 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffAlign : Few-shot learning using diffusion based synthesis and alignment
Dec 11, 2022We address the problem of few-shot classification where the goal is to learn a classifier from a limited set of samples. While data-driven learning is shown to be effective in various applications, learning from less data still remains challenging. To address this challenge, existing approaches consider various data augmentation techniques for increasing the number of training samples. Pseudo-labeling is commonly used in a few-shot setup, where approximate labels are estimated for a large set of unlabeled images. We propose DiffAlign which focuses on generating images from class labels. Specifically, we leverage the recent success of the generative models (e.g., DALL-E and diffusion models) that can generate realistic images from texts. However, naive learning on synthetic images is not adequate due to the domain gap between real and synthetic images. Thus, we employ a maximum mean discrepancy (MMD) loss to align the synthetic images to the real images minimizing the domain gap. We evaluate our method on the standard few-shot classification benchmarks: CIFAR-FS, FC100, miniImageNet, tieredImageNet and a cross-domain few-shot classification benchmark: miniImageNet to CUB. The proposed approach significantly outperforms the stateof-the-art in both 5-shot and 1-shot setups on these benchmarks. Our approach is also shown to be effective in the zero-shot classification setup
Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning
Oct 17, 2022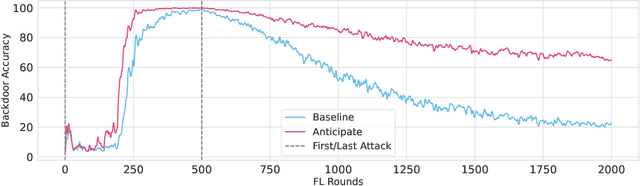
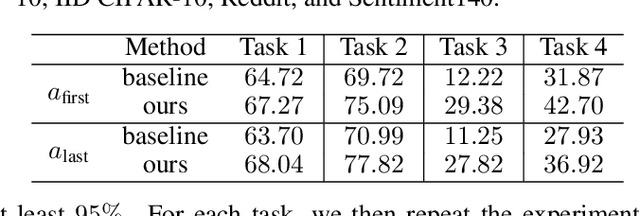
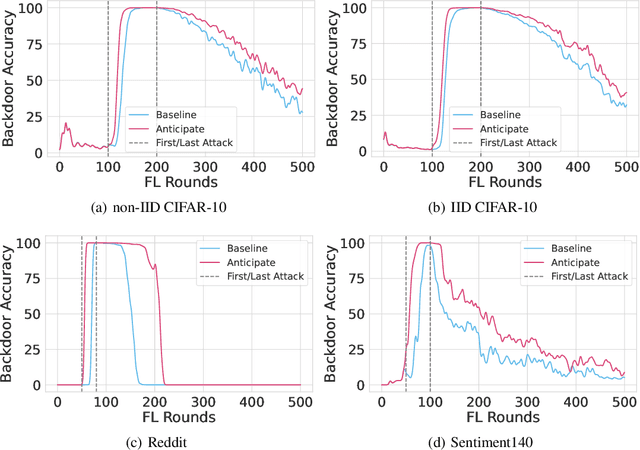
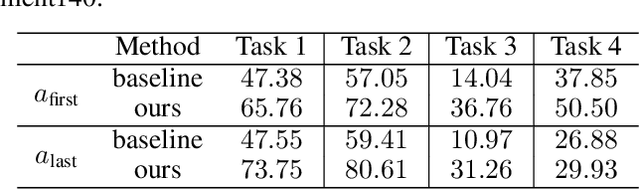
Federated learning is particularly susceptible to model poisoning and backdoor attacks because individual users have direct control over the training data and model updates. At the same time, the attack power of an individual user is limited because their updates are quickly drowned out by those of many other users. Existing attacks do not account for future behaviors of other users, and thus require many sequential updates and their effects are quickly erased. We propose an attack that anticipates and accounts for the entire federated learning pipeline, including behaviors of other clients, and ensures that backdoors are effective quickly and persist even after multiple rounds of community updates. We show that this new attack is effective in realistic scenarios where the attacker only contributes to a small fraction of randomly sampled rounds and demonstrate this attack on image classification, next-word prediction, and sentiment analysis.
DA-VSR: Domain Adaptable Volumetric Super-Resolution For Medical Images
Oct 11, 2022Medical image super-resolution (SR) is an active research area that has many potential applications, including reducing scan time, bettering visual understanding, increasing robustness in downstream tasks, etc. However, applying deep-learning-based SR approaches for clinical applications often encounters issues of domain inconsistency, as the test data may be acquired by different machines or on different organs. In this work, we present a novel algorithm called domain adaptable volumetric super-resolution (DA-VSR) to better bridge the domain inconsistency gap. DA-VSR uses a unified feature extraction backbone and a series of network heads to improve image quality over different planes. Furthermore, DA-VSR leverages the in-plane and through-plane resolution differences on the test data to achieve a self-learned domain adaptation. As such, DA-VSR combines the advantages of a strong feature generator learned through supervised training and the ability to tune to the idiosyncrasies of the test volumes through unsupervised learning. Through experiments, we demonstrate that DA-VSR significantly improves super-resolution quality across numerous datasets of different domains, thereby taking a further step toward real clinical applications.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022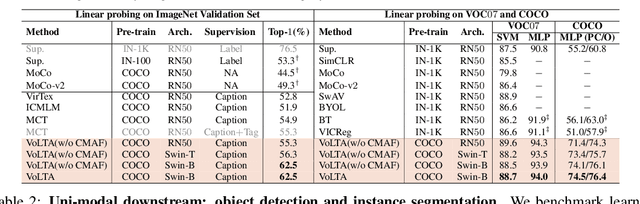
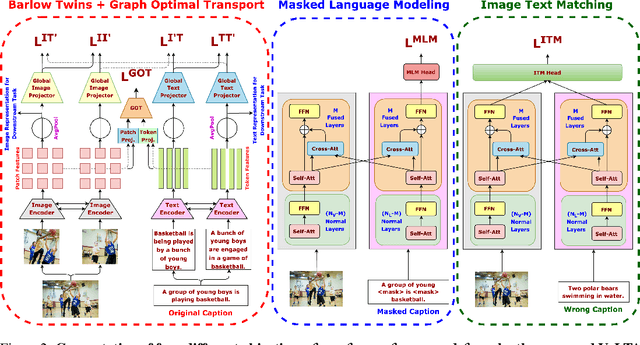
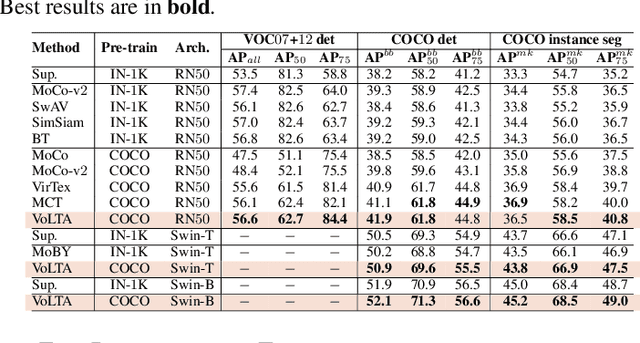

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.
Multi-Modal Human Authentication Using Silhouettes, Gait and RGB
Oct 08, 2022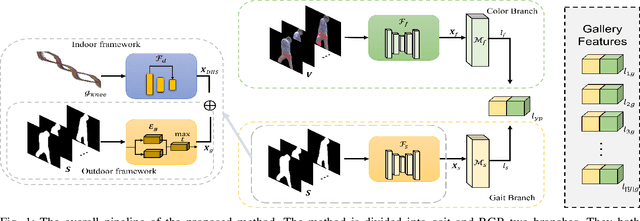
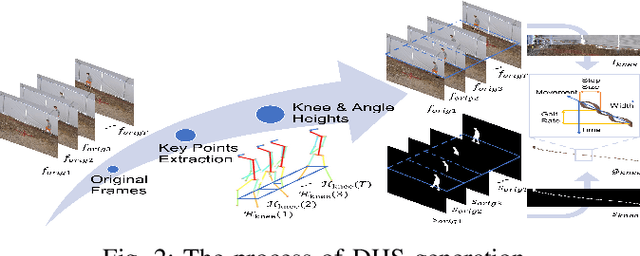


Whole-body-based human authentication is a promising approach for remote biometrics scenarios. Current literature focuses on either body recognition based on RGB images or gait recognition based on body shapes and walking patterns; both have their advantages and drawbacks. In this work, we propose Dual-Modal Ensemble (DME), which combines both RGB and silhouette data to achieve more robust performances for indoor and outdoor whole-body based recognition. Within DME, we propose GaitPattern, which is inspired by the double helical gait pattern used in traditional gait analysis. The GaitPattern contributes to robust identification performance over a large range of viewing angles. Extensive experimental results on the CASIA-B dataset demonstrate that the proposed method outperforms state-of-the-art recognition systems. We also provide experimental results using the newly collected BRIAR dataset.
PDRF: Progressively Deblurring Radiance Field for Fast and Robust Scene Reconstruction from Blurry Images
Aug 17, 2022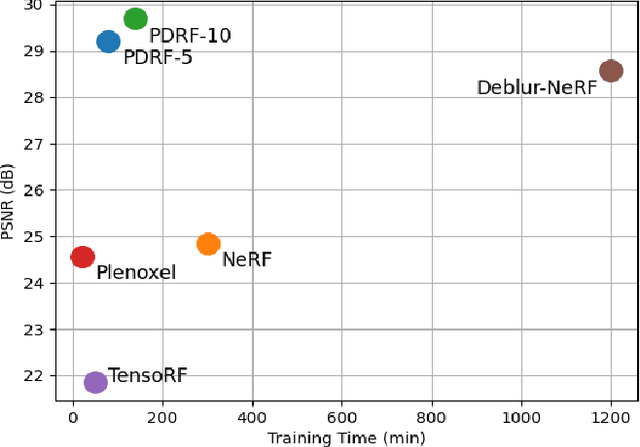
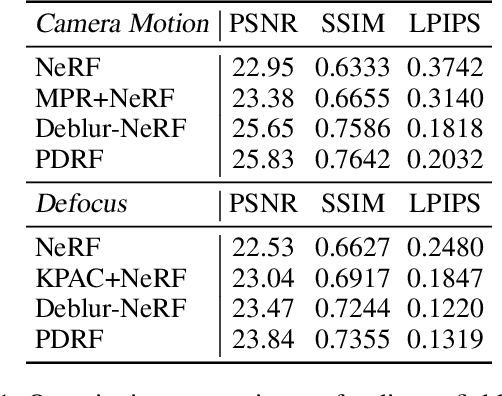

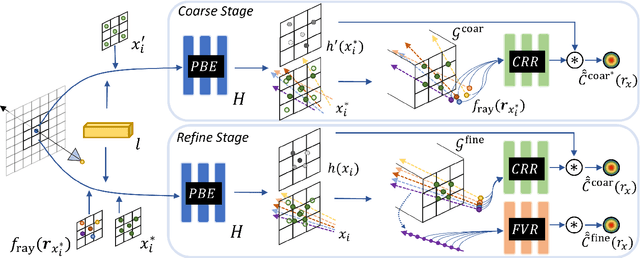
We present Progressively Deblurring Radiance Field (PDRF), a novel approach to efficiently reconstruct high quality radiance fields from blurry images. While current State-of-The-Art (SoTA) scene reconstruction methods achieve photo-realistic rendering results from clean source views, their performances suffer when the source views are affected by blur, which is commonly observed for images in the wild. Previous deblurring methods either do not account for 3D geometry, or are computationally intense. To addresses these issues, PDRF, a progressively deblurring scheme in radiance field modeling, accurately models blur by incorporating 3D scene context. PDRF further uses an efficient importance sampling scheme, which results in fast scene optimization. Specifically, PDRF proposes a Coarse Ray Renderer to quickly estimate voxel density and feature; a Fine Voxel Renderer is then used to achieve high quality ray tracing. We perform extensive experiments and show that PDRF is 15X faster than previous SoTA while achieving better performance on both synthetic and real scenes.
REGAS: REspiratory-GAted Synthesis of Views for Multi-Phase CBCT Reconstruction from a single 3D CBCT Acquisition
Aug 17, 2022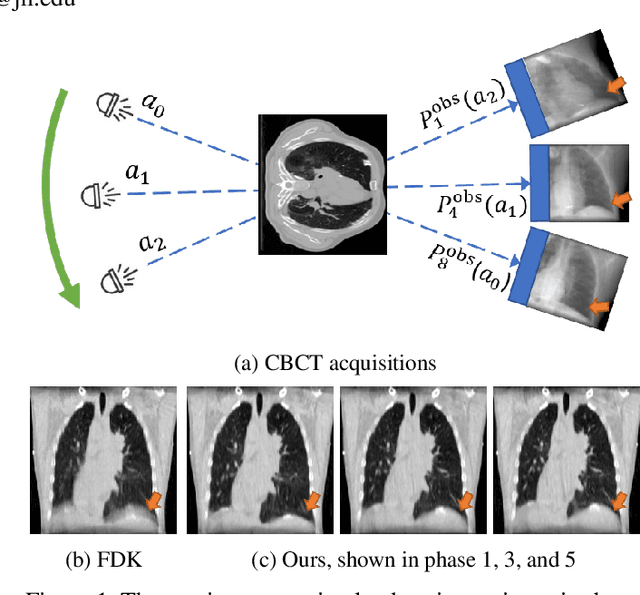
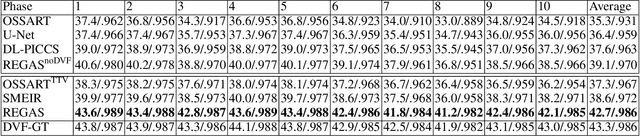
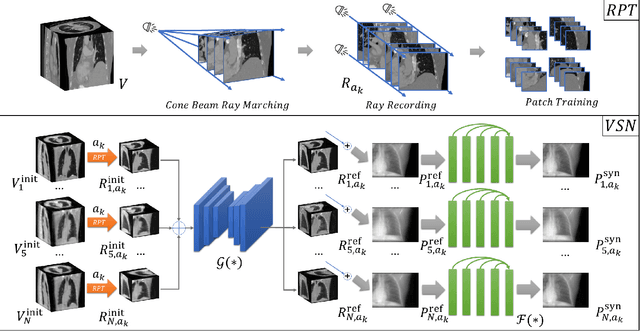
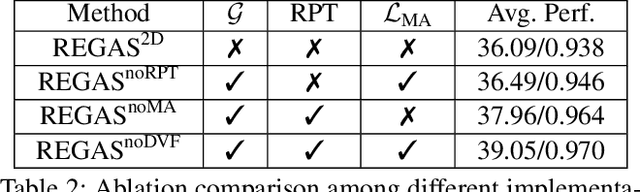
It is a long-standing challenge to reconstruct Cone Beam Computed Tomography (CBCT) of the lung under respiratory motion. This work takes a step further to address a challenging setting in reconstructing a multi-phase}4D lung image from just a single}3D CBCT acquisition. To this end, we introduce REpiratory-GAted Synthesis of views, or REGAS. REGAS proposes a self-supervised method to synthesize the undersampled tomographic views and mitigate aliasing artifacts in reconstructed images. This method allows a much better estimation of between-phase Deformation Vector Fields (DVFs), which are used to enhance reconstruction quality from direct observations without synthesis. To address the large memory cost of deep neural networks on high resolution 4D data, REGAS introduces a novel Ray Path Transformation (RPT) that allows for distributed, differentiable forward projections. REGAS require no additional measurements like prior scans, air-flow volume, or breathing velocity. Our extensive experiments show that REGAS significantly outperforms comparable methods in quantitative metrics and visual quality.
Scalable Vehicle Re-Identification via Self-Supervision
May 16, 2022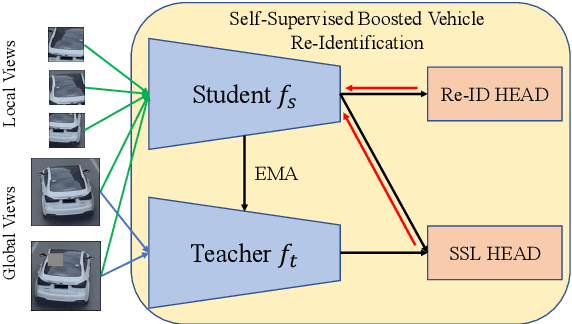
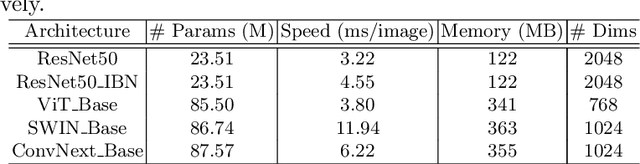
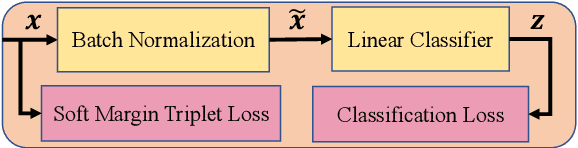
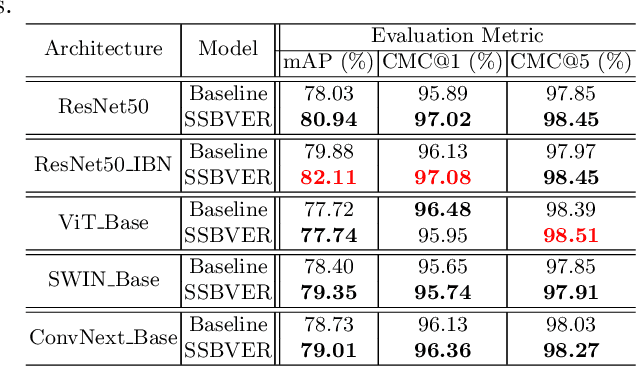
As Computer Vision technologies become more mature for intelligent transportation applications, it is time to ask how efficient and scalable they are for large-scale and real-time deployment. Among these technologies is Vehicle Re-Identification which is one of the key elements in city-scale vehicle analytics systems. Many state-of-the-art solutions for vehicle re-id mostly focus on improving the accuracy on existing re-id benchmarks and often ignore computational complexity. To balance the demands of accuracy and computational efficiency, in this work we propose a simple yet effective hybrid solution empowered by self-supervised training which only uses a single network during inference time and is free of intricate and computation-demanding add-on modules often seen in state-of-the-art approaches. Through extensive experiments, we show our approach, termed Self-Supervised and Boosted VEhicle Re-Identification (SSBVER), is on par with state-of-the-art alternatives in terms of accuracy without introducing any additional overhead during deployment. Additionally we show that our approach, generalizes to different backbone architectures which facilitates various resource constraints and consistently results in a significant accuracy boost.
Where in the World is this Image? Transformer-based Geo-localization in the Wild
Apr 29, 2022
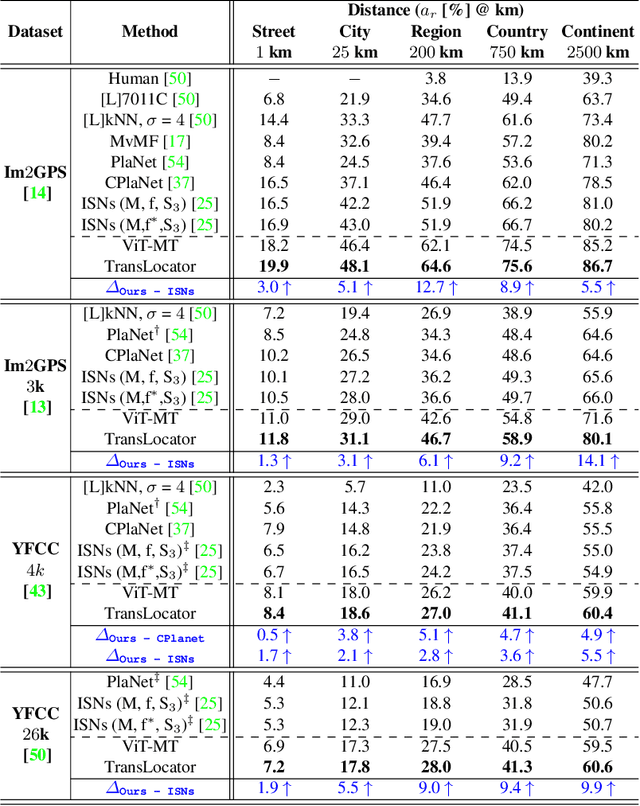
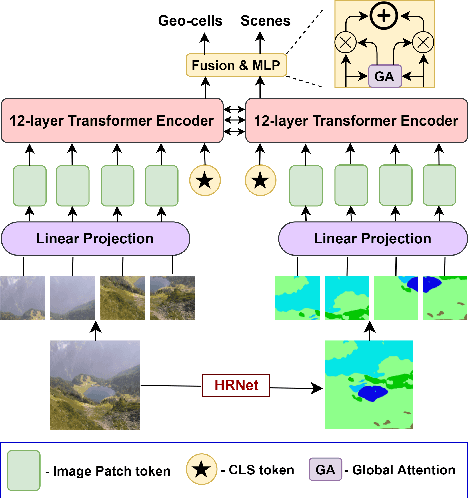
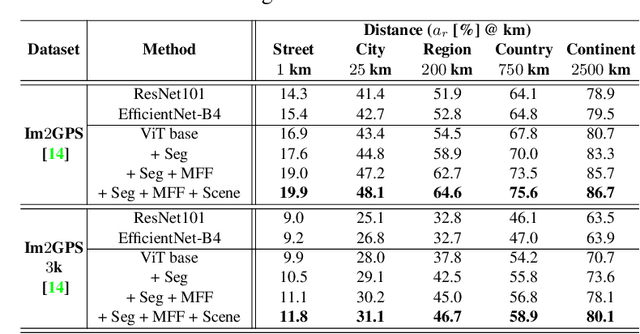
Predicting the geographic location (geo-localization) from a single ground-level RGB image taken anywhere in the world is a very challenging problem. The challenges include huge diversity of images due to different environmental scenarios, drastic variation in the appearance of the same location depending on the time of the day, weather, season, and more importantly, the prediction is made from a single image possibly having only a few geo-locating cues. For these reasons, most existing works are restricted to specific cities, imagery, or worldwide landmarks. In this work, we focus on developing an efficient solution to planet-scale single-image geo-localization. To this end, we propose TransLocator, a unified dual-branch transformer network that attends to tiny details over the entire image and produces robust feature representation under extreme appearance variations. TransLocator takes an RGB image and its semantic segmentation map as inputs, interacts between its two parallel branches after each transformer layer, and simultaneously performs geo-localization and scene recognition in a multi-task fashion. We evaluate TransLocator on four benchmark datasets - Im2GPS, Im2GPS3k, YFCC4k, YFCC26k and obtain 5.5%, 14.1%, 4.9%, 9.9% continent-level accuracy improvement over the state-of-the-art. TransLocator is also validated on real-world test images and found to be more effective than previous methods.
The 6th AI City Challenge
Apr 21, 2022
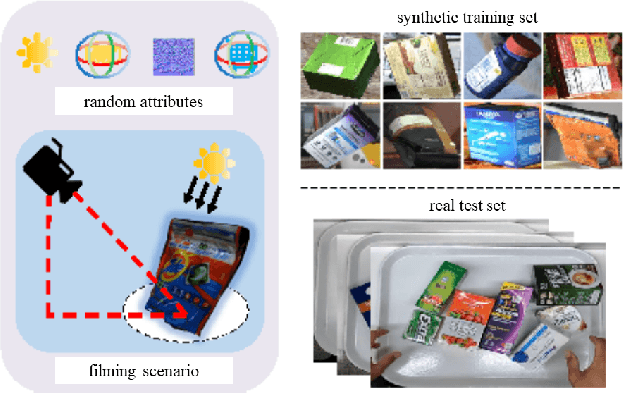
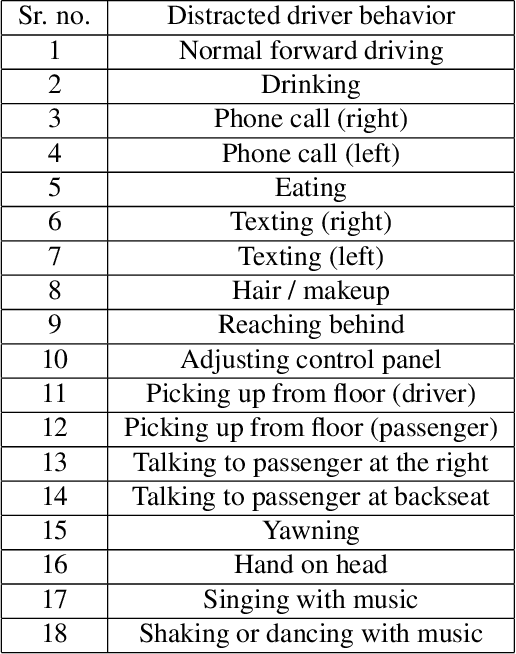
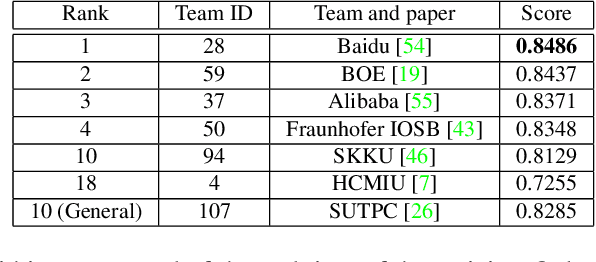
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.