 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplInterp: Improving our Understanding and Training of Sparse Autoencoders
May 17, 2025Sparse autoencoders (SAEs) have received considerable recent attention as tools for mechanistic interpretability, showing success at extracting interpretable features even from very large LLMs. However, this research has been largely empirical, and there have been recent doubts about the true utility of SAEs. In this work, we seek to enhance the theoretical understanding of SAEs, using the spline theory of deep learning. By situating SAEs in this framework: we discover that SAEs generalise ``$k$-means autoencoders'' to be piecewise affine, but sacrifice accuracy for interpretability vs. the optimal ``$k$-means-esque plus local principal component analysis (PCA)'' piecewise affine autoencoder. We characterise the underlying geometry of (TopK) SAEs using power diagrams. And we develop a novel proximal alternating method SGD (PAM-SGD) algorithm for training SAEs, with both solid theoretical foundations and promising empirical results in MNIST and LLM experiments, particularly in sample efficiency and (in the LLM setting) improved sparsity of codes. All code is available at: https://github.com/splInterp2025/splInterp
An Empirically Grounded Identifiability Theory Will Accelerate Self-Supervised Learning Research
Apr 17, 2025
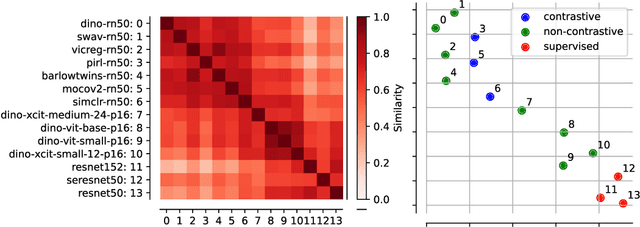
Self-Supervised Learning (SSL) powers many current AI systems. As research interest and investment grow, the SSL design space continues to expand. The Platonic view of SSL, following the Platonic Representation Hypothesis (PRH), suggests that despite different methods and engineering approaches, all representations converge to the same Platonic ideal. However, this phenomenon lacks precise theoretical explanation. By synthesizing evidence from Identifiability Theory (IT), we show that the PRH can emerge in SSL. However, current IT cannot explain SSL's empirical success. To bridge the gap between theory and practice, we propose expanding IT into what we term Singular Identifiability Theory (SITh), a broader theoretical framework encompassing the entire SSL pipeline. SITh would allow deeper insights into the implicit data assumptions in SSL and advance the field towards learning more interpretable and generalizable representations. We highlight three critical directions for future research: 1) training dynamics and convergence properties of SSL; 2) the impact of finite samples, batch size, and data diversity; and 3) the role of inductive biases in architecture, augmentations, initialization schemes, and optimizers.
Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models
Feb 20, 2025



A long-standing goal in AI is to build agents that can solve a variety of tasks across different environments, including previously unseen ones. Two dominant approaches tackle this challenge: (i) reinforcement learning (RL), which learns policies through trial and error, and (ii) optimal control, which plans actions using a learned or known dynamics model. However, their relative strengths and weaknesses remain underexplored in the setting where agents must learn from offline trajectories without reward annotations. In this work, we systematically analyze the performance of different RL and control-based methods under datasets of varying quality. On the RL side, we consider goal-conditioned and zero-shot approaches. On the control side, we train a latent dynamics model using the Joint Embedding Predictive Architecture (JEPA) and use it for planning. We study how dataset properties-such as data diversity, trajectory quality, and environment variability-affect the performance of these approaches. Our results show that model-free RL excels when abundant, high-quality data is available, while model-based planning excels in generalization to novel environment layouts, trajectory stitching, and data-efficiency. Notably, planning with a latent dynamics model emerges as a promising approach for zero-shot generalization from suboptimal data.
Eidetic Learning: an Efficient and Provable Solution to Catastrophic Forgetting
Feb 13, 2025



Catastrophic forgetting -- the phenomenon of a neural network learning a task t1 and losing the ability to perform it after being trained on some other task t2 -- is a long-standing problem for neural networks [McCloskey and Cohen, 1989]. We present a method, Eidetic Learning, that provably solves catastrophic forgetting. A network trained with Eidetic Learning -- here, an EideticNet -- requires no rehearsal or replay. We consider successive discrete tasks and show how at inference time an EideticNet automatically routes new instances without auxiliary task information. An EideticNet bears a family resemblance to the sparsely-gated Mixture-of-Experts layer Shazeer et al. [2016] in that network capacity is partitioned across tasks and the network itself performs data-conditional routing. An EideticNet is easy to implement and train, is efficient, and has time and space complexity linear in the number of parameters. The guarantee of our method holds for normalization layers of modern neural networks during both pre-training and fine-tuning. We show with a variety of network architectures and sets of tasks that EideticNets are immune to forgetting. While the practical benefits of EideticNets are substantial, we believe they can be benefit practitioners and theorists alike. The code for training EideticNets is available at \href{https://github.com/amazon-science/eideticnet-training}{this https URL}.
Curvature Tuning: Provable Training-free Model Steering From a Single Parameter
Feb 11, 2025



The scaling of model size and data size has reshaped the paradigm of AI. As a result, the common protocol to leverage the latest models is to steer them towards a specific downstream task of interest through {\em fine-tuning}. Despite its importance, the main methods for fine-tuning remain limited to full or low-rank adapters--containing countless hyper-parameters and lacking interpretability. In this paper, we take a step back and demonstrate how novel and explainable post-training steering solutions can be derived theoretically from {\em spline operators}, a rich mathematical framing of Deep Networks that was recently developed. Our method--coined \textbf{Curvature Tuning (CT)}--has a single parameter that provably modulates the curvature of the model's decision boundary henceforth allowing training-free steering. This makes CT both more efficient and interpretable than conventional fine-tuning methods. We empirically validate its effectiveness in improving generalization and robustness of pretrained models. For example, CT improves out-of-distribution transfer performances of ResNet-18/50 by 2.57\%/1.74\% across seventeen downstream datasets, and improves RobustBench robust accuracy by 11.76\%/348.44\%. Additionally, we apply CT to ReLU-based Swin-T/S, improving their generalization on nine downstream datasets by 2.43\%/3.33\%. Our code is available at \href{https://github.com/Leon-Leyang/curvature-tuning}{https://github.com/Leon-Leyang/curvature-tuning}.
Beyond and Free from Diffusion: Invertible Guided Consistency Training
Feb 08, 2025



Guidance in image generation steers models towards higher-quality or more targeted outputs, typically achieved in Diffusion Models (DMs) via Classifier-free Guidance (CFG). However, recent Consistency Models (CMs), which offer fewer function evaluations, rely on distilling CFG knowledge from pretrained DMs to achieve guidance, making them costly and inflexible. In this work, we propose invertible Guided Consistency Training (iGCT), a novel training framework for guided CMs that is entirely data-driven. iGCT, as a pioneering work, contributes to fast and guided image generation and editing without requiring the training and distillation of DMs, greatly reducing the overall compute requirements. iGCT addresses the saturation artifacts seen in CFG under high guidance scales. Our extensive experiments on CIFAR-10 and ImageNet64 show that iGCT significantly improves FID and precision compared to CFG. At a guidance of 13, iGCT improves precision to 0.8, while DM's drops to 0.47. Our work takes the first step toward enabling guidance and inversion for CMs without relying on DMs.
Beyond [cls]: Exploring the true potential of Masked Image Modeling representations
Dec 04, 2024![Figure 1 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F2-Figure2-1.png&w=640&q=75)
![Figure 4 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F13-Table2-1.png&w=640&q=75)
Masked Image Modeling (MIM) has emerged as a popular method for Self-Supervised Learning (SSL) of visual representations. However, for high-level perception tasks, MIM-pretrained models offer lower out-of-the-box representation quality than the Joint-Embedding Architectures (JEA) - another prominent SSL paradigm. To understand this performance gap, we analyze the information flow in Vision Transformers (ViT) learned by both approaches. We reveal that whereas JEAs construct their representation on a selected set of relevant image fragments, MIM models aggregate nearly whole image content. Moreover, we demonstrate that MIM-trained ViTs retain valuable information within their patch tokens, which is not effectively captured by the global [cls] token representations. Therefore, selective aggregation of relevant patch tokens, without any fine-tuning, results in consistently higher-quality of MIM representations. To our knowledge, we are the first to highlight the lack of effective representation aggregation as an emergent issue of MIM and propose directions to address it, contributing to future advances in Self-Supervised Learning.
Self-supervised Video Instance Segmentation Can Boost Geographic Entity Alignment in Historical Maps
Nov 26, 2024



Tracking geographic entities from historical maps, such as buildings, offers valuable insights into cultural heritage, urbanization patterns, environmental changes, and various historical research endeavors. However, linking these entities across diverse maps remains a persistent challenge for researchers. Traditionally, this has been addressed through a two-step process: detecting entities within individual maps and then associating them via a heuristic-based post-processing step. In this paper, we propose a novel approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). This method significantly streamlines geographic entity alignment and enhances automation. However, acquiring high-quality, video-format training data for VIS models is prohibitively expensive, especially for historical maps that often contain hundreds or thousands of geographic entities. To mitigate this challenge, we explore self-supervised learning (SSL) techniques to enhance VIS performance on historical maps. We evaluate the performance of VIS models under different pretraining configurations and introduce a novel method for generating synthetic videos from unlabeled historical map images for pretraining. Our proposed self-supervised VIS method substantially reduces the need for manual annotation. Experimental results demonstrate the superiority of the proposed self-supervised VIS approach, achieving a 24.9\% improvement in AP and a 0.23 increase in F1 score compared to the model trained from scratch.
Cross-Entropy Is All You Need To Invert the Data Generating Process
Oct 29, 2024



Supervised learning has become a cornerstone of modern machine learning, yet a comprehensive theory explaining its effectiveness remains elusive. Empirical phenomena, such as neural analogy-making and the linear representation hypothesis, suggest that supervised models can learn interpretable factors of variation in a linear fashion. Recent advances in self-supervised learning, particularly nonlinear Independent Component Analysis, have shown that these methods can recover latent structures by inverting the data generating process. We extend these identifiability results to parametric instance discrimination, then show how insights transfer to the ubiquitous setting of supervised learning with cross-entropy minimization. We prove that even in standard classification tasks, models learn representations of ground-truth factors of variation up to a linear transformation. We corroborate our theoretical contribution with a series of empirical studies. First, using simulated data matching our theoretical assumptions, we demonstrate successful disentanglement of latent factors. Second, we show that on DisLib, a widely-used disentanglement benchmark, simple classification tasks recover latent structures up to linear transformations. Finally, we reveal that models trained on ImageNet encode representations that permit linear decoding of proxy factors of variation. Together, our theoretical findings and experiments offer a compelling explanation for recent observations of linear representations, such as superposition in neural networks. This work takes a significant step toward a cohesive theory that accounts for the unreasonable effectiveness of supervised deep learning.
The Fair Language Model Paradox
Oct 15, 2024



Large Language Models (LLMs) are widely deployed in real-world applications, yet little is known about their training dynamics at the token level. Evaluation typically relies on aggregated training loss, measured at the batch level, which overlooks subtle per-token biases arising from (i) varying token-level dynamics and (ii) structural biases introduced by hyperparameters. While weight decay is commonly used to stabilize training, we reveal that it silently introduces performance biases detectable only at the token level. In fact, we empirically show across different dataset sizes, model architectures and sizes ranging from 270M to 3B parameters that as weight decay increases, low-frequency tokens are disproportionately depreciated. This is particularly concerning, as these neglected low-frequency tokens represent the vast majority of the token distribution in most languages, calling for novel regularization techniques that ensure fairness across all available tokens.