) gradient-norm based pruning affects second-order model evolution dynamics, such that increasing gradient norm via pruning can produce poorly performing models. We validate our claims on several VGG-13, MobileNet-V1, and ResNet-56 models trained on CIFAR-10 and CIFAR-100. Code available at https://github.com/EkdeepSLubana/flowandprune.
OrthoReg: Robust Network Pruning Using Orthonormality Regularization
Sep 10, 2020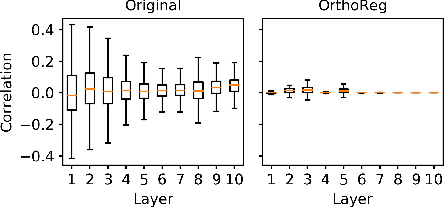
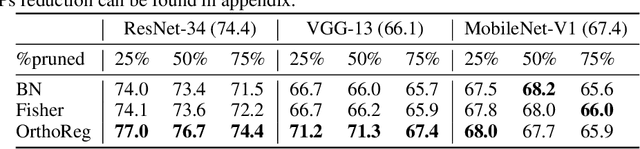
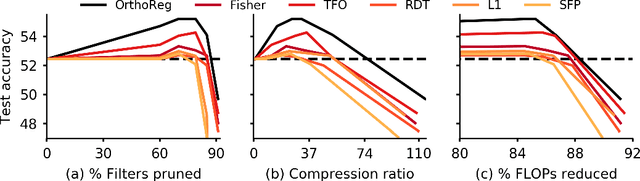
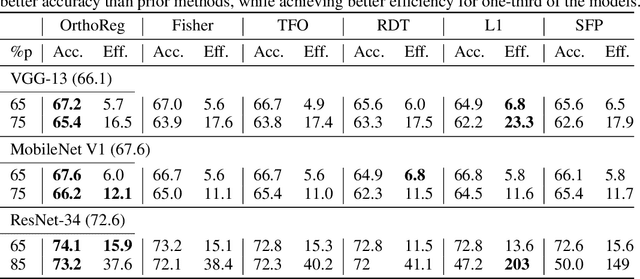
Network pruning in Convolutional Neural Networks (CNNs) has been extensively investigated in recent years. To determine the impact of pruning a group of filters on a network's accuracy, state-of-the-art pruning methods consistently assume filters of a CNN are independent. This allows the importance of a group of filters to be estimated as the sum of importances of individual filters. However, overparameterization in modern networks results in highly correlated filters that invalidate this assumption, thereby resulting in incorrect importance estimates. To address this issue, we propose OrthoReg, a principled regularization strategy that enforces orthonormality on a network's filters to reduce inter-filter correlation, thereby allowing reliable, efficient determination of group importance estimates, improved trainability of pruned networks, and efficient, simultaneous pruning of large groups of filters. When used for iterative pruning on VGG-13, MobileNet-V1, and ResNet-34, OrthoReg consistently outperforms five baseline techniques, including the state-of-the-art, on CIFAR-100 and Tiny-ImageNet. For the recently proposed Early-Bird Ticket hypothesis, which claims networks become amenable to pruning early-on in training and can be pruned after a few epochs to minimize training expenditure, we find OrthoReg significantly outperforms prior work. Code available at https://github.com/EkdeepSLubana/OrthoReg.