 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Biomedical Entity and Relation Extraction with Knowledge-Enhanced Collective Inference
Jun 01, 2021
Compared to the general news domain, information extraction (IE) from biomedical text requires much broader domain knowledge. However, many previous IE methods do not utilize any external knowledge during inference. Due to the exponential growth of biomedical publications, models that do not go beyond their fixed set of parameters will likely fall behind. Inspired by how humans look up relevant information to comprehend a scientific text, we present a novel framework that utilizes external knowledge for joint entity and relation extraction named KECI (Knowledge-Enhanced Collective Inference). Given an input text, KECI first constructs an initial span graph representing its initial understanding of the text. It then uses an entity linker to form a knowledge graph containing relevant background knowledge for the the entity mentions in the text. To make the final predictions, KECI fuses the initial span graph and the knowledge graph into a more refined graph using an attention mechanism. KECI takes a collective approach to link mention spans to entities by integrating global relational information into local representations using graph convolutional networks. Our experimental results show that the framework is highly effective, achieving new state-of-the-art results in two different benchmark datasets: BioRelEx (binding interaction detection) and ADE (adverse drug event extraction). For example, KECI achieves absolute improvements of 4.59% and 4.91% in F1 scores over the state-of-the-art on the BioRelEx entity and relation extraction tasks.
A Context-Dependent Gated Module for Incorporating Symbolic Semantics into Event Coreference Resolution
Apr 04, 2021
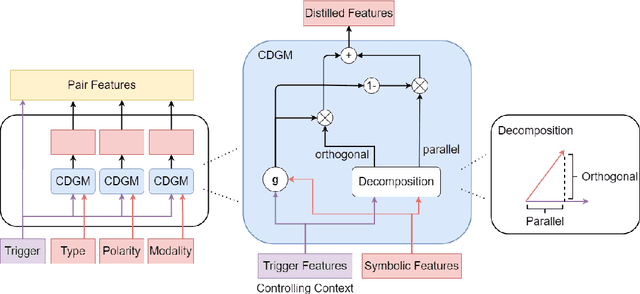
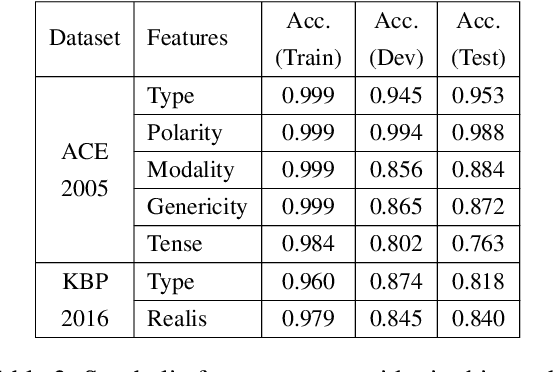
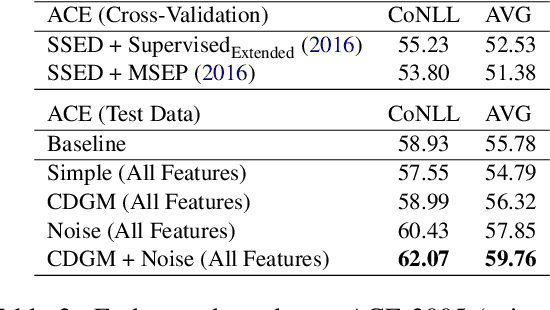
Event coreference resolution is an important research problem with many applications. Despite the recent remarkable success of pretrained language models, we argue that it is still highly beneficial to utilize symbolic features for the task. However, as the input for coreference resolution typically comes from upstream components in the information extraction pipeline, the automatically extracted symbolic features can be noisy and contain errors. Also, depending on the specific context, some features can be more informative than others. Motivated by these observations, we propose a novel context-dependent gated module to adaptively control the information flows from the input symbolic features. Combined with a simple noisy training method, our best models achieve state-of-the-art results on two datasets: ACE 2005 and KBP 2016.
What Does This Acronym Mean? Introducing a New Dataset for Acronym Identification and Disambiguation
Oct 28, 2020
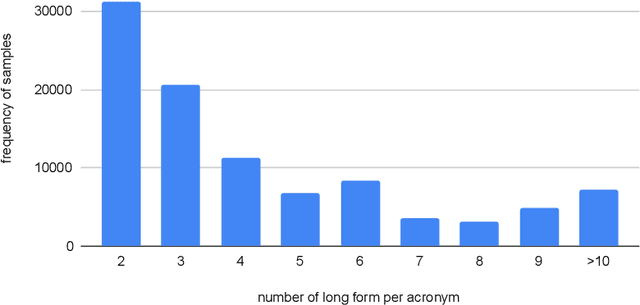
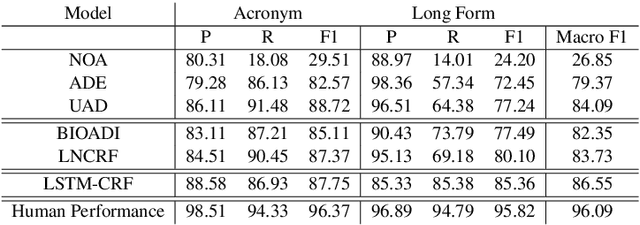
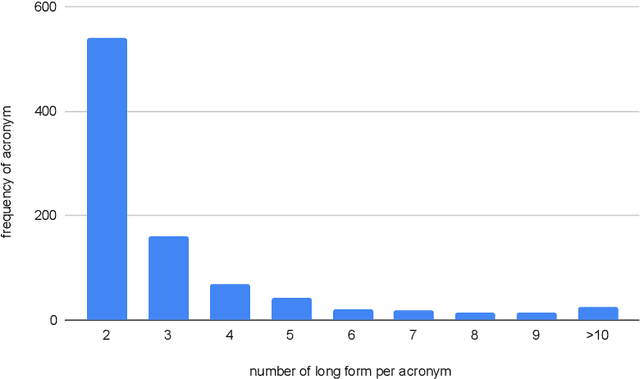
Acronyms are the short forms of phrases that facilitate conveying lengthy sentences in documents and serve as one of the mainstays of writing. Due to their importance, identifying acronyms and corresponding phrases (i.e., acronym identification (AI)) and finding the correct meaning of each acronym (i.e., acronym disambiguation (AD)) are crucial for text understanding. Despite the recent progress on this task, there are some limitations in the existing datasets which hinder further improvement. More specifically, limited size of manually annotated AI datasets or noises in the automatically created acronym identification datasets obstruct designing advanced high-performing acronym identification models. Moreover, the existing datasets are mostly limited to the medical domain and ignore other domains. In order to address these two limitations, we first create a manually annotated large AI dataset for scientific domain. This dataset contains 17,506 sentences which is substantially larger than previous scientific AI datasets. Next, we prepare an AD dataset for scientific domain with 62,441 samples which is significantly larger than the previous scientific AD dataset. Our experiments show that the existing state-of-the-art models fall far behind human-level performance on both datasets proposed by this work. In addition, we propose a new deep learning model that utilizes the syntactical structure of the sentence to expand an ambiguous acronym in a sentence. The proposed model outperforms the state-of-the-art models on the new AD dataset, providing a strong baseline for future research on this dataset.
Improving Aspect-based Sentiment Analysis with Gated Graph Convolutional Networks and Syntax-based Regulation
Oct 26, 2020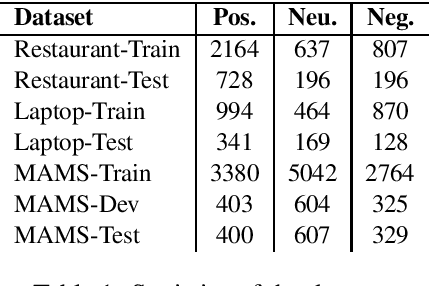
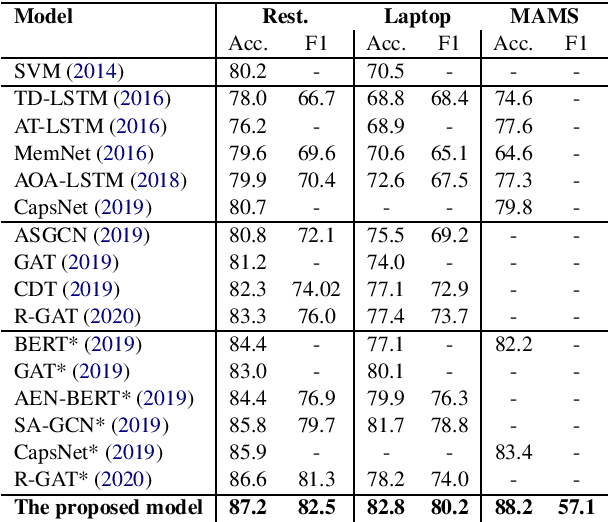
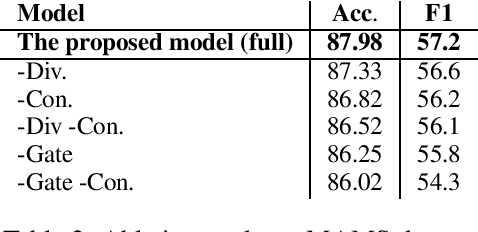

Aspect-based Sentiment Analysis (ABSA) seeks to predict the sentiment polarity of a sentence toward a specific aspect. Recently, it has been shown that dependency trees can be integrated into deep learning models to produce the state-of-the-art performance for ABSA. However, these models tend to compute the hidden/representation vectors without considering the aspect terms and fail to benefit from the overall contextual importance scores of the words that can be obtained from the dependency tree for ABSA. In this work, we propose a novel graph-based deep learning model to overcome these two issues of the prior work on ABSA. In our model, gate vectors are generated from the representation vectors of the aspect terms to customize the hidden vectors of the graph-based models toward the aspect terms. In addition, we propose a mechanism to obtain the importance scores for each word in the sentences based on the dependency trees that are then injected into the model to improve the representation vectors for ABSA. The proposed model achieves the state-of-the-art performance on three benchmark datasets.
A Joint Learning Approach based on Self-Distillation for Keyphrase Extraction from Scientific Documents
Oct 22, 2020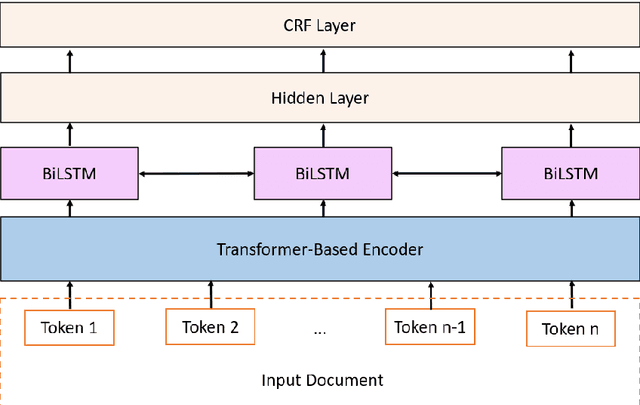
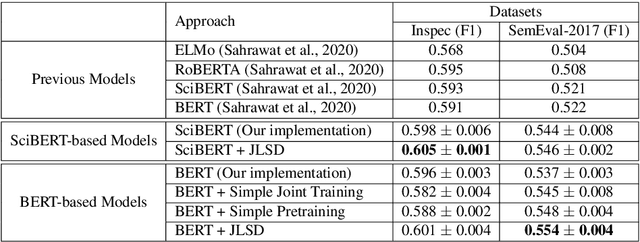

Keyphrase extraction is the task of extracting a small set of phrases that best describe a document. Most existing benchmark datasets for the task typically have limited numbers of annotated documents, making it challenging to train increasingly complex neural networks. In contrast, digital libraries store millions of scientific articles online, covering a wide range of topics. While a significant portion of these articles contain keyphrases provided by their authors, most other articles lack such kind of annotations. Therefore, to effectively utilize these large amounts of unlabeled articles, we propose a simple and efficient joint learning approach based on the idea of self-distillation. Experimental results show that our approach consistently improves the performance of baseline models for keyphrase extraction. Furthermore, our best models outperform previous methods for the task, achieving new state-of-the-art results on two public benchmarks: Inspec and SemEval-2017.
Scene Graph Modification Based on Natural Language Commands
Oct 06, 2020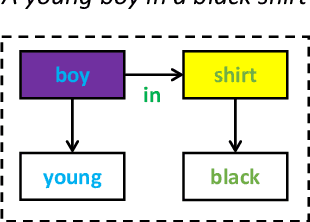
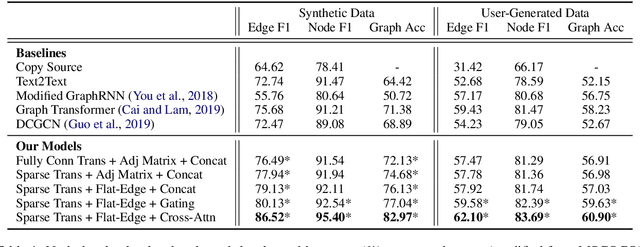
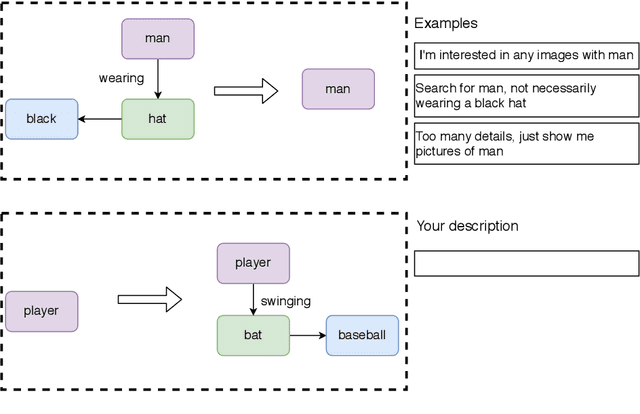
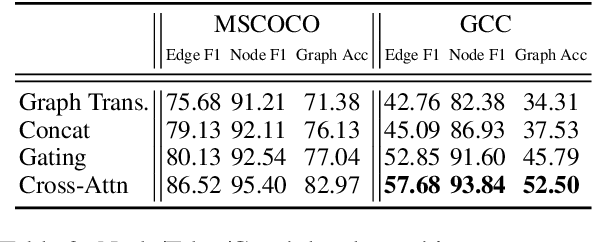
Structured representations like graphs and parse trees play a crucial role in many Natural Language Processing systems. In recent years, the advancements in multi-turn user interfaces necessitate the need for controlling and updating these structured representations given new sources of information. Although there have been many efforts focusing on improving the performance of the parsers that map text to graphs or parse trees, very few have explored the problem of directly manipulating these representations. In this paper, we explore the novel problem of graph modification, where the systems need to learn how to update an existing scene graph given a new user's command. Our novel models based on graph-based sparse transformer and cross attention information fusion outperform previous systems adapted from the machine translation and graph generation literature. We further contribute our large graph modification datasets to the research community to encourage future research for this new problem.
A Simple but Effective BERT Model for Dialog State Tracking on Resource-Limited Systems
Oct 28, 2019

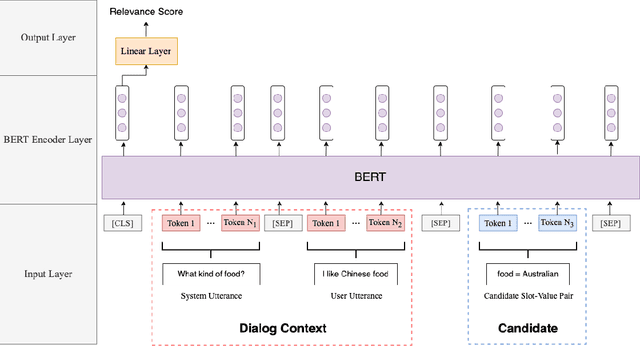
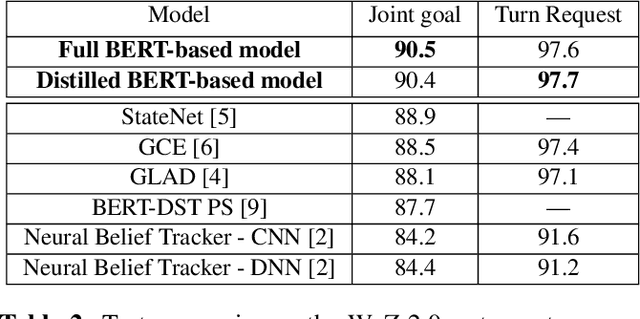
In a task-oriented dialog system, the goal of dialog state tracking (DST) is to monitor the state of the conversation from the dialog history. Recently, many deep learning based methods have been proposed for the task. Despite their impressive performance, current neural architectures for DST are typically heavily-engineered and conceptually complex, making it difficult to implement, debug, and maintain them in a production setting. In this work, we propose a simple but effective DST model based on BERT. In addition to its simplicity, our approach also has a number of other advantages: (a) the number of parameters does not grow with the ontology size (b) the model can operate in situations where the domain ontology may change dynamically. Experimental results demonstrate that our BERT-based model outperforms previous methods by a large margin, achieving new state-of-the-art results on the standard WoZ 2.0 dataset. Finally, to make the model small and fast enough for resource-restricted systems, we apply the knowledge distillation method to compress our model. The final compressed model achieves comparable results with the original model while being 8x smaller and 7x faster.
A Gated Self-attention Memory Network for Answer Selection
Sep 13, 2019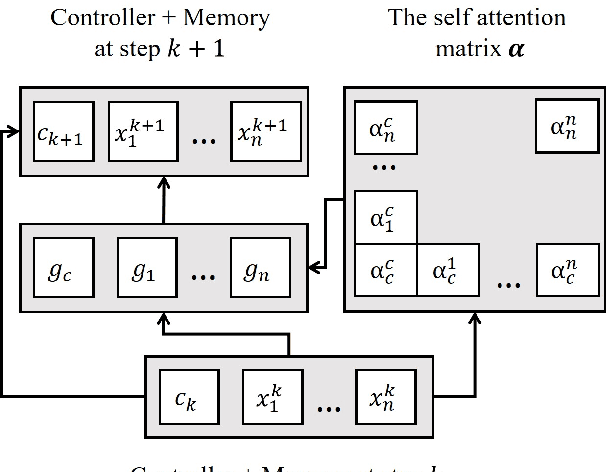

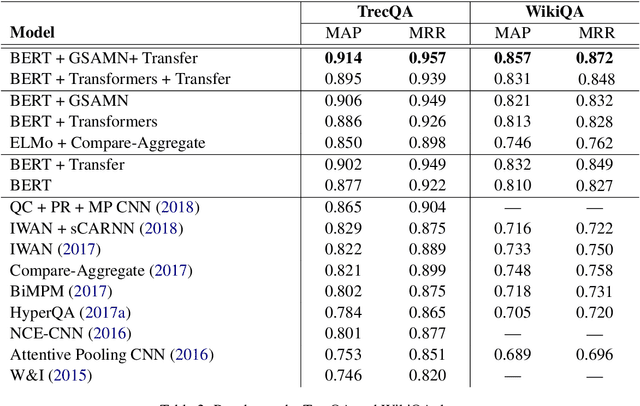
Answer selection is an important research problem, with applications in many areas. Previous deep learning based approaches for the task mainly adopt the Compare-Aggregate architecture that performs word-level comparison followed by aggregation. In this work, we take a departure from the popular Compare-Aggregate architecture, and instead, propose a new gated self-attention memory network for the task. Combined with a simple transfer learning technique from a large-scale online corpus, our model outperforms previous methods by a large margin, achieving new state-of-the-art results on two standard answer selection datasets: TrecQA and WikiQA.
Exploring Textual and Speech information in Dialogue Act Classification with Speaker Domain Adaptation
Oct 17, 2018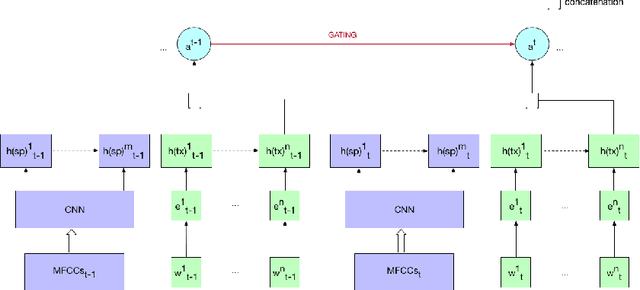
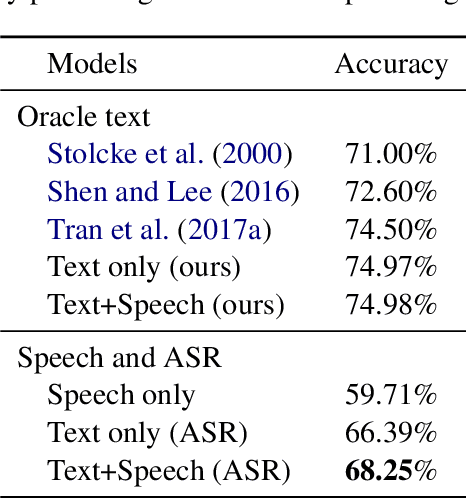
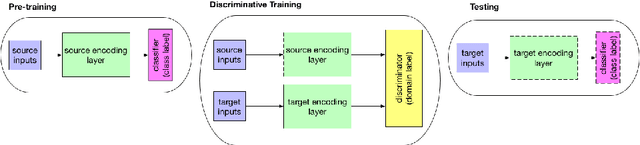
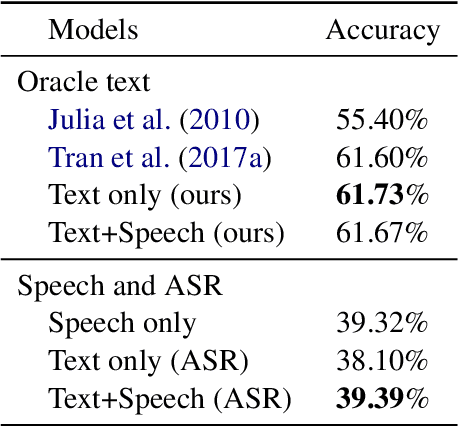
In spite of the recent success of Dialogue Act (DA) classification, the majority of prior works focus on text-based classification with oracle transcriptions, i.e. human transcriptions, instead of Automatic Speech Recognition (ASR)'s transcriptions. In spoken dialog systems, however, the agent would only have access to noisy ASR transcriptions, which may further suffer performance degradation due to domain shift. In this paper, we explore the effectiveness of using both acoustic and textual signals, either oracle or ASR transcriptions, and investigate speaker domain adaptation for DA classification. Our multimodal model proves to be superior to the unimodal models, particularly when the oracle transcriptions are not available. We also propose an effective method for speaker domain adaptation, which achieves competitive results.