 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Data Selection and Augmentation for Automatic Compliance Detection
Apr 23, 2026Automating the detection of regulatory compliance remains a challenging task due to the complexity and variability of legal texts. Models trained on one regulation often fail to generalise to others. This limitation underscores the need for principled methods to improve cross-domain transfer. We study data selection as a strategy to mitigate negative transfer in compliance detection framed as a natural language inference (NLI) task. Specifically, we evaluate four approaches for selecting augmentation data from a larger source domain: random sampling, Moore-Lewis's cross-entropy difference, importance weighting, and embedding-based retrieval. We systematically vary the proportion of selected data to analyse its effect on cross-domain adaptation. Our findings demonstrate that targeted data selection substantially reduces negative transfer, offering a practical path toward scalable and reliable compliance automation across heterogeneous regulations.
Evaluating Assurance Cases as Text-Attributed Graphs for Structure and Provenance Analysis
Apr 22, 2026An assurance case is a structured argument document that justifies claims about a system's requirements or properties, which are supported by evidence. In regulated domains, these are crucial for meeting compliance and safety requirements to industry standards. We propose a graph diagnostic framework for analysing the structure and provenance of assurance cases. We focus on two main tasks: (1) link prediction, to learn and identify connections between argument elements, and (2) graph classification, to differentiate between assurance cases created by a state-of-the-art large language model and those created by humans, aiming to detect bias. We compiled a publicly available dataset of assurance cases, represented as graphs with nodes and edges, supporting both link prediction and provenance analysis. Experiments show that graph neural networks (GNNs) achieve strong link prediction performance (ROC-AUC 0.760) on real assurance cases and generalise well across domains and semi-supervised settings. For provenance detection, GNNs effectively distinguish human-authored from LLM-generated cases (F1 0.94). We observed that LLM-generated assurance cases have different hierarchical linking patterns compared to human-authored cases. Furthermore, existing GNN explanation methods show only moderate faithfulness, revealing a gap between predicted reasoning and the true argument structure.
Explainable Compliance Detection with Multi-Hop Natural Language Inference on Assurance Case Structure
Jun 10, 2025Ensuring complex systems meet regulations typically requires checking the validity of assurance cases through a claim-argument-evidence framework. Some challenges in this process include the complicated nature of legal and technical texts, the need for model explanations, and limited access to assurance case data. We propose a compliance detection approach based on Natural Language Inference (NLI): EXplainable CompLiance detection with Argumentative Inference of Multi-hop reasoning (EXCLAIM). We formulate the claim-argument-evidence structure of an assurance case as a multi-hop inference for explainable and traceable compliance detection. We address the limited number of assurance cases by generating them using large language models (LLMs). We introduce metrics that measure the coverage and structural consistency. We demonstrate the effectiveness of the generated assurance case from GDPR requirements in a multi-hop inference task as a case study. Our results highlight the potential of NLI-based approaches in automating the regulatory compliance process.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Cross-Lingual Transfer for Distantly Supervised and Low-resources Indonesian NER
Jul 25, 2019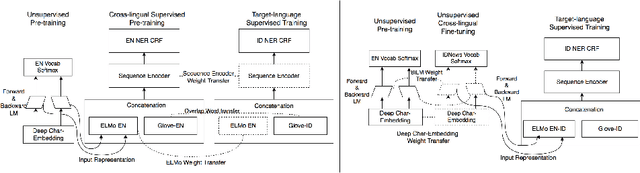
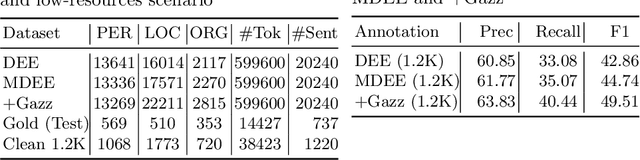
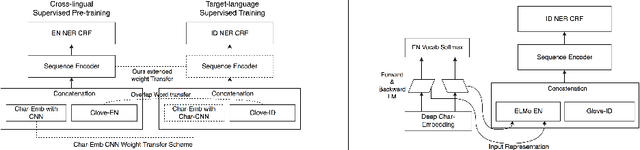
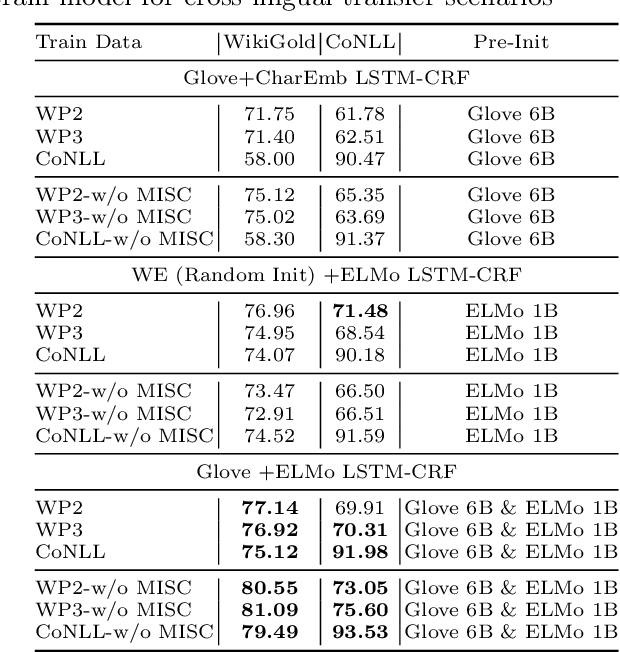
Manually annotated corpora for low-resource languages are usually small in quantity (gold), or large but distantly supervised (silver). Inspired by recent progress of injecting pre-trained language model (LM) on many Natural Language Processing (NLP) task, we proposed to fine-tune pre-trained language model from high-resources languages to low-resources languages to improve the performance of both scenarios. Our empirical experiment demonstrates significant improvement when fine-tuning pre-trained language model in cross-lingual transfer scenarios for small gold corpus and competitive results in large silver compare to supervised cross-lingual transfer, which will be useful when there is no parallel annotation in the same task to begin. We compare our proposed method of cross-lingual transfer using pre-trained LM to different sources of transfer such as mono-lingual LM and Part-of-Speech tagging (POS) in the downstream task of both large silver and small gold NER dataset by exploiting character-level input of bi-directional language model task.
Pretrained language model transfer on neural named entity recognition in Indonesian conversational texts
Feb 21, 2019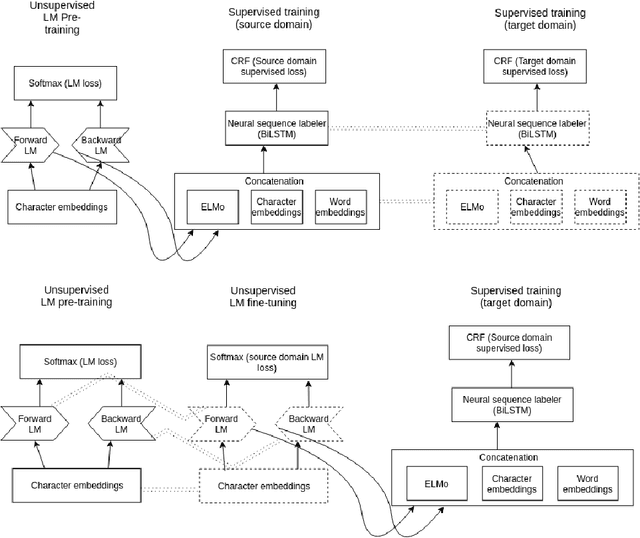
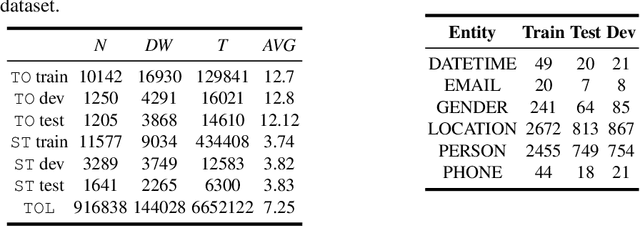

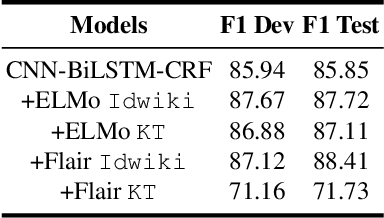
Named entity recognition (NER) is an important task in NLP, which is all the more challenging in conversational domain with their noisy facets. Moreover, conversational texts are often available in limited amount, making supervised tasks infeasible. To learn from small data, strong inductive biases are required. Previous work relied on hand-crafted features to encode these biases until transfer learning emerges. Here, we explore a transfer learning method, namely language model pretraining, on NER task in Indonesian conversational texts. We utilize large unlabeled data (generic domain) to be transferred to conversational texts, enabling supervised training on limited in-domain data. We report two transfer learning variants, namely supervised model fine-tuning and unsupervised pretrained LM fine-tuning. Our experiments show that both variants outperform baseline neural models when trained on small data (100 sentences), yielding an absolute improvement of 32 points of test F1 score. Furthermore, we find that the pretrained LM encodes part-of-speech information which is a strong predictor for NER.
Multi-Task Active Learning for Neural Semantic Role Labeling on Low Resource Conversational Corpus
Jun 05, 2018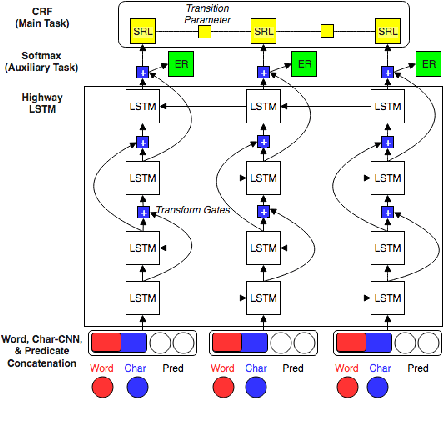
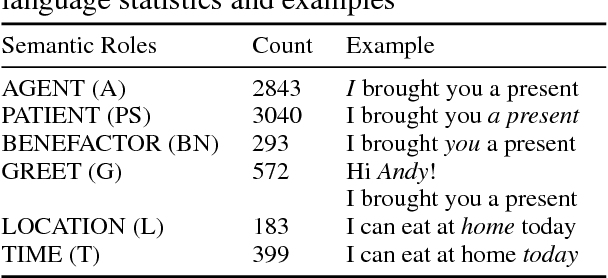
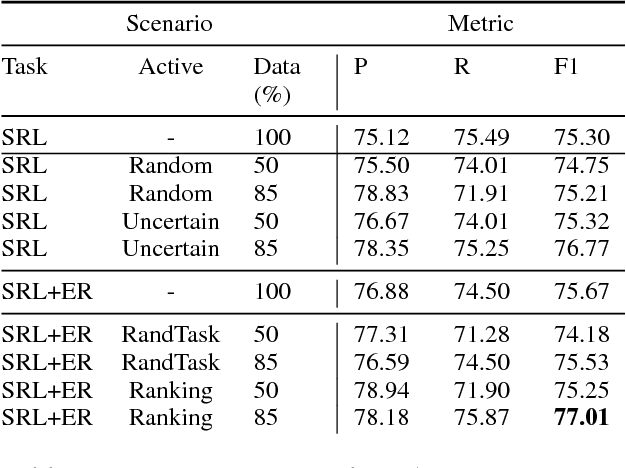
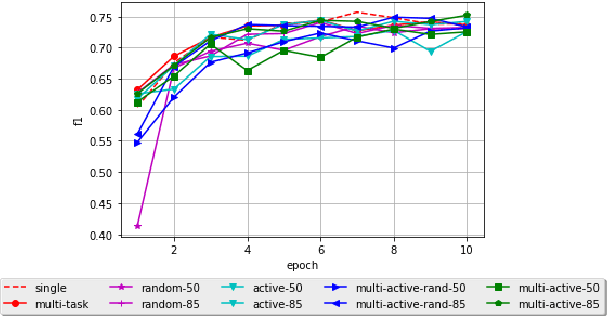
Most Semantic Role Labeling (SRL) approaches are supervised methods which require a significant amount of annotated corpus, and the annotation requires linguistic expertise. In this paper, we propose a Multi-Task Active Learning framework for Semantic Role Labeling with Entity Recognition (ER) as the auxiliary task to alleviate the need for extensive data and use additional information from ER to help SRL. We evaluate our approach on Indonesian conversational dataset. Our experiments show that multi-task active learning can outperform single-task active learning method and standard multi-task learning. According to our results, active learning is more efficient by using 12% less of training data compared to passive learning in both single-task and multi-task setting. We also introduce a new dataset for SRL in Indonesian conversational domain to encourage further research in this area.