 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialFRED: Dialogue-Enabled Agents for Embodied Instruction Following
Feb 27, 2022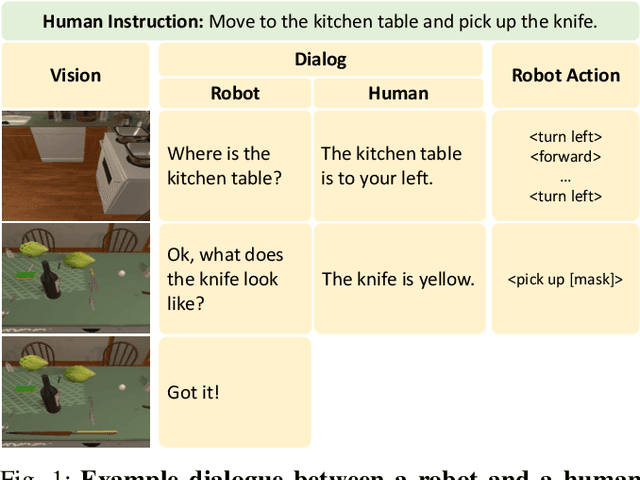


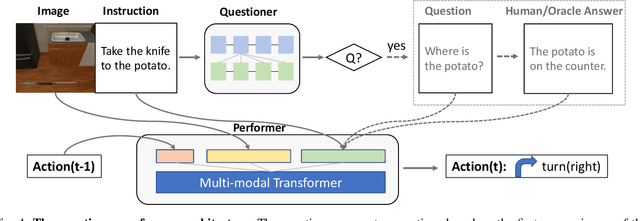
Language-guided Embodied AI benchmarks requiring an agent to navigate an environment and manipulate objects typically allow one-way communication: the human user gives a natural language command to the agent, and the agent can only follow the command passively. We present DialFRED, a dialogue-enabled embodied instruction following benchmark based on the ALFRED benchmark. DialFRED allows an agent to actively ask questions to the human user; the additional information in the user's response is used by the agent to better complete its task. We release a human-annotated dataset with 53K task-relevant questions and answers and an oracle to answer questions. To solve DialFRED, we propose a questioner-performer framework wherein the questioner is pre-trained with the human-annotated data and fine-tuned with reinforcement learning. We make DialFRED publicly available and encourage researchers to propose and evaluate their solutions to building dialog-enabled embodied agents.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022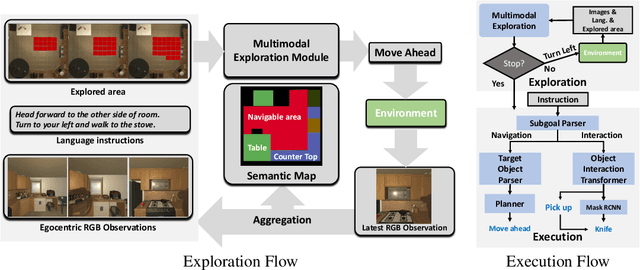

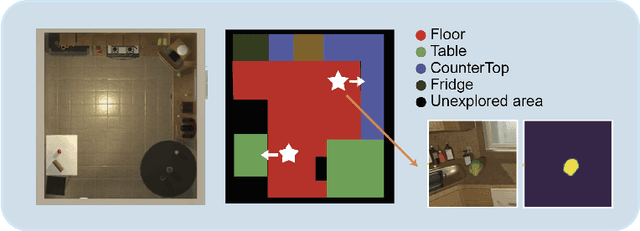
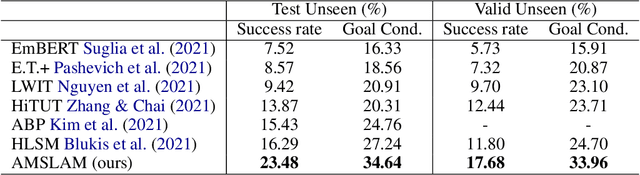
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
Best of Both Worlds: A Hybrid Approach for Multi-Hop Explanation with Declarative Facts
Dec 17, 2021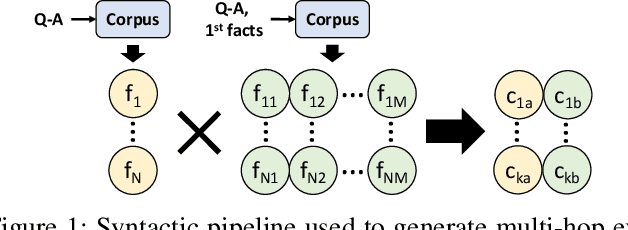
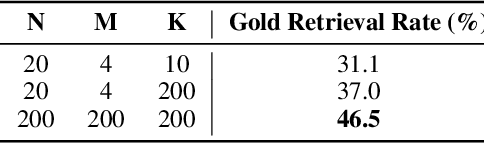
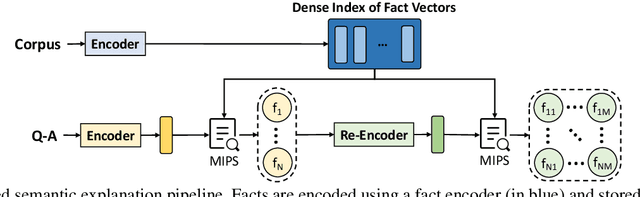
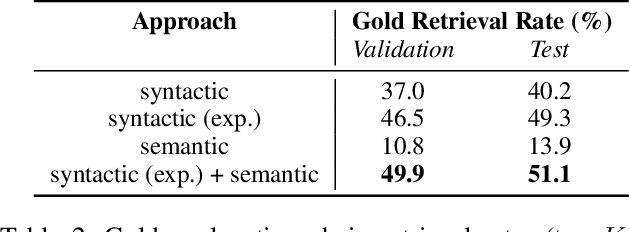
Language-enabled AI systems can answer complex, multi-hop questions to high accuracy, but supporting answers with evidence is a more challenging task which is important for the transparency and trustworthiness to users. Prior work in this area typically makes a trade-off between efficiency and accuracy; state-of-the-art deep neural network systems are too cumbersome to be useful in large-scale applications, while the fastest systems lack reliability. In this work, we integrate fast syntactic methods with powerful semantic methods for multi-hop explanation generation based on declarative facts. Our best system, which learns a lightweight operation to simulate multi-hop reasoning over pieces of evidence and fine-tunes language models to re-rank generated explanation chains, outperforms a purely syntactic baseline from prior work by up to 7% in gold explanation retrieval rate.
LUMINOUS: Indoor Scene Generation for Embodied AI Challenges
Nov 10, 2021

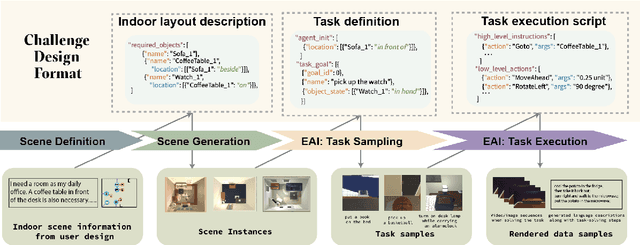
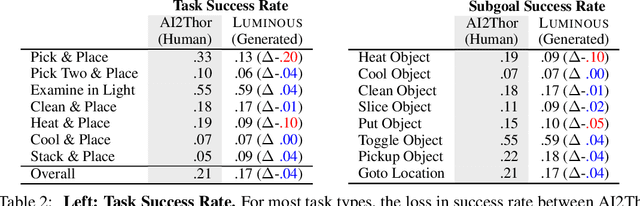
Learning-based methods for training embodied agents typically require a large number of high-quality scenes that contain realistic layouts and support meaningful interactions. However, current simulators for Embodied AI (EAI) challenges only provide simulated indoor scenes with a limited number of layouts. This paper presents Luminous, the first research framework that employs state-of-the-art indoor scene synthesis algorithms to generate large-scale simulated scenes for Embodied AI challenges. Further, we automatically and quantitatively evaluate the quality of generated indoor scenes via their ability to support complex household tasks. Luminous incorporates a novel scene generation algorithm (Constrained Stochastic Scene Generation (CSSG)), which achieves competitive performance with human-designed scenes. Within Luminous, the EAI task executor, task instruction generation module, and video rendering toolkit can collectively generate a massive multimodal dataset of new scenes for the training and evaluation of Embodied AI agents. Extensive experimental results demonstrate the effectiveness of the data generated by Luminous, enabling the comprehensive assessment of embodied agents on generalization and robustness.
Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding
Sep 10, 2021
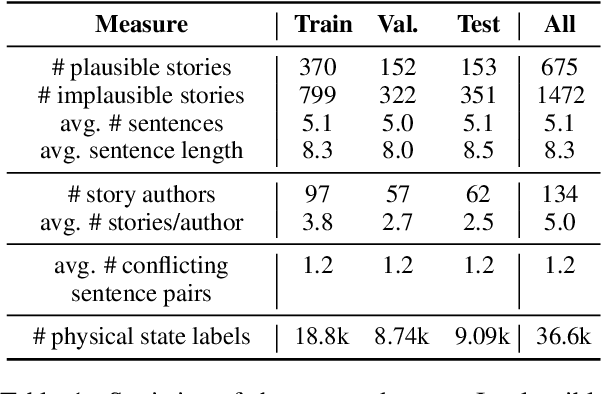
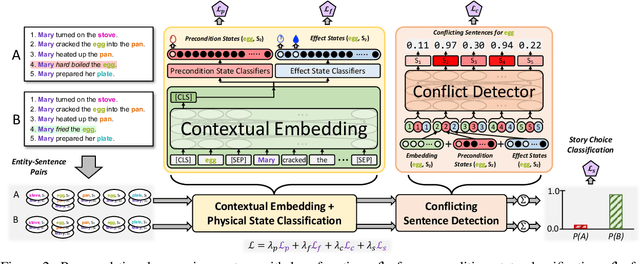
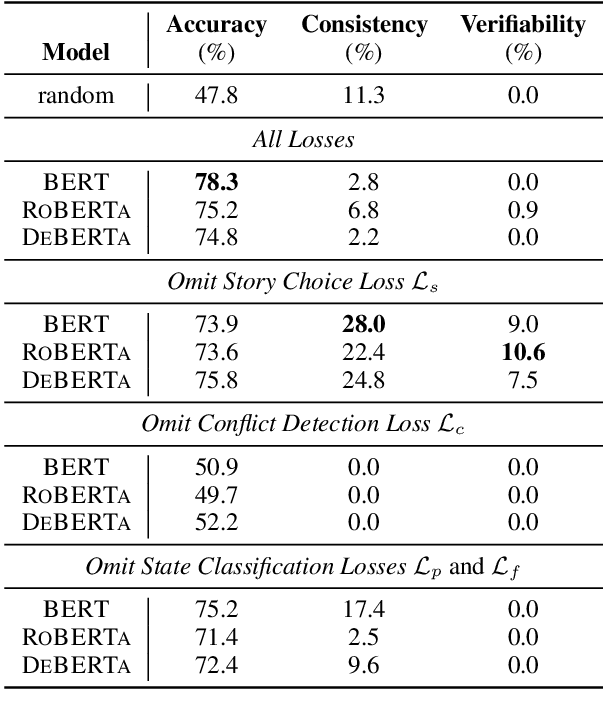
Large-scale, pre-trained language models (LMs) have achieved human-level performance on a breadth of language understanding tasks. However, evaluations only based on end task performance shed little light on machines' true ability in language understanding and reasoning. In this paper, we highlight the importance of evaluating the underlying reasoning process in addition to end performance. Toward this goal, we introduce Tiered Reasoning for Intuitive Physics (TRIP), a novel commonsense reasoning dataset with dense annotations that enable multi-tiered evaluation of machines' reasoning process. Our empirical results show that while large LMs can achieve high end performance, they struggle to support their predictions with valid supporting evidence. The TRIP dataset and our baseline results will motivate verifiable evaluation of commonsense reasoning and facilitate future research toward developing better language understanding and reasoning models.
Embodied BERT: A Transformer Model for Embodied, Language-guided Visual Task Completion
Aug 10, 2021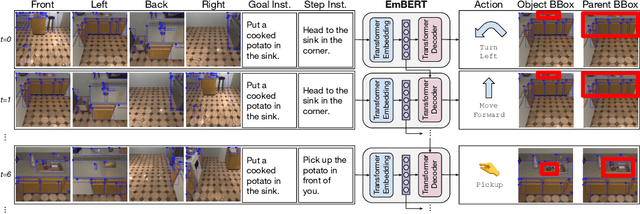

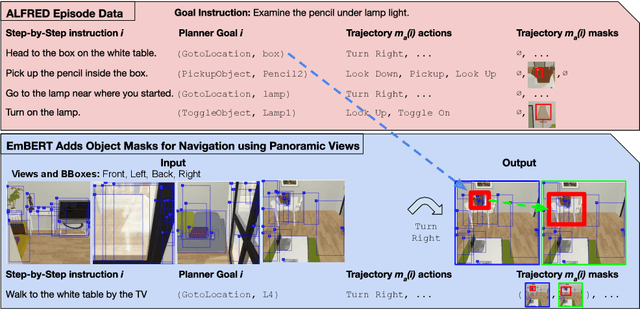
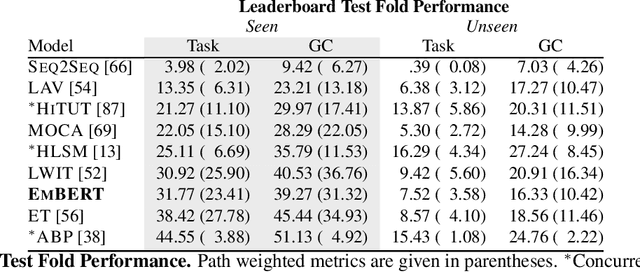
Language-guided robots performing home and office tasks must navigate in and interact with the world. Grounding language instructions against visual observations and actions to take in an environment is an open challenge. We present Embodied BERT (EmBERT), a transformer-based model which can attend to high-dimensional, multi-modal inputs across long temporal horizons for language-conditioned task completion. Additionally, we bridge the gap between successful object-centric navigation models used for non-interactive agents and the language-guided visual task completion benchmark, ALFRED, by introducing object navigation targets for EmBERT training. We achieve competitive performance on the ALFRED benchmark, and EmBERT marks the first transformer-based model to successfully handle the long-horizon, dense, multi-modal histories of ALFRED, and the first ALFRED model to utilize object-centric navigation targets.
Are We There Yet? Learning to Localize in Embodied Instruction Following
Jan 09, 2021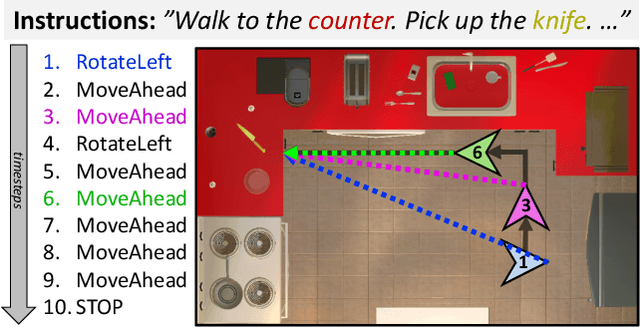
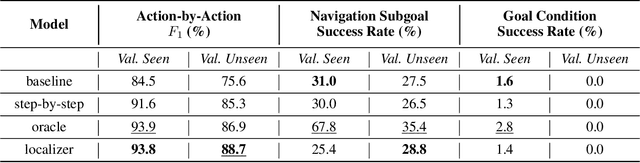
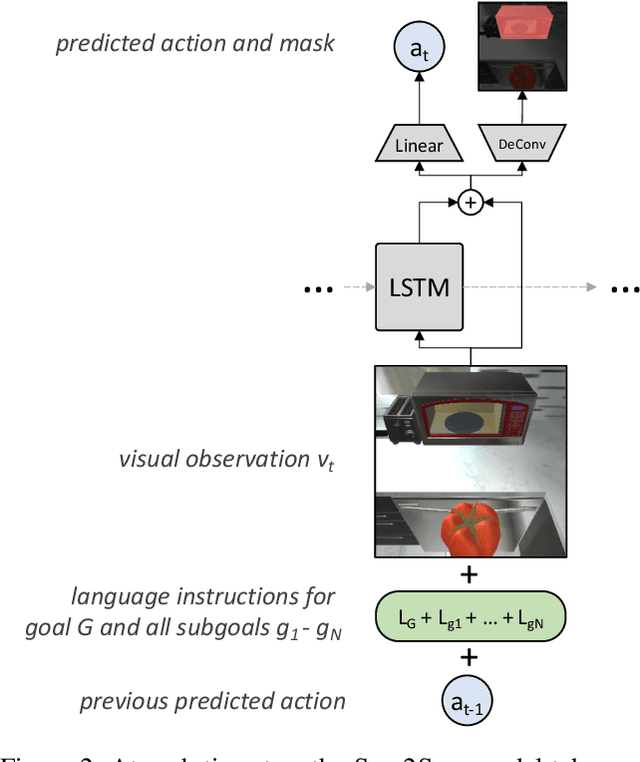
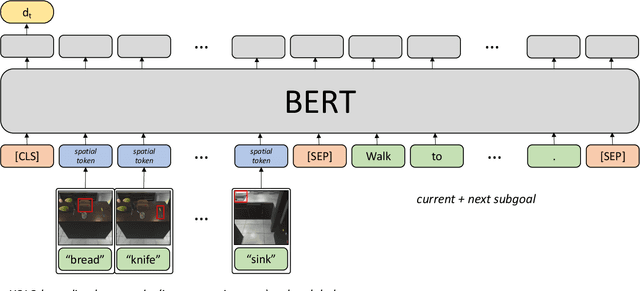
Embodied instruction following is a challenging problem requiring an agent to infer a sequence of primitive actions to achieve a goal environment state from complex language and visual inputs. Action Learning From Realistic Environments and Directives (ALFRED) is a recently proposed benchmark for this problem consisting of step-by-step natural language instructions to achieve subgoals which compose to an ultimate high-level goal. Key challenges for this task include localizing target locations and navigating to them through visual inputs, and grounding language instructions to visual appearance of objects. To address these challenges, in this study, we augment the agent's field of view during navigation subgoals with multiple viewing angles, and train the agent to predict its relative spatial relation to the target location at each timestep. We also improve language grounding by introducing a pre-trained object detection module to the model pipeline. Empirical studies show that our approach exceeds the baseline model performance.
Interactive Teaching for Conversational AI
Dec 02, 2020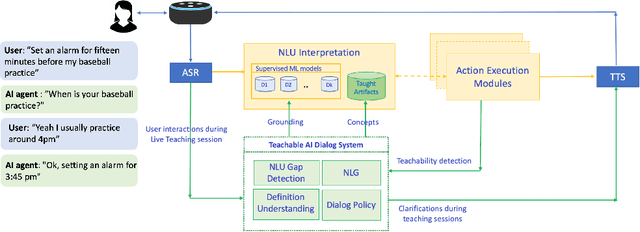
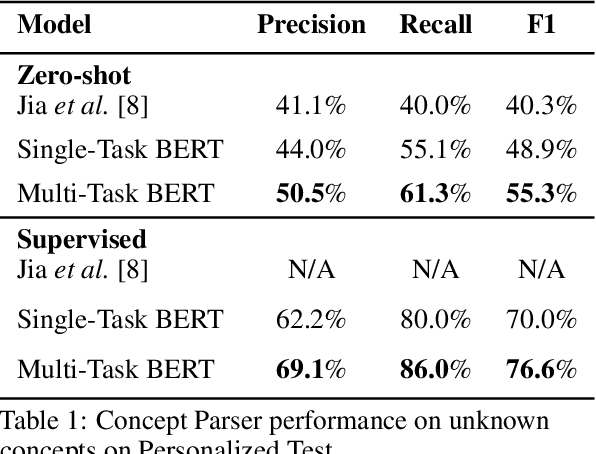
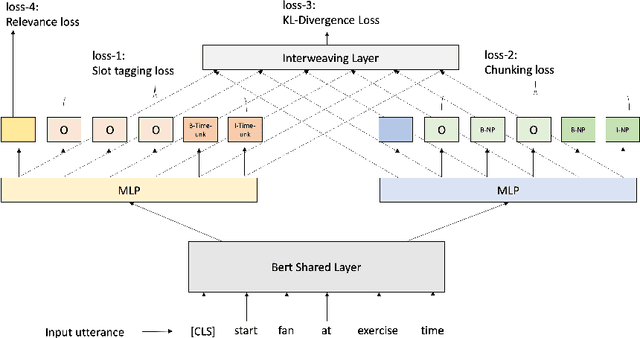
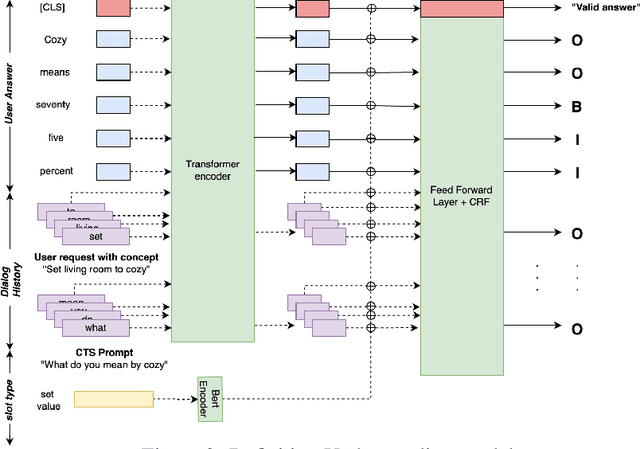
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.
Commonsense Reasoning for Natural Language Understanding: A Survey of Benchmarks, Resources, and Approaches
Apr 02, 2019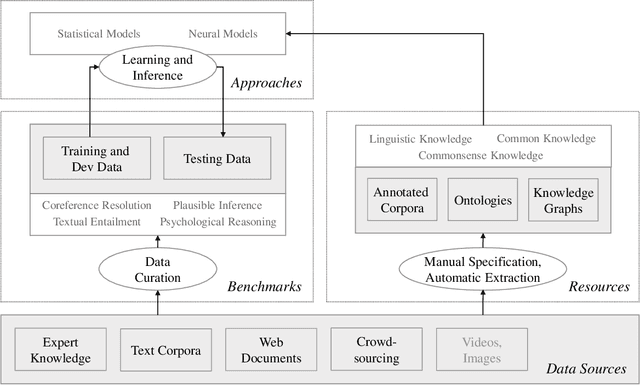
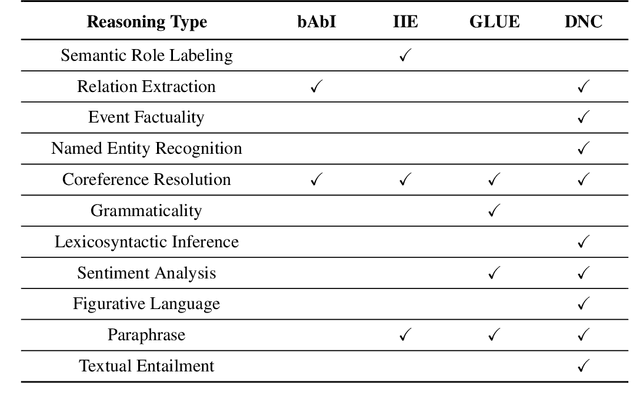
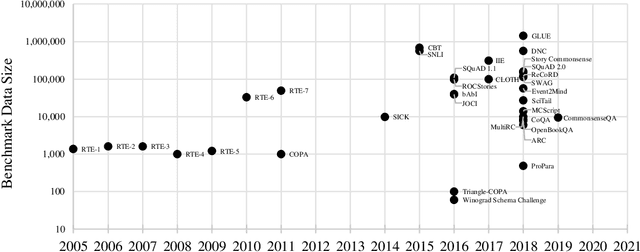
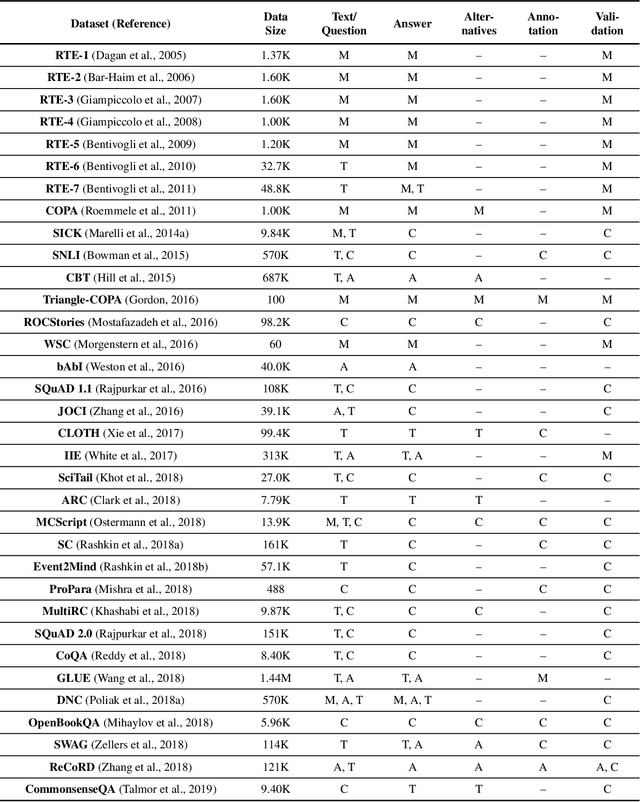
Commonsense knowledge and commonsense reasoning are some of the main bottlenecks in machine intelligence. In the NLP community, many benchmark datasets and tasks have been created to address commonsense reasoning for language understanding. These tasks are designed to assess machines' ability to acquire and learn commonsense knowledge in order to reason and understand natural language text. As these tasks become instrumental and a driving force for commonsense research, this paper aims to provide an overview of existing tasks and benchmarks, knowledge resources, and learning and inference approaches toward commonsense reasoning for natural language understanding. Through this, our goal is to support a better understanding of the state of the art, its limitations, and future challenges.
Interactive Learning of State Representation through Natural Language Instruction and Explanation
Oct 07, 2017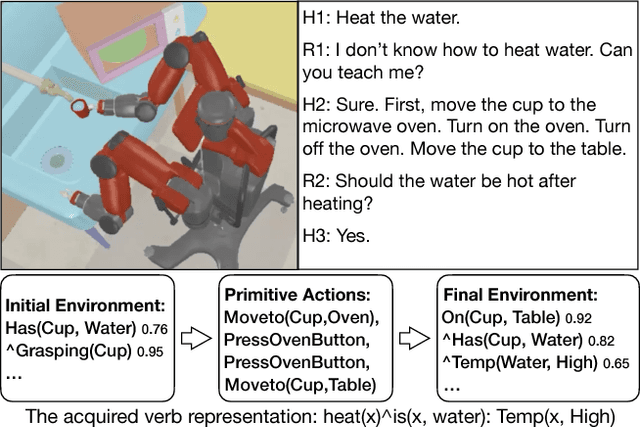
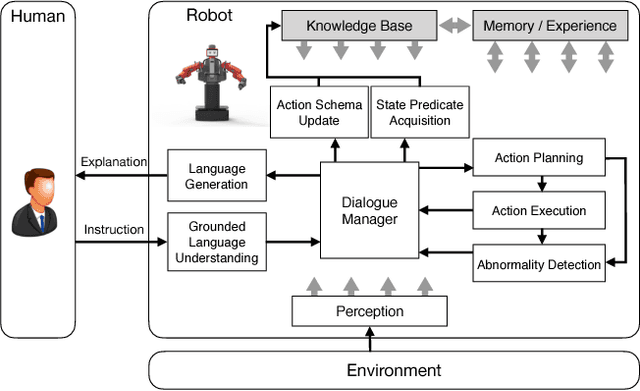

One significant simplification in most previous work on robot learning is the closed-world assumption where the robot is assumed to know ahead of time a complete set of predicates describing the state of the physical world. However, robots are not likely to have a complete model of the world especially when learning a new task. To address this problem, this extended abstract gives a brief introduction to our on-going work that aims to enable the robot to acquire new state representations through language communication with humans.