 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Agent-based Epidemiology
Jul 20, 2022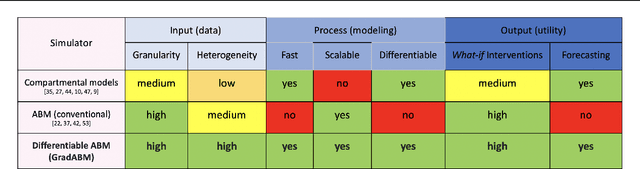
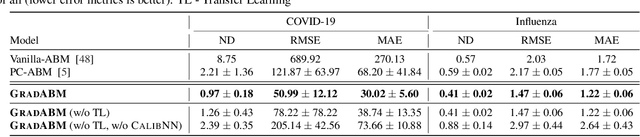
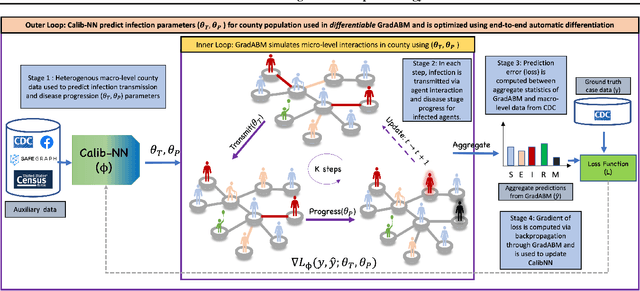

Mechanistic simulators are an indispensable tool for epidemiology to explore the behavior of complex, dynamic infections under varying conditions and navigate uncertain environments. ODE-based models are the dominant paradigm that enable fast simulations and are tractable to gradient-based optimization, but make simplifying assumptions about population homogeneity. Agent-based models (ABMs) are an increasingly popular alternative paradigm that can represent the heterogeneity of contact interactions with granular detail and agency of individual behavior. However, conventional ABM frameworks are not differentiable and present challenges in scalability; due to which it is non-trivial to connect them to auxiliary data sources easily. In this paper we introduce GradABM which is a new scalable, fast and differentiable design for ABMs. GradABM runs simulations in few seconds on commodity hardware and enables fast forward and differentiable inverse simulations. This makes it amenable to be merged with deep neural networks and seamlessly integrate heterogeneous data sources to help with calibration, forecasting and policy evaluation. We demonstrate the efficacy of GradABM via extensive experiments with real COVID-19 and influenza datasets. We are optimistic this work will bring ABM and AI communities closer together.
Private independence testing across two parties
Jul 08, 2022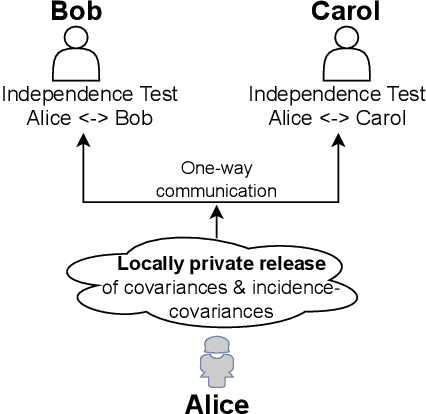

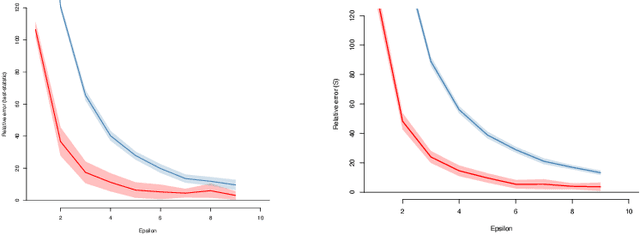
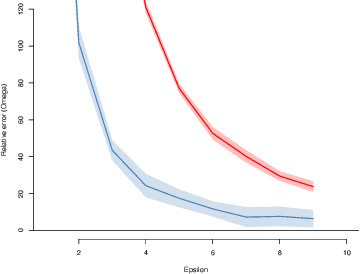
We introduce $\pi$-test, a privacy-preserving algorithm for testing statistical independence between data distributed across multiple parties. Our algorithm relies on privately estimating the distance correlation between datasets, a quantitative measure of independence introduced in Sz\'ekely et al. [2007]. We establish both additive and multiplicative error bounds on the utility of our differentially private test, which we believe will find applications in a variety of distributed hypothesis testing settings involving sensitive data.
Visual Transformer Meets CutMix for Improved Accuracy, Communication Efficiency, and Data Privacy in Split Learning
Jul 01, 2022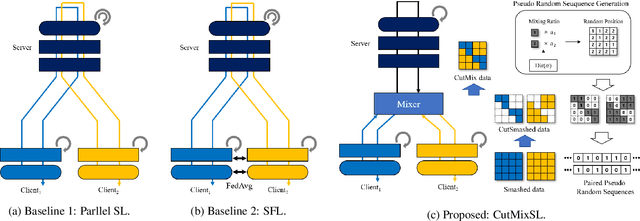
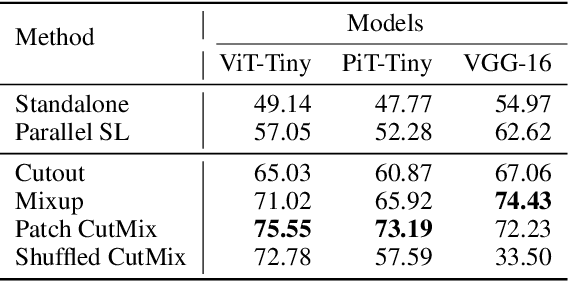
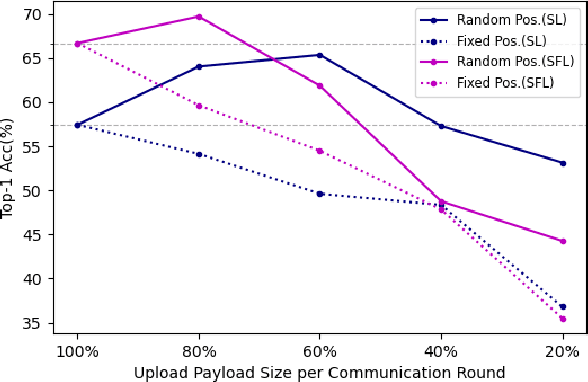
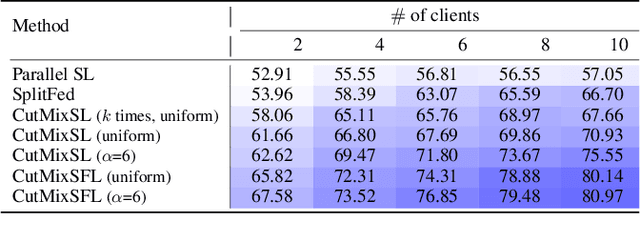
This article seeks for a distributed learning solution for the visual transformer (ViT) architectures. Compared to convolutional neural network (CNN) architectures, ViTs often have larger model sizes, and are computationally expensive, making federated learning (FL) ill-suited. Split learning (SL) can detour this problem by splitting a model and communicating the hidden representations at the split-layer, also known as smashed data. Notwithstanding, the smashed data of ViT are as large as and as similar as the input data, negating the communication efficiency of SL while violating data privacy. To resolve these issues, we propose a new form of CutSmashed data by randomly punching and compressing the original smashed data. Leveraging this, we develop a novel SL framework for ViT, coined CutMixSL, communicating CutSmashed data. CutMixSL not only reduces communication costs and privacy leakage, but also inherently involves the CutMix data augmentation, improving accuracy and scalability. Simulations corroborate that CutMixSL outperforms baselines such as parallelized SL and SplitFed that integrates FL with SL.
Physics vs. Learned Priors: Rethinking Camera and Algorithm Design for Task-Specific Imaging
Apr 21, 2022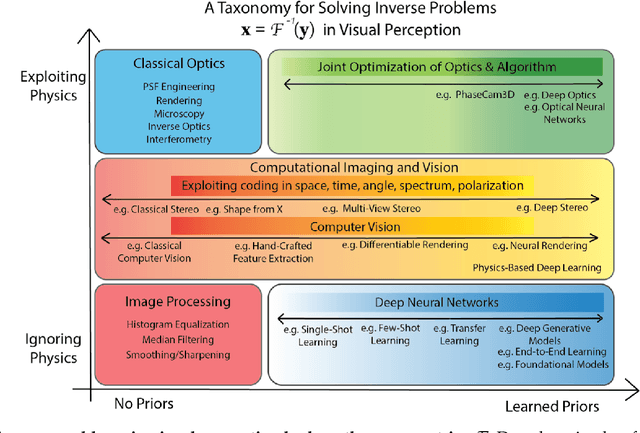
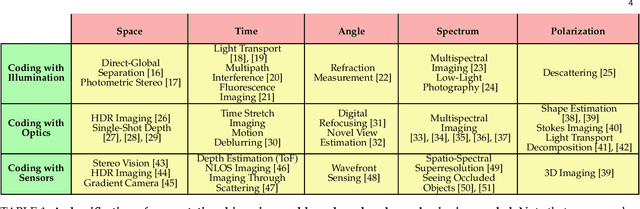
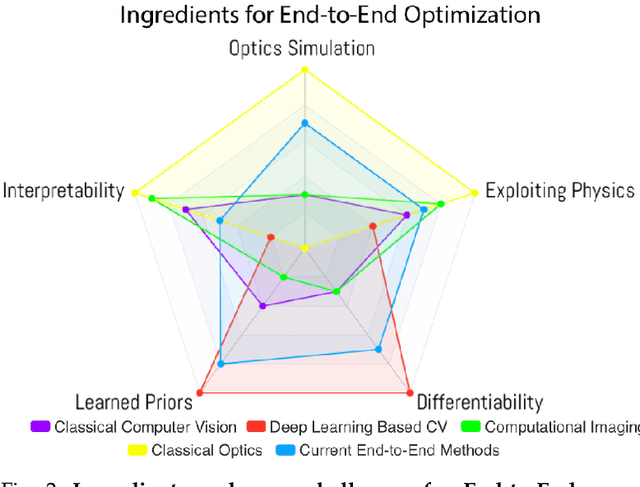
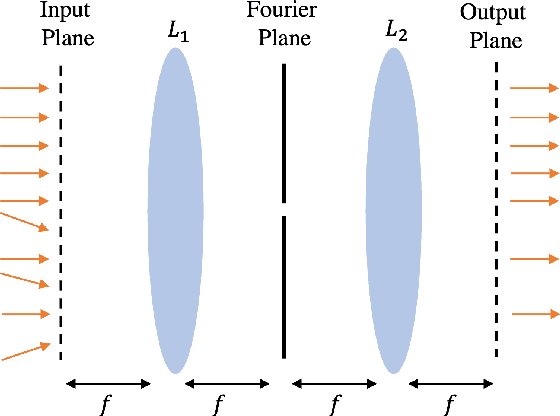
Cameras were originally designed using physics-based heuristics to capture aesthetic images. In recent years, there has been a transformation in camera design from being purely physics-driven to increasingly data-driven and task-specific. In this paper, we present a framework to understand the building blocks of this nascent field of end-to-end design of camera hardware and algorithms. As part of this framework, we show how methods that exploit both physics and data have become prevalent in imaging and computer vision, underscoring a key trend that will continue to dominate the future of task-specific camera design. Finally, we share current barriers to progress in end-to-end design, and hypothesize how these barriers can be overcome.
Physically Disentangled Representations
Apr 11, 2022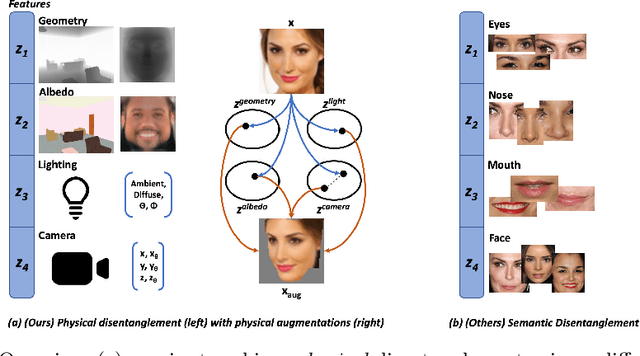
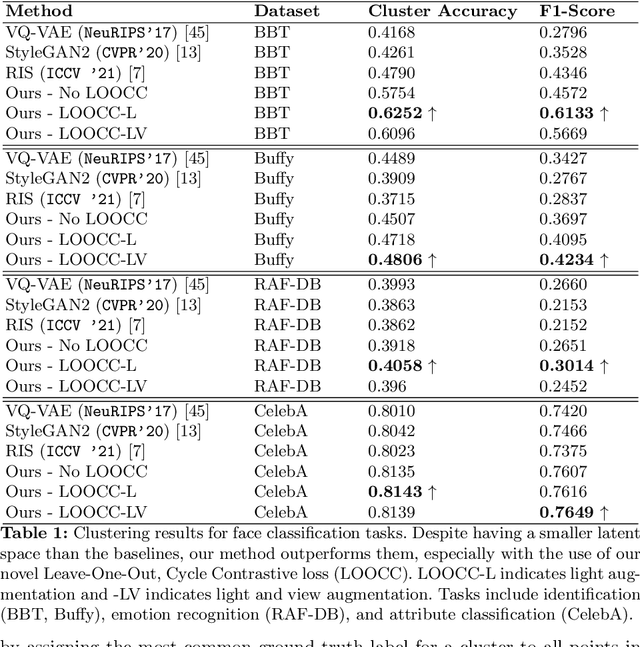
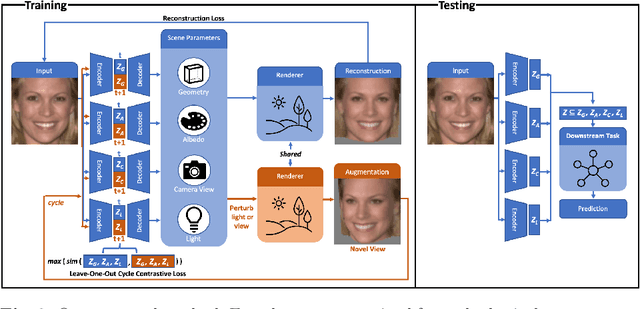
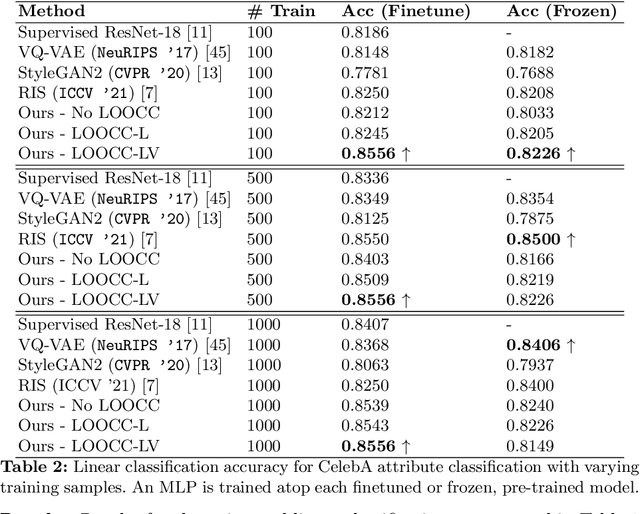
State-of-the-art methods in generative representation learning yield semantic disentanglement, but typically do not consider physical scene parameters, such as geometry, albedo, lighting, or camera. We posit that inverse rendering, a way to reverse the rendering process to recover scene parameters from an image, can also be used to learn physically disentangled representations of scenes without supervision. In this paper, we show the utility of inverse rendering in learning representations that yield improved accuracy on downstream clustering, linear classification, and segmentation tasks with the help of our novel Leave-One-Out, Cycle Contrastive loss (LOOCC), which improves disentanglement of scene parameters and robustness to out-of-distribution lighting and viewpoints. We perform a comparison of our method with other generative representation learning methods across a variety of downstream tasks, including face attribute classification, emotion recognition, identification, face segmentation, and car classification. Our physically disentangled representations yield higher accuracy than semantically disentangled alternatives across all tasks and by as much as 18%. We hope that this work will motivate future research in applying advances in inverse rendering and 3D understanding to representation learning.
Towards Learning Neural Representations from Shadows
Mar 29, 2022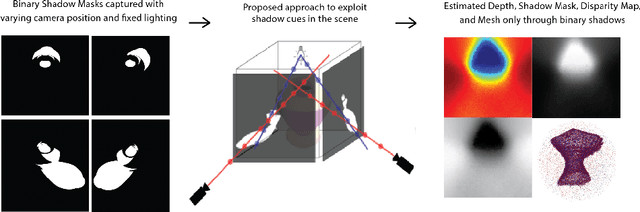
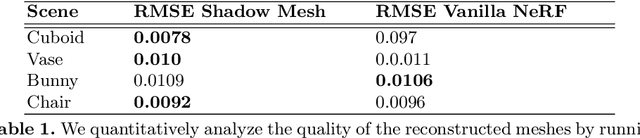
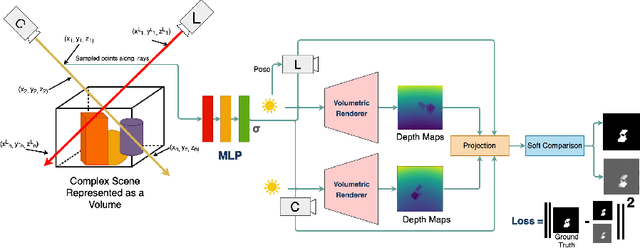
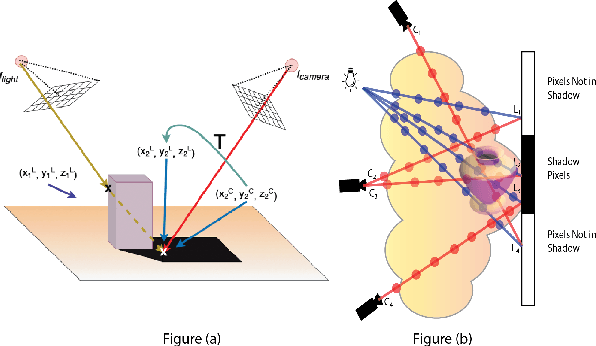
We present a method that learns neural scene representations from only shadows present in the scene. While traditional shape-from-shadow (SfS) algorithms reconstruct geometry from shadows, they assume a fixed scanning setup and fail to generalize to complex scenes. Neural rendering algorithms, on the other hand, rely on photometric consistency between RGB images but largely ignore physical cues such as shadows, which have been shown to provide valuable information about the scene. We observe that shadows are a powerful cue that can constrain neural scene representations to learn SfS, and even outperform NeRF to reconstruct otherwise hidden geometry. We propose a graphics-inspired differentiable approach to render accurate shadows with volumetric rendering, predicting a shadow map that can be compared to the ground truth shadow. Even with just binary shadow maps, we show that neural rendering can localize the object and estimate coarse geometry. Our approach reveals that sparse cues in images can be used to estimate geometry using differentiable volumetric rendering. Moreover, our framework is highly generalizable and can work alongside existing 3D reconstruction techniques that otherwise only use photometric consistency. Our code is made available in our supplementary materials.
Learning to Censor by Noisy Sampling
Mar 23, 2022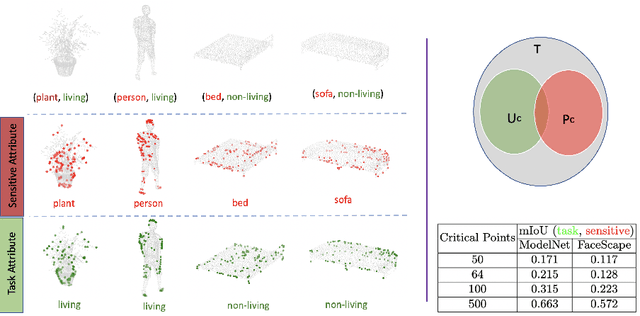
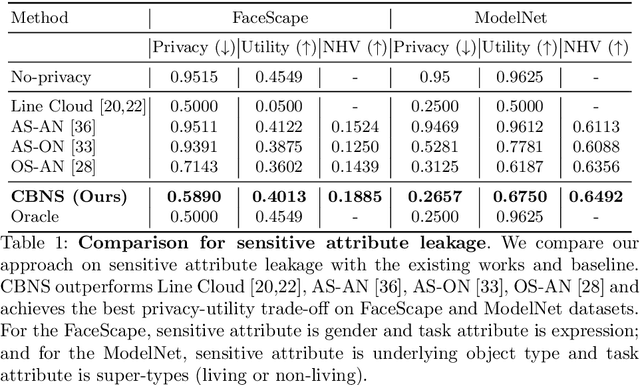

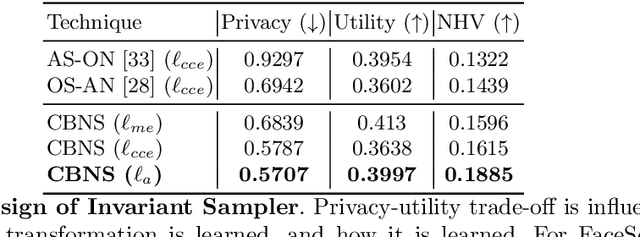
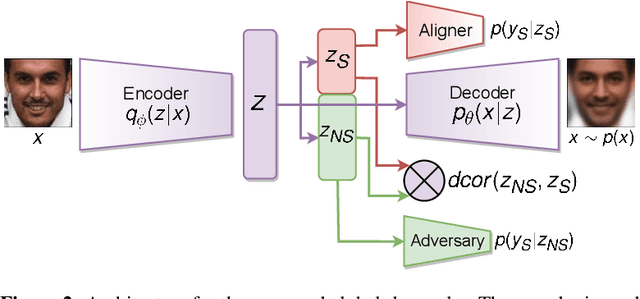
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring the sensitive information before the point cloud is released for downstream tasks. Specifically, we focus on preserving utility for perception tasks while mitigating attribute leakage attacks. The key motivating insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs. We realize this through a mechanism called Censoring by Noisy Sampling (CBNS), which is composed of two modules: i) Invariant Sampler: a differentiable point-cloud sampler which learns to remove points invariant to utility and ii) Noisy Distorter: which learns to distort sampled points to decouple the sensitive information from utility, and mitigate privacy leakage. We validate the effectiveness of CBNS through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Results show that CBNS achieves superior privacy-utility trade-offs on multiple datasets.
Decouple-and-Sample: Protecting sensitive information in task agnostic data release
Mar 17, 2022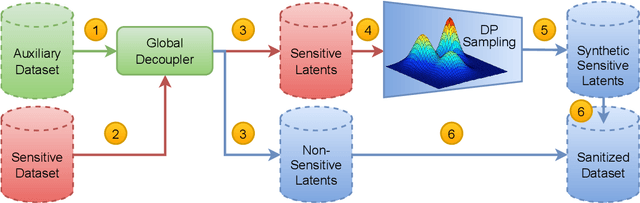
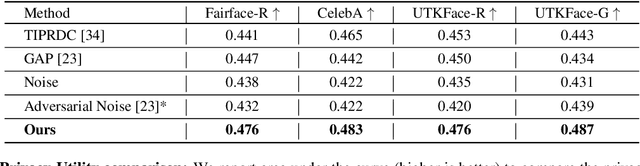
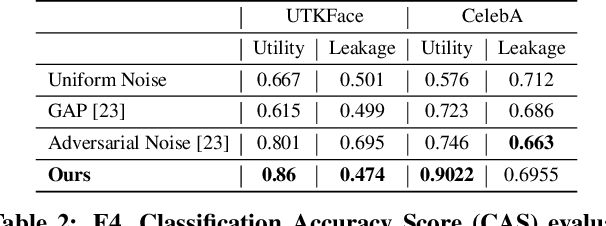
We propose sanitizer, a framework for secure and task-agnostic data release. While releasing datasets continues to make a big impact in various applications of computer vision, its impact is mostly realized when data sharing is not inhibited by privacy concerns. We alleviate these concerns by sanitizing datasets in a two-stage process. First, we introduce a global decoupling stage for decomposing raw data into sensitive and non-sensitive latent representations. Secondly, we design a local sampling stage to synthetically generate sensitive information with differential privacy and merge it with non-sensitive latent features to create a useful representation while preserving the privacy. This newly formed latent information is a task-agnostic representation of the original dataset with anonymized sensitive information. While most algorithms sanitize data in a task-dependent manner, a few task-agnostic sanitization techniques sanitize data by censoring sensitive information. In this work, we show that a better privacy-utility trade-off is achieved if sensitive information can be synthesized privately. We validate the effectiveness of the sanitizer by outperforming state-of-the-art baselines on the existing benchmark tasks and demonstrating tasks that are not possible using existing techniques.
Server-Side Local Gradient Averaging and Learning Rate Acceleration for Scalable Split Learning
Dec 11, 2021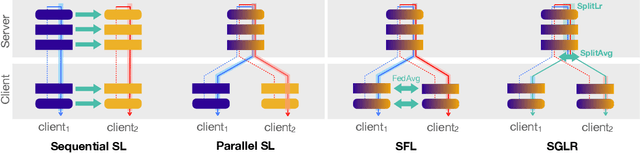
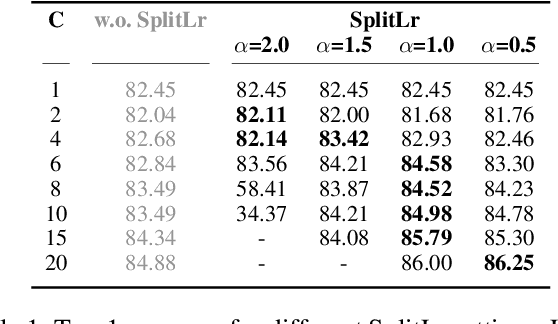
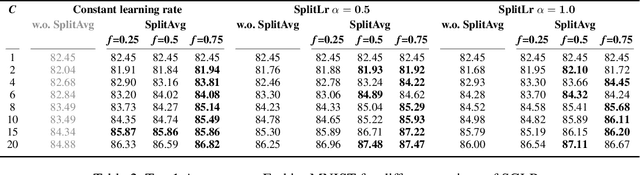

In recent years, there have been great advances in the field of decentralized learning with private data. Federated learning (FL) and split learning (SL) are two spearheads possessing their pros and cons, and are suited for many user clients and large models, respectively. To enjoy both benefits, hybrid approaches such as SplitFed have emerged of late, yet their fundamentals have still been illusive. In this work, we first identify the fundamental bottlenecks of SL, and thereby propose a scalable SL framework, coined SGLR. The server under SGLR broadcasts a common gradient averaged at the split-layer, emulating FL without any additional communication across clients as opposed to SplitFed. Meanwhile, SGLR splits the learning rate into its server-side and client-side rates, and separately adjusts them to support many clients in parallel. Simulation results corroborate that SGLR achieves higher accuracy than other baseline SL methods including SplitFed, which is even on par with FL consuming higher energy and communication costs. As a secondary result, we observe greater reduction in leakage of sensitive information via mutual information using SLGR over the baselines.
AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021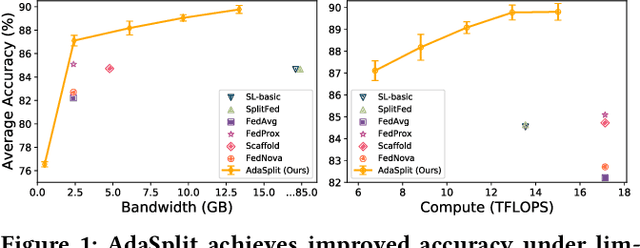
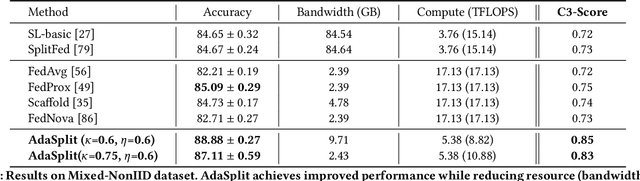
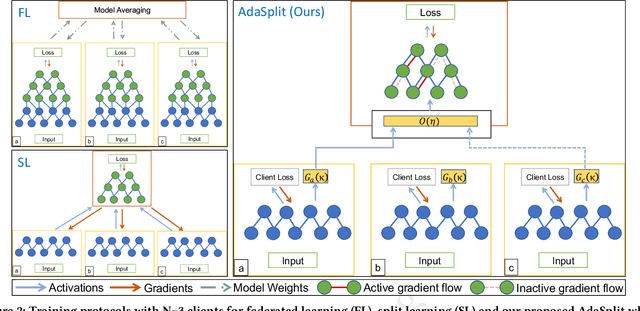
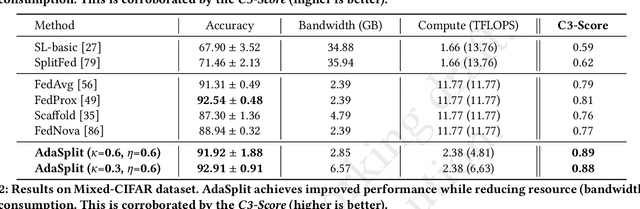
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.