 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Image Generation from Layouts
Mar 16, 2020


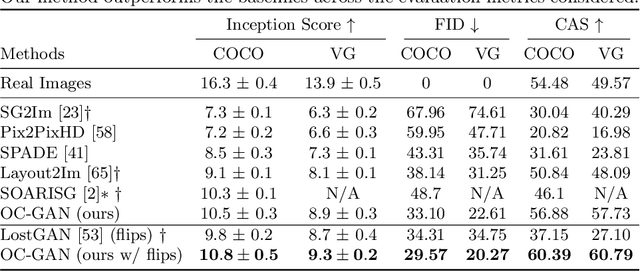
Despite recent impressive results on single-object and single-domain image generation, the generation of complex scenes with multiple objects remains challenging. In this paper, we start with the idea that a model must be able to understand individual objects and relationships between objects in order to generate complex scenes well. Our layout-to-image-generation method, which we call Object-Centric Generative Adversarial Network (or OC-GAN), relies on a novel Scene-Graph Similarity Module (SGSM). The SGSM learns representations of the spatial relationships between objects in the scene, which lead to our model's improved layout-fidelity. We also propose changes to the conditioning mechanism of the generator that enhance its object instance-awareness. Apart from improving image quality, our contributions mitigate two failure modes in previous approaches: (1) spurious objects being generated without corresponding bounding boxes in the layout, and (2) overlapping bounding boxes in the layout leading to merged objects in images. Extensive quantitative evaluation and ablation studies demonstrate the impact of our contributions, with our model outperforming previous state-of-the-art approaches on both the COCO-Stuff and Visual Genome datasets. Finally, we address an important limitation of evaluation metrics used in previous works by introducing SceneFID -- an object-centric adaptation of the popular Fr{\'e}chet Inception Distance metric, that is better suited for multi-object images.
An end-to-end approach for the verification problem: learning the right distance
Feb 21, 2020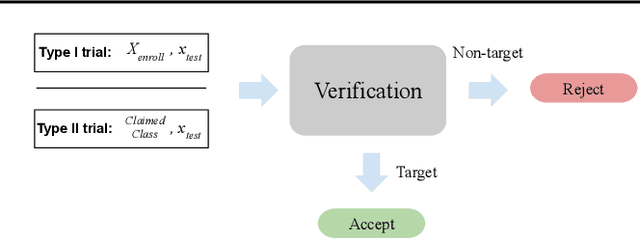
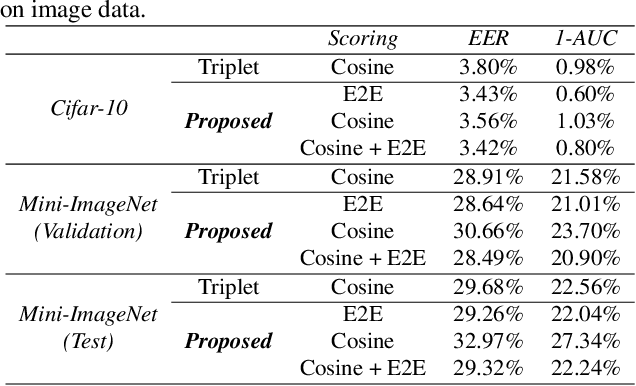
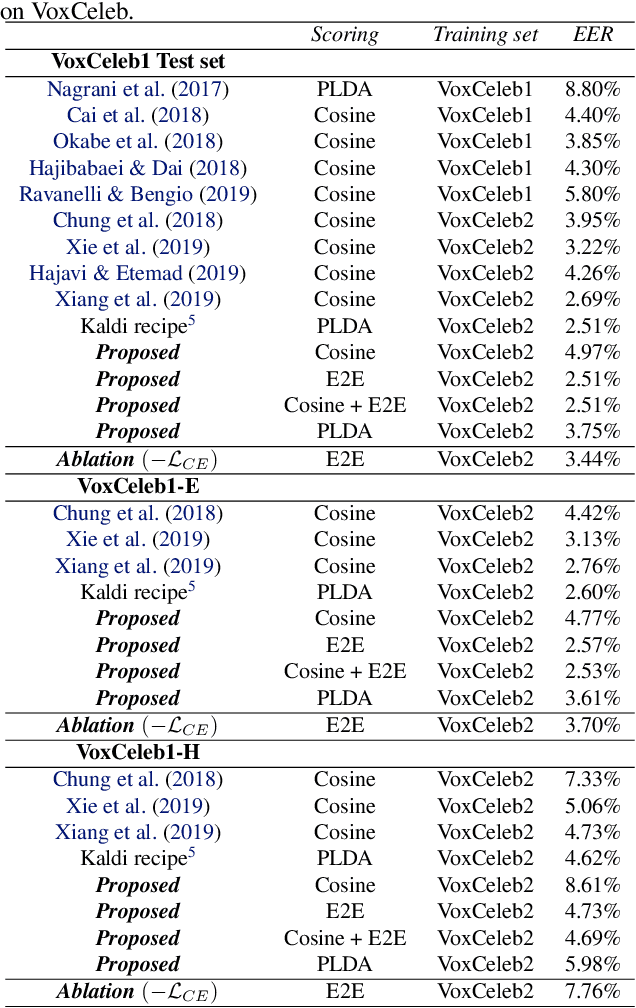
In this contribution, we augment the metric learning setting by introducing a parametric pseudo-distance, trained jointly with the encoder. Several interpretations are thus drawn for the learned distance-like model's output. We first show it approximates a likelihood ratio which can be used for hypothesis tests, and that it further induces a large divergence across the joint distributions of pairs of examples from the same and from different classes. Evaluation is performed under the verification setting consisting of determining whether sets of examples belong to the same class, even if such classes are novel and were never presented to the model during training. Empirical evaluation shows such method defines an end-to-end approach for the verification problem, able to attain better performance than simple scorers such as those based on cosine similarity and further outperforming widely used downstream classifiers. We further observe training is much simplified under the proposed approach compared to metric learning with actual distances, requiring no complex scheme to harvest pairs of examples.
Attraction-Repulsion Actor-Critic for Continuous Control Reinforcement Learning
Sep 24, 2019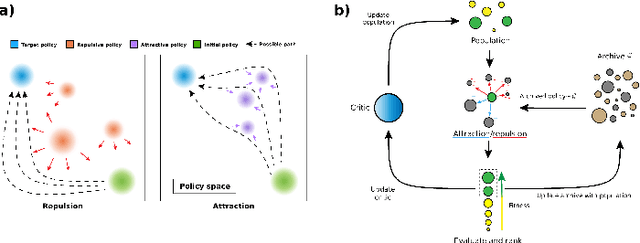
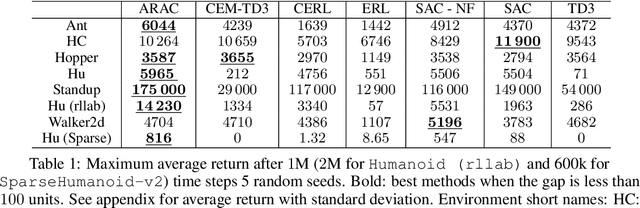
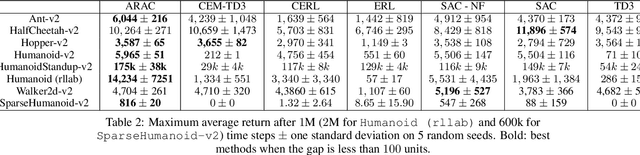
Continuous control tasks in reinforcement learning are important because they provide an important framework for learning in high-dimensional state spaces with deceptive rewards, where the agent can easily become trapped into suboptimal solutions. One way to avoid local optima is to use a population of agents to ensure coverage of the policy space, yet learning a population with the "best" coverage is still an open problem. In this work, we present a novel approach to population-based RL in continuous control that leverages properties of normalizing flows to perform attractive and repulsive operations between current members of the population and previously observed policies. Empirical results on the MuJoCo suite demonstrate a high performance gain for our algorithm compared to prior work, including Soft-Actor Critic (SAC).
Unsupervised State Representation Learning in Atari
Jun 26, 2019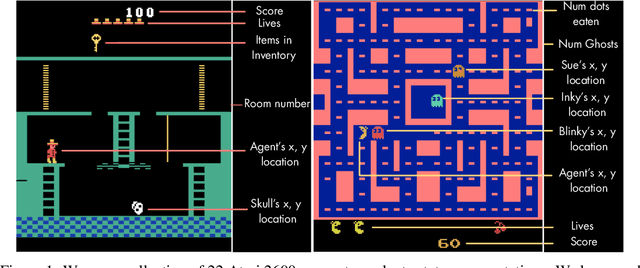
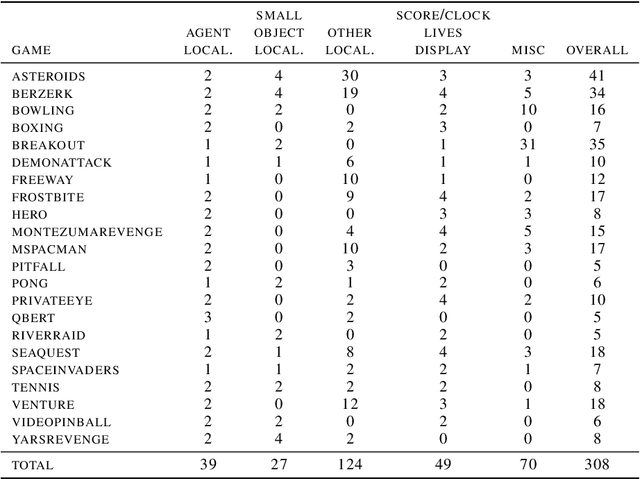
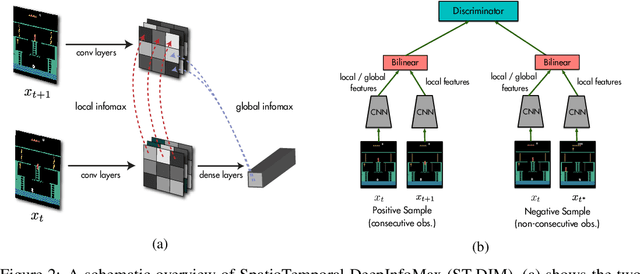
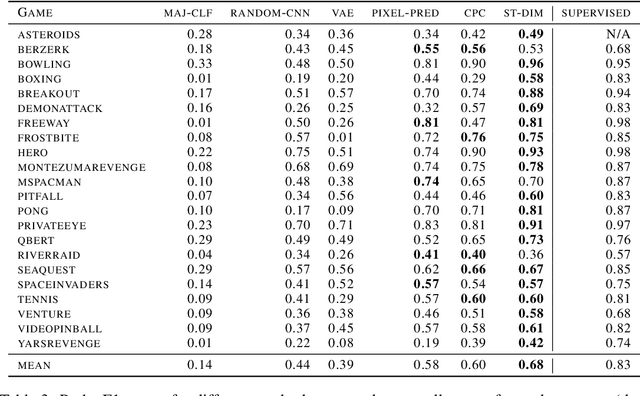
State representation learning, or the ability to capture latent generative factors of an environment, is crucial for building intelligent agents that can perform a wide variety of tasks. Learning such representations without supervision from rewards is a challenging open problem. We introduce a method that learns state representations by maximizing mutual information across spatially and temporally distinct features of a neural encoder of the observations. We also introduce a new benchmark based on Atari 2600 games where we evaluate representations based on how well they capture the ground truth state variables. We believe this new framework for evaluating representation learning models will be crucial for future representation learning research. Finally, we compare our technique with other state-of-the-art generative and contrastive representation learning methods.
Learning Representations by Maximizing Mutual Information Across Views
Jun 03, 2019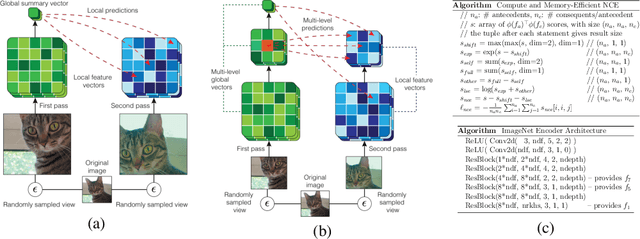
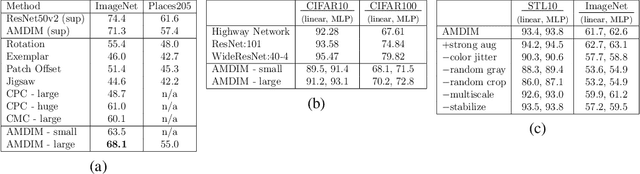

We propose an approach to self-supervised representation learning based on maximizing mutual information between features extracted from multiple views of a shared context. For example, a context could be an image from ImageNet, and multiple views of the context could be generated by repeatedly applying data augmentation to the image. Following this approach, we develop a new model which maximizes mutual information between features extracted at multiple scales from independently-augmented copies of each input. Our model significantly outperforms prior work on the tasks we consider. Most notably, it achieves over 60% accuracy on ImageNet using the standard linear evaluation protocol. This improves on prior results by over 4% (absolute). On Places205, using the representations learned on ImageNet, our model achieves 50% accuracy. This improves on prior results by 2% (absolute). When we extend our model to use mixture-based representations, segmentation behaviour emerges as a natural side-effect.
Batch weight for domain adaptation with mass shift
May 29, 2019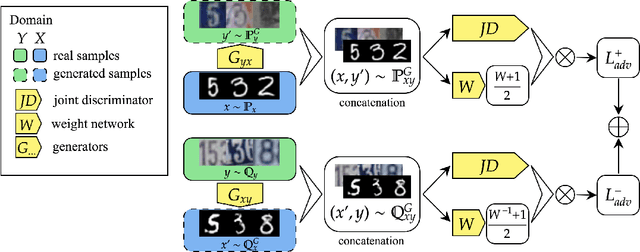


Unsupervised domain transfer is the task of transferring or translating samples from a source distribution to a different target distribution. Current solutions unsupervised domain transfer often operate on data on which the modes of the distribution are well-matched, for instance have the same frequencies of classes between source and target distributions. However, these models do not perform well when the modes are not well-matched, as would be the case when samples are drawn independently from two different, but related, domains. This mode imbalance is problematic as generative adversarial networks (GANs), a successful approach in this setting, are sensitive to mode frequency, which results in a mismatch of semantics between source samples and generated samples of the target distribution. We propose a principled method of re-weighting training samples to correct for such mass shift between the transferred distributions, which we call batch-weight. We also provide rigorous probabilistic setting for domain transfer and new simplified objective for training transfer networks, an alternative to complex, multi-component loss functions used in the current state-of-the art image-to-image translation models. The new objective stems from the discrimination of joint distributions and enforces cycle-consistency in an abstract, high-level, rather than pixel-wise, sense. Lastly, we experimentally show the effectiveness of the proposed methods in several image-to-image translation tasks.
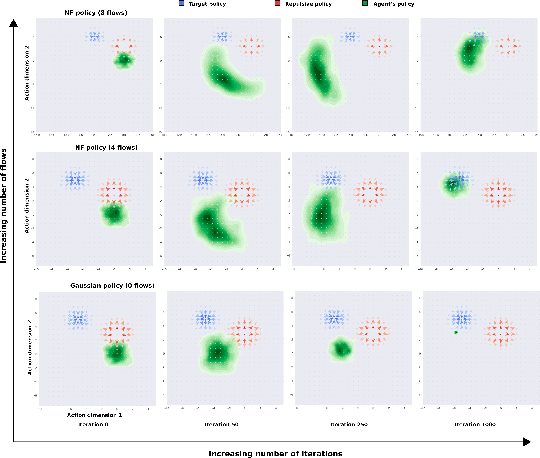
Leveraging exploration in off-policy algorithms via normalizing flows
May 16, 2019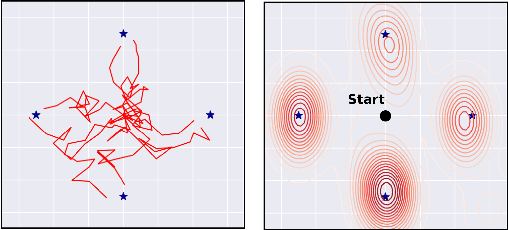
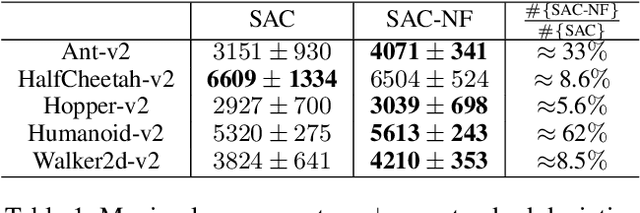
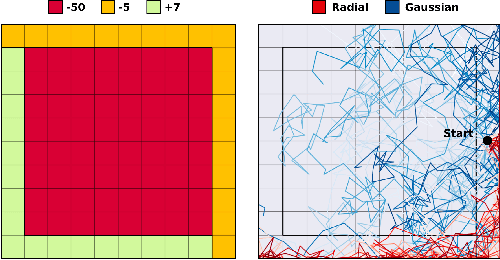
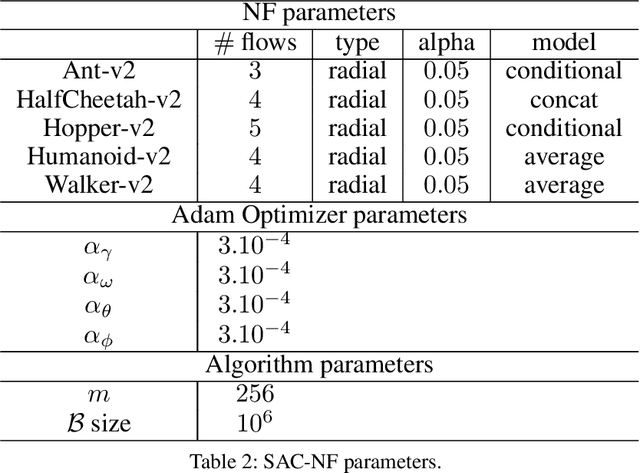
Exploration is a crucial component for discovering approximately optimal policies in most high-dimensional reinforcement learning (RL) settings with sparse rewards. Approaches such as neural density models and continuous exploration (e.g., Go-Explore) have been instrumental in recent advances. Soft actor-critic (SAC) is a method for improving exploration that aims to combine off-policy updates while maximizing the policy entropy. We extend SAC to a richer class of probability distributions through normalizing flows, which we show improves performance in exploration, sample complexity, and convergence. Finally, we show that not only the normalizing flow policy outperforms SAC on MuJoCo domains, it is also significantly lighter, using as low as 5.6% of the original network's parameters for similar performance.
Prediction of Progression to Alzheimer's disease with Deep InfoMax
May 01, 2019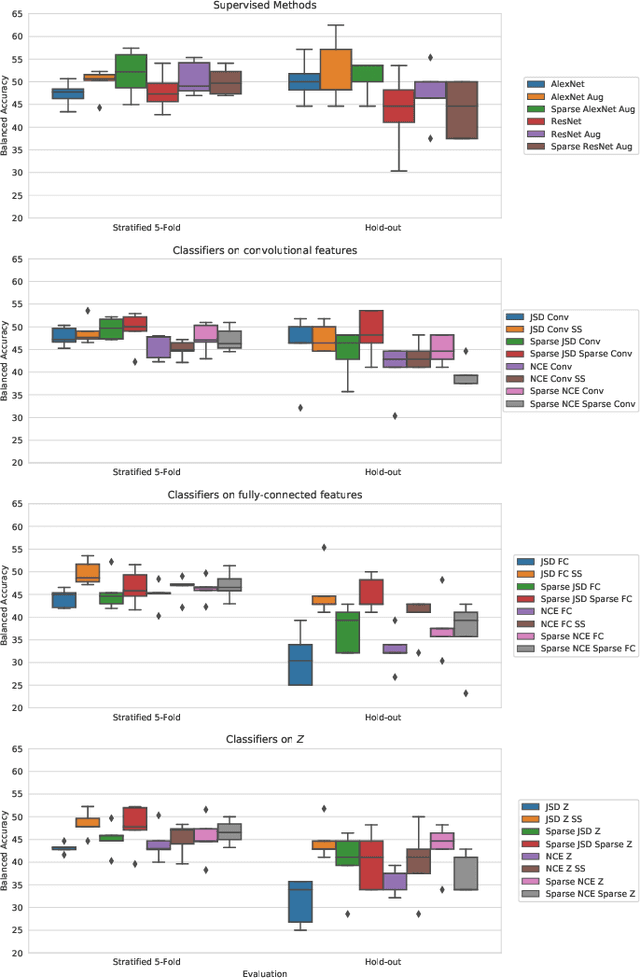
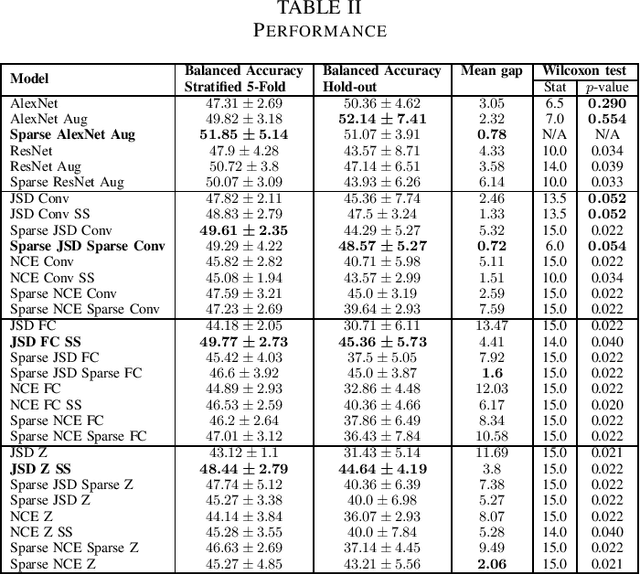
Arguably, unsupervised learning plays a crucial role in the majority of algorithms for processing brain imaging. A recently introduced unsupervised approach Deep InfoMax (DIM) is a promising tool for exploring brain structure in a flexible non-linear way. In this paper, we investigate the use of variants of DIM in a setting of progression to Alzheimer's disease in comparison with supervised AlexNet and ResNet inspired convolutional neural networks. As a benchmark, we use a classification task between four groups: patients with stable, and progressive mild cognitive impairment (MCI), with Alzheimer's disease, and healthy controls. Our dataset is comprised of 828 subjects from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. Our experiments highlight encouraging evidence of the high potential utility of DIM in future neuroimaging studies.
Spatio-Temporal Deep Graph Infomax
Apr 12, 2019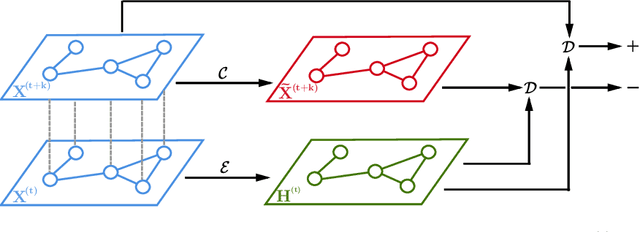
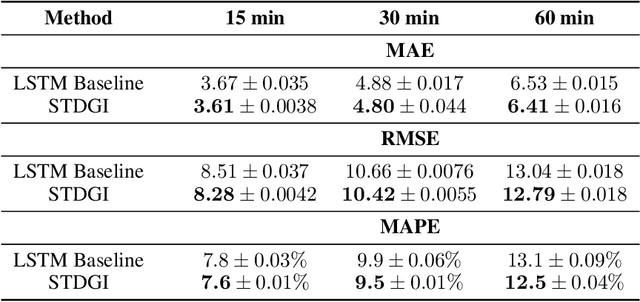
Spatio-temporal graphs such as traffic networks or gene regulatory systems present challenges for the existing deep learning methods due to the complexity of structural changes over time. To address these issues, we introduce Spatio-Temporal Deep Graph Infomax (STDGI)---a fully unsupervised node representation learning approach based on mutual information maximization that exploits both the temporal and spatial dynamics of the graph. Our model tackles the challenging task of node-level regression by training embeddings to maximize the mutual information between patches of the graph, at any given time step, and between features of the central nodes of patches, in the future. We demonstrate through experiments and qualitative studies that the learned representations can successfully encode relevant information about the input graph and improve the predictive performance of spatio-temporal auto-regressive forecasting models.
Adversarial Mixup Resynthesizers
Apr 04, 2019
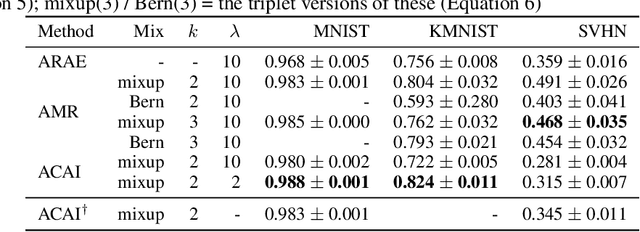
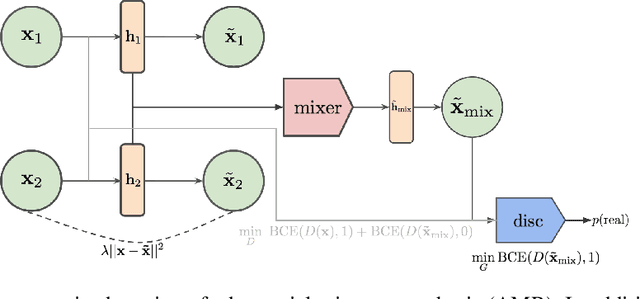
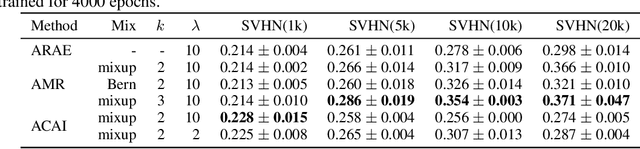
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.