 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Deep Learning Heuristics: Learning rate restarts, Warmup and Distillation
Oct 29, 2018
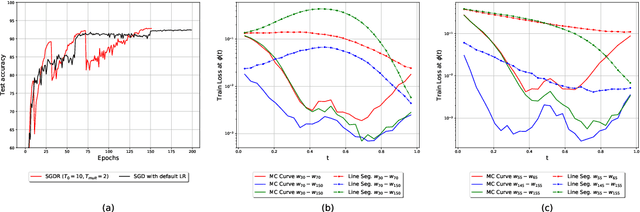
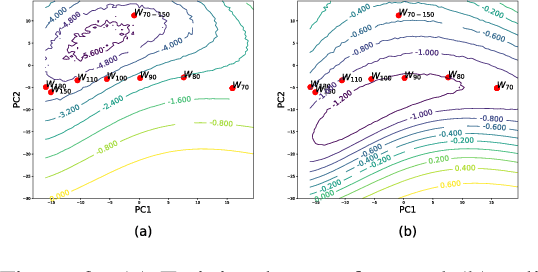
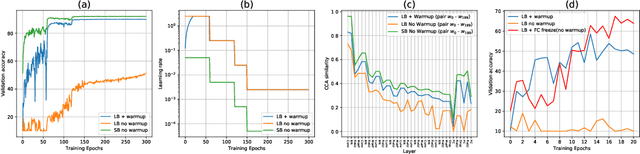
The convergence rate and final performance of common deep learning models have significantly benefited from heuristics such as learning rate schedules, knowledge distillation, skip connections, and normalization layers. In the absence of theoretical underpinnings, controlled experiments aimed at explaining these strategies can aid our understanding of deep learning landscapes and the training dynamics. Existing approaches for empirical analysis rely on tools of linear interpolation and visualizations with dimensionality reduction, each with their limitations. Instead, we revisit such analysis of heuristics through the lens of recently proposed methods for loss surface and representation analysis, viz., mode connectivity and canonical correlation analysis (CCA), and hypothesize reasons for the success of the heuristics. In particular, we explore knowledge distillation and learning rate heuristics of (cosine) restarts and warmup using mode connectivity and CCA. Our empirical analysis suggests that: (a) the reasons often quoted for the success of cosine annealing are not evidenced in practice; (b) that the effect of learning rate warmup is to prevent the deeper layers from creating training instability; and (c) that the latent knowledge shared by the teacher is primarily disbursed to the deeper layers.
Unsupervised robust nonparametric learning of hidden community properties
Jul 23, 2018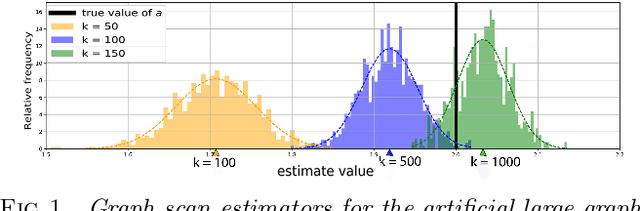
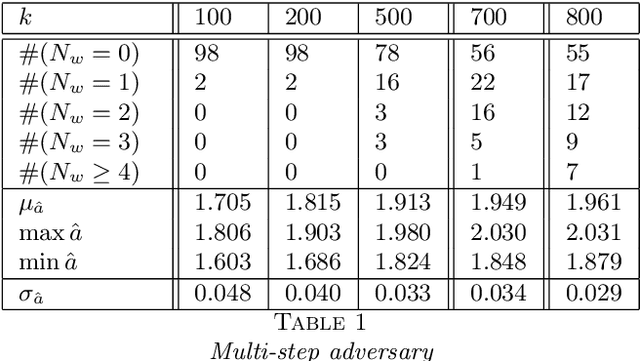
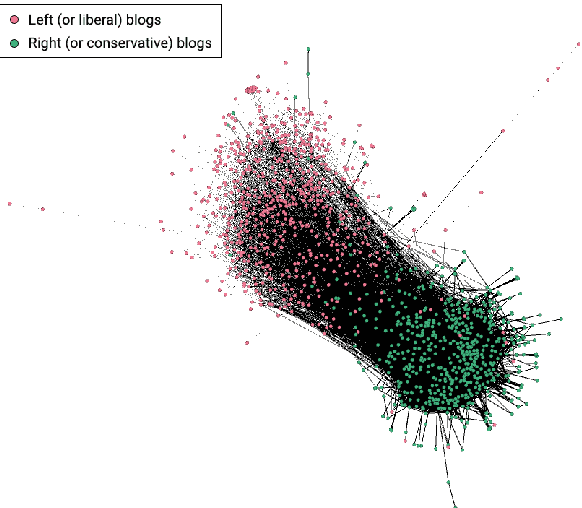
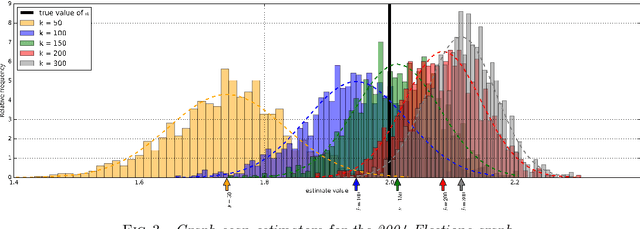
We consider learning of fundamental properties of communities in large noisy networks, in the prototypical situation where the nodes or users are split into two classes according to a binary property, e.g., according to their opinions or preferences on a topic. For learning these properties, we propose a nonparametric, unsupervised, and scalable graph scan procedure that is, in addition, robust against a class of powerful adversaries. In our setup, one of the communities can fall under the influence of a knowledgeable adversarial leader, who knows the full network structure, has unlimited computational resources and can completely foresee our planned actions on the network. We prove strong consistency of our results in this setup with minimal assumptions. In particular, the learning procedure estimates the baseline activity of normal users asymptotically correctly with probability 1; the only assumption being the existence of a single implicit community of asymptotically negligible logarithmic size. We provide experiments on real and synthetic data to illustrate the performance of our method, including examples with adversaries.
Using Mode Connectivity for Loss Landscape Analysis
Jun 18, 2018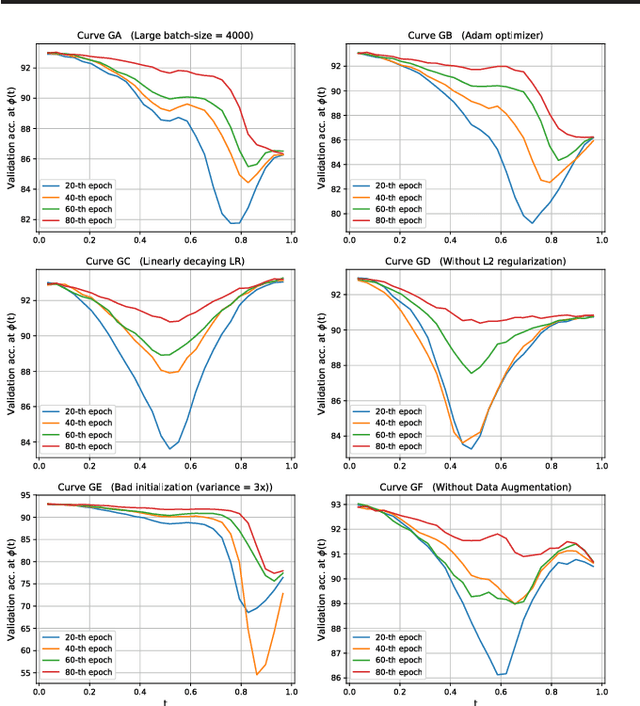
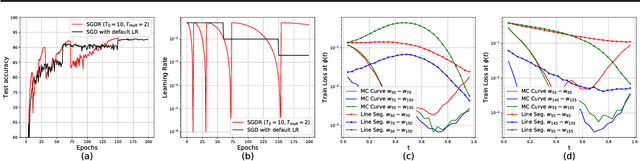
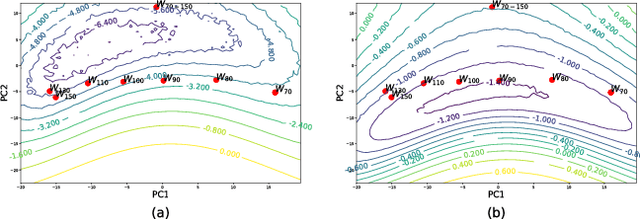
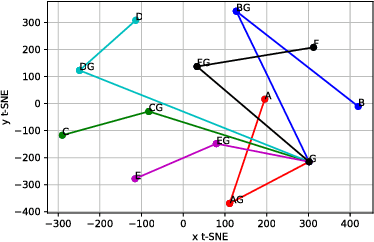
Mode connectivity is a recently introduced frame- work that empirically establishes the connected- ness of minima by finding a high accuracy curve between two independently trained models. To investigate the limits of this setup, we examine the efficacy of this technique in extreme cases where the input models are trained or initialized differently. We find that the procedure is resilient to such changes. Given this finding, we propose using the framework for analyzing loss surfaces and training trajectories more generally, and in this direction, study SGD with cosine annealing and restarts (SGDR). We report that while SGDR moves over barriers in its trajectory, propositions claiming that it converges to and escapes from multiple local minima are not substantiated by our empirical results.