 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema-Guided Dialogue State Tracking Task at DSTC8
Feb 02, 2020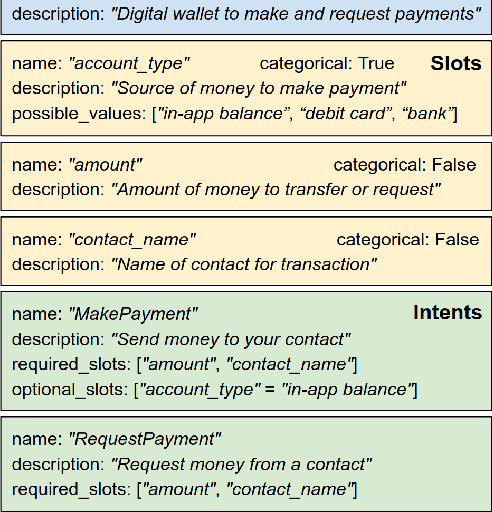

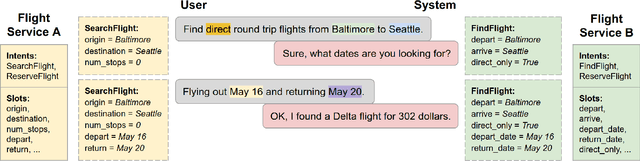
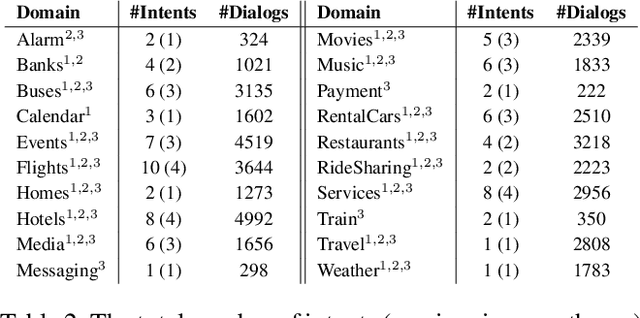
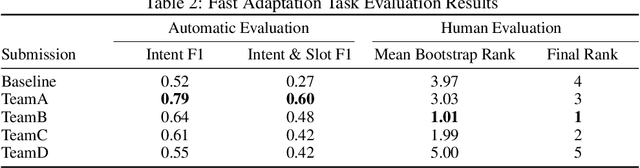
This paper gives an overview of the Schema-Guided Dialogue State Tracking task of the 8th Dialogue System Technology Challenge. The goal of this task is to develop dialogue state tracking models suitable for large-scale virtual assistants, with a focus on data-efficient joint modeling across domains and zero-shot generalization to new APIs. This task provided a new dataset consisting of over 16000 dialogues in the training set spanning 16 domains to highlight these challenges, and a baseline model capable of zero-shot generalization to new APIs. Twenty-five teams participated, developing a range of neural network models, exceeding the performance of the baseline model by a very high margin. The submissions incorporated a variety of pre-trained encoders and data augmentation techniques. This paper describes the task definition, dataset and evaluation methodology. We also summarize the approach and results of the submitted systems to highlight the overall trends in the state-of-the-art.
The Eighth Dialog System Technology Challenge
Nov 14, 2019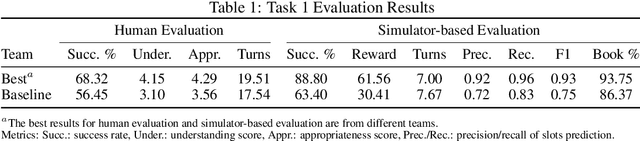
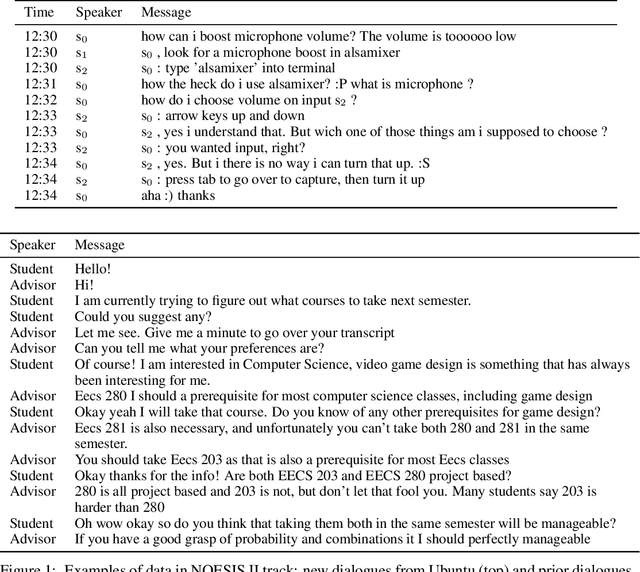
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Extreme Language Model Compression with Optimal Subwords and Shared Projections
Sep 25, 2019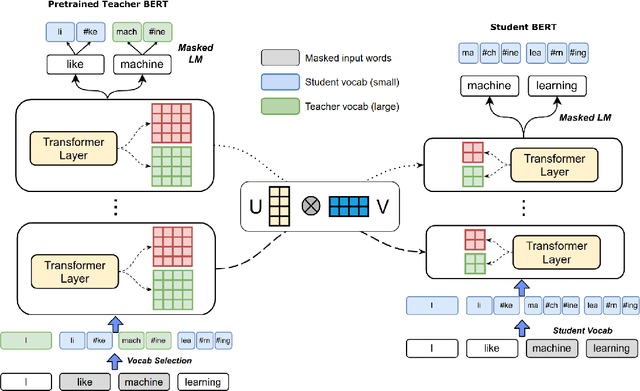


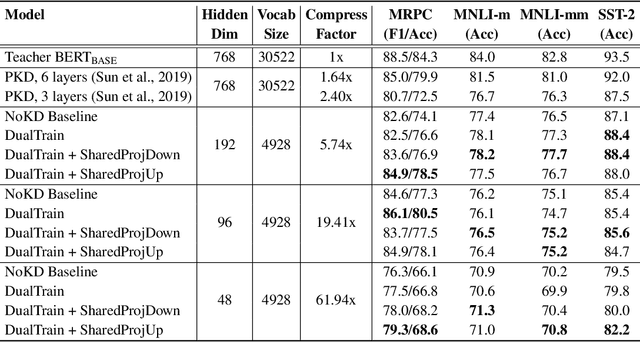
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset
Sep 12, 2019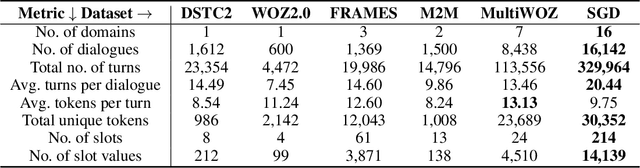
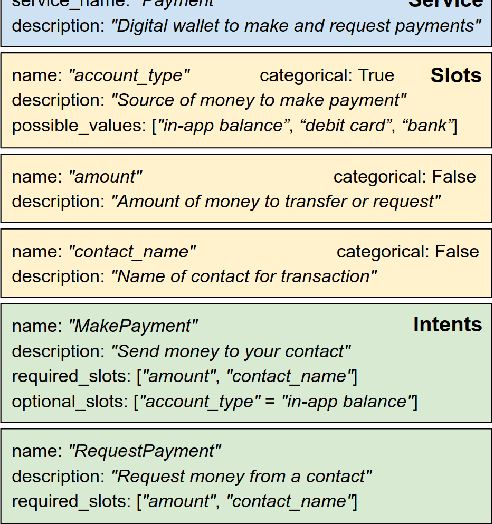
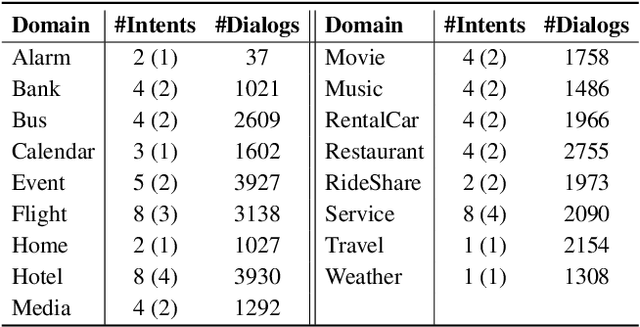
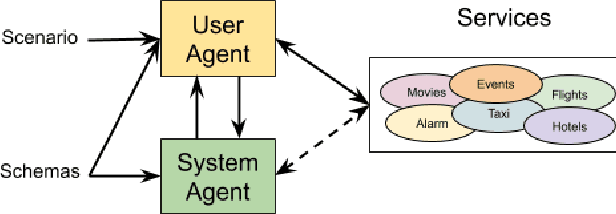
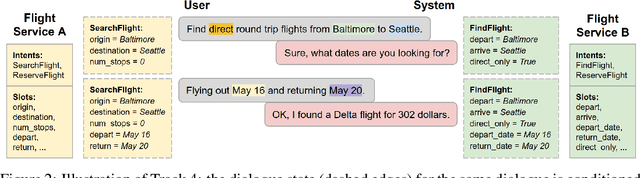
Virtual assistants such as Google Assistant, Alexa and Siri provide a conversational interface to a large number of services and APIs spanning multiple domains. Such systems need to support an ever-increasing number of services with possibly overlapping functionality. Furthermore, some of these services have little to no training data available. Existing public datasets for task-oriented dialogue do not sufficiently capture these challenges since they cover few domains and assume a single static ontology per domain. In this work, we introduce the the Schema-Guided Dialogue (SGD) dataset, containing over 16k multi-domain conversations spanning 16 domains. Our dataset exceeds the existing task-oriented dialogue corpora in scale, while also highlighting the challenges associated with building large-scale virtual assistants. It provides a challenging testbed for a number of tasks including language understanding, slot filling, dialogue state tracking and response generation. Along the same lines, we present a schema-guided paradigm for task-oriented dialogue, in which predictions are made over a dynamic set of intents and slots, provided as input, using their natural language descriptions. This allows a single dialogue system to easily support a large number of services and facilitates simple integration of new services without requiring additional training data. Building upon the proposed paradigm, we release a zero-shot dialogue state tracking model that achieves state-of-the-art performance on recent benchmark datasets.
Robust Zero-Shot Cross-Domain Slot Filling with Example Values
Jun 17, 2019
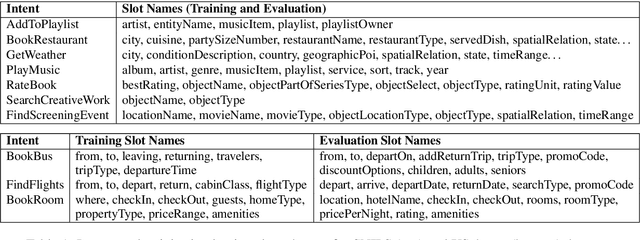
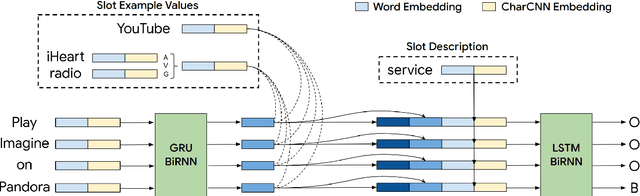
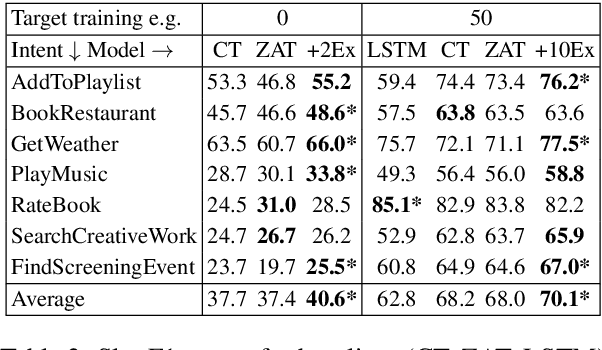
Task-oriented dialog systems increasingly rely on deep learning-based slot filling models, usually needing extensive labeled training data for target domains. Often, however, little to no target domain training data may be available, or the training and target domain schemas may be misaligned, as is common for web forms on similar websites. Prior zero-shot slot filling models use slot descriptions to learn concepts, but are not robust to misaligned schemas. We propose utilizing both the slot description and a small number of examples of slot values, which may be easily available, to learn semantic representations of slots which are transferable across domains and robust to misaligned schemas. Our approach outperforms state-of-the-art models on two multi-domain datasets, especially in the low-data setting.
Multi-task learning for Joint Language Understanding and Dialogue State Tracking
Nov 13, 2018
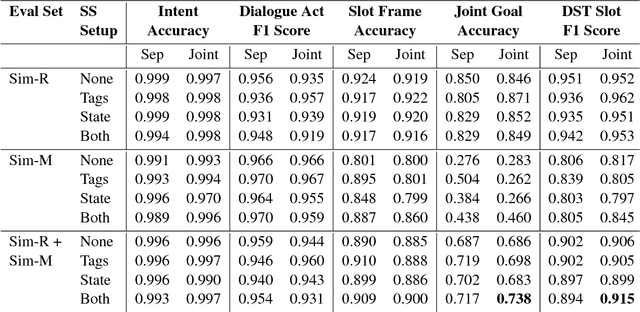
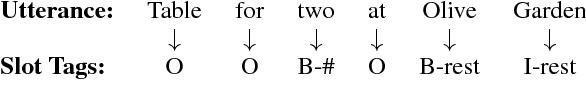

This paper presents a novel approach for multi-task learning of language understanding (LU) and dialogue state tracking (DST) in task-oriented dialogue systems. Multi-task training enables the sharing of the neural network layers responsible for encoding the user utterance for both LU and DST and improves performance while reducing the number of network parameters. In our proposed framework, DST operates on a set of candidate values for each slot that has been mentioned so far. These candidate sets are generated using LU slot annotations for the current user utterance, dialogue acts corresponding to the preceding system utterance and the dialogue state estimated for the previous turn, enabling DST to handle slots with a large or unbounded set of possible values and deal with slot values not seen during training. Furthermore, to bridge the gap between training and inference, we investigate the use of scheduled sampling on LU output for the current user utterance as well as the DST output for the preceding turn.
* Published at SIGdial 2018; 9 pages
An Efficient Approach to Encoding Context for Spoken Language Understanding
Jul 01, 2018
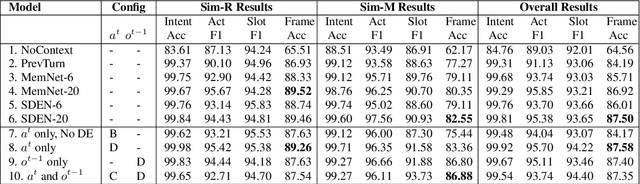
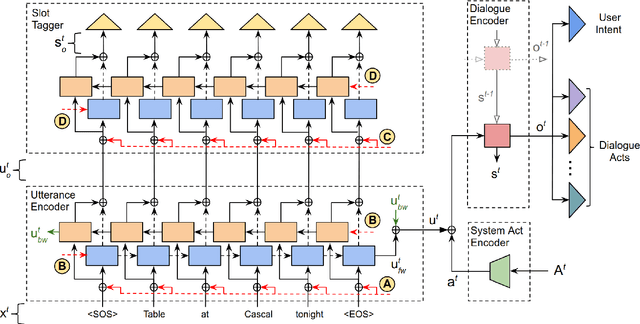
In task-oriented dialogue systems, spoken language understanding, or SLU, refers to the task of parsing natural language user utterances into semantic frames. Making use of context from prior dialogue history holds the key to more effective SLU. State of the art approaches to SLU use memory networks to encode context by processing multiple utterances from the dialogue at each turn, resulting in significant trade-offs between accuracy and computational efficiency. On the other hand, downstream components like the dialogue state tracker (DST) already keep track of the dialogue state, which can serve as a summary of the dialogue history. In this work, we propose an efficient approach to encoding context from prior utterances for SLU. More specifically, our architecture includes a separate recurrent neural network (RNN) based encoding module that accumulates dialogue context to guide the frame parsing sub-tasks and can be shared between SLU and DST. In our experiments, we demonstrate the effectiveness of our approach on dialogues from two domains.
A Fast Unified Model for Parsing and Sentence Understanding
Jul 29, 2016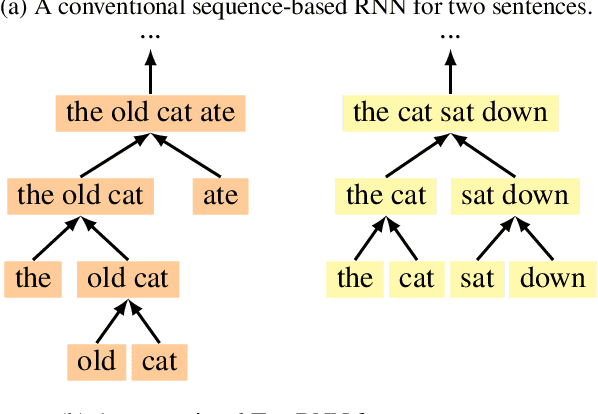
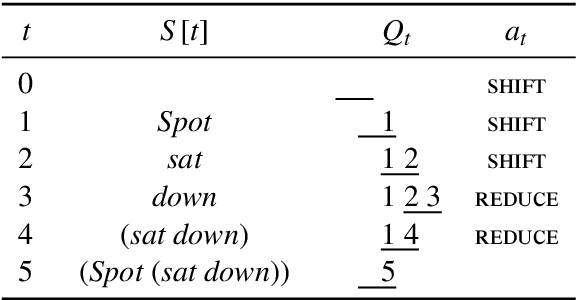


Tree-structured neural networks exploit valuable syntactic parse information as they interpret the meanings of sentences. However, they suffer from two key technical problems that make them slow and unwieldy for large-scale NLP tasks: they usually operate on parsed sentences and they do not directly support batched computation. We address these issues by introducing the Stack-augmented Parser-Interpreter Neural Network (SPINN), which combines parsing and interpretation within a single tree-sequence hybrid model by integrating tree-structured sentence interpretation into the linear sequential structure of a shift-reduce parser. Our model supports batched computation for a speedup of up to 25 times over other tree-structured models, and its integrated parser can operate on unparsed data with little loss in accuracy. We evaluate it on the Stanford NLI entailment task and show that it significantly outperforms other sentence-encoding models.
Qualitative Analysis of POMDPs with Temporal Logic Specifications for Robotics Applications
Feb 18, 2015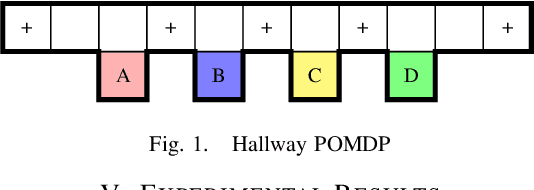
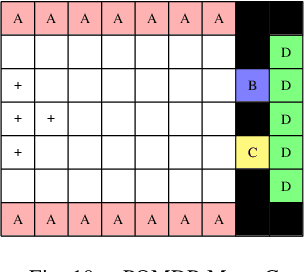
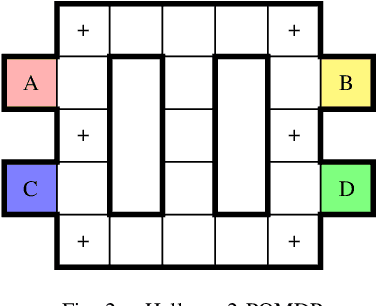
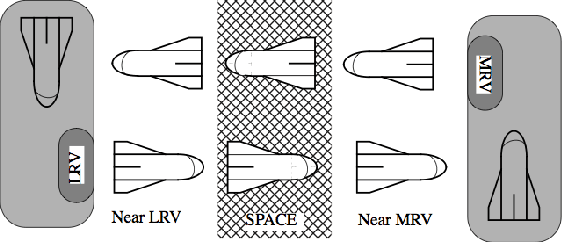
We consider partially observable Markov decision processes (POMDPs), that are a standard framework for robotics applications to model uncertainties present in the real world, with temporal logic specifications. All temporal logic specifications in linear-time temporal logic (LTL) can be expressed as parity objectives. We study the qualitative analysis problem for POMDPs with parity objectives that asks whether there is a controller (policy) to ensure that the objective holds with probability 1 (almost-surely). While the qualitative analysis of POMDPs with parity objectives is undecidable, recent results show that when restricted to finite-memory policies the problem is EXPTIME-complete. While the problem is intractable in theory, we present a practical approach to solve the qualitative analysis problem. We designed several heuristics to deal with the exponential complexity, and have used our implementation on a number of well-known POMDP examples for robotics applications. Our results provide the first practical approach to solve the qualitative analysis of robot motion planning with LTL properties in the presence of uncertainty.
Optimal Cost Almost-sure Reachability in POMDPs
Nov 14, 2014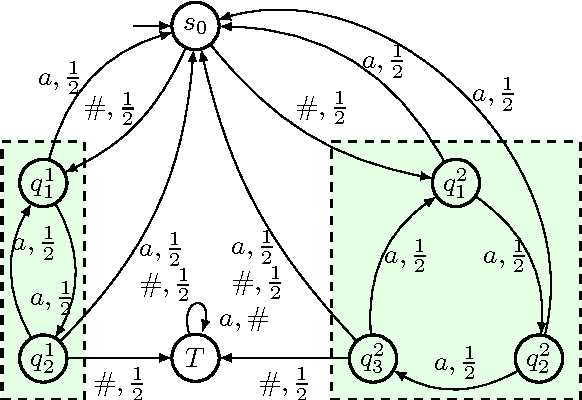
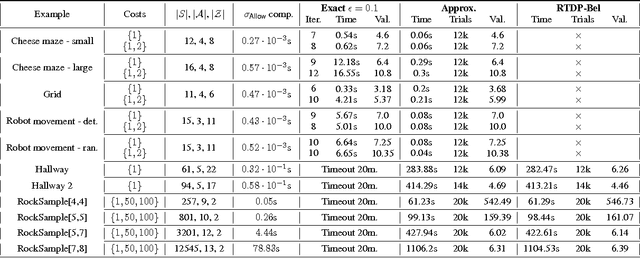
We consider partially observable Markov decision processes (POMDPs) with a set of target states and every transition is associated with an integer cost. The optimization objective we study asks to minimize the expected total cost till the target set is reached, while ensuring that the target set is reached almost-surely (with probability 1). We show that for integer costs approximating the optimal cost is undecidable. For positive costs, our results are as follows: (i) we establish matching lower and upper bounds for the optimal cost and the bound is double exponential; (ii) we show that the problem of approximating the optimal cost is decidable and present approximation algorithms developing on the existing algorithms for POMDPs with finite-horizon objectives. While the worst-case running time of our algorithm is double exponential, we also present efficient stopping criteria for the algorithm and show experimentally that it performs well in many examples of interest.