 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Diversity Optimization as Multi-Objective Optimization
Jan 31, 2026The Quality-Diversity (QD) optimization aims to discover a collection of high-performing solutions that simultaneously exhibit diverse behaviors within a user-defined behavior space. This paradigm has stimulated significant research interest and demonstrated practical utility in domains including robot control, creative design, and adversarial sample generation. A variety of QD algorithms with distinct design principles have been proposed in recent years. Instead of proposing a new QD algorithm, this work introduces a novel reformulation by casting the QD optimization as a multi-objective optimization (MOO) problem with a huge number of optimization objectives. By establishing this connection, we enable the direct adoption of well-established MOO methods, particularly set-based scalarization techniques, to solve QD problems through a collaborative search process. We further provide a theoretical analysis demonstrating that our approach inherits theoretical guarantees from MOO while providing desirable properties for the QD optimization. Experimental studies across several QD applications confirm that our method achieves performance competitive with state-of-the-art QD algorithms.
Evolving Interdependent Operators with Large Language Models for Multi-Objective Combinatorial Optimization
Jan 25, 2026Neighborhood search operators are critical to the performance of Multi-Objective Evolutionary Algorithms (MOEAs) and rely heavily on expert design. Although recent LLM-based Automated Heuristic Design (AHD) methods have made notable progress, they primarily optimize individual heuristics or components independently, lacking explicit exploration and exploitation of dynamic coupling relationships between multiple operators. In this paper, multi-operator optimization in MOEAs is formulated as a Markov decision process, enabling the improvement of interdependent operators through sequential decision-making. To address this, we propose the Evolution of Operator Combination (E2OC) framework for MOEAs, which achieves the co-evolution of design strategies and executable codes. E2OC employs Monte Carlo Tree Search to progressively search combinations of operator design strategies and adopts an operator rotation mechanism to identify effective operator configurations while supporting the integration of mainstream AHD methods as the underlying designer. Experimental results across AHD tasks with varying objectives and problem scales show that E2OC consistently outperforms state-of-the-art AHD and other multi-heuristic co-design frameworks, demonstrating strong generalization and sustained optimization capability.
LLM-Assisted Automatic Dispatching Rule Design for Dynamic Flexible Assembly Flow Shop Scheduling
Jan 22, 2026Dynamic multi-product delivery environments demand rapid coordination of part completion and product-level kitting within hybrid processing and assembly systems to satisfy strict hierarchical supply constraints. The flexible assembly flow shop scheduling problem formally defines dependencies for multi-stage kitting, yet dynamic variants make designing integrated scheduling rules under multi-level time coupling highly challenging. Existing automated heuristic design methods, particularly genetic programming constrained to fixed terminal symbol sets, struggle to capture and leverage dynamic uncertainties and hierarchical dependency information under transient decision states. This study develops an LLM-assisted Dynamic Rule Design framework (LLM4DRD) that automatically evolves integrated online scheduling rules adapted to scheduling features. Firstly, multi-stage processing and assembly supply decisions are transformed into feasible directed edge orderings based on heterogeneous graph. Then, an elite knowledge guided initialization embeds advanced design expertise into initial rules to enhance initial quality. Additionally, a dual-expert mechanism is introduced in which LLM-A evolutionary code to generate candidate rules and LLM-S conducts scheduling evaluation, while dynamic feature-fitting rule evolution combined with hybrid evaluation enables continuous improvement and extracts adaptive rules with strong generalization capability. A series of experiments are conducted to validate the effectiveness of the method. The average tardiness of LLM4DRD is 3.17-12.39% higher than state-of-the-art methods in 20 practical instances used for training and testing, respectively. In 24 scenarios with different resource configurations, order loads, and disturbance levels totaling 480 instances, it achieves 11.10% higher performance than the second best competitor, exhibiting excellent robustness.
An Efficient Evolutionary Algorithm for Few-for-Many Optimization
Jan 10, 2026Few-for-many (F4M) optimization, recently introduced as a novel paradigm in multi-objective optimization, aims to find a small set of solutions that effectively handle a large number of conflicting objectives. Unlike traditional many-objective optimization methods, which typically attempt comprehensive coverage of the Pareto front, F4M optimization emphasizes finding a small representative solution set to efficiently address high-dimensional objective spaces. Motivated by the computational complexity and practical relevance of F4M optimization, this paper proposes a new evolutionary algorithm explicitly tailored for efficiently solving F4M optimization problems. Inspired by SMS-EMOA, our proposed approach employs a $(μ+1)$-evolution strategy guided by the objective of F4M optimization. Furthermore, to facilitate rigorous performance assessment, we propose a novel benchmark test suite specifically designed for F4M optimization by leveraging the similarity between the R2 indicator and F4M formulations. Our test suite is highly flexible, allowing any existing multi-objective optimization problem to be transformed into a corresponding F4M instance via scalarization using the weighted Tchebycheff function. Comprehensive experimental evaluations on benchmarks demonstrate the superior performance of our algorithm compared to existing state-of-the-art algorithms, especially on instances involving a large number of objectives. The source code of the proposed algorithm will be released publicly. Source code is available at https://github.com/MOL-SZU/SoM-EMOA.
Consistency Is Not Always Correct: Towards Understanding the Role of Exploration in Post-Training Reasoning
Nov 10, 2025Foundation models exhibit broad knowledge but limited task-specific reasoning, motivating post-training strategies such as RLVR and inference scaling with outcome or process reward models (ORM/PRM). While recent work highlights the role of exploration and entropy stability in improving pass@K, empirical evidence points to a paradox: RLVR and ORM/PRM typically reinforce existing tree-like reasoning paths rather than expanding the reasoning scope, raising the question of why exploration helps at all if no new patterns emerge. To reconcile this paradox, we adopt the perspective of Kim et al. (2025), viewing easy (e.g., simplifying a fraction) versus hard (e.g., discovering a symmetry) reasoning steps as low- versus high-probability Markov transitions, and formalize post-training dynamics through Multi-task Tree-structured Markov Chains (TMC). In this tractable model, pretraining corresponds to tree expansion, while post-training corresponds to chain-of-thought reweighting. We show that several phenomena recently observed in empirical studies arise naturally in this setting: (1) RLVR induces a squeezing effect, reducing reasoning entropy and forgetting some correct paths; (2) population rewards of ORM/PRM encourage consistency rather than accuracy, thereby favoring common patterns; and (3) certain rare, high-uncertainty reasoning paths by the base model are responsible for solving hard problem instances. Together, these explain why exploration -- even when confined to the base model's reasoning scope -- remains essential: it preserves access to rare but crucial reasoning traces needed for difficult cases, which are squeezed out by RLVR or unfavored by inference scaling. Building on this, we further show that exploration strategies such as rejecting easy instances and KL regularization help preserve rare reasoning traces. Empirical simulations corroborate our theoretical results.
Provable Benefit of Curriculum in Transformer Tree-Reasoning Post-Training
Nov 10, 2025Recent curriculum techniques in the post-training stage of LLMs have been widely observed to outperform non-curriculum approaches in enhancing reasoning performance, yet a principled understanding of why and to what extent they work remains elusive. To address this gap, we develop a theoretical framework grounded in the intuition that progressively learning through manageable steps is more efficient than directly tackling a hard reasoning task, provided each stage stays within the model's effective competence. Under mild complexity conditions linking consecutive curriculum stages, we show that curriculum post-training avoids the exponential complexity bottleneck. To substantiate this result, drawing insights from the Chain-of-Thoughts (CoTs) solving mathematical problems such as Countdown and parity, we model CoT generation as a states-conditioned autoregressive reasoning tree, define a uniform-branching base model to capture pretrained behavior, and formalize curriculum stages as either depth-increasing (longer reasoning chains) or hint-decreasing (shorter prefixes) subtasks. Our analysis shows that, under outcome-only reward signals, reinforcement learning finetuning achieves high accuracy with polynomial sample complexity, whereas direct learning suffers from an exponential bottleneck. We further establish analogous guarantees for test-time scaling, where curriculum-aware querying reduces both reward oracle calls and sampling cost from exponential to polynomial order.
Beyond the Lower Bound: Bridging Regret Minimization and Best Arm Identification in Lexicographic Bandits
Nov 08, 2025In multi-objective decision-making with hierarchical preferences, lexicographic bandits provide a natural framework for optimizing multiple objectives in a prioritized order. In this setting, a learner repeatedly selects arms and observes reward vectors, aiming to maximize the reward for the highest-priority objective, then the next, and so on. While previous studies have primarily focused on regret minimization, this work bridges the gap between \textit{regret minimization} and \textit{best arm identification} under lexicographic preferences. We propose two elimination-based algorithms to address this joint objective. The first algorithm eliminates suboptimal arms sequentially, layer by layer, in accordance with the objective priorities, and achieves sample complexity and regret bounds comparable to those of the best single-objective algorithms. The second algorithm simultaneously leverages reward information from all objectives in each round, effectively exploiting cross-objective dependencies. Remarkably, it outperforms the known lower bound for the single-objective bandit problem, highlighting the benefit of cross-objective information sharing in the multi-objective setting. Empirical results further validate their superior performance over baselines.
Parametric Pareto Set Learning for Expensive Multi-Objective Optimization
Nov 08, 2025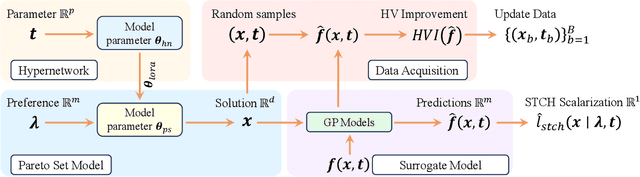
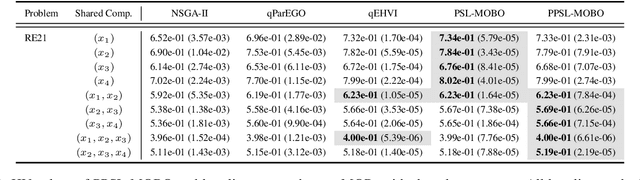
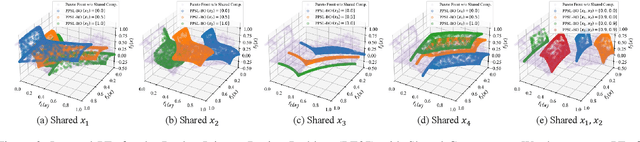
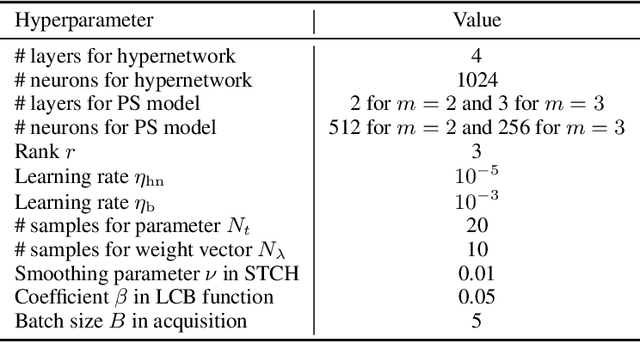
Parametric multi-objective optimization (PMO) addresses the challenge of solving an infinite family of multi-objective optimization problems, where optimal solutions must adapt to varying parameters. Traditional methods require re-execution for each parameter configuration, leading to prohibitive costs when objective evaluations are computationally expensive. To address this issue, we propose Parametric Pareto Set Learning with multi-objective Bayesian Optimization (PPSL-MOBO), a novel framework that learns a unified mapping from both preferences and parameters to Pareto-optimal solutions. PPSL-MOBO leverages a hypernetwork with Low-Rank Adaptation (LoRA) to efficiently capture parametric variations, while integrating Gaussian process surrogates and hypervolume-based acquisition to minimize expensive function evaluations. We demonstrate PPSL-MOBO's effectiveness on two challenging applications: multi-objective optimization with shared components, where certain design variables must be identical across solution families due to modular constraints, and dynamic multi-objective optimization, where objectives evolve over time. Unlike existing methods that cannot directly solve PMO problems in a unified manner, PPSL-MOBO learns a single model that generalizes across the entire parameter space. By enabling instant inference of Pareto sets for new parameter values without retraining, PPSL-MOBO provides an efficient solution for expensive PMO problems.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
Discovering Interpretable Programmatic Policies via Multimodal LLM-assisted Evolutionary Search
Aug 07, 2025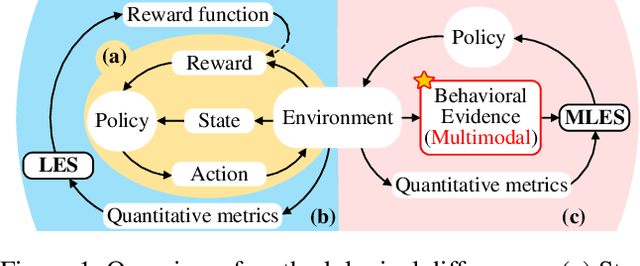
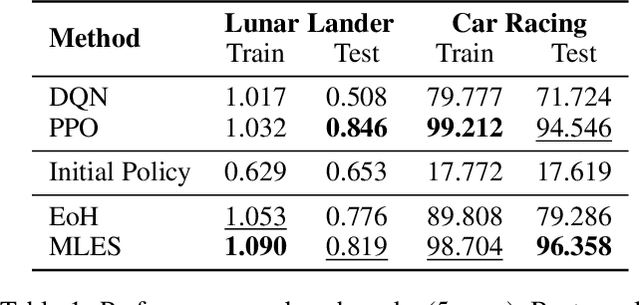
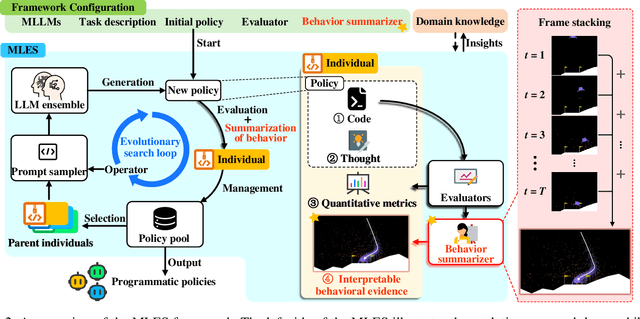
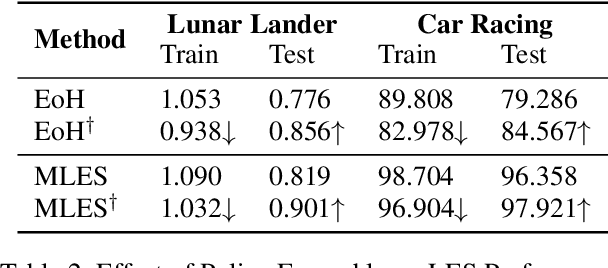
Interpretability and high performance are essential goals in designing control policies, particularly for safety-critical tasks. Deep reinforcement learning has greatly enhanced performance, yet its inherent lack of interpretability often undermines trust and hinders real-world deployment. This work addresses these dual challenges by introducing a novel approach for programmatic policy discovery, called Multimodal Large Language Model-assisted Evolutionary Search (MLES). MLES utilizes multimodal large language models as policy generators, combining them with evolutionary mechanisms for automatic policy optimization. It integrates visual feedback-driven behavior analysis within the policy generation process to identify failure patterns and facilitate targeted improvements, enhancing the efficiency of policy discovery and producing adaptable, human-aligned policies. Experimental results show that MLES achieves policy discovery capabilities and efficiency comparable to Proximal Policy Optimization (PPO) across two control tasks, while offering transparent control logic and traceable design processes. This paradigm overcomes the limitations of predefined domain-specific languages, facilitates knowledge transfer and reuse, and is scalable across various control tasks. MLES shows promise as a leading approach for the next generation of interpretable control policy discovery.