 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Monitoring Navigation Agent via Auxiliary Progress Estimation
Jan 10, 2019
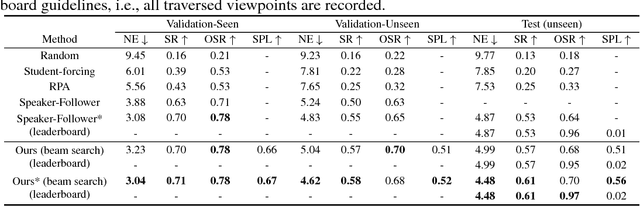
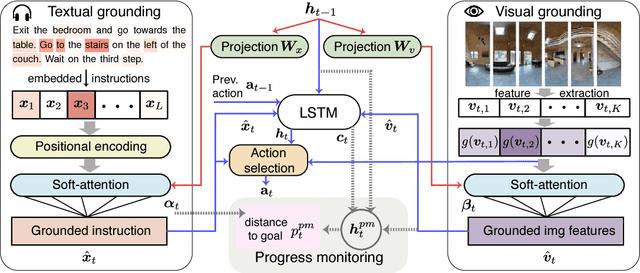
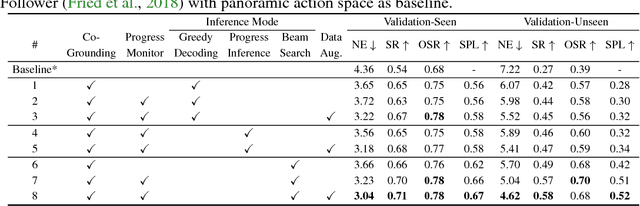
The Vision-and-Language Navigation (VLN) task entails an agent following navigational instruction in photo-realistic unknown environments. This challenging task demands that the agent be aware of which instruction was completed, which instruction is needed next, which way to go, and its navigation progress towards the goal. In this paper, we introduce a self-monitoring agent with two complementary components: (1) visual-textual co-grounding module to locate the instruction completed in the past, the instruction required for the next action, and the next moving direction from surrounding images and (2) progress monitor to ensure the grounded instruction correctly reflects the navigation progress. We test our self-monitoring agent on a standard benchmark and analyze our proposed approach through a series of ablation studies that elucidate the contributions of the primary components. Using our proposed method, we set the new state of the art by a significant margin (8% absolute increase in success rate on the unseen test set). Code is available at https://github.com/chihyaoma/selfmonitoring-agent .
Coarse-grain Fine-grain Coattention Network for Multi-evidence Question Answering
Jan 03, 2019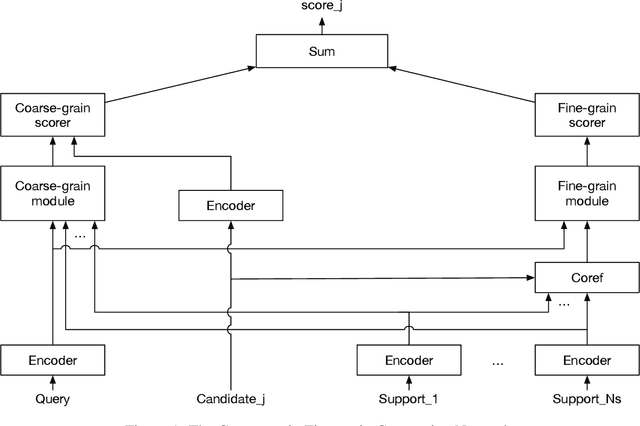
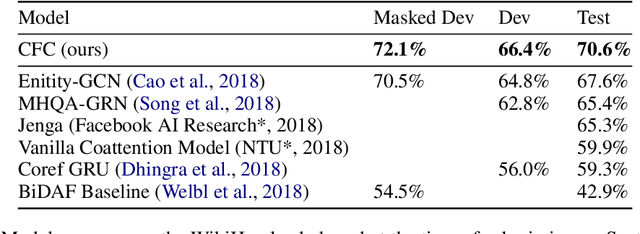
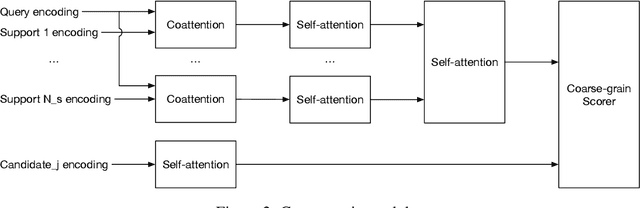
End-to-end neural models have made significant progress in question answering, however recent studies show that these models implicitly assume that the answer and evidence appear close together in a single document. In this work, we propose the Coarse-grain Fine-grain Coattention Network (CFC), a new question answering model that combines information from evidence across multiple documents. The CFC consists of a coarse-grain module that interprets documents with respect to the query then finds a relevant answer, and a fine-grain module which scores each candidate answer by comparing its occurrences across all of the documents with the query. We design these modules using hierarchies of coattention and self-attention, which learn to emphasize different parts of the input. On the Qangaroo WikiHop multi-evidence question answering task, the CFC obtains a new state-of-the-art result of 70.6% on the blind test set, outperforming the previous best by 3% accuracy despite not using pretrained contextual encoders.
AdaFrame: Adaptive Frame Selection for Fast Video Recognition
Nov 29, 2018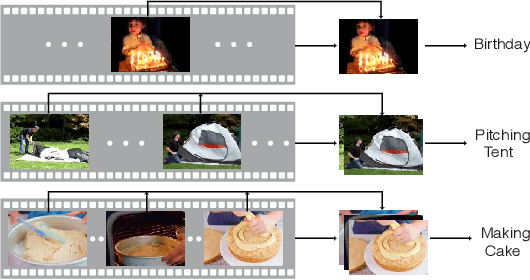
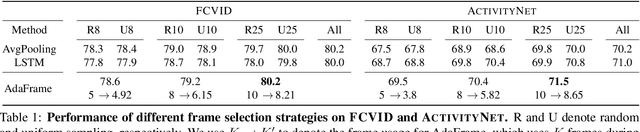
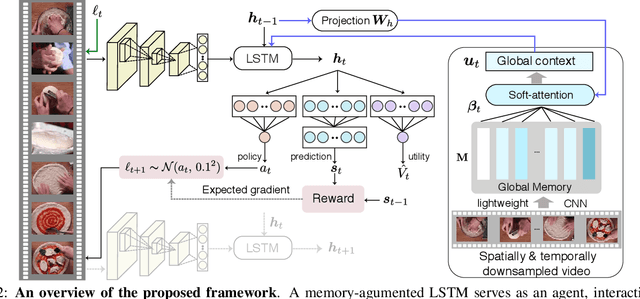
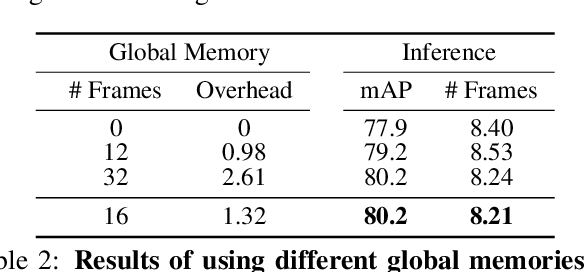
We present AdaFrame, a framework that adaptively selects relevant frames on a per-input basis for fast video recognition. AdaFrame contains a Long Short-Term Memory network augmented with a global memory that provides context information for searching which frames to use over time. Trained with policy gradient methods, AdaFrame generates a prediction, determines which frame to observe next, and computes the utility, i.e., expected future rewards, of seeing more frames at each time step. At testing time, AdaFrame exploits predicted utilities to achieve adaptive lookahead inference such that the overall computational costs are reduced without incurring a decrease in accuracy. Extensive experiments are conducted on two large-scale video benchmarks, FCVID and AvtivityNet. AdaFrame matches the performance of using all frames with only 8.21 and 8.65 frames on FCVID and AvtivityNet, respectively. We further qualitatively demonstrate learned frame usage can indicate the difficulty of making classification decisions; easier samples need fewer frames while harder ones require more, both at instance-level within the same class and at class-level among different categories.
A Closer Look at Deep Learning Heuristics: Learning rate restarts, Warmup and Distillation
Oct 29, 2018
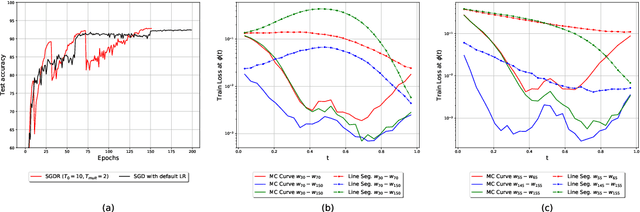
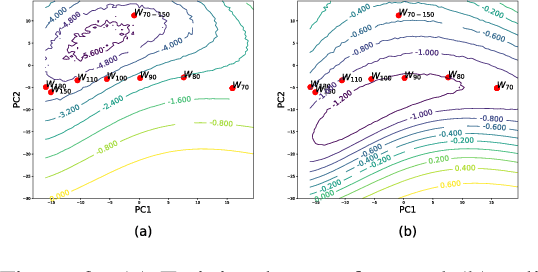
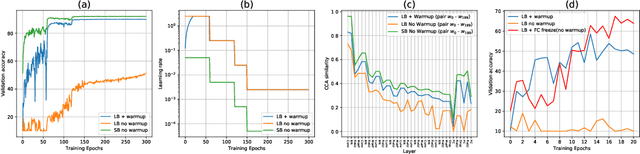
The convergence rate and final performance of common deep learning models have significantly benefited from heuristics such as learning rate schedules, knowledge distillation, skip connections, and normalization layers. In the absence of theoretical underpinnings, controlled experiments aimed at explaining these strategies can aid our understanding of deep learning landscapes and the training dynamics. Existing approaches for empirical analysis rely on tools of linear interpolation and visualizations with dimensionality reduction, each with their limitations. Instead, we revisit such analysis of heuristics through the lens of recently proposed methods for loss surface and representation analysis, viz., mode connectivity and canonical correlation analysis (CCA), and hypothesize reasons for the success of the heuristics. In particular, we explore knowledge distillation and learning rate heuristics of (cosine) restarts and warmup using mode connectivity and CCA. Our empirical analysis suggests that: (a) the reasons often quoted for the success of cosine annealing are not evidenced in practice; (b) that the effect of learning rate warmup is to prevent the deeper layers from creating training instability; and (c) that the latent knowledge shared by the teacher is primarily disbursed to the deeper layers.
Identifying Generalization Properties in Neural Networks
Sep 19, 2018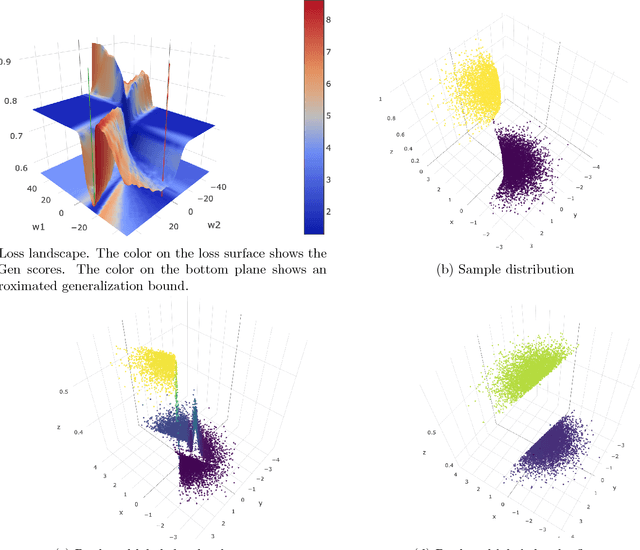
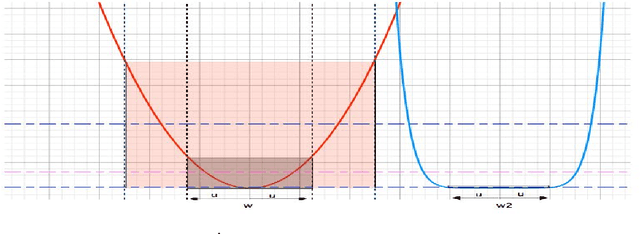
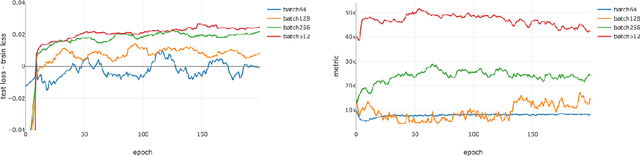
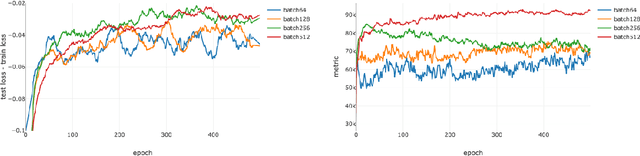
While it has not yet been proven, empirical evidence suggests that model generalization is related to local properties of the optima which can be described via the Hessian. We connect model generalization with the local property of a solution under the PAC-Bayes paradigm. In particular, we prove that model generalization ability is related to the Hessian, the higher-order "smoothness" terms characterized by the Lipschitz constant of the Hessian, and the scales of the parameters. Guided by the proof, we propose a metric to score the generalization capability of the model, as well as an algorithm that optimizes the perturbed model accordingly.
Multi-Hop Knowledge Graph Reasoning with Reward Shaping
Sep 11, 2018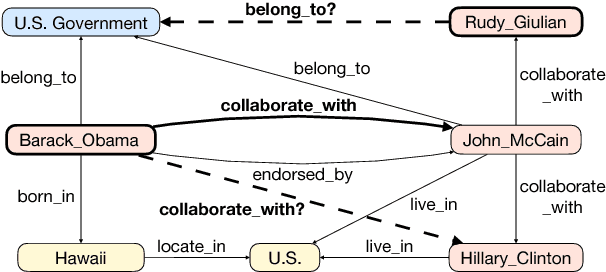
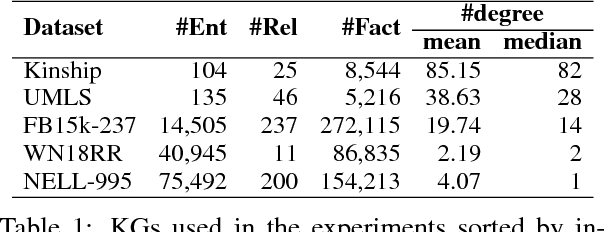
Multi-hop reasoning is an effective approach for query answering (QA) over incomplete knowledge graphs (KGs). The problem can be formulated in a reinforcement learning (RL) setup, where a policy-based agent sequentially extends its inference path until it reaches a target. However, in an incomplete KG environment, the agent receives low-quality rewards corrupted by false negatives in the training data, which harms generalization at test time. Furthermore, since no golden action sequence is used for training, the agent can be misled by spurious search trajectories that incidentally lead to the correct answer. We propose two modeling advances to address both issues: (1) we reduce the impact of false negative supervision by adopting a pretrained one-hop embedding model to estimate the reward of unobserved facts; (2) we counter the sensitivity to spurious paths of on-policy RL by forcing the agent to explore a diverse set of paths using randomly generated edge masks. Our approach significantly improves over existing path-based KGQA models on several benchmark datasets and is comparable or better than embedding-based models.
Global-Locally Self-Attentive Dialogue State Tracker
Sep 06, 2018
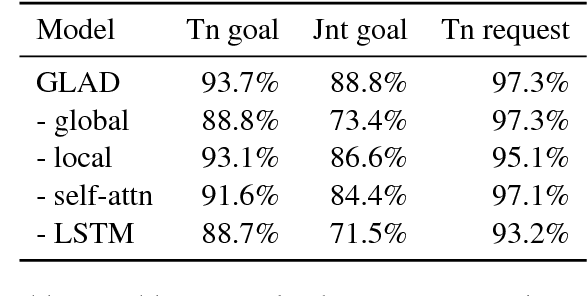
Dialogue state tracking, which estimates user goals and requests given the dialogue context, is an essential part of task-oriented dialogue systems. In this paper, we propose the Global-Locally Self-Attentive Dialogue State Tracker (GLAD), which learns representations of the user utterance and previous system actions with global-local modules. Our model uses global modules to share parameters between estimators for different types (called slots) of dialogue states, and uses local modules to learn slot-specific features. We show that this significantly improves tracking of rare states and achieves state-of-the-art performance on the WoZ and DSTC2 state tracking tasks. GLAD obtains 88.1% joint goal accuracy and 97.1% request accuracy on WoZ, outperforming prior work by 3.7% and 5.5%. On DSTC2, our model obtains 74.5% joint goal accuracy and 97.5% request accuracy, outperforming prior work by 1.1% and 1.0%.
Improving Abstraction in Text Summarization
Aug 23, 2018
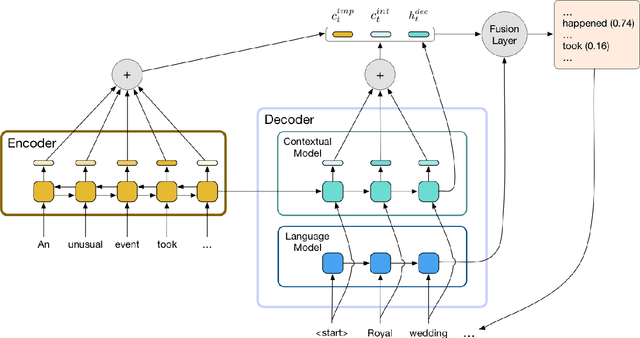
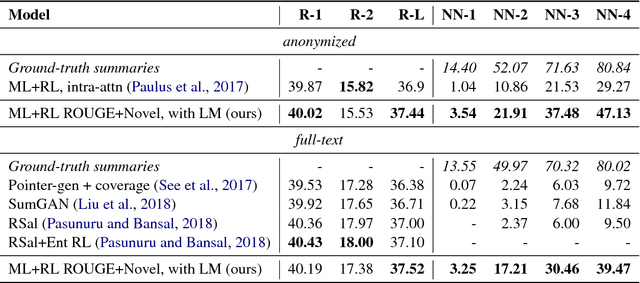
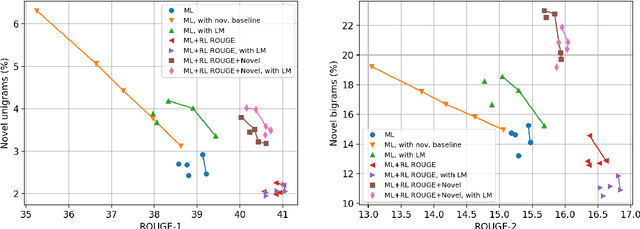
Abstractive text summarization aims to shorten long text documents into a human readable form that contains the most important facts from the original document. However, the level of actual abstraction as measured by novel phrases that do not appear in the source document remains low in existing approaches. We propose two techniques to improve the level of abstraction of generated summaries. First, we decompose the decoder into a contextual network that retrieves relevant parts of the source document, and a pretrained language model that incorporates prior knowledge about language generation. Second, we propose a novelty metric that is optimized directly through policy learning to encourage the generation of novel phrases. Our model achieves results comparable to state-of-the-art models, as determined by ROUGE scores and human evaluations, while achieving a significantly higher level of abstraction as measured by n-gram overlap with the source document.
Augmented Cyclic Adversarial Learning for Domain Adaptation
Aug 07, 2018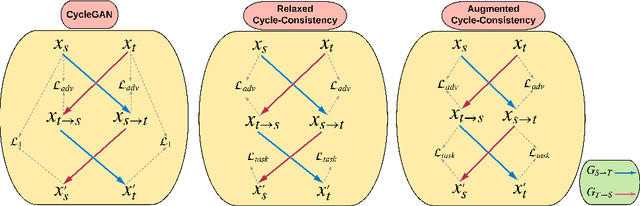
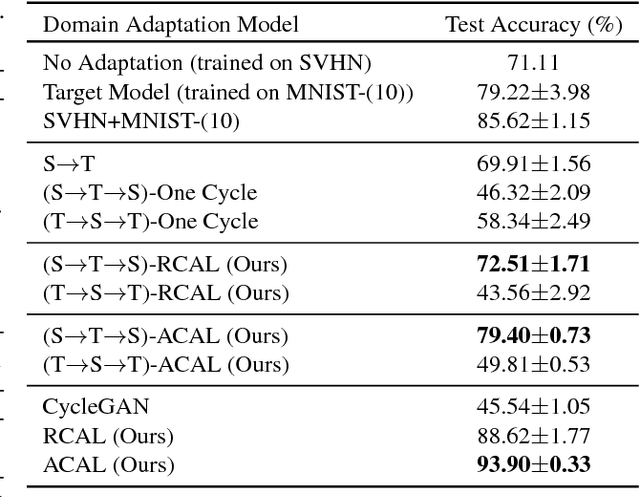
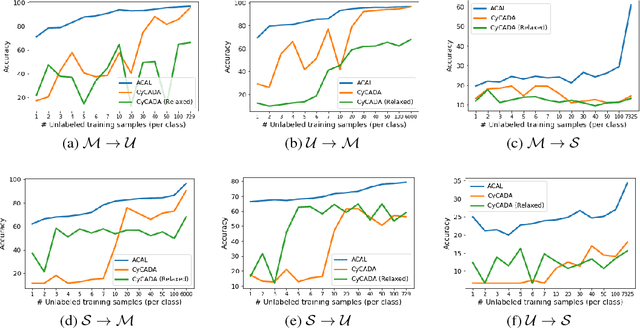
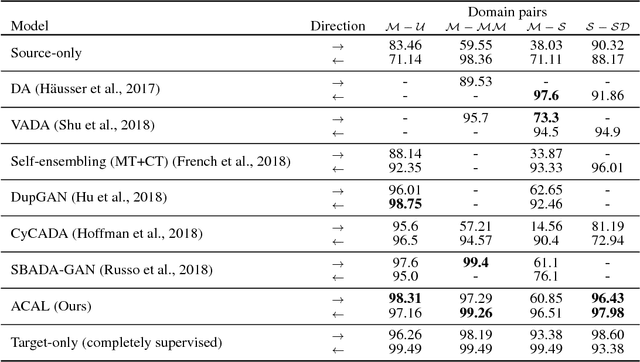
Training a model to perform a task typically requires a large amount of data from the domains in which the task will be applied. However, it is often the case that data are abundant in some domains but scarce in others. Domain adaptation deals with the challenge of adapting a model trained from a data-rich source domain to perform well in a data-poor target domain. In general, this requires learning plausible mappings between domains. CycleGAN is a powerful framework that efficiently learns to map inputs from one domain to another using adversarial training and a cycle-consistency constraint. However, the conventional approach of enforcing cycle-consistency via reconstruction may be overly restrictive in cases where one or more domains have limited training data. In this paper, we propose an augmented cyclic adversarial learning model that enforces the cycle-consistency constraint through an external task specific model, which encourages the preservation of task-relevant content as opposed to exact reconstruction. We explore digit classification with MNIST and SVHN in a low-resource setting in supervised, semi and unsupervised situation. In low-resource supervised setting, the results show that our approach improves absolute performance by $14\%$ and $4\%$ when adapting SVHN to MNIST and vice versa, respectively, which outperforms unsupervised domain adaptation methods that require high-resource unlabeled target domain. Moreover, using only few unsupervised target data, our approach can still outperforms many high-resource unsupervised models. In speech domains, we also adopt a speech recognition model from each domain as the task specific model. Our approach improves absolute performance of speech recognition by $2\%$ for female speakers in the TIMIT dataset, where the majority of training samples are from male voices.
A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation
Jul 09, 2018
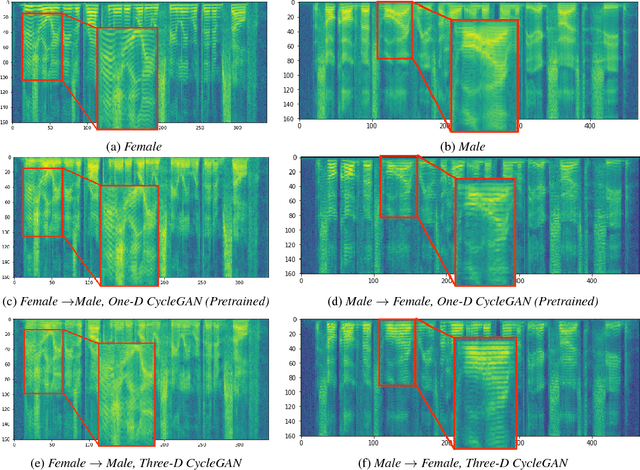
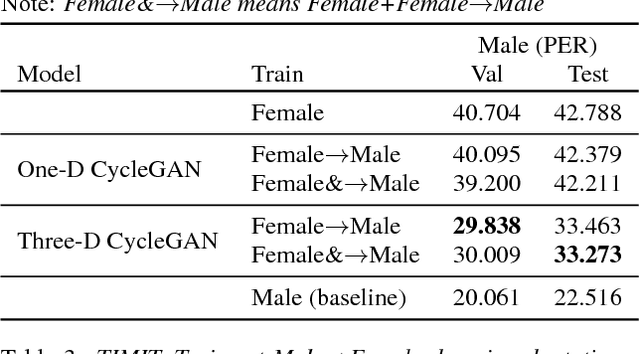
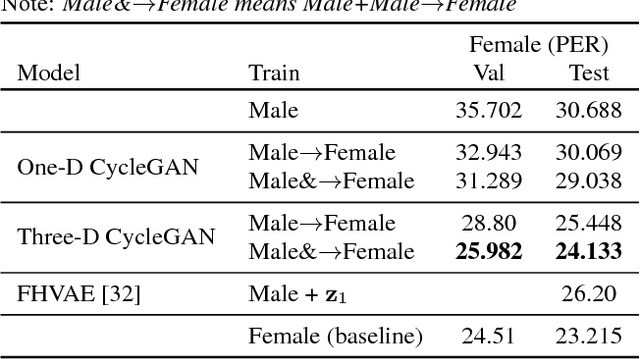
Domain adaptation plays an important role for speech recognition models, in particular, for domains that have low resources. We propose a novel generative model based on cyclic-consistent generative adversarial network (CycleGAN) for unsupervised non-parallel speech domain adaptation. The proposed model employs multiple independent discriminators on the power spectrogram, each in charge of different frequency bands. As a result we have 1) better discriminators that focus on fine-grained details of the frequency features, and 2) a generator that is capable of generating more realistic domain-adapted spectrogram. We demonstrate the effectiveness of our method on speech recognition with gender adaptation, where the model only has access to supervised data from one gender during training, but is evaluated on the other at test time. Our model is able to achieve an average of $7.41\%$ on phoneme error rate, and $11.10\%$ word error rate relative performance improvement as compared to the baseline, on TIMIT and WSJ dataset, respectively. Qualitatively, our model also generates more natural sounding speech, when conditioned on data from the other domain.