 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Encoder Models for Polish Language Understanding
Mar 12, 2026While decoder-only Large Language Models (LLMs) have recently dominated the NLP landscape, encoder-only architectures remain a cost-effective and parameter-efficient standard for discriminative tasks. However, classic encoders like BERT are limited by a short context window, which is insufficient for processing long documents. In this paper, we address this limitation for the Polish by introducing a high-quality Polish model capable of processing sequences of up to 8192 tokens. The model was developed by employing a two-stage training procedure that involves positional embedding adaptation and full parameter continuous pre-training. Furthermore, we propose compressed model variants trained via knowledge distillation. The models were evaluated on 25 tasks, including the KLEJ benchmark, a newly introduced financial task suite (FinBench), and other classification and regression tasks, specifically those requiring long-document understanding. The results demonstrate that our model achieves the best average performance among Polish and multilingual models, significantly outperforming competitive solutions in long-context tasks while maintaining comparable quality on short texts.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025



Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Unveiling Dual Quality in Product Reviews: An NLP-Based Approach
May 25, 2025Consumers often face inconsistent product quality, particularly when identical products vary between markets, a situation known as the dual quality problem. To identify and address this issue, automated techniques are needed. This paper explores how natural language processing (NLP) can aid in detecting such discrepancies and presents the full process of developing a solution. First, we describe in detail the creation of a new Polish-language dataset with 1,957 reviews, 540 highlighting dual quality issues. We then discuss experiments with various approaches like SetFit with sentence-transformers, transformer-based encoders, and LLMs, including error analysis and robustness verification. Additionally, we evaluate multilingual transfer using a subset of opinions in English, French, and German. The paper concludes with insights on deployment and practical applications.
Evaluating Polish linguistic and cultural competency in large language models
Mar 02, 2025


Large language models (LLMs) are becoming increasingly proficient in processing and generating multilingual texts, which allows them to address real-world problems more effectively. However, language understanding is a far more complex issue that goes beyond simple text analysis. It requires familiarity with cultural context, including references to everyday life, historical events, traditions, folklore, literature, and pop culture. A lack of such knowledge can lead to misinterpretations and subtle, hard-to-detect errors. To examine language models' knowledge of the Polish cultural context, we introduce the Polish linguistic and cultural competency benchmark, consisting of 600 manually crafted questions. The benchmark is divided into six categories: history, geography, culture & tradition, art & entertainment, grammar, and vocabulary. As part of our study, we conduct an extensive evaluation involving over 30 open-weight and commercial LLMs. Our experiments provide a new perspective on Polish competencies in language models, moving past traditional natural language processing tasks and general knowledge assessment.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Review of the Challenges with Massive Web-mined Corpora Used in Large Language Models Pre-Training
Jul 10, 2024This article presents a comprehensive review of the challenges associated with using massive web-mined corpora for the pre-training of large language models (LLMs). This review identifies key challenges in this domain, including challenges such as noise (irrelevant or misleading information), duplication of content, the presence of low-quality or incorrect information, biases, and the inclusion of sensitive or personal information in web-mined corpora. Addressing these issues is crucial for the development of accurate, reliable, and ethically responsible language models. Through an examination of current methodologies for data cleaning, pre-processing, bias detection and mitigation, we highlight the gaps in existing approaches and suggest directions for future research. Our discussion aims to catalyze advancements in developing more sophisticated and ethically responsible LLMs.
PL-MTEB: Polish Massive Text Embedding Benchmark
May 16, 2024In this paper, we introduce the Polish Massive Text Embedding Benchmark (PL-MTEB), a comprehensive benchmark for text embeddings in Polish. The PL-MTEB consists of 28 diverse NLP tasks from 5 task types. We adapted the tasks based on previously used datasets by the Polish NLP community. In addition, we created a new PLSC (Polish Library of Science Corpus) dataset consisting of titles and abstracts of scientific publications in Polish, which was used as the basis for two novel clustering tasks. We evaluated 15 publicly available models for text embedding, including Polish and multilingual ones, and collected detailed results for individual tasks and aggregated results for each task type and the entire benchmark. PL-MTEB comes with open-source code at https://github.com/rafalposwiata/pl-mteb.
PIRB: A Comprehensive Benchmark of Polish Dense and Hybrid Text Retrieval Methods
Feb 20, 2024We present Polish Information Retrieval Benchmark (PIRB), a comprehensive evaluation framework encompassing 41 text information retrieval tasks for Polish. The benchmark incorporates existing datasets as well as 10 new, previously unpublished datasets covering diverse topics such as medicine, law, business, physics, and linguistics. We conduct an extensive evaluation of over 20 dense and sparse retrieval models, including the baseline models trained by us as well as other available Polish and multilingual methods. Finally, we introduce a three-step process for training highly effective language-specific retrievers, consisting of knowledge distillation, supervised fine-tuning, and building sparse-dense hybrid retrievers using a lightweight rescoring model. In order to validate our approach, we train new text encoders for Polish and compare their results with previously evaluated methods. Our dense models outperform the best solutions available to date, and the use of hybrid methods further improves their performance.
Pre-training Polish Transformer-based Language Models at Scale
Jun 09, 2020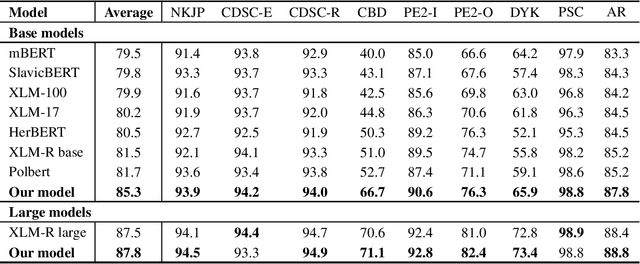
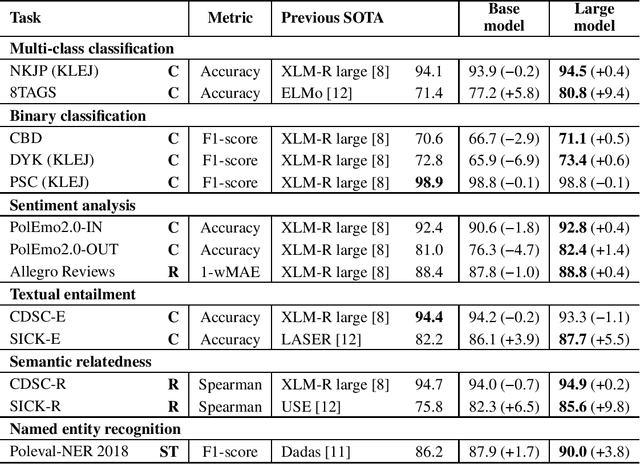
Transformer-based language models are now widely used in Natural Language Processing (NLP). This statement is especially true for English language, in which many pre-trained models utilizing transformer-based architecture have been published in recent years. This has driven forward the state of the art for a variety of standard NLP tasks such as classification, regression, and sequence labeling, as well as text-to-text tasks, such as machine translation, question answering, or summarization. The situation have been different for low-resource languages, such as Polish, however. Although some transformer-based language models for Polish are available, none of them have come close to the scale, in terms of corpus size and the number of parameters, of the largest English-language models. In this study, we present two language models for Polish based on the popular BERT architecture. The larger model was trained on a dataset consisting of over 1 billion polish sentences, or 135GB of raw text. We describe our methodology for collecting the data, preparing the corpus, and pre-training the model. We then evaluate our models on thirteen Polish linguistic tasks, and demonstrate improvements over previous approaches in eleven of them.