 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoNLI: A Natural Language Inference Dataset for Indonesian
Oct 27, 2021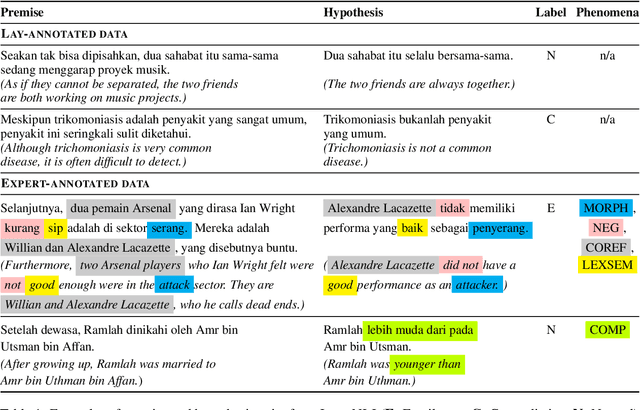
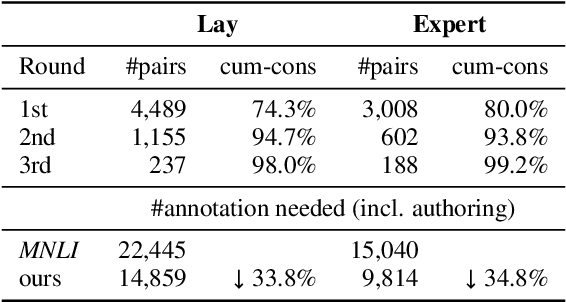
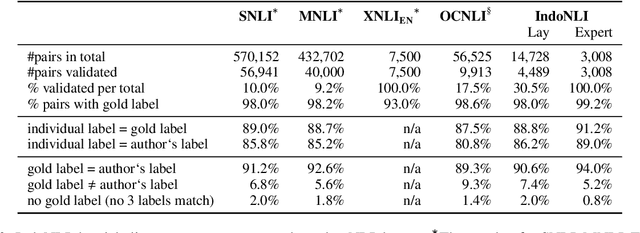
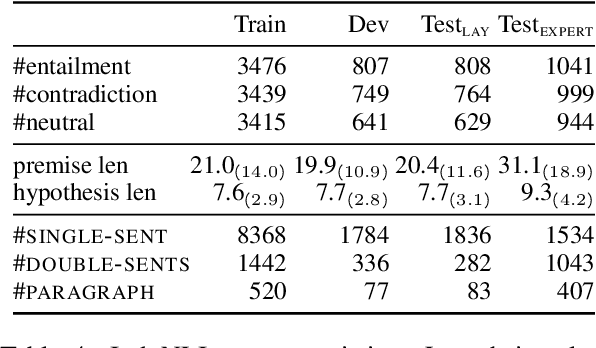
We present IndoNLI, the first human-elicited NLI dataset for Indonesian. We adapt the data collection protocol for MNLI and collect nearly 18K sentence pairs annotated by crowd workers and experts. The expert-annotated data is used exclusively as a test set. It is designed to provide a challenging test-bed for Indonesian NLI by explicitly incorporating various linguistic phenomena such as numerical reasoning, structural changes, idioms, or temporal and spatial reasoning. Experiment results show that XLM-R outperforms other pre-trained models in our data. The best performance on the expert-annotated data is still far below human performance (13.4% accuracy gap), suggesting that this test set is especially challenging. Furthermore, our analysis shows that our expert-annotated data is more diverse and contains fewer annotation artifacts than the crowd-annotated data. We hope this dataset can help accelerate progress in Indonesian NLP research.
Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation
Nov 06, 2020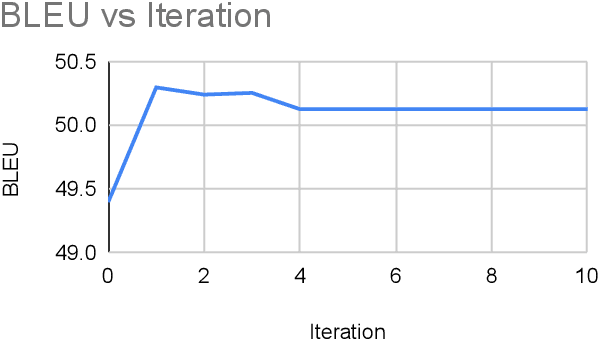
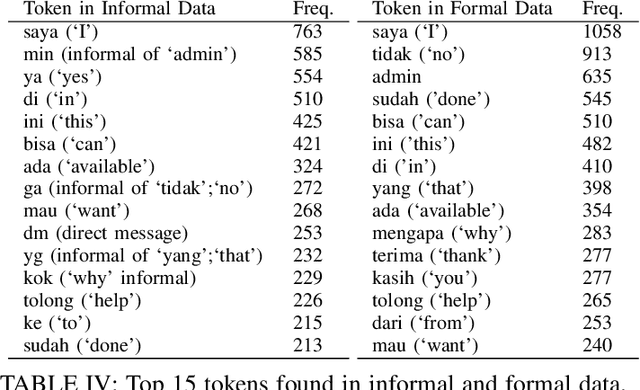

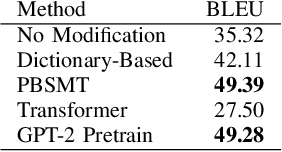
In its daily use, the Indonesian language is riddled with informality, that is, deviations from the standard in terms of vocabulary, spelling, and word order. On the other hand, current available Indonesian NLP models are typically developed with the standard Indonesian in mind. In this work, we address a style-transfer from informal to formal Indonesian as a low-resource machine translation problem. We build a new dataset of parallel sentences of informal Indonesian and its formal counterpart. We benchmark several strategies to perform style transfer from informal to formal Indonesian. We also explore augmenting the training set with artificial forward-translated data. Since we are dealing with an extremely low-resource setting, we find that a phrase-based machine translation approach outperforms the Transformer-based approach. Alternatively, a pre-trained GPT-2 fined-tuned to this task performed equally well but costs more computational resource. Our findings show a promising step towards leveraging machine translation models for style transfer. Our code and data are available in https://github.com/haryoa/stif-indonesia
IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding
Oct 08, 2020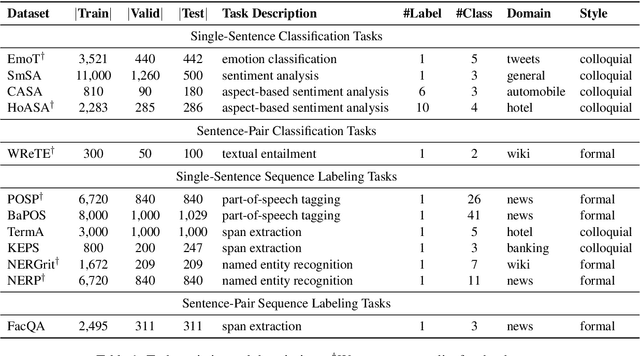
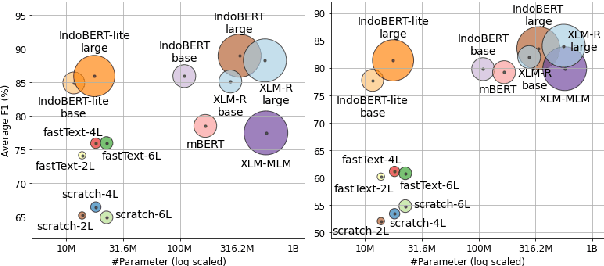
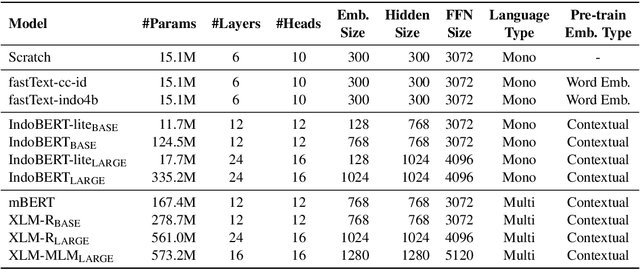
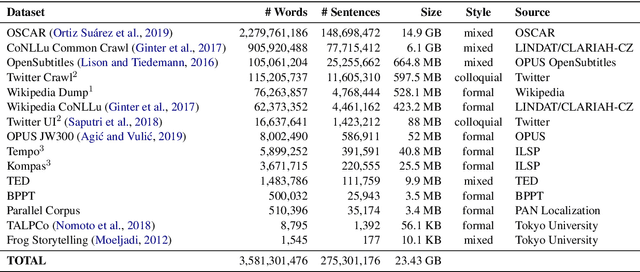
Although Indonesian is known to be the fourth most frequently used language over the internet, the research progress on this language in the natural language processing (NLP) is slow-moving due to a lack of available resources. In response, we introduce the first-ever vast resource for the training, evaluating, and benchmarking on Indonesian natural language understanding (IndoNLU) tasks. IndoNLU includes twelve tasks, ranging from single sentence classification to pair-sentences sequence labeling with different levels of complexity. The datasets for the tasks lie in different domains and styles to ensure task diversity. We also provide a set of Indonesian pre-trained models (IndoBERT) trained from a large and clean Indonesian dataset Indo4B collected from publicly available sources such as social media texts, blogs, news, and websites. We release baseline models for all twelve tasks, as well as the framework for benchmark evaluation, and thus it enables everyone to benchmark their system performances.
Multi-Task Active Learning for Neural Semantic Role Labeling on Low Resource Conversational Corpus
Jun 05, 2018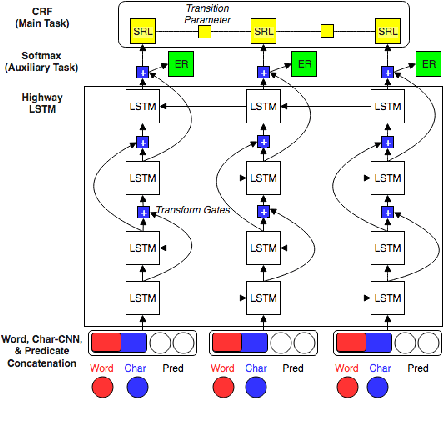
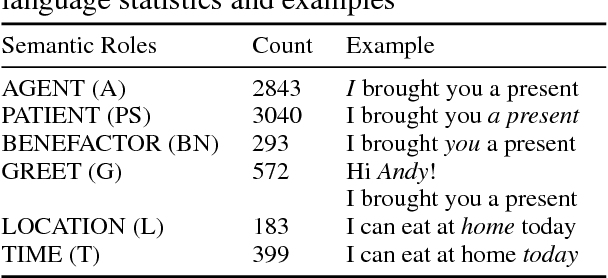
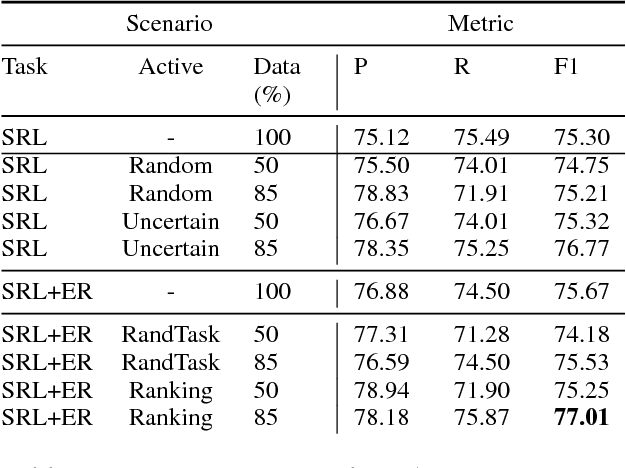
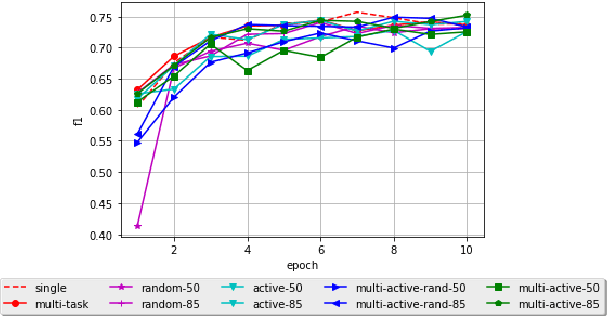
Most Semantic Role Labeling (SRL) approaches are supervised methods which require a significant amount of annotated corpus, and the annotation requires linguistic expertise. In this paper, we propose a Multi-Task Active Learning framework for Semantic Role Labeling with Entity Recognition (ER) as the auxiliary task to alleviate the need for extensive data and use additional information from ER to help SRL. We evaluate our approach on Indonesian conversational dataset. Our experiments show that multi-task active learning can outperform single-task active learning method and standard multi-task learning. According to our results, active learning is more efficient by using 12% less of training data compared to passive learning in both single-task and multi-task setting. We also introduce a new dataset for SRL in Indonesian conversational domain to encourage further research in this area.