 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Spline Net and a Unified World
Oct 24, 2024In today's machine learning world for tabular data, XGBoost and fully connected neural network (FCNN) are two most popular methods due to their good model performance and convenience to use. However, they are highly complicated, hard to interpret, and can be overfitted. In this paper, we propose a new modeling framework called cross spline net (CSN) that is based on a combination of spline transformation and cross-network (Wang et al. 2017, 2021). We will show CSN is as performant and convenient to use, and is less complicated, more interpretable and robust. Moreover, the CSN framework is flexible, as the spline layer can be configured differently to yield different models. With different choices of the spline layer, we can reproduce or approximate a set of non-neural network models, including linear and spline-based statistical models, tree, rule-fit, tree-ensembles (gradient boosting trees, random forest), oblique tree/forests, multi-variate adaptive regression spline (MARS), SVM with polynomial kernel, etc. Therefore, CSN provides a unified modeling framework that puts the above set of non-neural network models under the same neural network framework. By using scalable and powerful gradient descent algorithms available in neural network libraries, CSN avoids some pitfalls (such as being ad-hoc, greedy or non-scalable) in the case-specific optimization methods used in the above non-neural network models. We will use a special type of CSN, TreeNet, to illustrate our point. We will compare TreeNet with XGBoost and FCNN to show the benefits of TreeNet. We believe CSN will provide a flexible and convenient framework for practitioners to build performant, robust and more interpretable models.
Assessing Robustness of Machine Learning Models using Covariate Perturbations
Aug 02, 2024



As machine learning models become increasingly prevalent in critical decision-making models and systems in fields like finance, healthcare, etc., ensuring their robustness against adversarial attacks and changes in the input data is paramount, especially in cases where models potentially overfit. This paper proposes a comprehensive framework for assessing the robustness of machine learning models through covariate perturbation techniques. We explore various perturbation strategies to assess robustness and examine their impact on model predictions, including separate strategies for numeric and non-numeric variables, summaries of perturbations to assess and compare model robustness across different scenarios, and local robustness diagnosis to identify any regions in the data where a model is particularly unstable. Through empirical studies on real world dataset, we demonstrate the effectiveness of our approach in comparing robustness across models, identifying the instabilities in the model, and enhancing model robustness.
Monotone Tree-Based GAMI Models by Adapting XGBoost
Sep 05, 2023



Recent papers have used machine learning architecture to fit low-order functional ANOVA models with main effects and second-order interactions. These GAMI (GAM + Interaction) models are directly interpretable as the functional main effects and interactions can be easily plotted and visualized. Unfortunately, it is not easy to incorporate the monotonicity requirement into the existing GAMI models based on boosted trees, such as EBM (Lou et al. 2013) and GAMI-Lin-T (Hu et al. 2022). This paper considers models of the form $f(x)=\sum_{j,k}f_{j,k}(x_j, x_k)$ and develops monotone tree-based GAMI models, called monotone GAMI-Tree, by adapting the XGBoost algorithm. It is straightforward to fit a monotone model to $f(x)$ using the options in XGBoost. However, the fitted model is still a black box. We take a different approach: i) use a filtering technique to determine the important interactions, ii) fit a monotone XGBoost algorithm with the selected interactions, and finally iii) parse and purify the results to get a monotone GAMI model. Simulated datasets are used to demonstrate the behaviors of mono-GAMI-Tree and EBM, both of which use piecewise constant fits. Note that the monotonicity requirement is for the full model. Under certain situations, the main effects will also be monotone. But, as seen in the examples, the interactions will not be monotone.
Document Automation Architectures: Updated Survey in Light of Large Language Models
Aug 18, 2023

This paper surveys the current state of the art in document automation (DA). The objective of DA is to reduce the manual effort during the generation of documents by automatically creating and integrating input from different sources and assembling documents conforming to defined templates. There have been reviews of commercial solutions of DA, particularly in the legal domain, but to date there has been no comprehensive review of the academic research on DA architectures and technologies. The current survey of DA reviews the academic literature and provides a clearer definition and characterization of DA and its features, identifies state-of-the-art DA architectures and technologies in academic research, and provides ideas that can lead to new research opportunities within the DA field in light of recent advances in generative AI and large language models.
Interpretable Machine Learning based on Functional ANOVA Framework: Algorithms and Comparisons
May 25, 2023



In the early days of machine learning (ML), the emphasis was on developing complex algorithms to achieve best predictive performance. To understand and explain the model results, one had to rely on post hoc explainability techniques, which are known to have limitations. Recently, with the recognition that interpretability is just as important, researchers are compromising on small increases in predictive performance to develop algorithms that are inherently interpretable. While doing so, the ML community has rediscovered the use of low-order functional ANOVA (fANOVA) models that have been known in the statistical literature for some time. This paper starts with a description of challenges with post hoc explainability and reviews the fANOVA framework with a focus on main effects and second-order interactions. This is followed by an overview of two recently developed techniques: Explainable Boosting Machines or EBM (Lou et al., 2013) and GAMI-Net (Yang et al., 2021b). The paper proposes a new algorithm, called GAMI-Lin-T, that also uses trees like EBM, but it does linear fits instead of piecewise constants within the partitions. There are many other differences, including the development of a new interaction filtering algorithm. Finally, the paper uses simulated and real datasets to compare selected ML algorithms. The results show that GAMI-Lin-T and GAMI-Net have comparable performances, and both are generally better than EBM.
Behavior of Hyper-Parameters for Selected Machine Learning Algorithms: An Empirical Investigation
Nov 15, 2022



Hyper-parameters (HPs) are an important part of machine learning (ML) model development and can greatly influence performance. This paper studies their behavior for three algorithms: Extreme Gradient Boosting (XGB), Random Forest (RF), and Feedforward Neural Network (FFNN) with structured data. Our empirical investigation examines the qualitative behavior of model performance as the HPs vary, quantifies the importance of each HP for different ML algorithms, and stability of the performance near the optimal region. Based on the findings, we propose a set of guidelines for efficient HP tuning by reducing the search space.
Comparing Baseline Shapley and Integrated Gradients for Local Explanation: Some Additional Insights
Aug 12, 2022
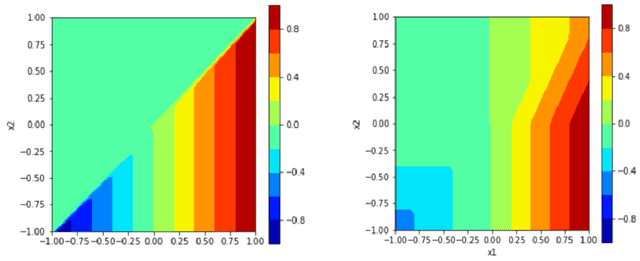

There are many different methods in the literature for local explanation of machine learning results. However, the methods differ in their approaches and often do not provide same explanations. In this paper, we consider two recent methods: Integrated Gradients (Sundararajan, Taly, & Yan, 2017) and Baseline Shapley (Sundararajan and Najmi, 2020). The original authors have already studied the axiomatic properties of the two methods and provided some comparisons. Our work provides some additional insights on their comparative behavior for tabular data. We discuss common situations where the two provide identical explanations and where they differ. We also use simulation studies to examine the differences when neural networks with ReLU activation function is used to fit the models.
Using Model-Based Trees with Boosting to Fit Low-Order Functional ANOVA Models
Jul 14, 2022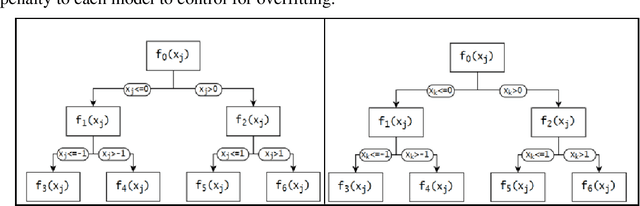


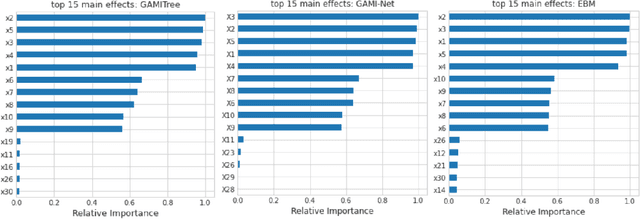
Low-order functional ANOVA (fANOVA) models have been rediscovered in the machine learning (ML) community under the guise of inherently interpretable machine learning. Explainable Boosting Machines or EBM (Lou et al. 2013) and GAMI-Net (Yang et al. 2021) are two recently proposed ML algorithms for fitting functional main effects and second-order interactions. We propose a new algorithm, called GAMI-Tree, that is similar to EBM, but has a number of features that lead to better performance. It uses model-based trees as base learners and incorporates a new interaction filtering method that is better at capturing the underlying interactions. In addition, our iterative training method converges to a model with better predictive performance, and the embedded purification ensures that interactions are hierarchically orthogonal to main effects. The algorithm does not need extensive tuning, and our implementation is fast and efficient. We use simulated and real datasets to compare the performance and interpretability of GAMI-Tree with EBM and GAMI-Net.
Quantifying Inherent Randomness in Machine Learning Algorithms
Jun 24, 2022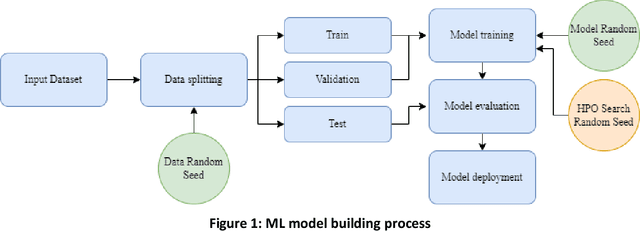
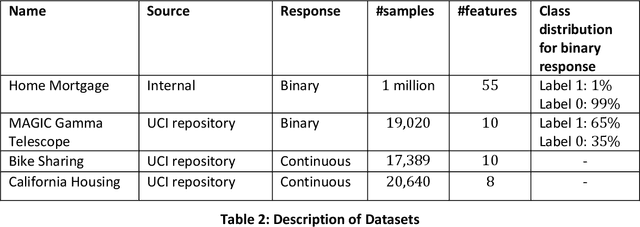
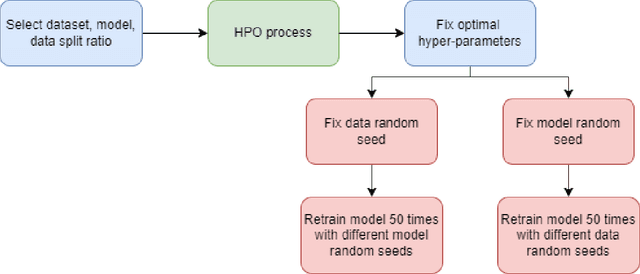
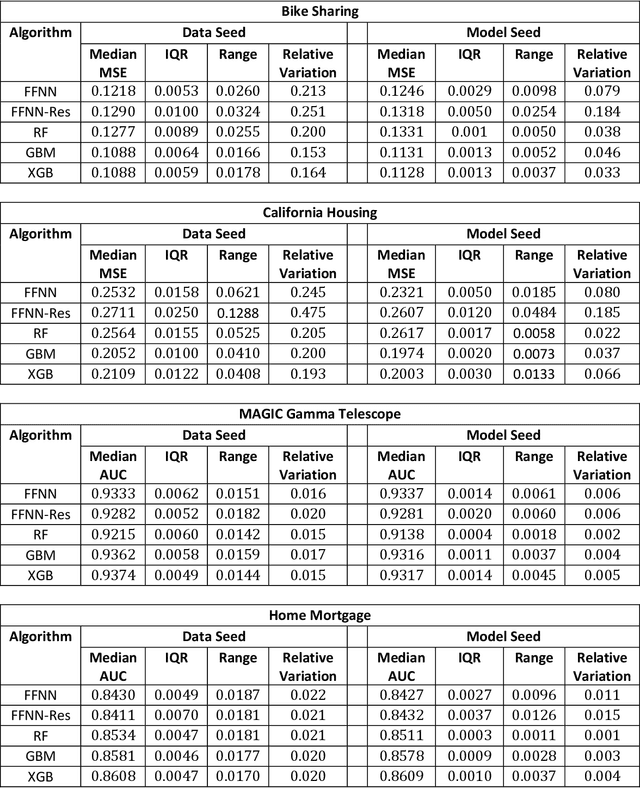
Most machine learning (ML) algorithms have several stochastic elements, and their performances are affected by these sources of randomness. This paper uses an empirical study to systematically examine the effects of two sources: randomness in model training and randomness in the partitioning of a dataset into training and test subsets. We quantify and compare the magnitude of the variation in predictive performance for the following ML algorithms: Random Forests (RFs), Gradient Boosting Machines (GBMs), and Feedforward Neural Networks (FFNNs). Among the different algorithms, randomness in model training causes larger variation for FFNNs compared to tree-based methods. This is to be expected as FFNNs have more stochastic elements that are part of their model initialization and training. We also found that random splitting of datasets leads to higher variation compared to the inherent randomness from model training. The variation from data splitting can be a major issue if the original dataset has considerable heterogeneity. Keywords: Model Training, Reproducibility, Variation
Interpretable Feature Engineering for Time Series Predictors using Attention Networks
May 23, 2022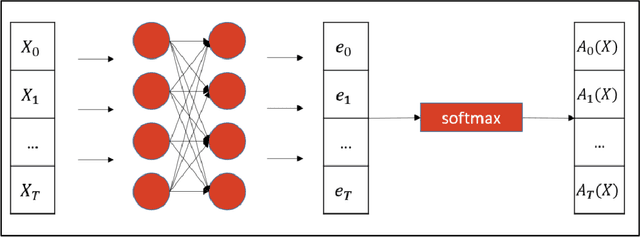

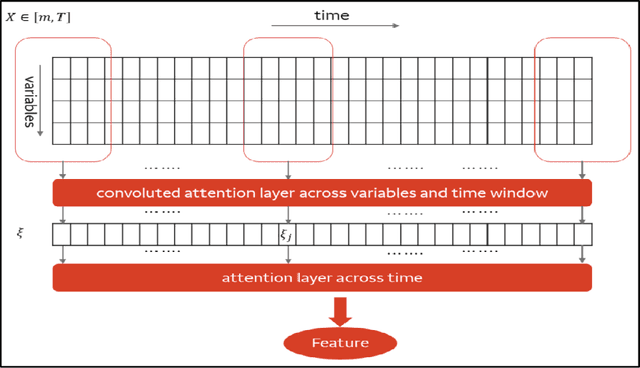

Regression problems with time-series predictors are common in banking and many other areas of application. In this paper, we use multi-head attention networks to develop interpretable features and use them to achieve good predictive performance. The customized attention layer explicitly uses multiplicative interactions and builds feature-engineering heads that capture temporal dynamics in a parsimonious manner. Convolutional layers are used to combine multivariate time series. We also discuss methods for handling static covariates in the modeling process. Visualization and explanation tools are used to interpret the results and explain the relationship between the inputs and the extracted features. Both simulation and real dataset are used to illustrate the usefulness of the methodology. Keyword: Attention heads, Deep neural networks, Interpretable feature engineering