 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiQG-TI: Towards Question Generation from Multi-modal Sources
Jul 07, 2023We study the new problem of automatic question generation (QG) from multi-modal sources containing images and texts, significantly expanding the scope of most of the existing work that focuses exclusively on QG from only textual sources. We propose a simple solution for our new problem, called MultiQG-TI, which enables a text-only question generator to process visual input in addition to textual input. Specifically, we leverage an image-to-text model and an optical character recognition model to obtain the textual description of the image and extract any texts in the image, respectively, and then feed them together with the input texts to the question generator. We only fine-tune the question generator while keeping the other components fixed. On the challenging ScienceQA dataset, we demonstrate that MultiQG-TI significantly outperforms ChatGPT with few-shot prompting, despite having hundred-times less trainable parameters. Additional analyses empirically confirm the necessity of both visual and textual signals for QG and show the impact of various modeling choices.
SplineCam: Exact Visualization and Characterization of Deep Network Geometry and Decision Boundaries
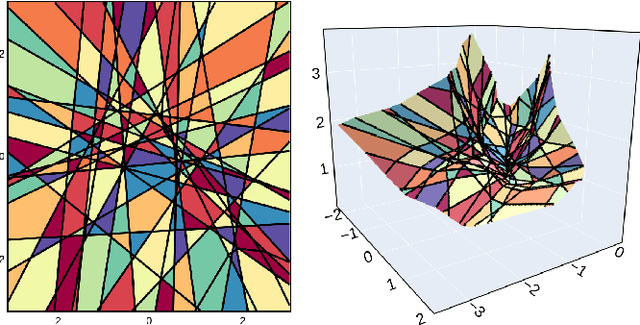
Feb 24, 2023Current Deep Network (DN) visualization and interpretability methods rely heavily on data space visualizations such as scoring which dimensions of the data are responsible for their associated prediction or generating new data features or samples that best match a given DN unit or representation. In this paper, we go one step further by developing the first provably exact method for computing the geometry of a DN's mapping - including its decision boundary - over a specified region of the data space. By leveraging the theory of Continuous Piece-Wise Linear (CPWL) spline DNs, SplineCam exactly computes a DNs geometry without resorting to approximations such as sampling or architecture simplification. SplineCam applies to any DN architecture based on CPWL nonlinearities, including (leaky-)ReLU, absolute value, maxout, and max-pooling and can also be applied to regression DNs such as implicit neural representations. Beyond decision boundary visualization and characterization, SplineCam enables one to compare architectures, measure generalizability and sample from the decision boundary on or off the manifold. Project Website: bit.ly/splinecam.
Unsupervised Learning of Sampling Distributions for Particle Filters
Feb 02, 2023



Accurate estimation of the states of a nonlinear dynamical system is crucial for their design, synthesis, and analysis. Particle filters are estimators constructed by simulating trajectories from a sampling distribution and averaging them based on their importance weight. For particle filters to be computationally tractable, it must be feasible to simulate the trajectories by drawing from the sampling distribution. Simultaneously, these trajectories need to reflect the reality of the nonlinear dynamical system so that the resulting estimators are accurate. Thus, the crux of particle filters lies in designing sampling distributions that are both easy to sample from and lead to accurate estimators. In this work, we propose to learn the sampling distributions. We put forward four methods for learning sampling distributions from observed measurements. Three of the methods are parametric methods in which we learn the mean and covariance matrix of a multivariate Gaussian distribution; each methods exploits a different aspect of the data (generic, time structure, graph structure). The fourth method is a nonparametric alternative in which we directly learn a transform of a uniform random variable. All four methods are trained in an unsupervised manner by maximizing the likelihood that the states may have produced the observed measurements. Our computational experiments demonstrate that learned sampling distributions exhibit better performance than designed, minimum-degeneracy sampling distributions.
Retrieval-based Controllable Molecule Generation
Aug 23, 2022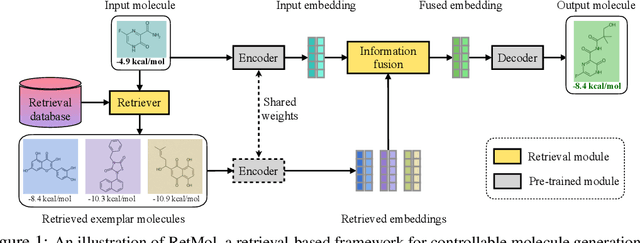

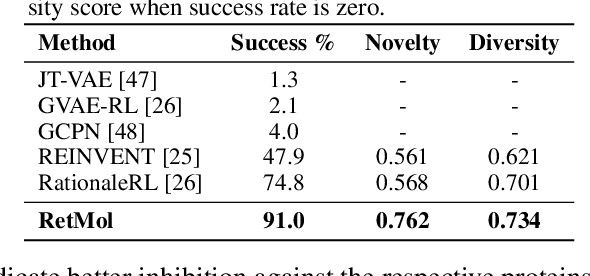
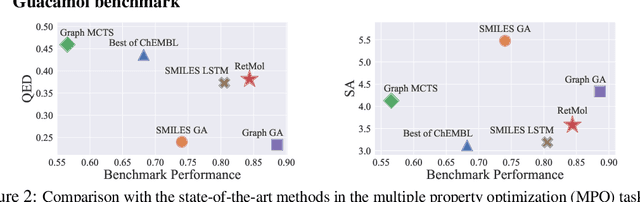
Generating new molecules with specified chemical and biological properties via generative models has emerged as a promising direction for drug discovery. However, existing methods require extensive training/fine-tuning with a large dataset, often unavailable in real-world generation tasks. In this work, we propose a new retrieval-based framework for controllable molecule generation. We use a small set of exemplar molecules, i.e., those that (partially) satisfy the design criteria, to steer the pre-trained generative model towards synthesizing molecules that satisfy the given design criteria. We design a retrieval mechanism that retrieves and fuses the exemplar molecules with the input molecule, which is trained by a new self-supervised objective that predicts the nearest neighbor of the input molecule. We also propose an iterative refinement process to dynamically update the generated molecules and retrieval database for better generalization. Our approach is agnostic to the choice of generative models and requires no task-specific fine-tuning. On various tasks ranging from simple design criteria to a challenging real-world scenario for designing lead compounds that bind to the SARS-CoV-2 main protease, we demonstrate our approach extrapolates well beyond the retrieval database, and achieves better performance and wider applicability than previous methods.
Automated Scoring for Reading Comprehension via In-context BERT Tuning
May 19, 2022
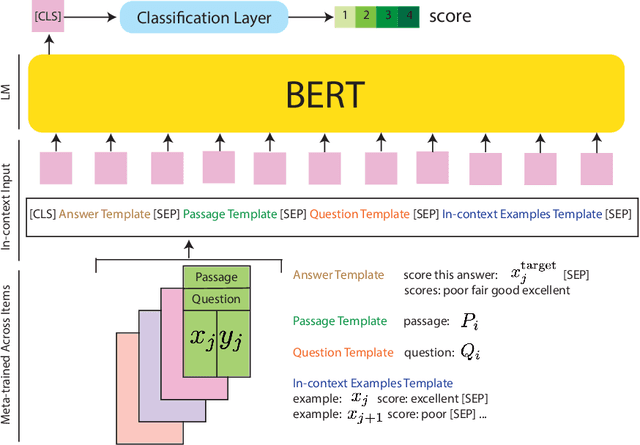

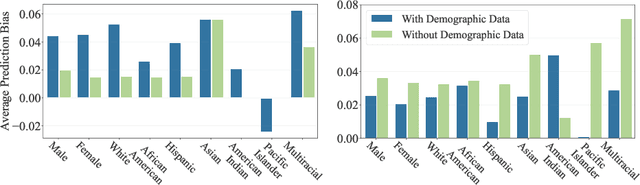
Automated scoring of open-ended student responses has the potential to significantly reduce human grader effort. Recent advances in automated scoring often leverage textual representations based on pre-trained language models such as BERT and GPT as input to scoring models. Most existing approaches train a separate model for each item/question, which is suitable for scenarios such as essay scoring where items can be quite different from one another. However, these approaches have two limitations: 1) they fail to leverage item linkage for scenarios such as reading comprehension where multiple items may share a reading passage; 2) they are not scalable since storing one model per item becomes difficult when models have a large number of parameters. In this paper, we report our (grand prize-winning) solution to the National Assessment of Education Progress (NAEP) automated scoring challenge for reading comprehension. Our approach, in-context BERT fine-tuning, produces a single shared scoring model for all items with a carefully-designed input structure to provide contextual information on each item. We demonstrate the effectiveness of our approach via local evaluations using the training dataset provided by the challenge. We also discuss the biases, common error types, and limitations of our approach.
Can Neural Nets Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary Perspective
Mar 15, 2022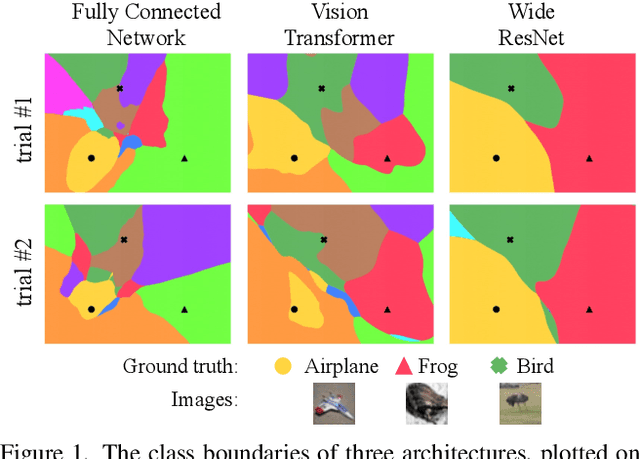
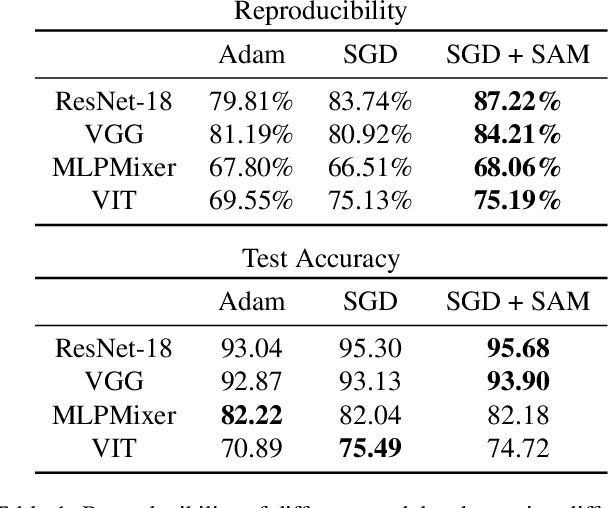
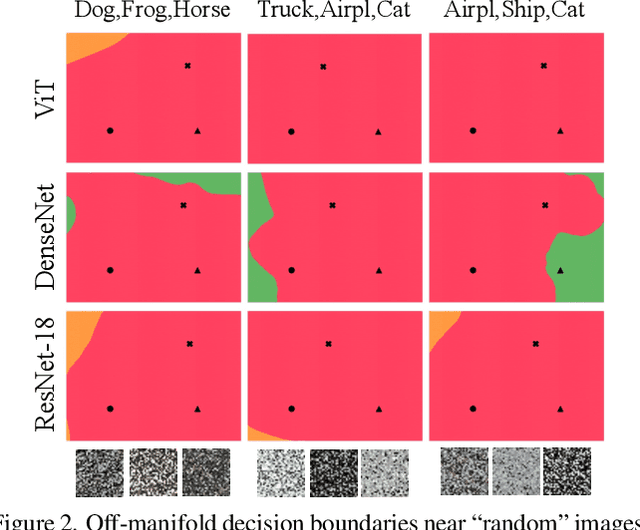

We discuss methods for visualizing neural network decision boundaries and decision regions. We use these visualizations to investigate issues related to reproducibility and generalization in neural network training. We observe that changes in model architecture (and its associate inductive bias) cause visible changes in decision boundaries, while multiple runs with the same architecture yield results with strong similarities, especially in the case of wide architectures. We also use decision boundary methods to visualize double descent phenomena. We see that decision boundary reproducibility depends strongly on model width. Near the threshold of interpolation, neural network decision boundaries become fragmented into many small decision regions, and these regions are non-reproducible. Meanwhile, very narrows and very wide networks have high levels of reproducibility in their decision boundaries with relatively few decision regions. We discuss how our observations relate to the theory of double descent phenomena in convex models. Code is available at https://github.com/somepago/dbViz
No More Than 6ft Apart: Robust K-Means via Radius Upper Bounds
Mar 04, 2022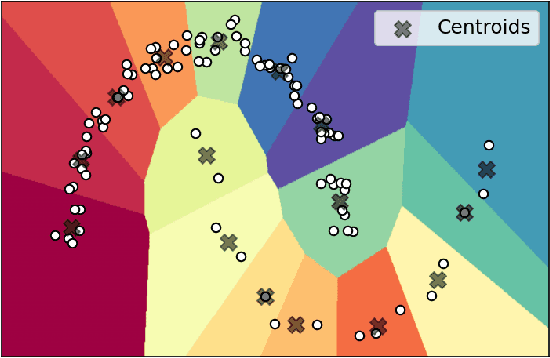


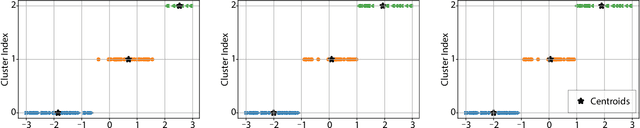
Centroid based clustering methods such as k-means, k-medoids and k-centers are heavily applied as a go-to tool in exploratory data analysis. In many cases, those methods are used to obtain representative centroids of the data manifold for visualization or summarization of a dataset. Real world datasets often contain inherent abnormalities, e.g., repeated samples and sampling bias, that manifest imbalanced clustering. We propose to remedy such a scenario by introducing a maximal radius constraint $r$ on the clusters formed by the centroids, i.e., samples from the same cluster should not be more than $2r$ apart in terms of $\ell_2$ distance. We achieve this constraint by solving a semi-definite program, followed by a linear assignment problem with quadratic constraints. Through qualitative results, we show that our proposed method is robust towards dataset imbalances and sampling artifacts. To the best of our knowledge, ours is the first constrained k-means clustering method with hard radius constraints. Codes at https://bit.ly/kmeans-constrained
Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values
Mar 03, 2022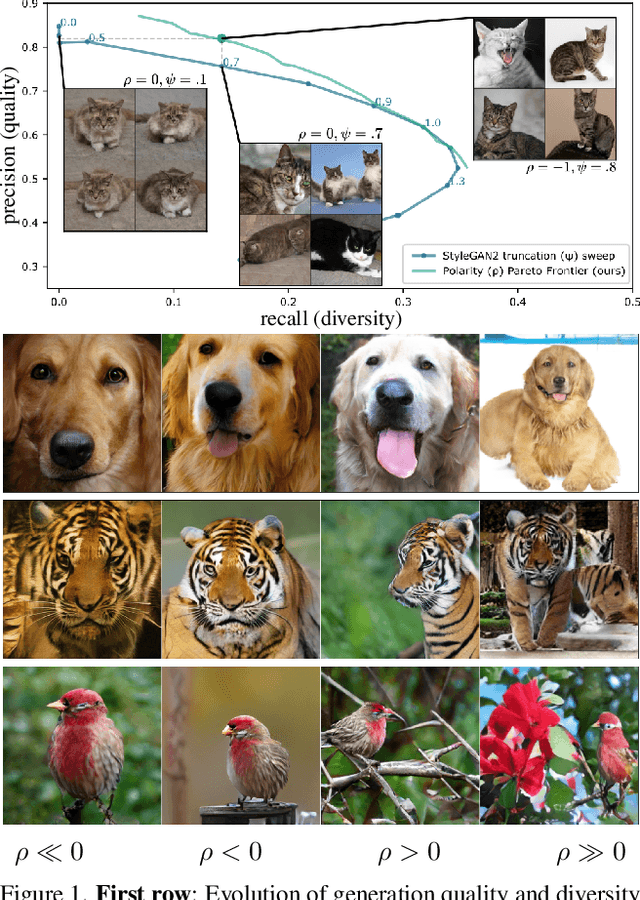
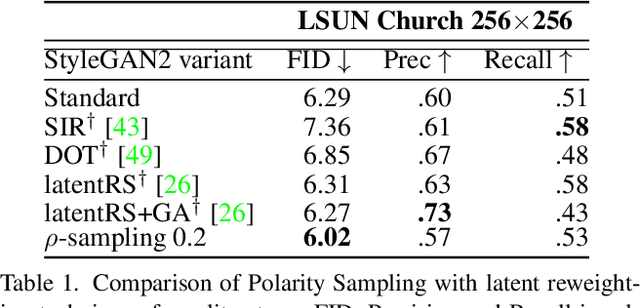
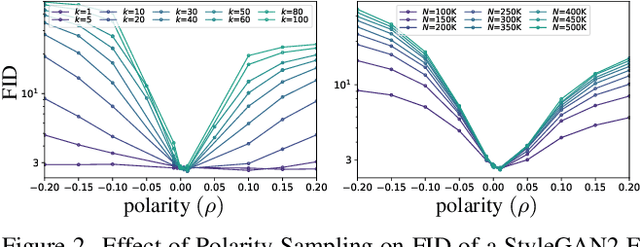
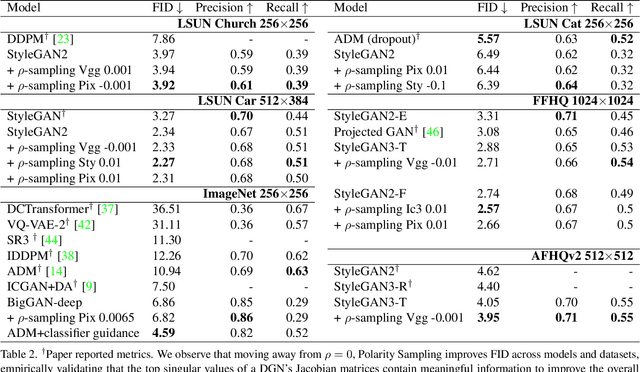
We present Polarity Sampling, a theoretically justified plug-and-play method for controlling the generation quality and diversity of pre-trained deep generative networks DGNs). Leveraging the fact that DGNs are, or can be approximated by, continuous piecewise affine splines, we derive the analytical DGN output space distribution as a function of the product of the DGN's Jacobian singular values raised to a power $\rho$. We dub $\rho$ the $\textbf{polarity}$ parameter and prove that $\rho$ focuses the DGN sampling on the modes ($\rho < 0$) or anti-modes ($\rho > 0$) of the DGN output-space distribution. We demonstrate that nonzero polarity values achieve a better precision-recall (quality-diversity) Pareto frontier than standard methods, such as truncation, for a number of state-of-the-art DGNs. We also present quantitative and qualitative results on the improvement of overall generation quality (e.g., in terms of the Frechet Inception Distance) for a number of state-of-the-art DGNs, including StyleGAN3, BigGAN-deep, NVAE, for different conditional and unconditional image generation tasks. In particular, Polarity Sampling redefines the state-of-the-art for StyleGAN2 on the FFHQ Dataset to FID 2.57, StyleGAN2 on the LSUN Car Dataset to FID 2.27 and StyleGAN3 on the AFHQv2 Dataset to FID 3.95. Demo: bit.ly/polarity-demo-colab
Spatial Transformer K-Means
Feb 16, 2022
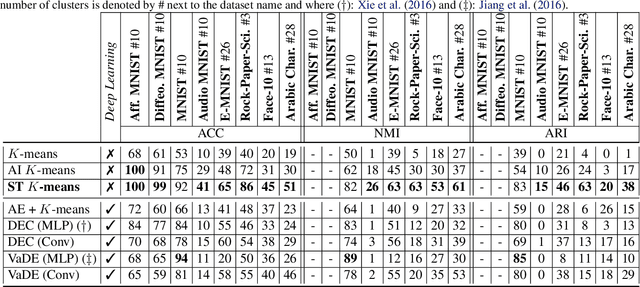
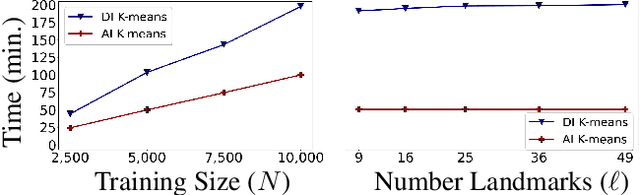

K-means defines one of the most employed centroid-based clustering algorithms with performances tied to the data's embedding. Intricate data embeddings have been designed to push $K$-means performances at the cost of reduced theoretical guarantees and interpretability of the results. Instead, we propose preserving the intrinsic data space and augment K-means with a similarity measure invariant to non-rigid transformations. This enables (i) the reduction of intrinsic nuisances associated with the data, reducing the complexity of the clustering task and increasing performances and producing state-of-the-art results, (ii) clustering in the input space of the data, leading to a fully interpretable clustering algorithm, and (iii) the benefit of convergence guarantees.
MaGNET: Uniform Sampling from Deep Generative Network Manifolds Without Retraining
Oct 18, 2021
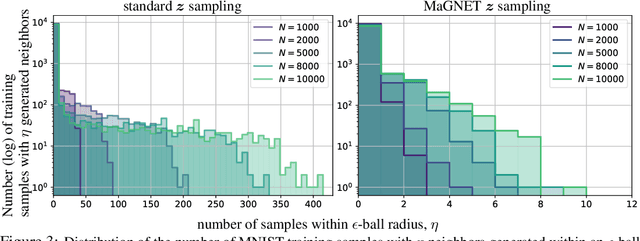
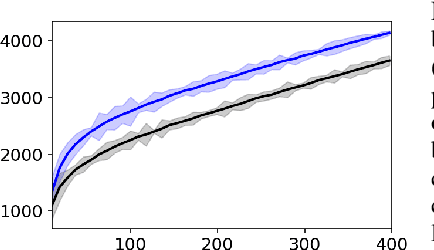
Deep Generative Networks (DGNs) are extensively employed in Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and their variants to approximate the data manifold, and data distribution on that manifold. However, training samples are often obtained based on preferences, costs, or convenience producing artifacts in the empirical data distribution e.g., the large fraction of smiling faces in the CelebA dataset or the large fraction of dark-haired individuals in FFHQ. These inconsistencies will be reproduced when sampling from the trained DGN, which has far-reaching potential implications for fairness, data augmentation, anomaly detection, domain adaptation, and beyond. In response, we develop a differential geometry based sampler -- coined MaGNET -- that, given any trained DGN, produces samples that are uniformly distributed on the learned manifold. We prove theoretically and empirically that our technique produces a uniform distribution on the manifold regardless of the training set distribution. We perform a range of experiments on various datasets and DGNs. One of them considers the state-of-the-art StyleGAN2 trained on FFHQ dataset, where uniform sampling via MaGNET increases distribution precision and recall by 4.1% & 3.0% and decreases gender bias by 41.2%, without requiring labels or retraining.