 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Reinforcement Learning for Content Caching at the Wireless Edge via Restless Bandits
Feb 26, 2022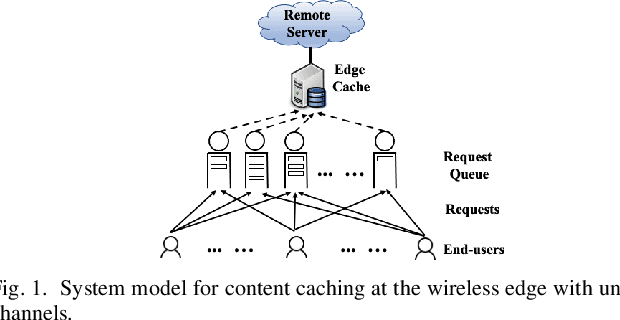
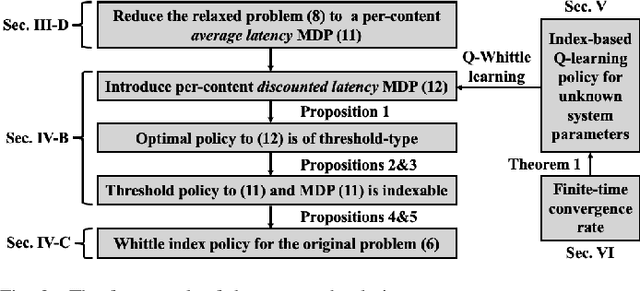
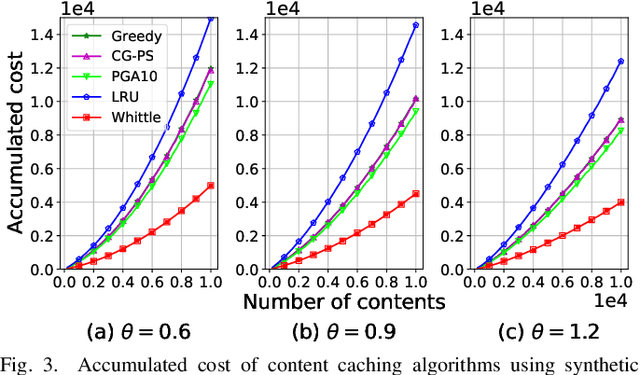
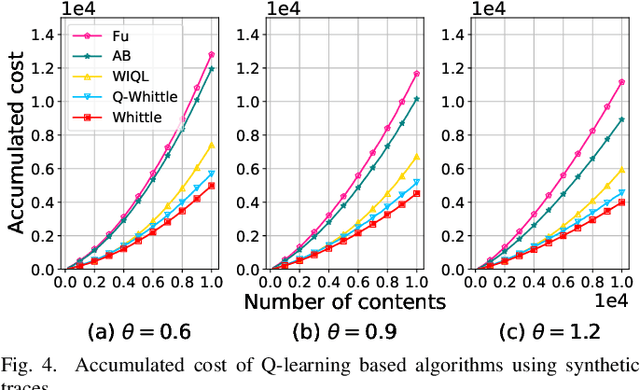
An explosive growth in the number of on-demand content requests has imposed significant pressure on current wireless network infrastructure. To enhance the perceived user experience, and support latency-sensitive applications, edge computing has emerged as a promising computing paradigm. The performance of a wireless edge depends on contents that are cached. In this paper, we consider the problem of content caching at the wireless edge with unreliable channels to minimize average content request latency. We formulate this problem as a restless bandit problem, which is provably hard to solve. We begin by investigating a discounted counterpart, and prove that it admits an optimal policy of the threshold-type. We then show that the result also holds for the average latency problem. Using these structural results, we establish the indexability of the problem, and employ Whittle index policy to minimize average latency. Since system parameters such as content request rate are often unknown, we further develop a model-free reinforcement learning algorithm dubbed Q-Whittle learning that relies on our index policy. We also derive a bound on its finite-time convergence rate. Simulation results using real traces demonstrate that our proposed algorithms yield excellent empirical performance.
Augmented RBMLE-UCB Approach for Adaptive Control of Linear Quadratic Systems
Jan 25, 2022We consider the problem of controlling a stochastic linear system with quadratic costs, when its system parameters are not known to the agent -- called the adaptive LQG control problem. We re-examine an approach called "Reward-Biased Maximum Likelihood Estimate" (RBMLE) that was proposed more than forty years ago, and which predates the "Upper Confidence Bound" (UCB) method as well as the definition of "regret". It simply added a term favoring parameters with larger rewards to the estimation criterion. We propose an augmented approach that combines the penalty of the RBMLE method with the constraint of the UCB method, uniting the two approaches to optimization in the face of uncertainty. We first establish that theoretically this method retains $\mathcal{O}(\sqrt{T})$ regret, the best known so far. We show through a comprehensive simulation study that this augmented RBMLE method considerably outperforms the UCB and Thompson sampling approaches, with a regret that is typically less than 50\% of the better of their regrets. The simulation study includes all examples from earlier papers as well as a large collection of randomly generated systems.
Generalized Kernel Ridge Regression for Long Term Causal Inference: Treatment Effects, Dose Responses, and Counterfactual Distributions
Jan 13, 2022



I propose kernel ridge regression estimators for long term causal inference, where a short term experimental data set containing randomized treatment and short term surrogates is fused with a long term observational data set containing short term surrogates and long term outcomes. I propose estimators of treatment effects, dose responses, and counterfactual distributions with closed form solutions in terms of kernel matrix operations. I allow covariates, treatment, and surrogates to be discrete or continuous, and low, high, or infinite dimensional. For long term treatment effects, I prove $\sqrt{n}$ consistency, Gaussian approximation, and semiparametric efficiency. For long term dose responses, I prove uniform consistency with finite sample rates. For long term counterfactual distributions, I prove convergence in distribution.
A Finite Sample Theorem for Longitudinal Causal Inference with Machine Learning: Long Term, Dynamic, and Mediated Effects
Dec 28, 2021I construct and justify confidence intervals for longitudinal causal parameters estimated with machine learning. Longitudinal parameters include long term, dynamic, and mediated effects. I provide a nonasymptotic theorem for any longitudinal causal parameter estimated with any machine learning algorithm that satisfies a few simple, interpretable conditions. The main result encompasses local parameters defined for specific demographics as well as proximal parameters defined in the presence of unobserved confounding. Formally, I prove consistency, Gaussian approximation, and semiparametric efficiency. The rate of convergence is $n^{-1/2}$ for global parameters, and it degrades gracefully for local parameters. I articulate a simple set of conditions to translate mean square rates into statistical inference. A key feature of the main result is a new multiple robustness to ill posedness for proximal causal inference in longitudinal settings.
Pruning Attention Heads of Transformer Models Using A* Search: A Novel Approach to Compress Big NLP Architectures
Nov 17, 2021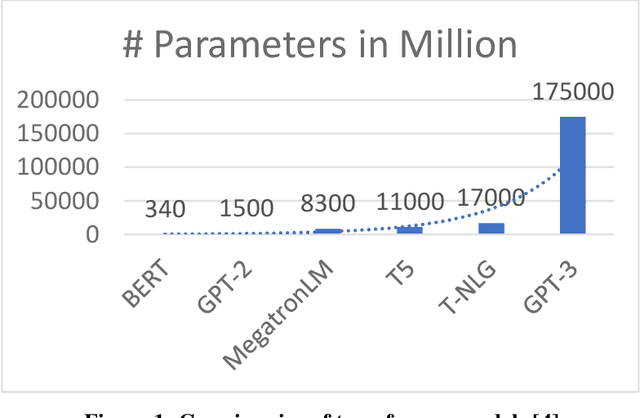

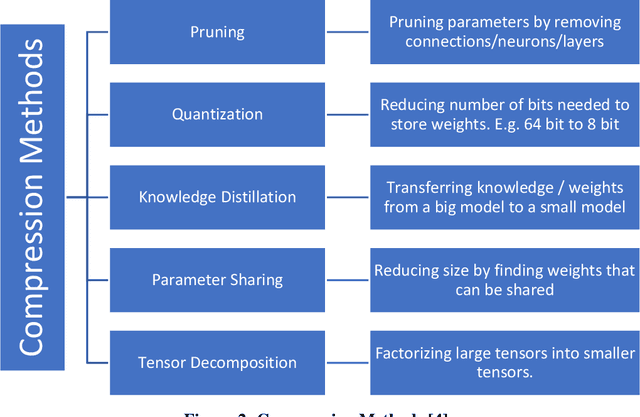
Recent years have seen a growing adoption of Transformer models such as BERT in Natural Language Processing and even in Computer Vision. However, due to their size, there has been limited adoption of such models within resource-constrained computing environments. This paper proposes novel pruning algorithm to compress transformer models by eliminating redundant Attention Heads. We apply the A* search algorithm to obtain a pruned model with strict accuracy guarantees. Our results indicate that the method could eliminate as much as 40% of the attention heads in the BERT transformer model with no loss in accuracy.
Generalized Kernel Ridge Regression for Causal Inference with Missing-at-Random Sample Selection
Nov 09, 2021
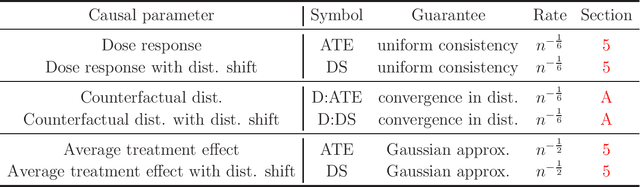
I propose kernel ridge regression estimators for nonparametric dose response curves and semiparametric treatment effects in the setting where an analyst has access to a selected sample rather than a random sample; only for select observations, the outcome is observed. I assume selection is as good as random conditional on treatment and a sufficiently rich set of observed covariates, where the covariates are allowed to cause treatment or be caused by treatment -- an extension of missingness-at-random (MAR). I propose estimators of means, increments, and distributions of counterfactual outcomes with closed form solutions in terms of kernel matrix operations, allowing treatment and covariates to be discrete or continuous, and low, high, or infinite dimensional. For the continuous treatment case, I prove uniform consistency with finite sample rates. For the discrete treatment case, I prove root-n consistency, Gaussian approximation, and semiparametric efficiency.
Kernel Methods for Multistage Causal Inference: Mediation Analysis and Dynamic Treatment Effects
Nov 06, 2021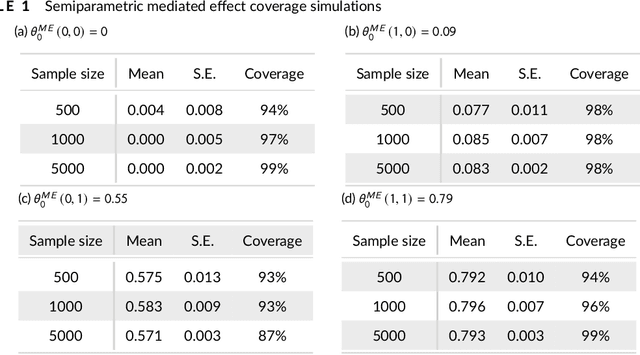
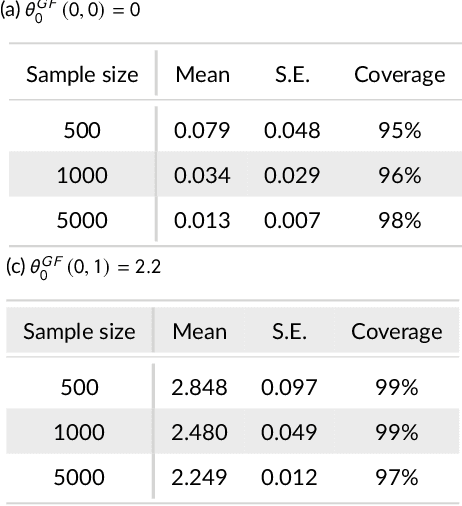
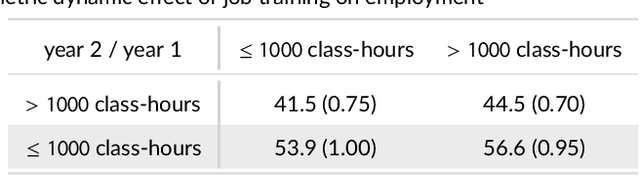
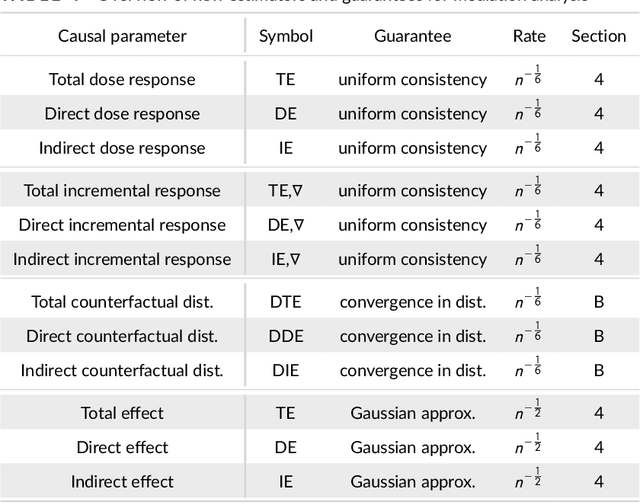
We propose kernel ridge regression estimators for mediation analysis and dynamic treatment effects over short horizons. We allow treatments, covariates, and mediators to be discrete or continuous, and low, high, or infinite dimensional. We propose estimators of means, increments, and distributions of counterfactual outcomes with closed form solutions in terms of kernel matrix operations. For the continuous treatment case, we prove uniform consistency with finite sample rates. For the discrete treatment case, we prove root-n consistency, Gaussian approximation, and semiparametric efficiency. We conduct simulations then estimate mediated and dynamic treatment effects of the US Job Corps program for disadvantaged youth.
Reinforcement Learning for Finite-Horizon Restless Multi-Armed Multi-Action Bandits
Sep 20, 2021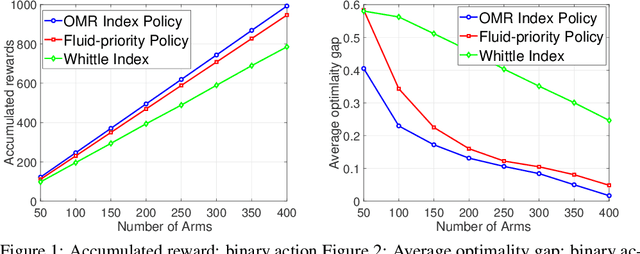
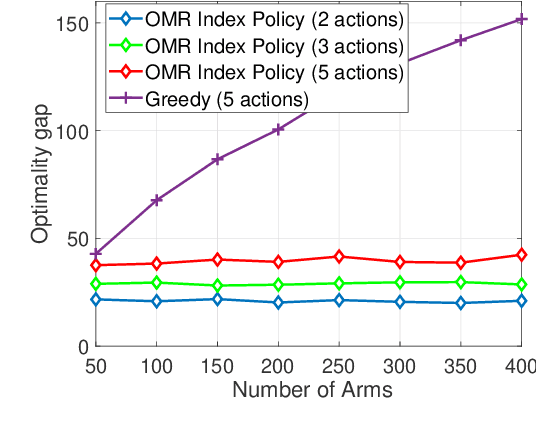
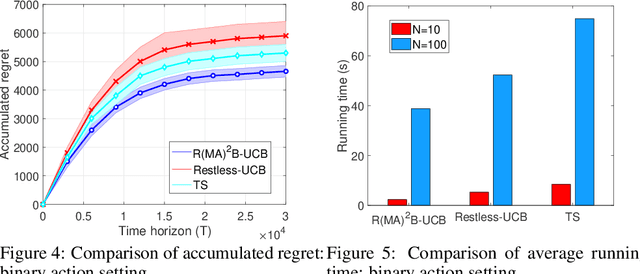
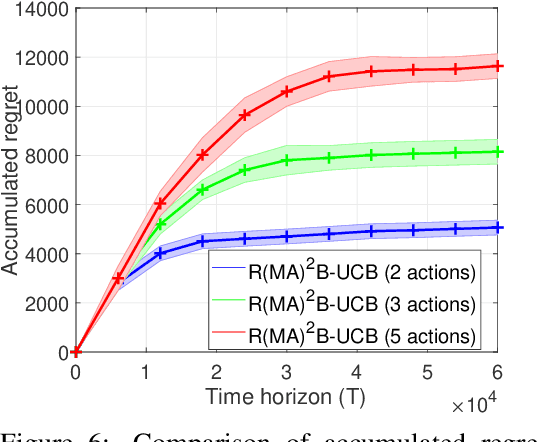
We study a finite-horizon restless multi-armed bandit problem with multiple actions, dubbed R(MA)^2B. The state of each arm evolves according to a controlled Markov decision process (MDP), and the reward of pulling an arm depends on both the current state of the corresponding MDP and the action taken. The goal is to sequentially choose actions for arms so as to maximize the expected value of the cumulative rewards collected. Since finding the optimal policy is typically intractable, we propose a computationally appealing index policy which we call Occupancy-Measured-Reward Index Policy. Our policy is well-defined even if the underlying MDPs are not indexable. We prove that it is asymptotically optimal when the activation budget and number of arms are scaled up, while keeping their ratio as a constant. For the case when the system parameters are unknown, we develop a learning algorithm. Our learning algorithm uses the principle of optimism in the face of uncertainty and further uses a generative model in order to fully exploit the structure of Occupancy-Measured-Reward Index Policy. We call it the R(MA)^2B-UCB algorithm. As compared with the existing algorithms, R(MA)^2B-UCB performs close to an offline optimum policy, and also achieves a sub-linear regret with a low computational complexity. Experimental results show that R(MA)^2B-UCB outperforms the existing algorithms in both regret and run time.
Inference of collective Gaussian hidden Markov models
Jul 24, 2021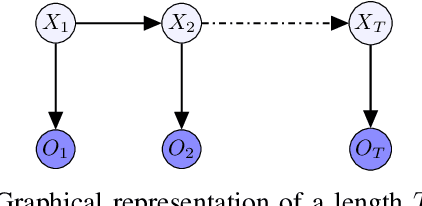
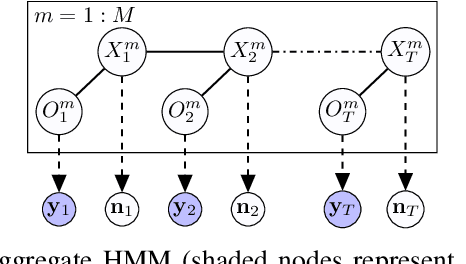
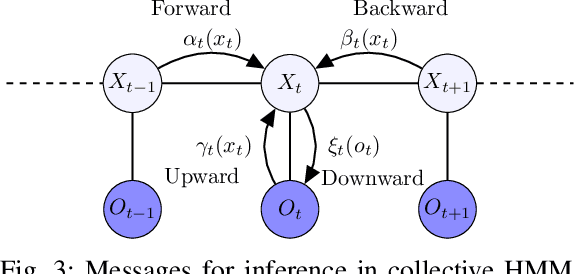
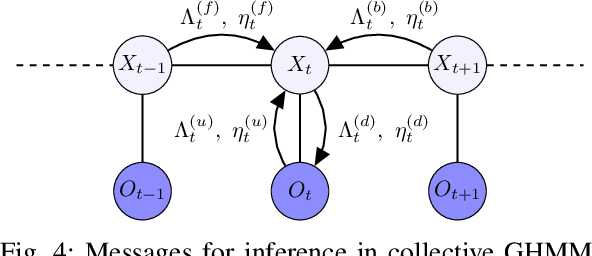
We consider inference problems for a class of continuous state collective hidden Markov models, where the data is recorded in aggregate (collective) form generated by a large population of individuals following the same dynamics. We propose an aggregate inference algorithm called collective Gaussian forward-backward algorithm, extending recently proposed Sinkhorn belief propagation algorithm to models characterized by Gaussian densities. Our algorithm enjoys convergence guarantee. In addition, it reduces to the standard Kalman filter when the observations are generated by a single individual. The efficacy of the proposed algorithm is demonstrated through multiple experiments.
Causal Inference with Corrupted Data: Measurement Error, Missing Values, Discretization, and Differential Privacy
Jul 06, 2021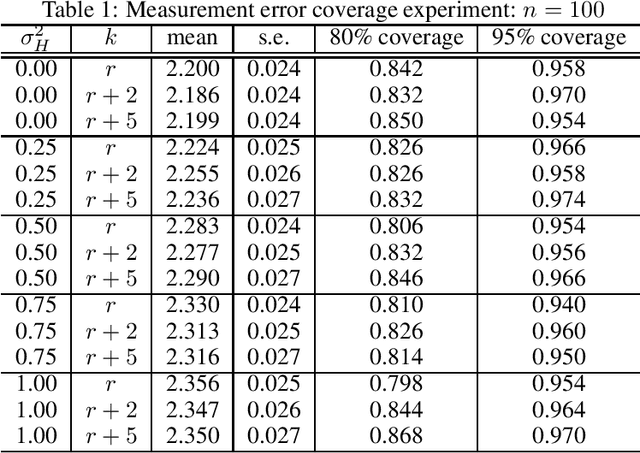
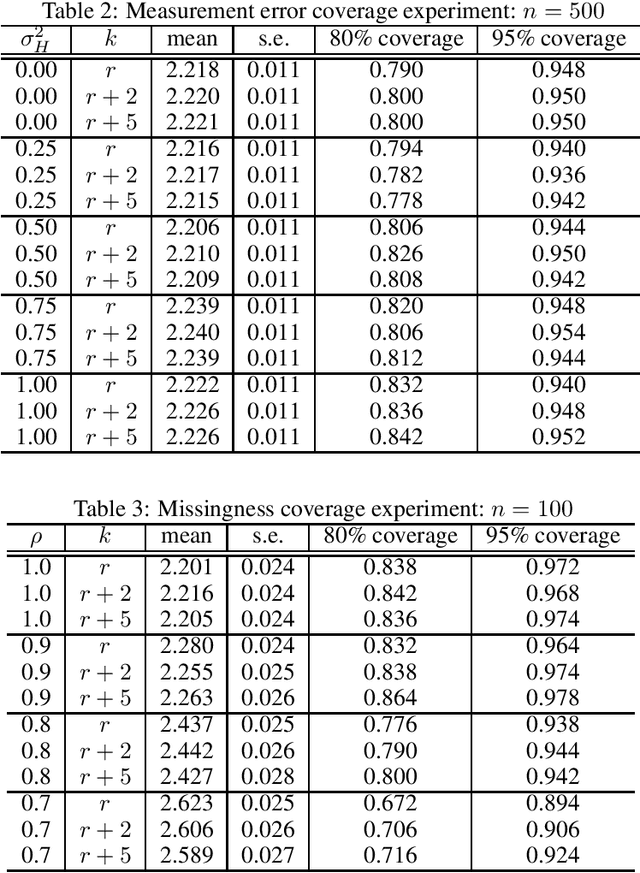
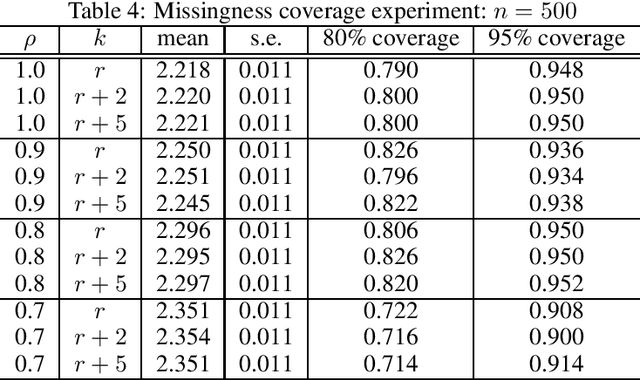
Even the most carefully curated economic data sets have variables that are noisy, missing, discretized, or privatized. The standard workflow for empirical research involves data cleaning followed by data analysis that typically ignores the bias and variance consequences of data cleaning. We formulate a semiparametric model for causal inference with corrupted data to encompass both data cleaning and data analysis. We propose a new end-to-end procedure for data cleaning, estimation, and inference with data cleaning-adjusted confidence intervals. We prove root-n consistency, Gaussian approximation, and semiparametric efficiency for our estimator of the causal parameter by finite sample arguments. Our key assumption is that the true covariates are approximately low rank. In our analysis, we provide nonasymptotic theoretical contributions to matrix completion, statistical learning, and semiparametric statistics. We verify the coverage of the data cleaning-adjusted confidence intervals in simulations.