 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Encoder Models for Polish Language Understanding
Mar 12, 2026While decoder-only Large Language Models (LLMs) have recently dominated the NLP landscape, encoder-only architectures remain a cost-effective and parameter-efficient standard for discriminative tasks. However, classic encoders like BERT are limited by a short context window, which is insufficient for processing long documents. In this paper, we address this limitation for the Polish by introducing a high-quality Polish model capable of processing sequences of up to 8192 tokens. The model was developed by employing a two-stage training procedure that involves positional embedding adaptation and full parameter continuous pre-training. Furthermore, we propose compressed model variants trained via knowledge distillation. The models were evaluated on 25 tasks, including the KLEJ benchmark, a newly introduced financial task suite (FinBench), and other classification and regression tasks, specifically those requiring long-document understanding. The results demonstrate that our model achieves the best average performance among Polish and multilingual models, significantly outperforming competitive solutions in long-context tasks while maintaining comparable quality on short texts.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025



Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Unveiling Dual Quality in Product Reviews: An NLP-Based Approach
May 25, 2025Consumers often face inconsistent product quality, particularly when identical products vary between markets, a situation known as the dual quality problem. To identify and address this issue, automated techniques are needed. This paper explores how natural language processing (NLP) can aid in detecting such discrepancies and presents the full process of developing a solution. First, we describe in detail the creation of a new Polish-language dataset with 1,957 reviews, 540 highlighting dual quality issues. We then discuss experiments with various approaches like SetFit with sentence-transformers, transformer-based encoders, and LLMs, including error analysis and robustness verification. Additionally, we evaluate multilingual transfer using a subset of opinions in English, French, and German. The paper concludes with insights on deployment and practical applications.
Evaluating Polish linguistic and cultural competency in large language models
Mar 02, 2025


Large language models (LLMs) are becoming increasingly proficient in processing and generating multilingual texts, which allows them to address real-world problems more effectively. However, language understanding is a far more complex issue that goes beyond simple text analysis. It requires familiarity with cultural context, including references to everyday life, historical events, traditions, folklore, literature, and pop culture. A lack of such knowledge can lead to misinterpretations and subtle, hard-to-detect errors. To examine language models' knowledge of the Polish cultural context, we introduce the Polish linguistic and cultural competency benchmark, consisting of 600 manually crafted questions. The benchmark is divided into six categories: history, geography, culture & tradition, art & entertainment, grammar, and vocabulary. As part of our study, we conduct an extensive evaluation involving over 30 open-weight and commercial LLMs. Our experiments provide a new perspective on Polish competencies in language models, moving past traditional natural language processing tasks and general knowledge assessment.
PL-MTEB: Polish Massive Text Embedding Benchmark
May 16, 2024In this paper, we introduce the Polish Massive Text Embedding Benchmark (PL-MTEB), a comprehensive benchmark for text embeddings in Polish. The PL-MTEB consists of 28 diverse NLP tasks from 5 task types. We adapted the tasks based on previously used datasets by the Polish NLP community. In addition, we created a new PLSC (Polish Library of Science Corpus) dataset consisting of titles and abstracts of scientific publications in Polish, which was used as the basis for two novel clustering tasks. We evaluated 15 publicly available models for text embedding, including Polish and multilingual ones, and collected detailed results for individual tasks and aggregated results for each task type and the entire benchmark. PL-MTEB comes with open-source code at https://github.com/rafalposwiata/pl-mteb.
Assessing generalization capability of text ranking models in Polish
Feb 22, 2024



Retrieval-augmented generation (RAG) is becoming an increasingly popular technique for integrating internal knowledge bases with large language models. In a typical RAG pipeline, three models are used, responsible for the retrieval, reranking, and generation stages. In this article, we focus on the reranking problem for the Polish language, examining the performance of rerankers and comparing their results with available retrieval models. We conduct a comprehensive evaluation of existing models and those trained by us, utilizing a benchmark of 41 diverse information retrieval tasks for the Polish language. The results of our experiments show that most models struggle with out-of-domain generalization. However, a combination of effective optimization method and a large training dataset allows for building rerankers that are both compact in size and capable of generalization. The best of our models establishes a new state-of-the-art for reranking in the Polish language, outperforming existing models with up to 30 times more parameters.
PIRB: A Comprehensive Benchmark of Polish Dense and Hybrid Text Retrieval Methods
Feb 20, 2024We present Polish Information Retrieval Benchmark (PIRB), a comprehensive evaluation framework encompassing 41 text information retrieval tasks for Polish. The benchmark incorporates existing datasets as well as 10 new, previously unpublished datasets covering diverse topics such as medicine, law, business, physics, and linguistics. We conduct an extensive evaluation of over 20 dense and sparse retrieval models, including the baseline models trained by us as well as other available Polish and multilingual methods. Finally, we introduce a three-step process for training highly effective language-specific retrievers, consisting of knowledge distillation, supervised fine-tuning, and building sparse-dense hybrid retrievers using a lightweight rescoring model. In order to validate our approach, we train new text encoders for Polish and compare their results with previously evaluated methods. Our dense models outperform the best solutions available to date, and the use of hybrid methods further improves their performance.
OPI at SemEval 2023 Task 1: Image-Text Embeddings and Multimodal Information Retrieval for Visual Word Sense Disambiguation
Apr 14, 2023



The goal of visual word sense disambiguation is to find the image that best matches the provided description of the word's meaning. It is a challenging problem, requiring approaches that combine language and image understanding. In this paper, we present our submission to SemEval 2023 visual word sense disambiguation shared task. The proposed system integrates multimodal embeddings, learning to rank methods, and knowledge-based approaches. We build a classifier based on the CLIP model, whose results are enriched with additional information retrieved from Wikipedia and lexical databases. Our solution was ranked third in the multilingual task and won in the Persian track, one of the three language subtasks.
OPI at SemEval 2023 Task 9: A Simple But Effective Approach to Multilingual Tweet Intimacy Analysis
Apr 14, 2023



This paper describes our submission to the SemEval 2023 multilingual tweet intimacy analysis shared task. The goal of the task was to assess the level of intimacy of Twitter posts in ten languages. The proposed approach consists of several steps. First, we perform in-domain pre-training to create a language model adapted to Twitter data. In the next step, we train an ensemble of regression models to expand the training set with pseudo-labeled examples. The extended dataset is used to train the final solution. Our method was ranked first in five out of ten language subtasks, obtaining the highest average score across all languages.
Training Effective Neural Sentence Encoders from Automatically Mined Paraphrases
Jul 26, 2022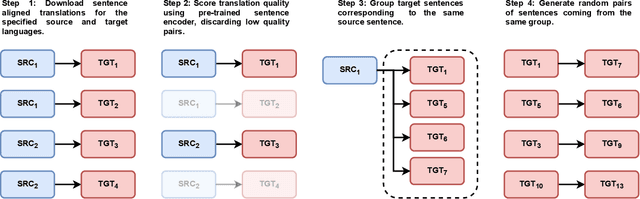
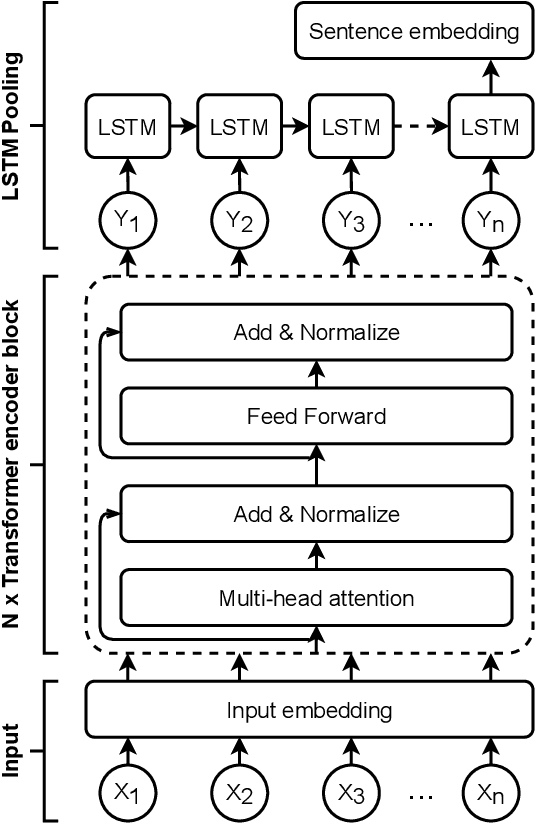
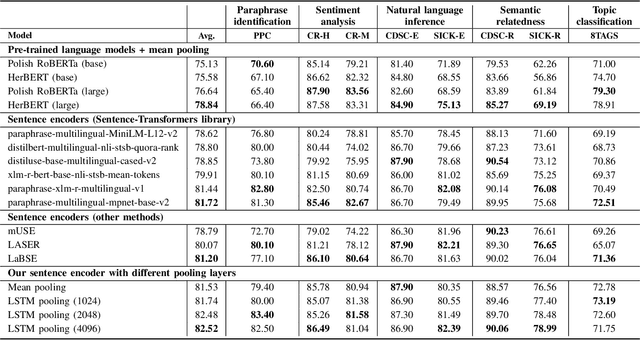
Sentence embeddings are commonly used in text clustering and semantic retrieval tasks. State-of-the-art sentence representation methods are based on artificial neural networks fine-tuned on large collections of manually labeled sentence pairs. Sufficient amount of annotated data is available for high-resource languages such as English or Chinese. In less popular languages, multilingual models have to be used, which offer lower performance. In this publication, we address this problem by proposing a method for training effective language-specific sentence encoders without manually labeled data. Our approach is to automatically construct a dataset of paraphrase pairs from sentence-aligned bilingual text corpora. We then use the collected data to fine-tune a Transformer language model with an additional recurrent pooling layer. Our sentence encoder can be trained in less than a day on a single graphics card, achieving high performance on a diverse set of sentence-level tasks. We evaluate our method on eight linguistic tasks in Polish, comparing it with the best available multilingual sentence encoders.