 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Small Test Error in Mildly Overparameterized Neural Networks
Apr 24, 2021Recent theoretical works on over-parameterized neural nets have focused on two aspects: optimization and generalization. Many existing works that study optimization and generalization together are based on neural tangent kernel and require a very large width. In this work, we are interested in the following question: for a binary classification problem with two-layer mildly over-parameterized ReLU network, can we find a point with small test error in polynomial time? We first show that the landscape of loss functions with explicit regularization has the following property: all local minima and certain other points which are only stationary in certain directions achieve small test error. We then prove that for convolutional neural nets, there is an algorithm which finds one of these points in polynomial time (in the input dimension and the number of data points). In addition, we prove that for a fully connected neural net, with an additional assumption on the data distribution, there is a polynomial time algorithm.
Sample Complexity and Overparameterization Bounds for Projection-Free Neural TD Learning
Mar 02, 2021
We study the dynamics of temporal-difference learning with neural network-based value function approximation over a general state space, namely, \emph{Neural TD learning}. Existing analysis of neural TD learning relies on either infinite width-analysis or constraining the network parameters in a (random) compact set; as a result, an extra projection step is required at each iteration. This paper establishes a new convergence analysis of neural TD learning \emph{without any projection}. We show that the projection-free TD learning equipped with a two-layer ReLU network of any width exceeding $poly(\overline{\nu},1/\epsilon)$ converges to the true value function with error $\epsilon$ given $poly(\overline{\nu},1/\epsilon)$ iterations or samples, where $\overline{\nu}$ is an upper bound on the RKHS norm of the value function induced by the neural tangent kernel. Our sample complexity and overparameterization bounds are based on a drift analysis of the network parameters as a stopped random process in the lazy training regime.
Optimistic Policy Iteration for MDPs with Acyclic Transient State Structure
Feb 13, 2021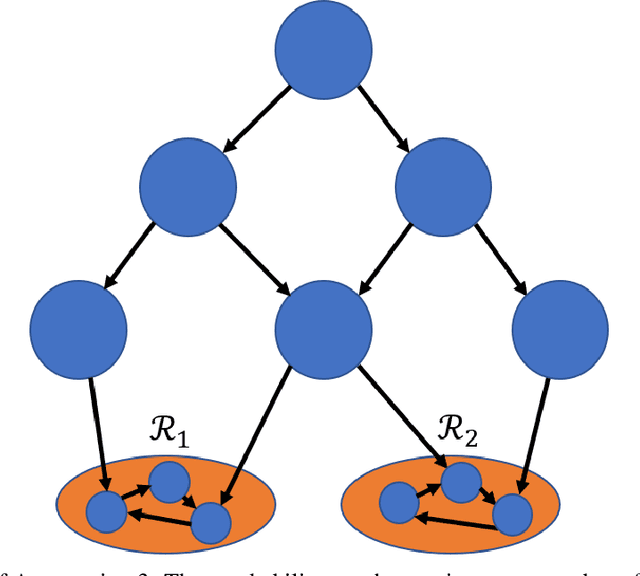
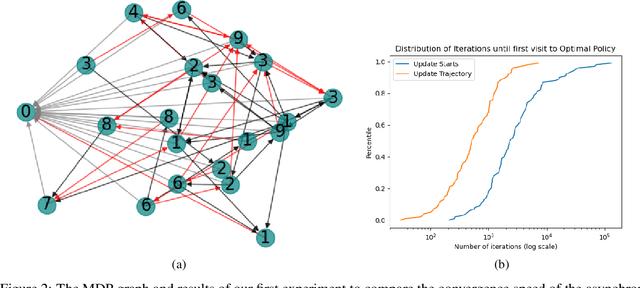
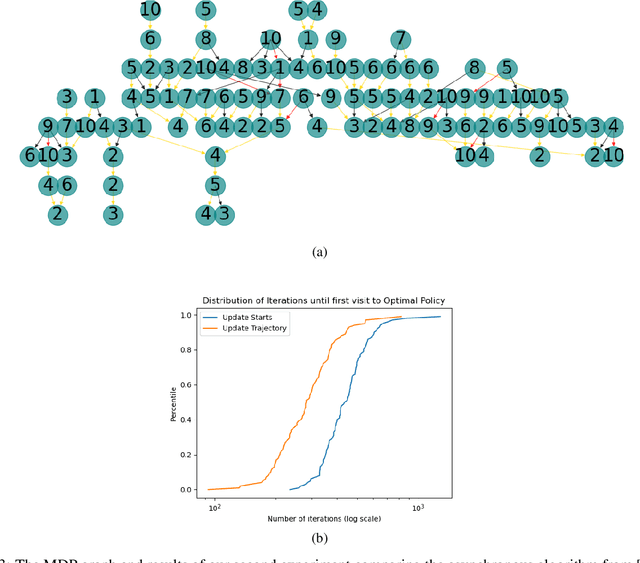
We consider Markov Decision Processes (MDPs) in which every stationary policy induces the same graph structure for the underlying Markov chain and further, the graph has the following property: if we replace each recurrent class by a node, then the resulting graph is acyclic. For such MDPs, we prove the convergence of the stochastic dynamics associated with a version of optimistic policy iteration (OPI), suggested in Tsitsiklis (2002), in which the values associated with all the nodes visited during each iteration of the OPI are updated.
One-bit feedback is sufficient for upper confidence bound policies
Dec 04, 2020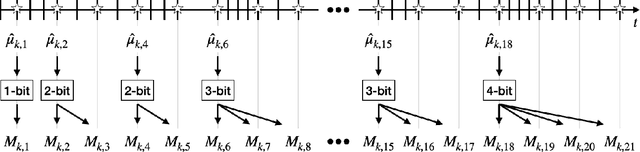
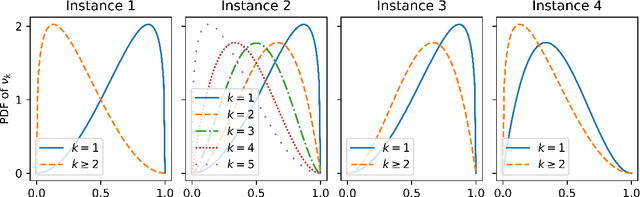
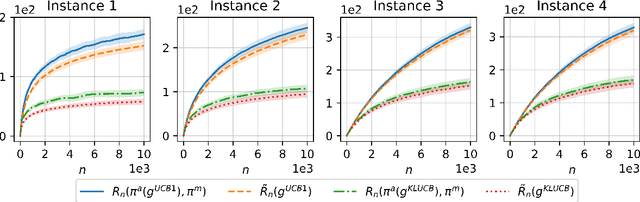
We consider a variant of the traditional multi-armed bandit problem in which each arm is only able to provide one-bit feedback during each pull based on its past history of rewards. Our main result is the following: given an upper confidence bound policy which uses full-reward feedback, there exists a coding scheme for generating one-bit feedback, and a corresponding decoding scheme and arm selection policy, such that the ratio of the regret achieved by our policy and the regret of the full-reward feedback policy asymptotically approaches one.
Combining Reinforcement Learning with Model Predictive Control for On-Ramp Merging
Nov 17, 2020
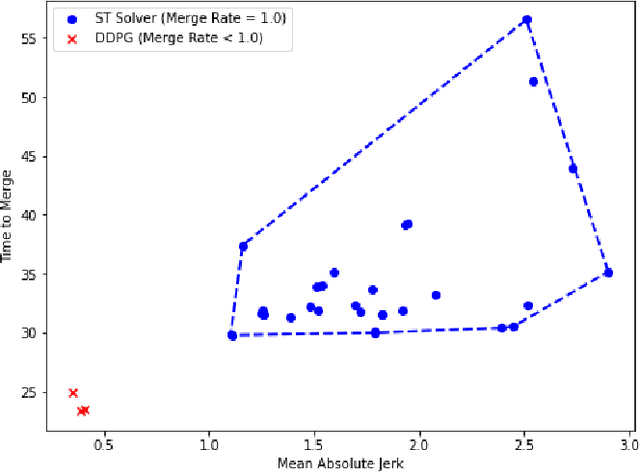
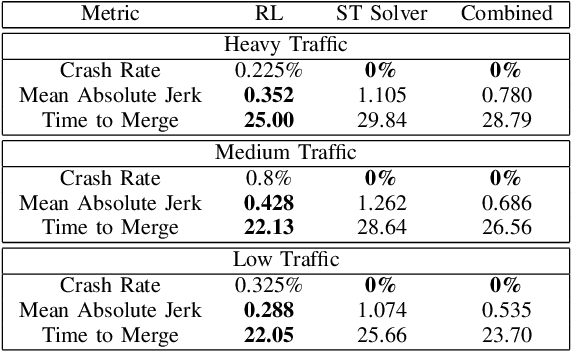
We consider the problem of designing an algorithm to allow a car to autonomously merge on to a highway from an on-ramp. Two broad classes of techniques have been proposed to solve motion planning problems in autonomous driving: Model Predictive Control (MPC) and Reinforcement Learning (RL). In this paper, we first establish the strengths and weaknesses of state-of-the-art MPC and RL-based techniques through simulations. We show that the performance of the RL agent is worse than that of the MPC solution from the perspective of safety and robustness to out-of-distribution traffic patterns, i.e., traffic patterns which were not seen by the RL agent during training. On the other hand, the performance of the RL agent is better than that of the MPC solution when it comes to efficiency and passenger comfort. We subsequently present an algorithm which blends the model-free RL agent with the MPC solution and show that it provides better trade-offs between all metrics -- passenger comfort, efficiency, crash rate and robustness.
On the Consistency of Maximum Likelihood Estimators for Causal Network Identification
Oct 17, 2020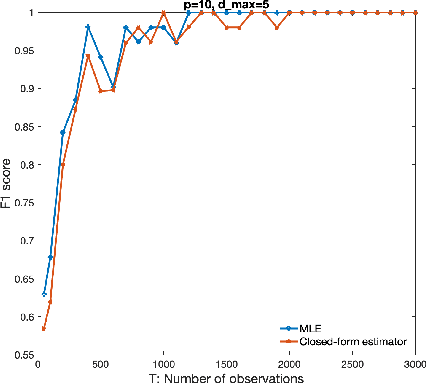
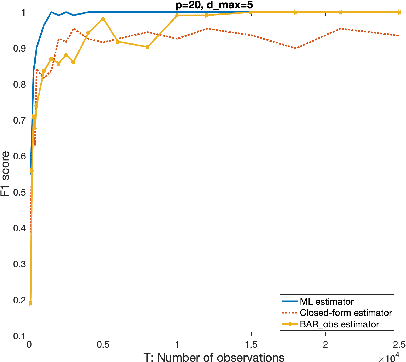
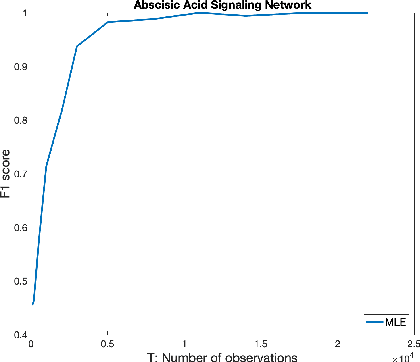
We consider the problem of identifying parameters of a particular class of Markov chains, called Bernoulli Autoregressive (BAR) processes. The structure of any BAR model is encoded by a directed graph. Incoming edges to a node in the graph indicate that the state of the node at a particular time instant is influenced by the states of the corresponding parental nodes in the previous time instant. The associated edge weights determine the corresponding level of influence from each parental node. In the simplest setup, the Bernoulli parameter of a particular node's state variable is a convex combination of the parental node states in the previous time instant and an additional Bernoulli noise random variable. This paper focuses on the problem of edge weight identification using Maximum Likelihood (ML) estimation and proves that the ML estimator is strongly consistent for two variants of the BAR model. We additionally derive closed-form estimators for the aforementioned two variants and prove their strong consistency.
Hellinger KL-UCB based Bandit Algorithms for Markovian and i.i.d. Settings
Sep 14, 2020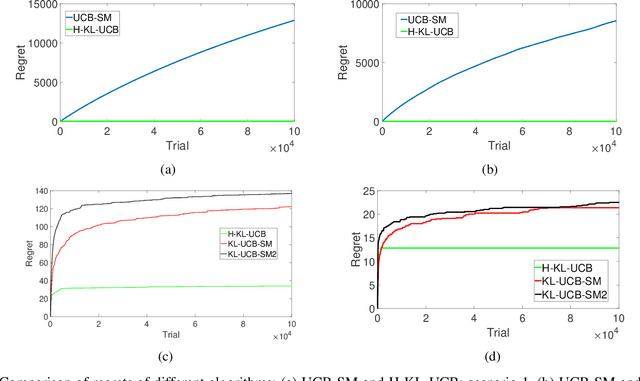
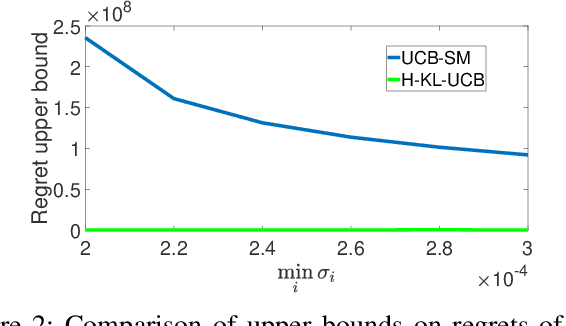
In the regret-based formulation of multi-armed bandit (MAB) problems, except in rare instances, much of the literature focuses on arms with i.i.d. rewards. In this paper, we consider the problem of obtaining regret guarantees for MAB problems in which the rewards of each arm form a Markov chain which may not belong to a single parameter exponential family. To achieve logarithmic regret in such problems is not difficult: a variation of standard KL-UCB does the job. However, the constants obtained from such an analysis are poor for the following reason: i.i.d. rewards are a special case of Markov rewards and it is difficult to design an algorithm that works well independent of whether the underlying model is truly Markovian or i.i.d. To overcome this issue, we introduce a novel algorithm that identifies whether the rewards from each arm are truly Markovian or i.i.d. using a Hellinger distance-based test. Our algorithm then switches from using a standard KL-UCB to a specialized version of KL-UCB when it determines that the arm reward is Markovian, thus resulting in low regret for both i.i.d. and Markovian settings.
Provably-Efficient Double Q-Learning
Jul 09, 2020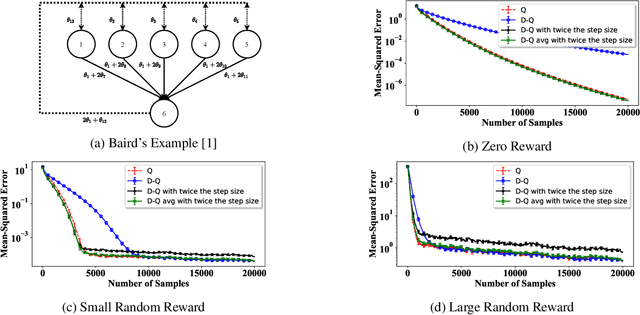
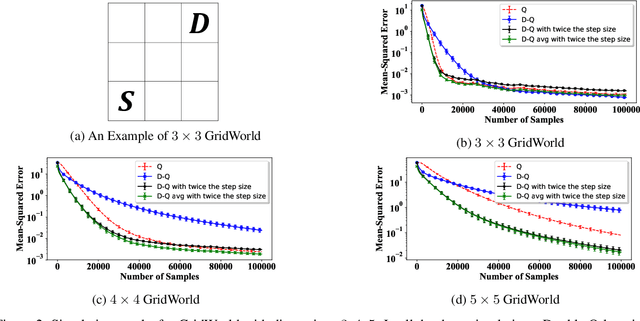

In this paper, we establish a theoretical comparison between the asymptotic mean-squared error of Double Q-learning and Q-learning. Our result builds upon an analysis for linear stochastic approximation based on Lyapunov equations and applies to both tabular setting and with linear function approximation, provided that the optimal policy is unique and the algorithms converge. We show that the asymptotic mean-squared error of Double Q-learning is exactly equal to that of Q-learning if Double Q-learning uses twice the learning rate of Q-learning and outputs the average of its two estimators. We also present some practical implications of this theoretical observation using simulations.
Robust Multi-Agent Multi-Armed Bandits
Jul 07, 2020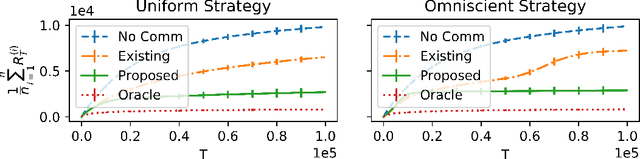
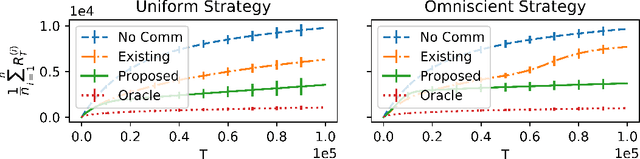
There has been recent interest in collaborative multi-agent bandits, where groups of agents share recommendations to decrease per-agent regret. However, these works assume that each agent always recommends their individual best-arm estimates to other agents, which is unrealistic in envisioned applications (machine faults in distributed computing or spam in social recommendation systems). Hence, we generalize the setting to include honest and malicious agents who recommend best-arm estimates and arbitrary arms, respectively. We show that even with a single malicious agent, existing collaboration-based algorithms fail to improve regret guarantees over a single-agent baseline. We propose a scheme where honest agents learn who is malicious and dynamically reduce communication with them, i.e., "blacklist" them. We show that collaboration indeed decreases regret for this algorithm, when the number of malicious agents is small compared to the number of arms, and crucially without assumptions on the malicious agents' behavior. Thus, our algorithm is robust against any malicious recommendation strategy.
Continuous-Time Multi-Armed Bandits with Controlled Restarts
Jun 30, 2020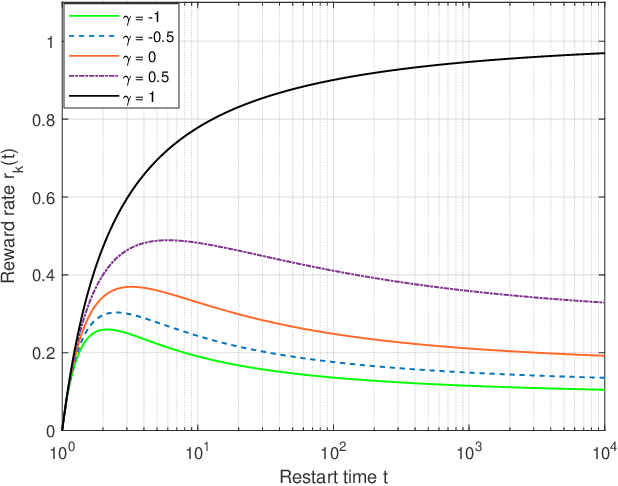
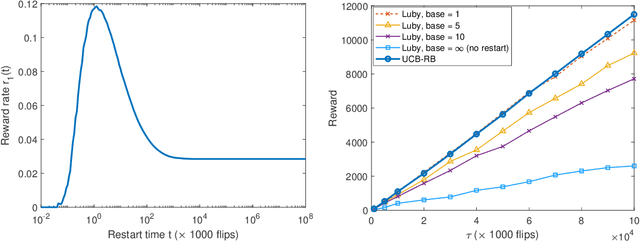
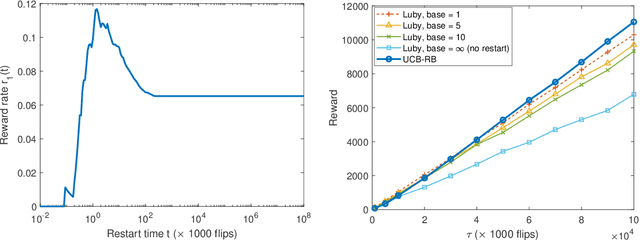
Time-constrained decision processes have been ubiquitous in many fundamental applications in physics, biology and computer science. Recently, restart strategies have gained significant attention for boosting the efficiency of time-constrained processes by expediting the completion times. In this work, we investigate the bandit problem with controlled restarts for time-constrained decision processes, and develop provably good learning algorithms. In particular, we consider a bandit setting where each decision takes a random completion time, and yields a random and correlated reward at the end, with unknown values at the time of decision. The goal of the decision-maker is to maximize the expected total reward subject to a time constraint $\tau$. As an additional control, we allow the decision-maker to interrupt an ongoing task and forgo its reward for a potentially more rewarding alternative. For this problem, we develop efficient online learning algorithms with $O(\log(\tau))$ and $O(\sqrt{\tau\log(\tau)})$ regret in a finite and continuous action space of restart strategies, respectively. We demonstrate an applicability of our algorithm by using it to boost the performance of SAT solvers.