 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Pseudo Ground Truth with Motion Cue for Unsupervised Video Object Segmentation
Dec 13, 2018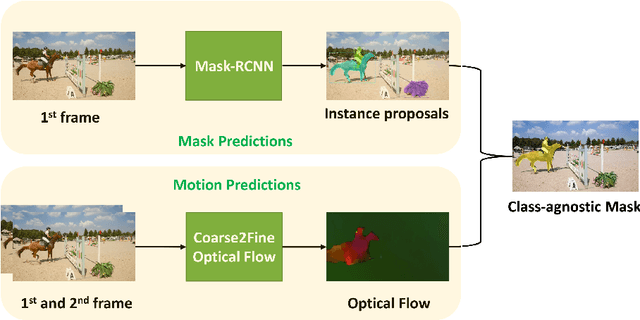


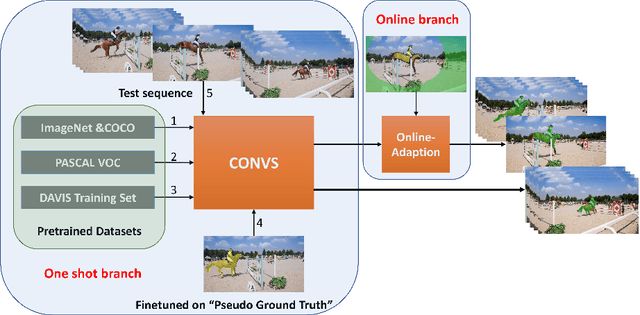
One major technique debt in video object segmentation is to label the object masks for training instances. As a result, we propose to prepare inexpensive, yet high quality pseudo ground truth corrected with motion cue for video object segmentation training. Our method conducts semantic segmentation using instance segmentation networks and, then, selects the segmented object of interest as the pseudo ground truth based on the motion information. Afterwards, the pseudo ground truth is exploited to finetune the pretrained objectness network to facilitate object segmentation in the remaining frames of the video. We show that the pseudo ground truth could effectively improve the segmentation performance. This straightforward unsupervised video object segmentation method is more efficient than existing methods. Experimental results on DAVIS and FBMS show that the proposed method outperforms state-of-the-art unsupervised segmentation methods on various benchmark datasets. And the category-agnostic pseudo ground truth has great potential to extend to multiple arbitrary object tracking.
SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting
Aug 06, 2018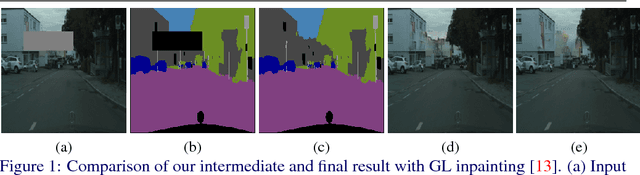
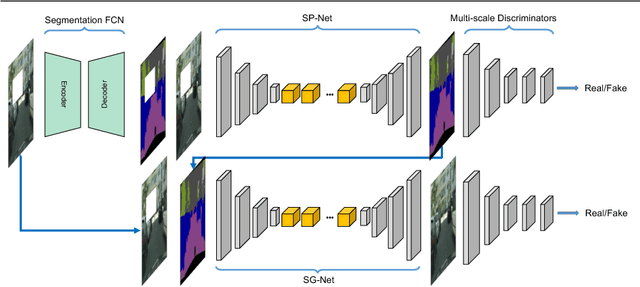


In this paper, we focus on image inpainting task, aiming at recovering the missing area of an incomplete image given the context information. Recent development in deep generative models enables an efficient end-to-end framework for image synthesis and inpainting tasks, but existing methods based on generative models don't exploit the segmentation information to constrain the object shapes, which usually lead to blurry results on the boundary. To tackle this problem, we propose to introduce the semantic segmentation information, which disentangles the inter-class difference and intra-class variation for image inpainting. This leads to much clearer recovered boundary between semantically different regions and better texture within semantically consistent segments. Our model factorizes the image inpainting process into segmentation prediction (SP-Net) and segmentation guidance (SG-Net) as two steps, which predict the segmentation labels in the missing area first, and then generate segmentation guided inpainting results. Experiments on multiple public datasets show that our approach outperforms existing methods in optimizing the image inpainting quality, and the interactive segmentation guidance provides possibilities for multi-modal predictions of image inpainting.
Contextual-based Image Inpainting: Infer, Match, and Translate
Jul 25, 2018

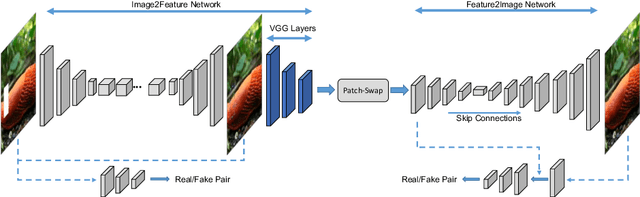
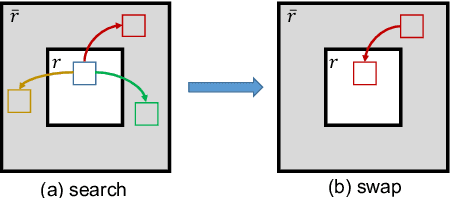
We study the task of image inpainting, which is to fill in the missing region of an incomplete image with plausible contents. To this end, we propose a learning-based approach to generate visually coherent completion given a high-resolution image with missing components. In order to overcome the difficulty to directly learn the distribution of high-dimensional image data, we divide the task into inference and translation as two separate steps and model each step with a deep neural network. We also use simple heuristics to guide the propagation of local textures from the boundary to the hole. We show that, by using such techniques, inpainting reduces to the problem of learning two image-feature translation functions in much smaller space and hence easier to train. We evaluate our method on several public datasets and show that we generate results of better visual quality than previous state-of-the-art methods.
Instance Embedding Transfer to Unsupervised Video Object Segmentation
Feb 27, 2018

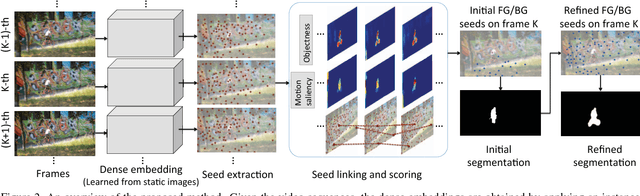

We propose a method for unsupervised video object segmentation by transferring the knowledge encapsulated in image-based instance embedding networks. The instance embedding network produces an embedding vector for each pixel that enables identifying all pixels belonging to the same object. Though trained on static images, the instance embeddings are stable over consecutive video frames, which allows us to link objects together over time. Thus, we adapt the instance networks trained on static images to video object segmentation and incorporate the embeddings with objectness and optical flow features, without model retraining or online fine-tuning. The proposed method outperforms state-of-the-art unsupervised segmentation methods in the DAVIS dataset and the FBMS dataset.
Multiple Instance Curriculum Learning for Weakly Supervised Object Detection
Nov 25, 2017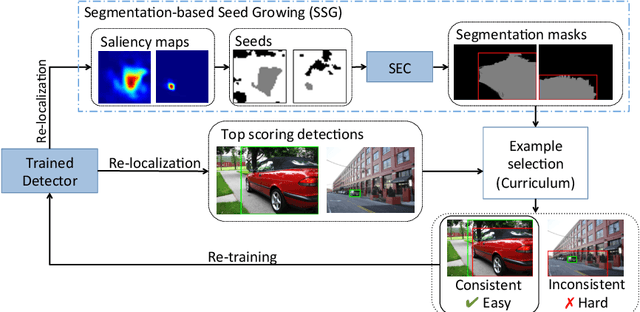

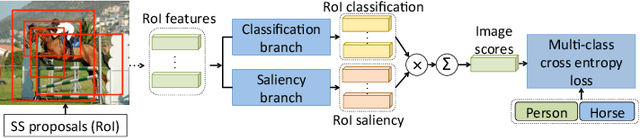

When supervising an object detector with weakly labeled data, most existing approaches are prone to trapping in the discriminative object parts, e.g., finding the face of a cat instead of the full body, due to lacking the supervision on the extent of full objects. To address this challenge, we incorporate object segmentation into the detector training, which guides the model to correctly localize the full objects. We propose the multiple instance curriculum learning (MICL) method, which injects curriculum learning (CL) into the multiple instance learning (MIL) framework. The MICL method starts by automatically picking the easy training examples, where the extent of the segmentation masks agree with detection bounding boxes. The training set is gradually expanded to include harder examples to train strong detectors that handle complex images. The proposed MICL method with segmentation in the loop outperforms the state-of-the-art weakly supervised object detectors by a substantial margin on the PASCAL VOC datasets.
A Taught-Obesrve-Ask Method for Object Detection with Critical Supervision
Nov 03, 2017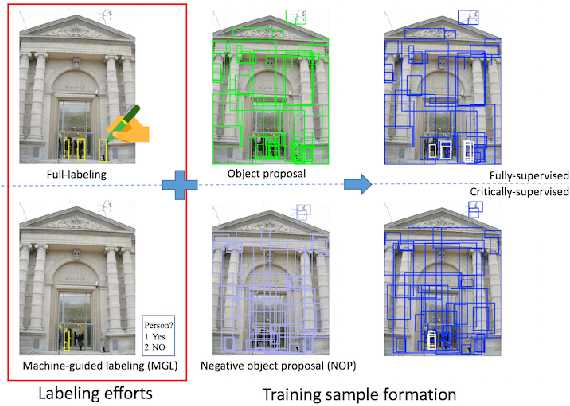

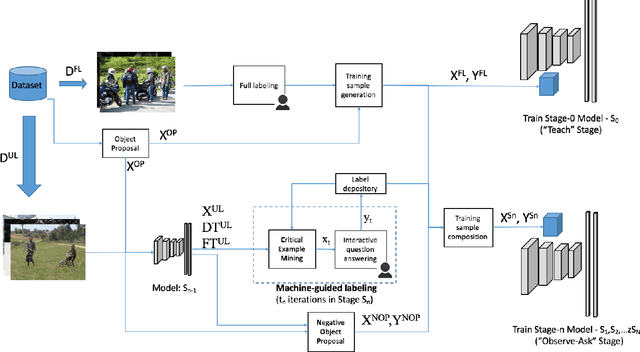

Being inspired by child's learning experience - taught first and followed by observation and questioning, we investigate a critically supervised learning methodology for object detection in this work. Specifically, we propose a taught-observe-ask (TOA) method that consists of several novel components such as negative object proposal, critical example mining, and machine-guided question-answer (QA) labeling. To consider labeling time and performance jointly, new evaluation methods are developed to compare the performance of the TOA method, with the fully and weakly supervised learning methods. Extensive experiments are conducted on the PASCAL VOC and the Caltech benchmark datasets. The TOA method provides significantly improved performance of weakly supervision yet demands only about 3-6% of labeling time of full supervision. The effectiveness of each novel component is also analyzed.
Semantic Segmentation with Reverse Attention
Jul 20, 2017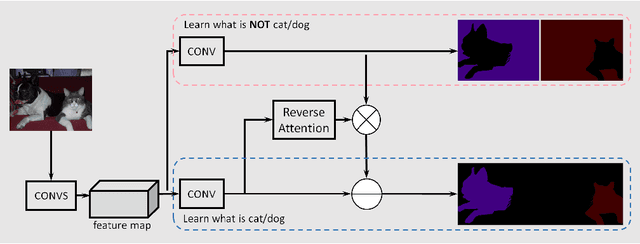
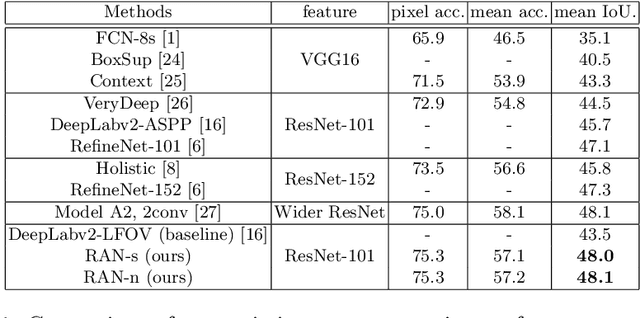
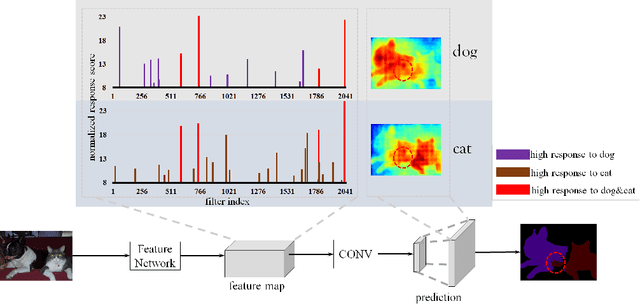
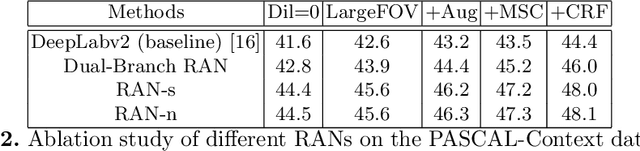
Recent development in fully convolutional neural network enables efficient end-to-end learning of semantic segmentation. Traditionally, the convolutional classifiers are taught to learn the representative semantic features of labeled semantic objects. In this work, we propose a reverse attention network (RAN) architecture that trains the network to capture the opposite concept (i.e., what are not associated with a target class) as well. The RAN is a three-branch network that performs the direct, reverse and reverse-attention learning processes simultaneously. Extensive experiments are conducted to show the effectiveness of the RAN in semantic segmentation. Being built upon the DeepLabv2-LargeFOV, the RAN achieves the state-of-the-art mIoU score (48.1%) for the challenging PASCAL-Context dataset. Significant performance improvements are also observed for the PASCAL-VOC, Person-Part, NYUDv2 and ADE20K datasets.
Object Boundary Guided Semantic Segmentation
Jul 06, 2016
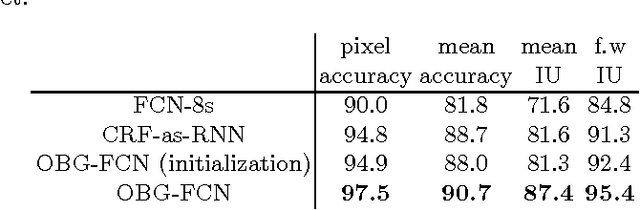

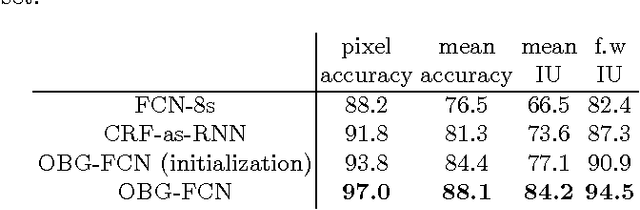
Semantic segmentation is critical to image content understanding and object localization. Recent development in fully-convolutional neural network (FCN) has enabled accurate pixel-level labeling. One issue in previous works is that the FCN based method does not exploit the object boundary information to delineate segmentation details since the object boundary label is ignored in the network training. To tackle this problem, we introduce a double branch fully convolutional neural network, which separates the learning of the desirable semantic class labeling with mask-level object proposals guided by relabeled boundaries. This network, called object boundary guided FCN (OBG-FCN), is able to integrate the distinct properties of object shape and class features elegantly in a fully convolutional way with a designed masking architecture. We conduct experiments on the PASCAL VOC segmentation benchmark, and show that the end-to-end trainable OBG-FCN system offers great improvement in optimizing the target semantic segmentation quality.