 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop memorizing: A data-dependent regularization framework for intrinsic pattern learning
Sep 23, 2018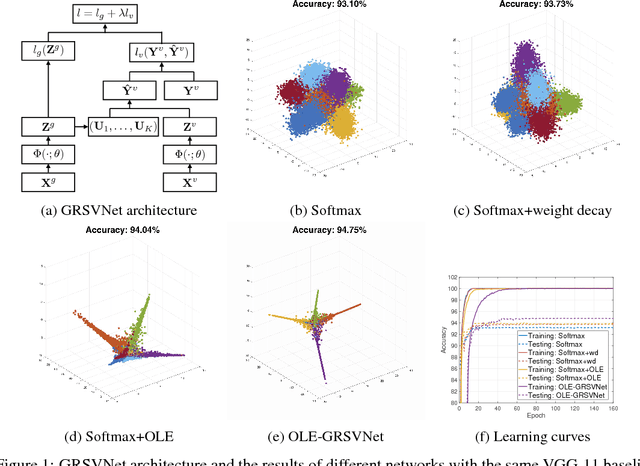

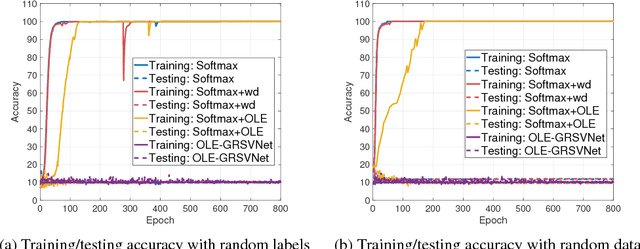
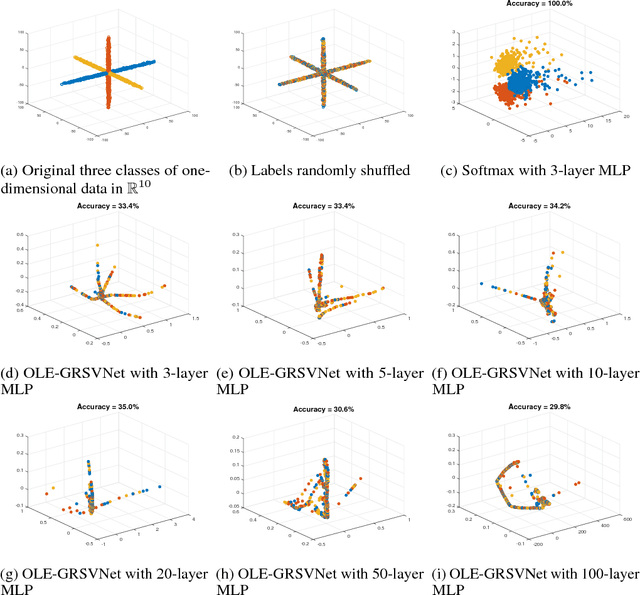
Deep neural networks (DNNs) typically have enough capacity to fit random data by brute force even when conventional data-dependent regularizations focusing on the geometry of the features are imposed. We find out that the reason for this is the inconsistency between the enforced geometry and the standard softmax cross entropy loss. To resolve this, we propose a new framework for data-dependent DNN regularization, the Geometrically-Regularized-Self-Validating neural Networks (GRSVNet). During training, the geometry enforced on one batch of features is simultaneously validated on a separate batch using a validation loss consistent with the geometry. We study a particular case of GRSVNet, the Orthogonal-Low-rank Embedding (OLE)-GRSVNet, which is capable of producing highly discriminative features residing in orthogonal low-rank subspaces. Numerical experiments show that OLE-GRSVNet outperforms DNNs with conventional regularization when trained on real data. More importantly, unlike conventional DNNs, OLE-GRSVNet refuses to memorize random data or random labels, suggesting it only learns intrinsic patterns by reducing the memorizing capacity of the baseline DNN.
In Defense of Single-column Networks for Crowd Counting
Aug 18, 2018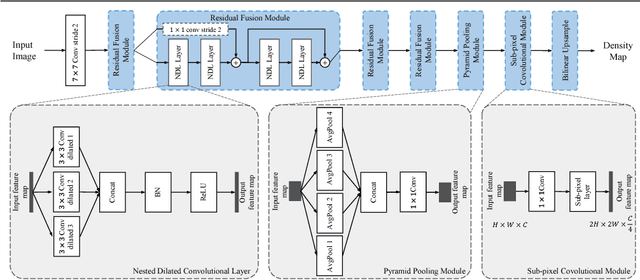


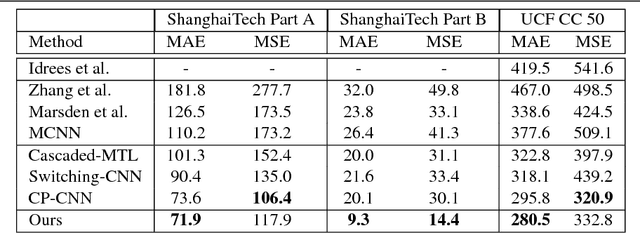
Crowd counting usually addressed by density estimation becomes an increasingly important topic in computer vision due to its widespread applications in video surveillance, urban planning, and intelligence gathering. However, it is essentially a challenging task because of the greatly varied sizes of objects, coupled with severe occlusions and vague appearance of extremely small individuals. Existing methods heavily rely on multi-column learning architectures to extract multi-scale features, which however suffer from heavy computational cost, especially undesired for crowd counting. In this paper, we propose the single-column counting network (SCNet) for efficient crowd counting without relying on multi-column networks. SCNet consists of residual fusion modules (RFMs) for multi-scale feature extraction, a pyramid pooling module (PPM) for information fusion, and a sub-pixel convolutional module (SPCM) followed by a bilinear upsampling layer for resolution recovery. Those proposed modules enable our SCNet to fully capture multi-scale features in a compact single-column architecture and estimate high-resolution density map in an efficient way. In addition, we provide a principled paradigm for density map generation and data augmentation for training, which shows further improved performance. Extensive experiments on three benchmark datasets show that our SCNet delivers new state-of-the-art performance and surpasses previous methods by large margins, which demonstrates the great effectiveness of SCNet as a single-column network for crowd counting.
ForestHash: Semantic Hashing With Shallow Random Forests and Tiny Convolutional Networks
Jul 28, 2018

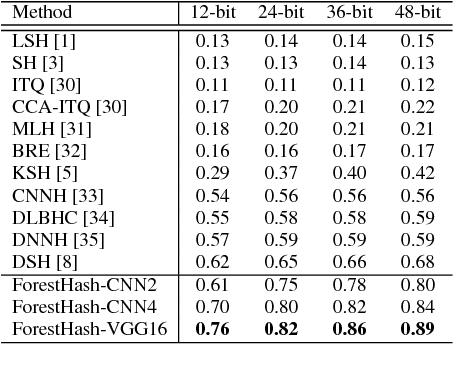
Hash codes are efficient data representations for coping with the ever growing amounts of data. In this paper, we introduce a random forest semantic hashing scheme that embeds tiny convolutional neural networks (CNN) into shallow random forests, with near-optimal information-theoretic code aggregation among trees. We start with a simple hashing scheme, where random trees in a forest act as hashing functions by setting `1' for the visited tree leaf, and `0' for the rest. We show that traditional random forests fail to generate hashes that preserve the underlying similarity between the trees, rendering the random forests approach to hashing challenging. To address this, we propose to first randomly group arriving classes at each tree split node into two groups, obtaining a significantly simplified two-class classification problem, which can be handled using a light-weight CNN weak learner. Such random class grouping scheme enables code uniqueness by enforcing each class to share its code with different classes in different trees. A non-conventional low-rank loss is further adopted for the CNN weak learners to encourage code consistency by minimizing intra-class variations and maximizing inter-class distance for the two random class groups. Finally, we introduce an information-theoretic approach for aggregating codes of individual trees into a single hash code, producing a near-optimal unique hash for each class. The proposed approach significantly outperforms state-of-the-art hashing methods for image retrieval tasks on large-scale public datasets, while performing at the level of other state-of-the-art image classification techniques while utilizing a more compact and efficient scalable representation. This work proposes a principled and robust procedure to train and deploy in parallel an ensemble of light-weight CNNs, instead of simply going deeper.
DCFNet: Deep Neural Network with Decomposed Convolutional Filters
Jul 27, 2018

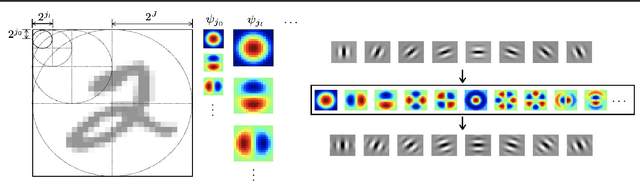

Filters in a Convolutional Neural Network (CNN) contain model parameters learned from enormous amounts of data. In this paper, we suggest to decompose convolutional filters in CNN as a truncated expansion with pre-fixed bases, namely the Decomposed Convolutional Filters network (DCFNet), where the expansion coefficients remain learned from data. Such a structure not only reduces the number of trainable parameters and computation, but also imposes filter regularity by bases truncation. Through extensive experiments, we consistently observe that DCFNet maintains accuracy for image classification tasks with a significant reduction of model parameters, particularly with Fourier-Bessel (FB) bases, and even with random bases. Theoretically, we analyze the representation stability of DCFNet with respect to input variations, and prove representation stability under generic assumptions on the expansion coefficients. The analysis is consistent with the empirical observations.
LaneNet: Real-Time Lane Detection Networks for Autonomous Driving
Jul 04, 2018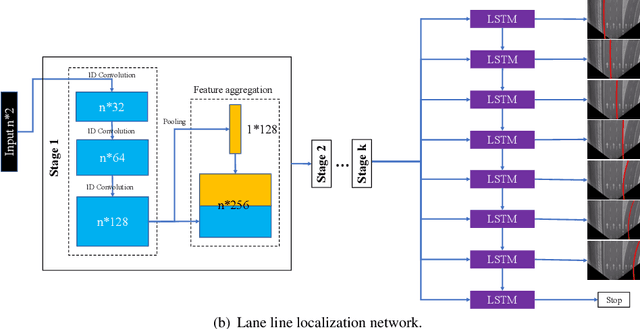
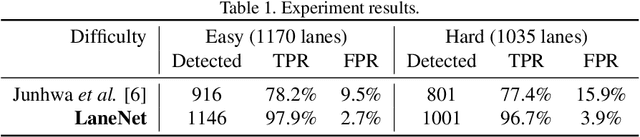


Lane detection is to detect lanes on the road and provide the accurate location and shape of each lane. It severs as one of the key techniques to enable modern assisted and autonomous driving systems. However, several unique properties of lanes challenge the detection methods. The lack of distinctive features makes lane detection algorithms tend to be confused by other objects with similar local appearance. Moreover, the inconsistent number of lanes on a road as well as diverse lane line patterns, e.g. solid, broken, single, double, merging, and splitting lines further hamper the performance. In this paper, we propose a deep neural network based method, named LaneNet, to break down the lane detection into two stages: lane edge proposal and lane line localization. Stage one uses a lane edge proposal network for pixel-wise lane edge classification, and the lane line localization network in stage two then detects lane lines based on lane edge proposals. Please note that the goal of our LaneNet is built to detect lane line only, which introduces more difficulties on suppressing the false detections on the similar lane marks on the road like arrows and characters. Despite all the difficulties, our lane detection is shown to be robust to both highway and urban road scenarios method without relying on any assumptions on the lane number or the lane line patterns. The high running speed and low computational cost endow our LaneNet the capability of being deployed on vehicle-based systems. Experiments validate that our LaneNet consistently delivers outstanding performances on real world traffic scenarios.
Learning to Collaborate for User-Controlled Privacy
May 18, 2018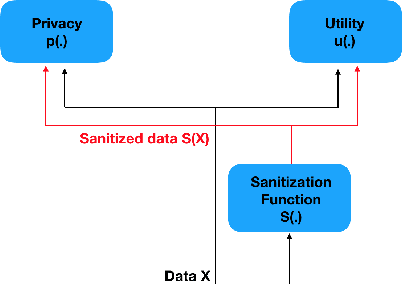
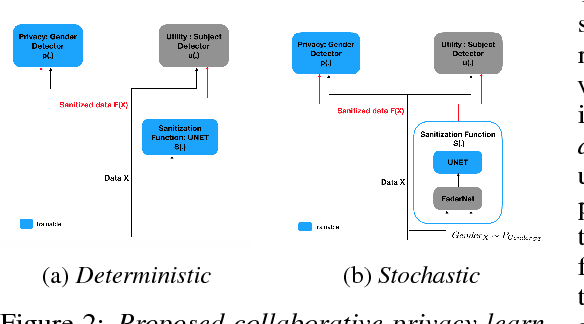
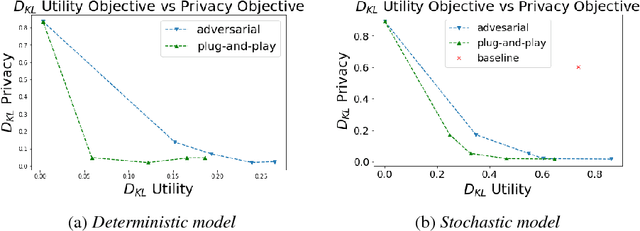
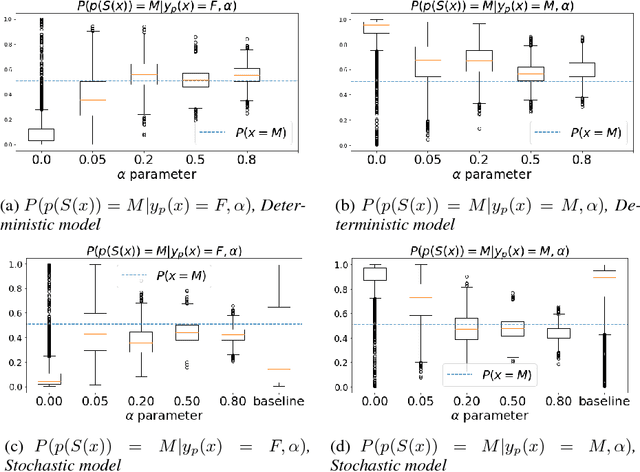
It is becoming increasingly clear that users should own and control their data. Utility providers are also becoming more interested in guaranteeing data privacy. As such, users and utility providers should collaborate in data privacy, a paradigm that has not yet been developed in the privacy research community. We introduce this concept and present explicit architectures where the user controls what characteristics of the data she/he wants to share and what she/he wants to keep private. This is achieved by collaborative learning a sensitization function, either a deterministic or a stochastic one, that retains valuable information for the utility tasks but it also eliminates necessary information for the privacy ones. As illustration examples, we implement them using a plug-and-play approach, where no algorithm is changed at the system provider end, and an adversarial approach, where minor re-training of the privacy inferring engine is allowed. In both cases the learned sanitization function keeps the data in the original domain, thereby allowing the system to use the same algorithms it was using before for both original and privatized data. We show how we can maintain utility while fully protecting private information if the user chooses to do so, even when the first is harder than the second, as in the case here illustrated of identity detection while hiding gender.
RotDCF: Decomposition of Convolutional Filters for Rotation-Equivariant Deep Networks
May 17, 2018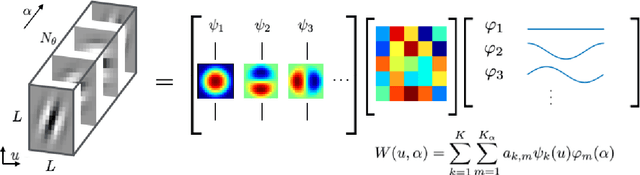

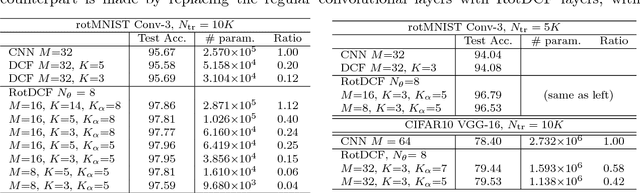

Explicit encoding of group actions in deep features makes it possible for convolutional neural networks (CNNs) to handle global deformations of images, which is critical to success in many vision tasks. This paper proposes to decompose the convolutional filters over joint steerable bases across the space and the group geometry simultaneously, namely a rotation-equivariant CNN with decomposed convolutional filters (RotDCF). This decomposition facilitates computing the joint convolution, which is proved to be necessary for the group equivariance. It significantly reduces the model size and computational complexity while preserving performance, and truncation of the bases expansion serves implicitly to regularize the filters. On datasets involving in-plane and out-of-plane object rotations, RotDCF deep features demonstrate greater robustness and interpretability than regular CNNs. The stability of the equivariant representation to input variations is also proved theoretically under generic assumptions on the filters in the decomposed form. The RotDCF framework can be extended to groups other than rotations, providing a general approach which achieves both group equivariance and representation stability at a reduced model size.
Liveness Detection Using Implicit 3D Features
Apr 19, 2018
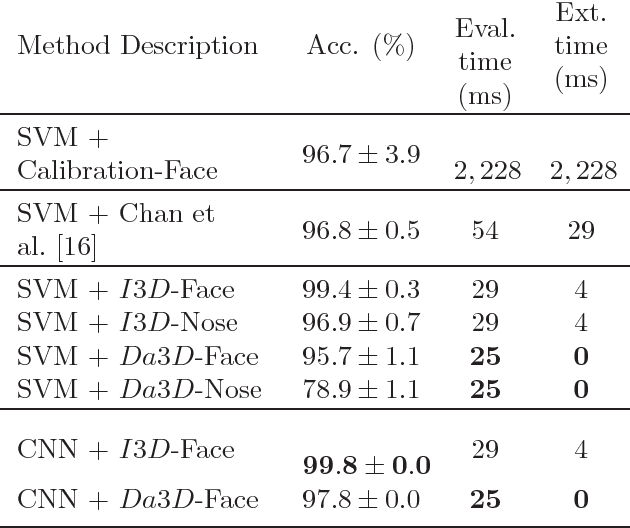


Spoofing attacks are a threat to modern face recognition systems. In this work we present a simple yet effective liveness detection approach to enhance 2D face recognition methods and make them robust against spoofing attacks. We show that the risk to spoofing attacks can be re- duced through the use of an additional source of light, for example a flash. From a pair of input images taken under different illumination, we define discriminative features that implicitly contain facial three-dimensional in- formation. Furthermore, we show that when multiple sources of light are considered, we are able to validate which one has been activated. This makes possible the design of a highly secure active-light authentication framework. Finally, further investigating the use of 3D features without 3D reconstruction, we introduce an approximated disparity-based implicit 3D feature obtained from an uncalibrated stereo-pair of cameras. Valida- tion experiments show that the proposed methods produce state-of-the-art results in challenging scenarios with nearly no feature extraction latency.
Weakly Supervised Instance Segmentation using Class Peak Response
Apr 03, 2018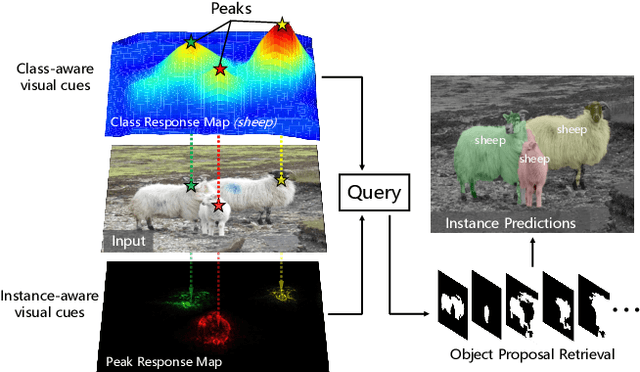
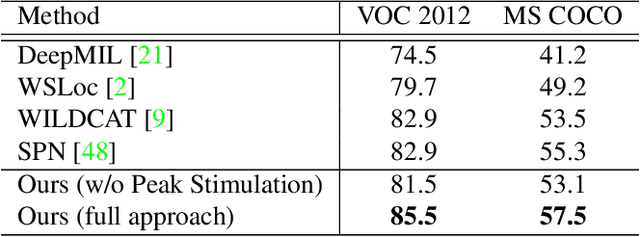

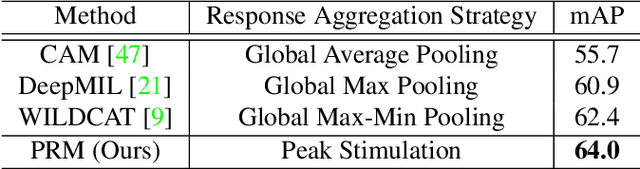
Weakly supervised instance segmentation with image-level labels, instead of expensive pixel-level masks, remains unexplored. In this paper, we tackle this challenging problem by exploiting class peak responses to enable a classification network for instance mask extraction. With image labels supervision only, CNN classifiers in a fully convolutional manner can produce class response maps, which specify classification confidence at each image location. We observed that local maximums, i.e., peaks, in a class response map typically correspond to strong visual cues residing inside each instance. Motivated by this, we first design a process to stimulate peaks to emerge from a class response map. The emerged peaks are then back-propagated and effectively mapped to highly informative regions of each object instance, such as instance boundaries. We refer to the above maps generated from class peak responses as Peak Response Maps (PRMs). PRMs provide a fine-detailed instance-level representation, which allows instance masks to be extracted even with some off-the-shelf methods. To the best of our knowledge, we for the first time report results for the challenging image-level supervised instance segmentation task. Extensive experiments show that our method also boosts weakly supervised pointwise localization as well as semantic segmentation performance, and reports state-of-the-art results on popular benchmarks, including PASCAL VOC 2012 and MS COCO.
Virtual CNN Branching: Efficient Feature Ensemble for Person Re-Identification
Mar 15, 2018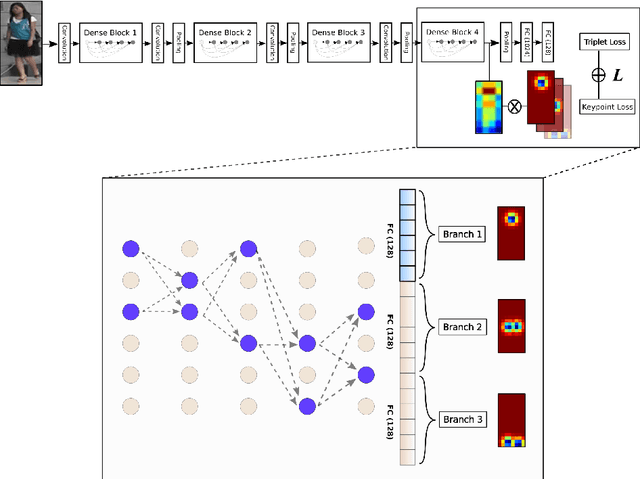
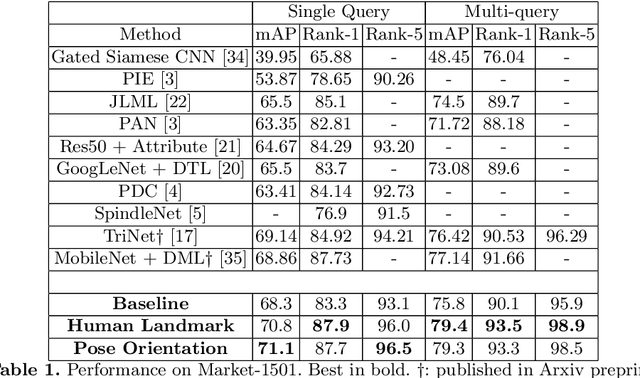

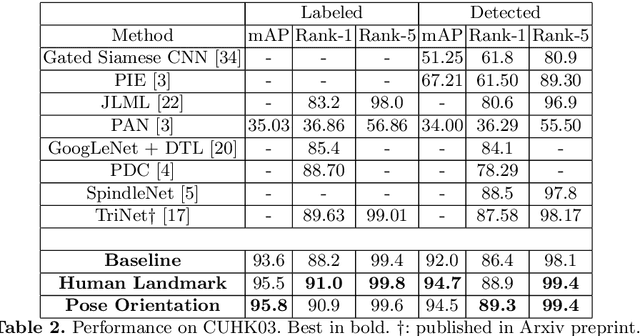
In this paper we introduce an ensemble method for convolutional neural network (CNN), called "virtual branching," which can be implemented with nearly no additional parameters and computation on top of standard CNNs. We propose our method in the context of person re-identification (re-ID). Our CNN model consists of shared bottom layers, followed by "virtual" branches, where neurons from a block of regular convolutional and fully-connected layers are partitioned into multiple sets. Each virtual branch is trained with different data to specialize in different aspects, e.g., a specific body region or pose orientation. In this way, robust ensemble representations are obtained against human body misalignment, deformations, or variations in viewing angles, at nearly no any additional cost. The proposed method achieves competitive performance on multiple person re-ID benchmark datasets, including Market-1501, CUHK03, and DukeMTMC-reID.