 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Diffusion
Feb 07, 2023Denoising diffusion models have spurred significant gains in density modeling and image generation, precipitating an industrial revolution in text-guided AI art generation. We introduce a new mathematical foundation for diffusion models inspired by classic results in information theory that connect Information with Minimum Mean Square Error regression, the so-called I-MMSE relations. We generalize the I-MMSE relations to exactly relate the data distribution to an optimal denoising regression problem, leading to an elegant refinement of existing diffusion bounds. This new insight leads to several improvements for probability distribution estimation, including theoretical justification for diffusion model ensembling. Remarkably, our framework shows how continuous and discrete probabilities can be learned with the same regression objective, avoiding domain-specific generative models used in variational methods. Code to reproduce experiments is provided at http://github.com/kxh001/ITdiffusion and simplified demonstration code is at http://github.com/gregversteeg/InfoDiffusionSimple.
Rho-Tau Bregman Information and the Geometry of Annealing Paths
Sep 15, 2022


Markov Chain Monte Carlo methods for sampling from complex distributions and estimating normalization constants often simulate samples from a sequence of intermediate distributions along an annealing path, which bridges between a tractable initial distribution and a target density of interest. Prior work has constructed annealing paths using quasi-arithmetic means, and interpreted the resulting intermediate densities as minimizing an expected divergence to the endpoints. We provide a comprehensive analysis of this 'centroid' property using Bregman divergences under a monotonic embedding of the density function, thereby associating common divergences such as Amari's and Renyi's ${\alpha}$-divergences, ${(\alpha,\beta)}$-divergences, and the Jensen-Shannon divergence with intermediate densities along an annealing path. Our analysis highlights the interplay between parametric families, quasi-arithmetic means, and divergence functions using the rho-tau Bregman divergence framework of Zhang 2004;2013.
Your Policy Regularizer is Secretly an Adversary
Apr 01, 2022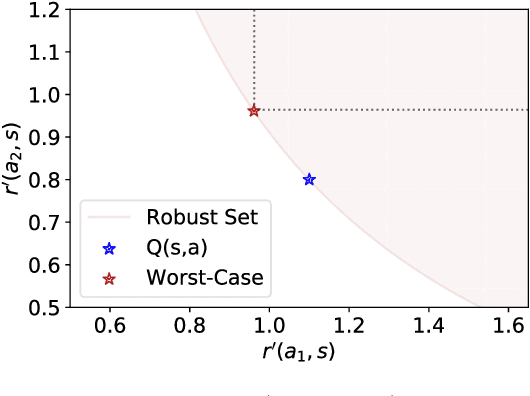

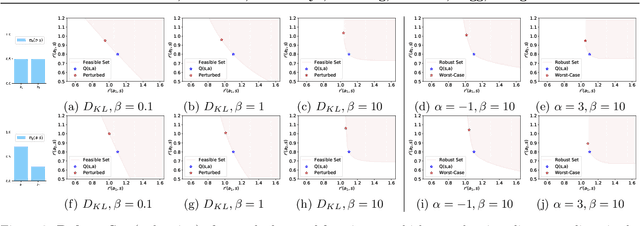

Policy regularization methods such as maximum entropy regularization are widely used in reinforcement learning to improve the robustness of a learned policy. In this paper, we show how this robustness arises from hedging against worst-case perturbations of the reward function, which are chosen from a limited set by an imagined adversary. Using convex duality, we characterize this robust set of adversarial reward perturbations under KL and alpha-divergence regularization, which includes Shannon and Tsallis entropy regularization as special cases. Importantly, generalization guarantees can be given within this robust set. We provide detailed discussion of the worst-case reward perturbations, and present intuitive empirical examples to illustrate this robustness and its relationship with generalization. Finally, we discuss how our analysis complements and extends previous results on adversarial reward robustness and path consistency optimality conditions.
Model-Free Risk-Sensitive Reinforcement Learning
Nov 04, 2021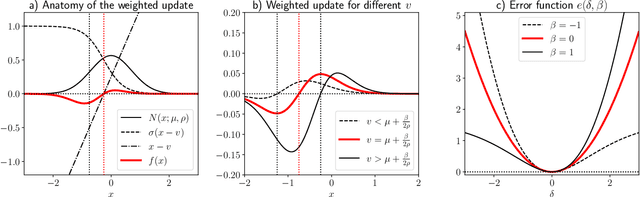
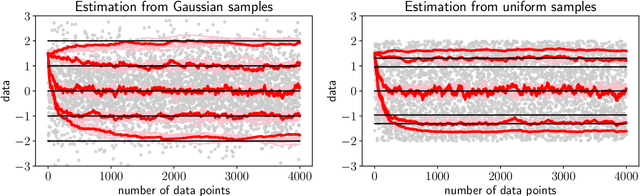
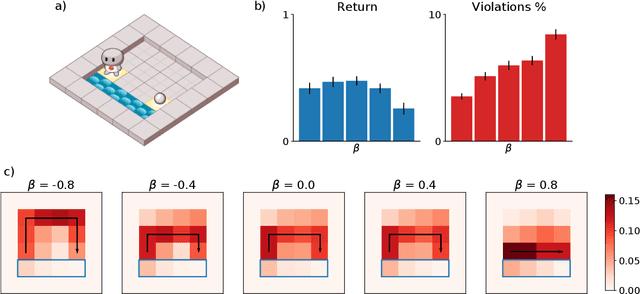

We extend temporal-difference (TD) learning in order to obtain risk-sensitive, model-free reinforcement learning algorithms. This extension can be regarded as modification of the Rescorla-Wagner rule, where the (sigmoidal) stimulus is taken to be either the event of over- or underestimating the TD target. As a result, one obtains a stochastic approximation rule for estimating the free energy from i.i.d. samples generated by a Gaussian distribution with unknown mean and variance. Since the Gaussian free energy is known to be a certainty-equivalent sensitive to the mean and the variance, the learning rule has applications in risk-sensitive decision-making.
q-Paths: Generalizing the Geometric Annealing Path using Power Means
Jul 01, 2021
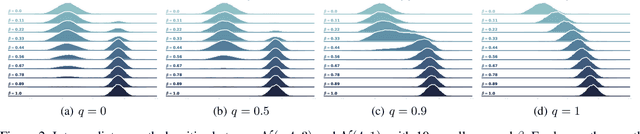
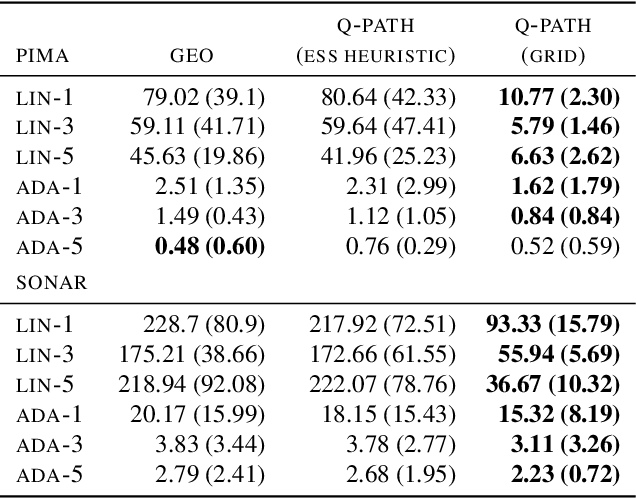

Many common machine learning methods involve the geometric annealing path, a sequence of intermediate densities between two distributions of interest constructed using the geometric average. While alternatives such as the moment-averaging path have demonstrated performance gains in some settings, their practical applicability remains limited by exponential family endpoint assumptions and a lack of closed form energy function. In this work, we introduce $q$-paths, a family of paths which is derived from a generalized notion of the mean, includes the geometric and arithmetic mixtures as special cases, and admits a simple closed form involving the deformed logarithm function from nonextensive thermodynamics. Following previous analysis of the geometric path, we interpret our $q$-paths as corresponding to a $q$-exponential family of distributions, and provide a variational representation of intermediate densities as minimizing a mixture of $\alpha$-divergences to the endpoints. We show that small deviations away from the geometric path yield empirical gains for Bayesian inference using Sequential Monte Carlo and generative model evaluation using Annealed Importance Sampling.
Likelihood Ratio Exponential Families
Jan 15, 2021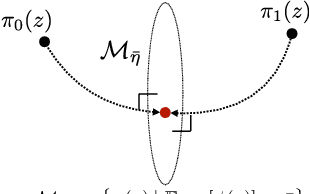
The exponential family is well known in machine learning and statistical physics as the maximum entropy distribution subject to a set of observed constraints, while the geometric mixture path is common in MCMC methods such as annealed importance sampling. Linking these two ideas, recent work has interpreted the geometric mixture path as an exponential family of distributions to analyze the thermodynamic variational objective (TVO). We extend these likelihood ratio exponential families to include solutions to rate-distortion (RD) optimization, the information bottleneck (IB) method, and recent rate-distortion-classification approaches which combine RD and IB. This provides a common mathematical framework for understanding these methods via the conjugate duality of exponential families and hypothesis testing. Further, we collect existing results to provide a variational representation of intermediate RD or TVO distributions as a minimizing an expectation of KL divergences. This solution also corresponds to a size-power tradeoff using the likelihood ratio test and the Neyman Pearson lemma. In thermodynamic integration bounds such as the TVO, we identify the intermediate distribution whose expected sufficient statistics match the log partition function.
Annealed Importance Sampling with q-Paths
Dec 14, 2020
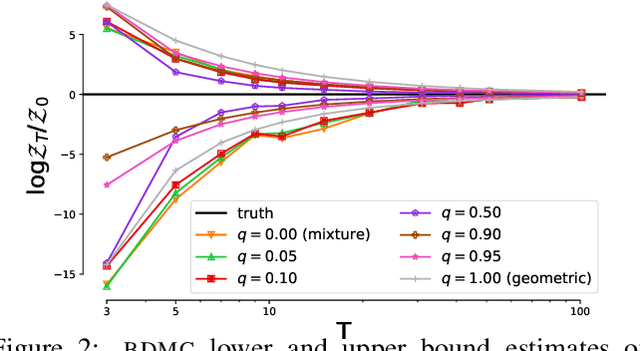

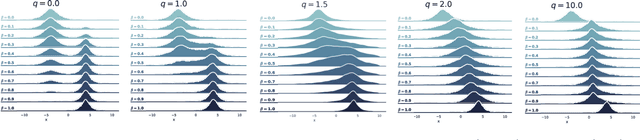
Annealed importance sampling (AIS) is the gold standard for estimating partition functions or marginal likelihoods, corresponding to importance sampling over a path of distributions between a tractable base and an unnormalized target. While AIS yields an unbiased estimator for any path, existing literature has been primarily limited to the geometric mixture or moment-averaged paths associated with the exponential family and KL divergence. We explore AIS using $q$-paths, which include the geometric path as a special case and are related to the homogeneous power mean, deformed exponential family, and $\alpha$-divergence.
Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective
Oct 31, 2020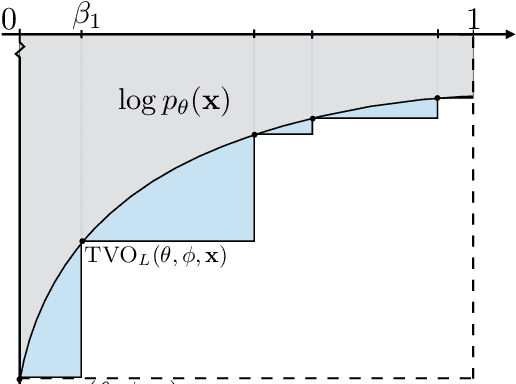

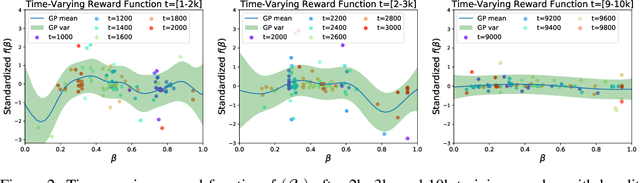

Achieving the full promise of the Thermodynamic Variational Objective (TVO), a recently proposed variational lower bound on the log evidence involving a one-dimensional Riemann integral approximation, requires choosing a "schedule" of sorted discretization points. This paper introduces a bespoke Gaussian process bandit optimization method for automatically choosing these points. Our approach not only automates their one-time selection, but also dynamically adapts their positions over the course of optimization, leading to improved model learning and inference. We provide theoretical guarantees that our bandit optimization converges to the regret-minimizing choice of integration points. Empirical validation of our algorithm is provided in terms of improved learning and inference in Variational Autoencoders and Sigmoid Belief Networks.
All in the Exponential Family: Bregman Duality in Thermodynamic Variational Inference
Jul 01, 2020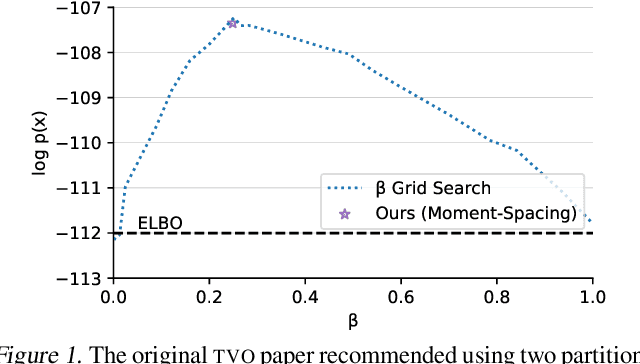

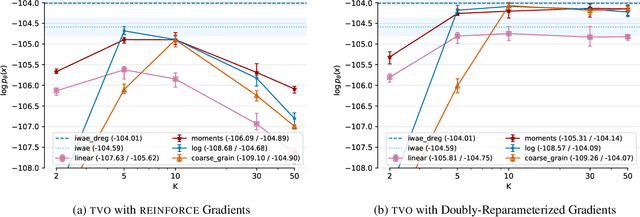
The recently proposed Thermodynamic Variational Objective (TVO) leverages thermodynamic integration to provide a family of variational inference objectives, which both tighten and generalize the ubiquitous Evidence Lower Bound (ELBO). However, the tightness of TVO bounds was not previously known, an expensive grid search was used to choose a "schedule" of intermediate distributions, and model learning suffered with ostensibly tighter bounds. In this work, we propose an exponential family interpretation of the geometric mixture curve underlying the TVO and various path sampling methods, which allows us to characterize the gap in TVO likelihood bounds as a sum of KL divergences. We propose to choose intermediate distributions using equal spacing in the moment parameters of our exponential family, which matches grid search performance and allows the schedule to adaptively update over the course of training. Finally, we derive a doubly reparameterized gradient estimator which improves model learning and allows the TVO to benefit from more refined bounds. To further contextualize our contributions, we provide a unified framework for understanding thermodynamic integration and the TVO using Taylor series remainders.
Discovery and Separation of Features for Invariant Representation Learning
Dec 02, 2019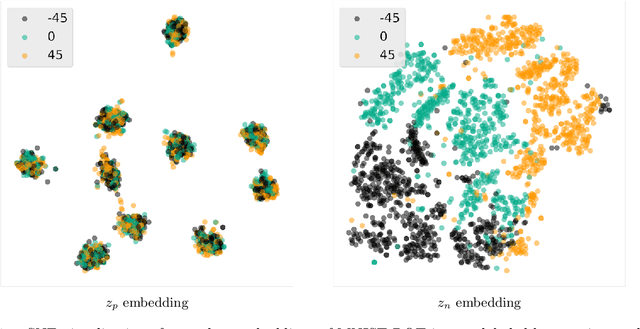


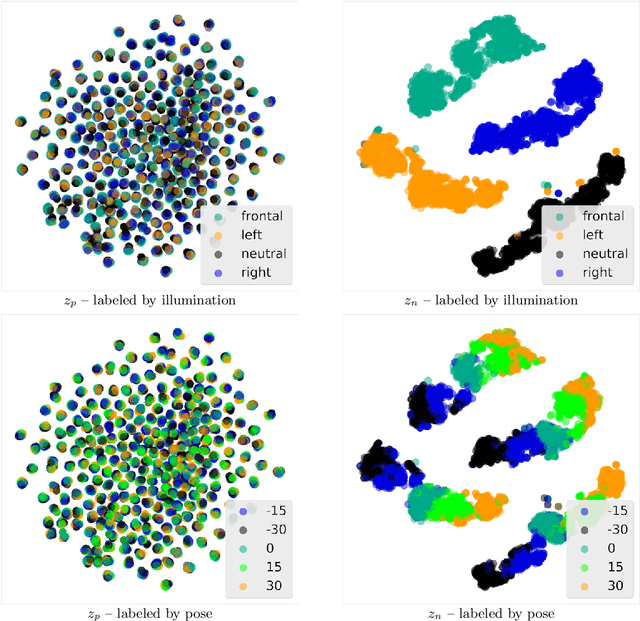
Supervised machine learning models often associate irrelevant nuisance factors with the prediction target, which hurts generalization. We propose a framework for training robust neural networks that induces invariance to nuisances through learning to discover and separate predictive and nuisance factors of data. We present an information theoretic formulation of our approach, from which we derive training objectives and its connections with previous methods. Empirical results on a wide array of datasets show that the proposed framework achieves state-of-the-art performance, without requiring nuisance annotations during training.