 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Conditional Neural Processes
Nov 30, 2022



The Conditional Neural Process (CNP) family of models offer a promising direction to tackle few-shot problems by achieving better scalability and competitive predictive performance. However, the current CNP models only capture the overall uncertainty for the prediction made on a target data point. They lack a systematic fine-grained quantification on the distinct sources of uncertainty that are essential for model training and decision-making under the few-shot setting. We propose Evidential Conditional Neural Processes (ECNP), which replace the standard Gaussian distribution used by CNP with a much richer hierarchical Bayesian structure through evidential learning to achieve epistemic-aleatoric uncertainty decomposition. The evidential hierarchical structure also leads to a theoretically justified robustness over noisy training tasks. Theoretical analysis on the proposed ECNP establishes the relationship with CNP while offering deeper insights on the roles of the evidential parameters. Extensive experiments conducted on both synthetic and real-world data demonstrate the effectiveness of our proposed model in various few-shot settings.
Towards Open Set Video Anomaly Detection
Aug 23, 2022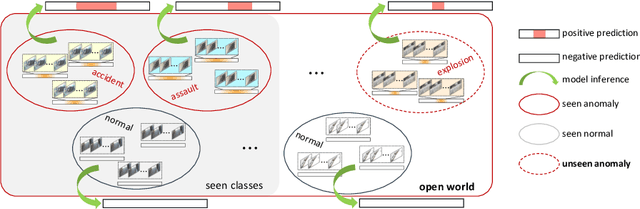
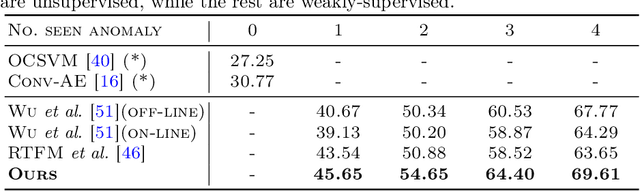
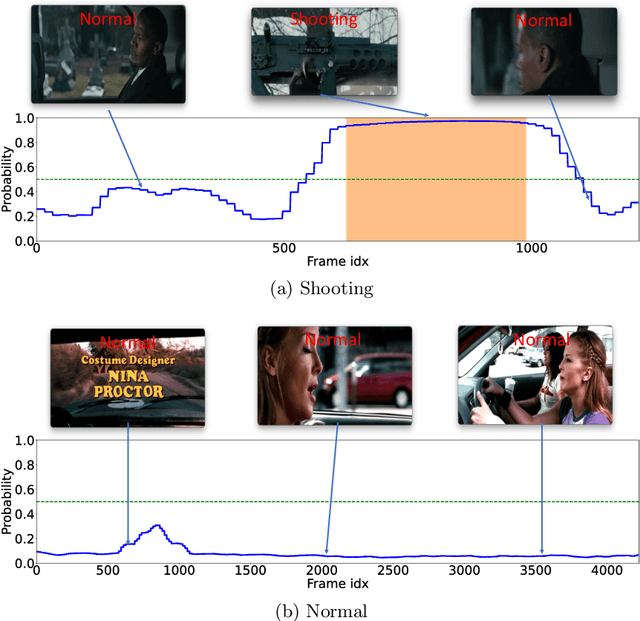
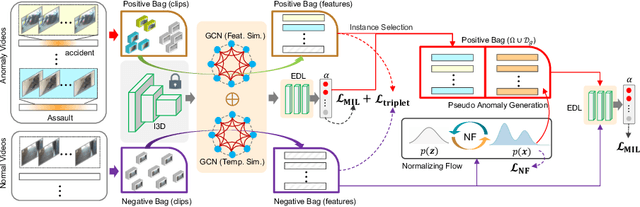
Open Set Video Anomaly Detection (OpenVAD) aims to identify abnormal events from video data where both known anomalies and novel ones exist in testing. Unsupervised models learned solely from normal videos are applicable to any testing anomalies but suffer from a high false positive rate. In contrast, weakly supervised methods are effective in detecting known anomalies but could fail in an open world. We develop a novel weakly supervised method for the OpenVAD problem by integrating evidential deep learning (EDL) and normalizing flows (NFs) into a multiple instance learning (MIL) framework. Specifically, we propose to use graph neural networks and triplet loss to learn discriminative features for training the EDL classifier, where the EDL is capable of identifying the unknown anomalies by quantifying the uncertainty. Moreover, we develop an uncertainty-aware selection strategy to obtain clean anomaly instances and a NFs module to generate the pseudo anomalies. Our method is superior to existing approaches by inheriting the advantages of both the unsupervised NFs and the weakly-supervised MIL framework. Experimental results on multiple real-world video datasets show the effectiveness of our method.
Scaling Up Dynamic Graph Representation Learning via Spiking Neural Networks
Aug 15, 2022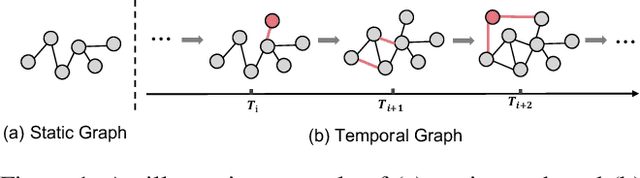
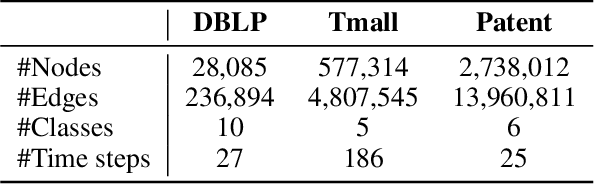
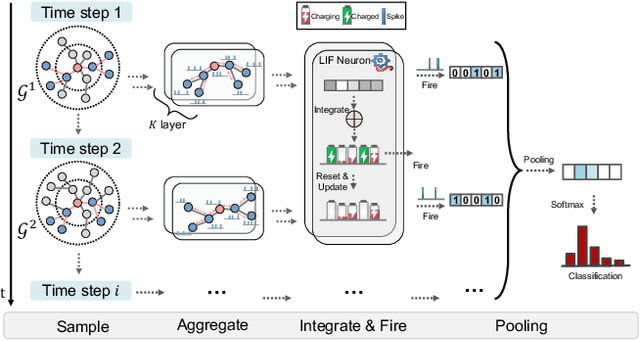
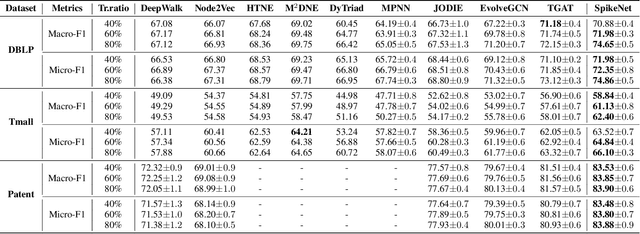
Recent years have seen a surge in research on dynamic graph representation learning, which aims to model temporal graphs that are dynamic and evolving constantly over time. However, current work typically models graph dynamics with recurrent neural networks (RNNs), making them suffer seriously from computation and memory overheads on large temporal graphs. So far, scalability of dynamic graph representation learning on large temporal graphs remains one of the major challenges. In this paper, we present a scalable framework, namely SpikeNet, to efficiently capture the temporal and structural patterns of temporal graphs. We explore a new direction in that we can capture the evolving dynamics of temporal graphs with spiking neural networks (SNNs) instead of RNNs. As a low-power alternative to RNNs, SNNs explicitly model graph dynamics as spike trains of neuron populations and enable spike-based propagation in an efficient way. Experiments on three large real-world temporal graph datasets demonstrate that SpikeNet outperforms strong baselines on the temporal node classification task with lower computational costs. Particularly, SpikeNet generalizes to a large temporal graph (2M nodes and 13M edges) with significantly fewer parameters and computation overheads. Our code is publicly available at https://github.com/EdisonLeeeee/SpikeNet
Balancing Bias and Variance for Active Weakly Supervised Learning
Jun 12, 2022
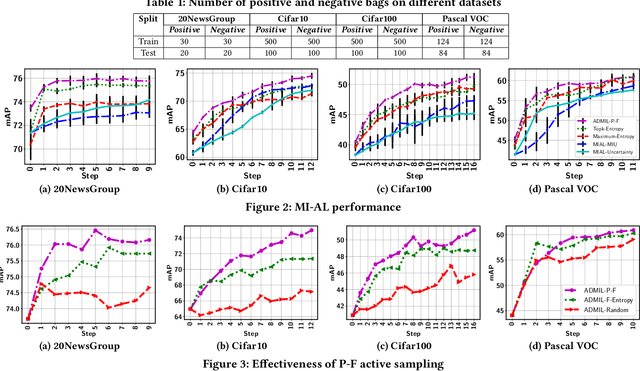
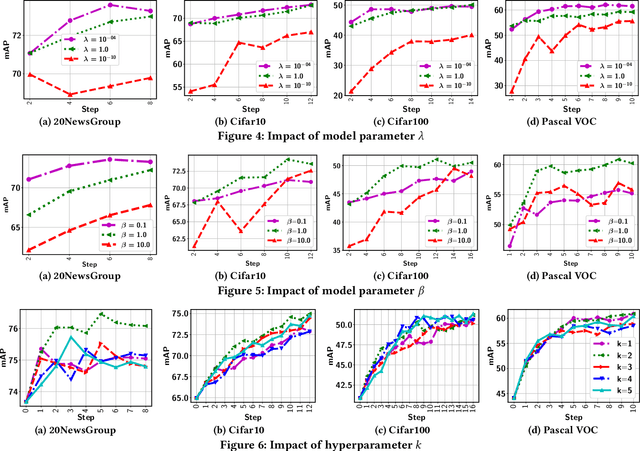

As a widely used weakly supervised learning scheme, modern multiple instance learning (MIL) models achieve competitive performance at the bag level. However, instance-level prediction, which is essential for many important applications, remains largely unsatisfactory. We propose to conduct novel active deep multiple instance learning that samples a small subset of informative instances for annotation, aiming to significantly boost the instance-level prediction. A variance regularized loss function is designed to properly balance the bias and variance of instance-level predictions, aiming to effectively accommodate the highly imbalanced instance distribution in MIL and other fundamental challenges. Instead of directly minimizing the variance regularized loss that is non-convex, we optimize a distributionally robust bag level likelihood as its convex surrogate. The robust bag likelihood provides a good approximation of the variance based MIL loss with a strong theoretical guarantee. It also automatically balances bias and variance, making it effective to identify the potentially positive instances to support active sampling. The robust bag likelihood can be naturally integrated with a deep architecture to support deep model training using mini-batches of positive-negative bag pairs. Finally, a novel P-F sampling function is developed that combines a probability vector and predicted instance scores, obtained by optimizing the robust bag likelihood. By leveraging the key MIL assumption, the sampling function can explore the most challenging bags and effectively detect their positive instances for annotation, which significantly improves the instance-level prediction. Experiments conducted over multiple real-world datasets clearly demonstrate the state-of-the-art instance-level prediction achieved by the proposed model.
Spiking Graph Convolutional Networks
May 05, 2022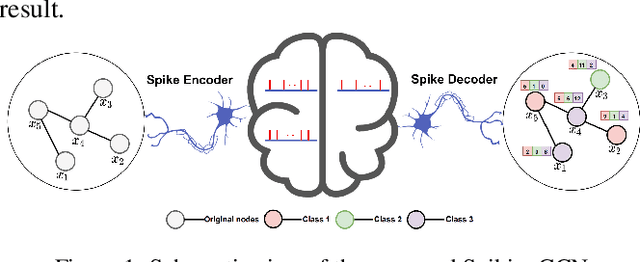
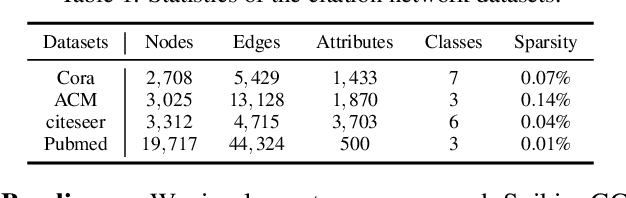
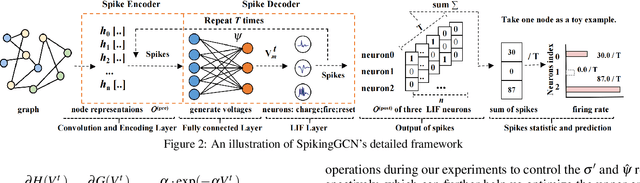
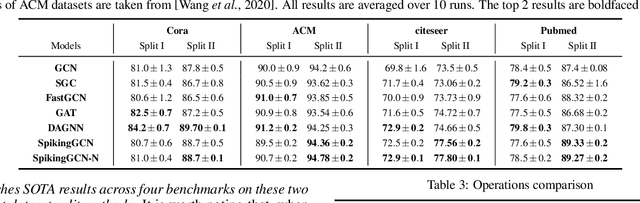
Graph Convolutional Networks (GCNs) achieve an impressive performance due to the remarkable representation ability in learning the graph information. However, GCNs, when implemented on a deep network, require expensive computation power, making them difficult to be deployed on battery-powered devices. In contrast, Spiking Neural Networks (SNNs), which perform a bio-fidelity inference process, offer an energy-efficient neural architecture. In this work, we propose SpikingGCN, an end-to-end framework that aims to integrate the embedding of GCNs with the biofidelity characteristics of SNNs. The original graph data are encoded into spike trains based on the incorporation of graph convolution. We further model biological information processing by utilizing a fully connected layer combined with neuron nodes. In a wide range of scenarios (e.g. citation networks, image graph classification, and recommender systems), our experimental results show that the proposed method could gain competitive performance against state-of-the-art approaches. Furthermore, we show that SpikingGCN on a neuromorphic chip can bring a clear advantage of energy efficiency into graph data analysis, which demonstrates its great potential to construct environment-friendly machine learning models.
A Dynamic Meta-Learning Model for Time-Sensitive Cold-Start Recommendations
Apr 03, 2022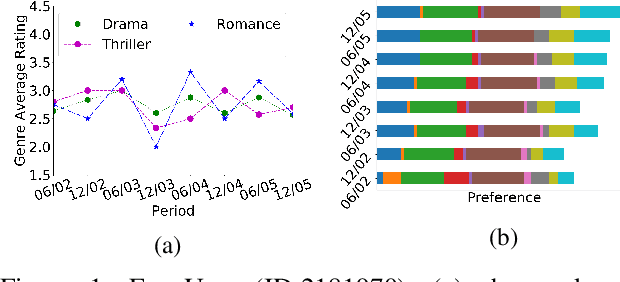
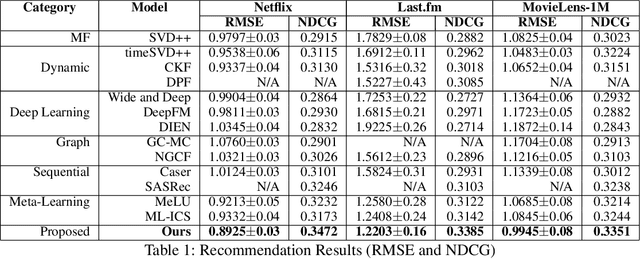
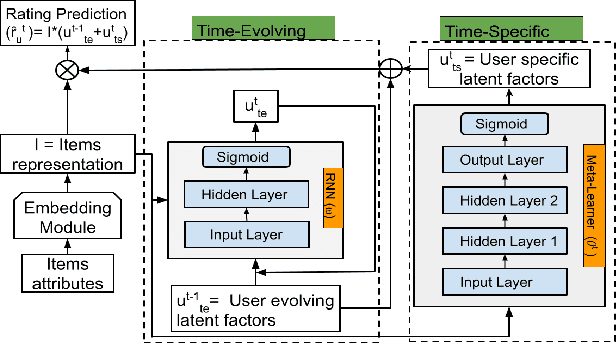
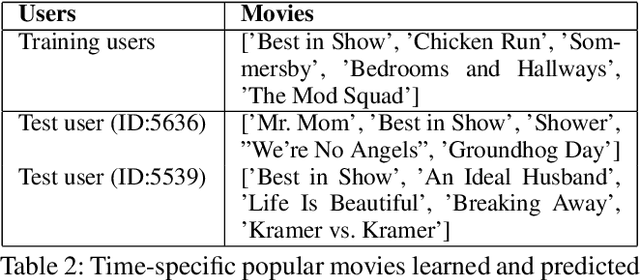
We present a novel dynamic recommendation model that focuses on users who have interactions in the past but turn relatively inactive recently. Making effective recommendations to these time-sensitive cold-start users is critical to maintain the user base of a recommender system. Due to the sparse recent interactions, it is challenging to capture these users' current preferences precisely. Solely relying on their historical interactions may also lead to outdated recommendations misaligned with their recent interests. The proposed model leverages historical and current user-item interactions and dynamically factorizes a user's (latent) preference into time-specific and time-evolving representations that jointly affect user behaviors. These latent factors further interact with an optimized item embedding to achieve accurate and timely recommendations. Experiments over real-world data help demonstrate the effectiveness of the proposed time-sensitive cold-start recommendation model.
Bayesian Nonparametric Submodular Video Partition for Robust Anomaly Detection
Mar 24, 2022
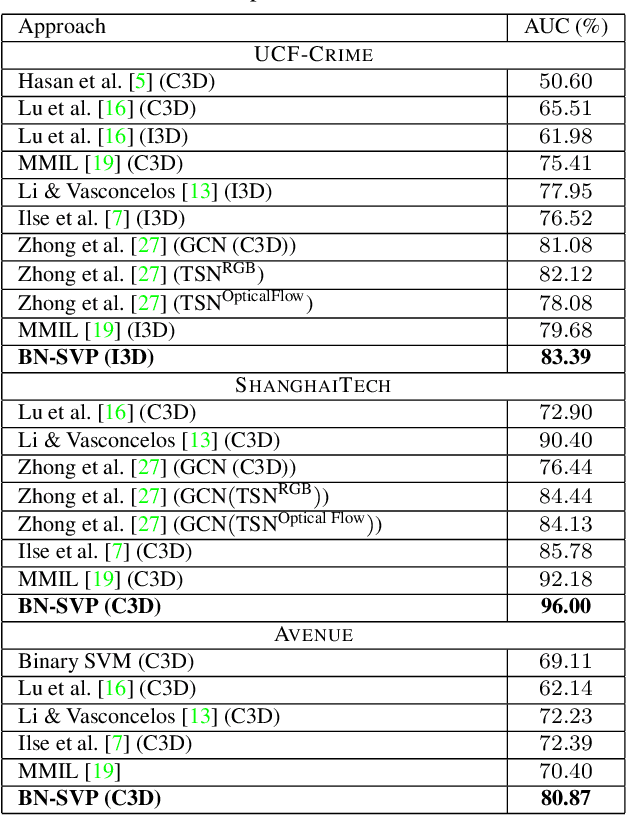
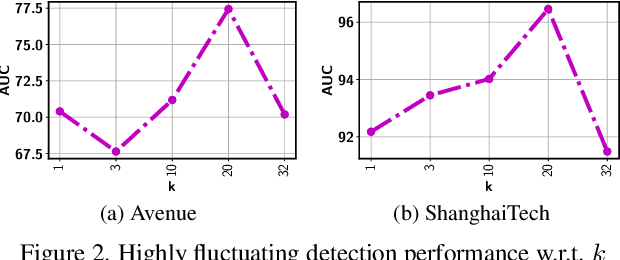

Multiple-instance learning (MIL) provides an effective way to tackle the video anomaly detection problem by modeling it as a weakly supervised problem as the labels are usually only available at the video level while missing for frames due to expensive labeling cost. We propose to conduct novel Bayesian non-parametric submodular video partition (BN-SVP) to significantly improve MIL model training that can offer a highly reliable solution for robust anomaly detection in practical settings that include outlier segments or multiple types of abnormal events. BN-SVP essentially performs dynamic non-parametric hierarchical clustering with an enhanced self-transition that groups segments in a video into temporally consistent and semantically coherent hidden states that can be naturally interpreted as scenes. Each segment is assumed to be generated through a non-parametric mixture process that allows variations of segments within the same scenes to accommodate the dynamic and noisy nature of many real-world surveillance videos. The scene and mixture component assignment of BN-SVP also induces a pairwise similarity among segments, resulting in non-parametric construction of a submodular set function. Integrating this function with an MIL loss effectively exposes the model to a diverse set of potentially positive instances to improve its training. A greedy algorithm is developed to optimize the submodular function and support efficient model training. Our theoretical analysis ensures a strong performance guarantee of the proposed algorithm. The effectiveness of the proposed approach is demonstrated over multiple real-world anomaly video datasets with robust detection performance.
Multidimensional Belief Quantification for Label-Efficient Meta-Learning
Mar 23, 2022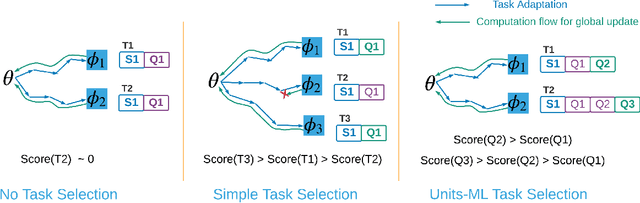
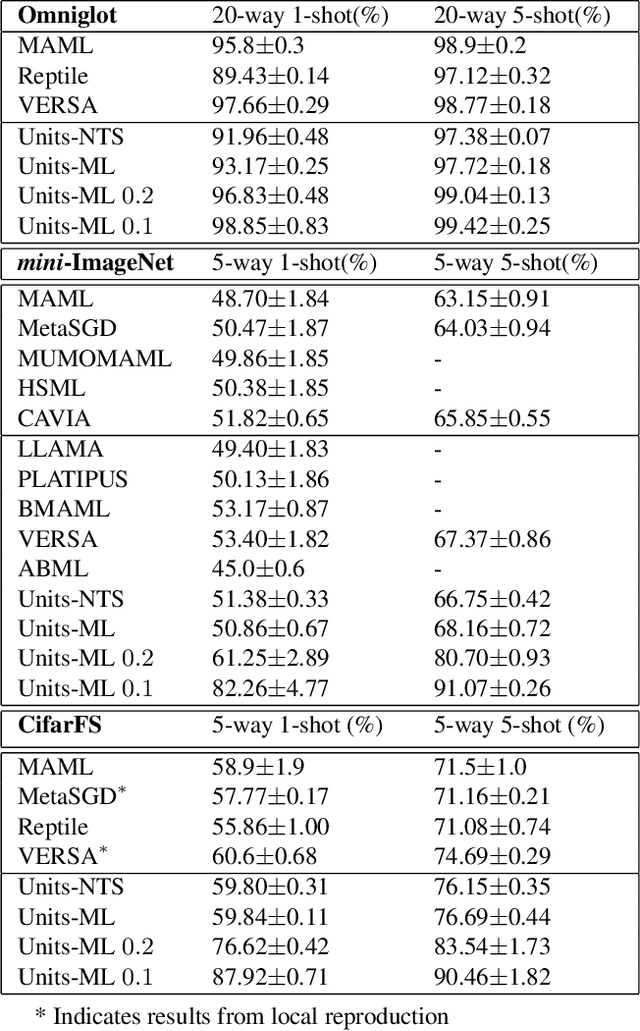
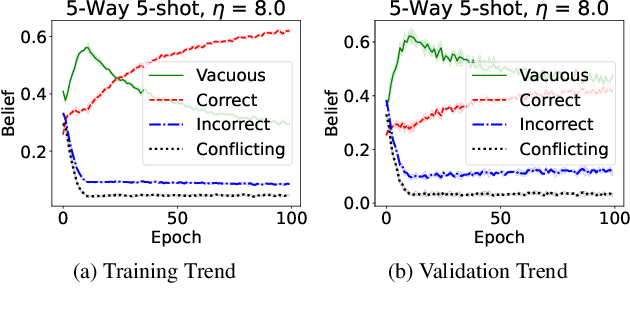
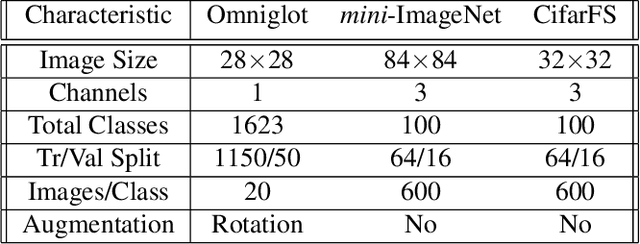
Optimization-based meta-learning offers a promising direction for few-shot learning that is essential for many real-world computer vision applications. However, learning from few samples introduces uncertainty, and quantifying model confidence for few-shot predictions is essential for many critical domains. Furthermore, few-shot tasks used in meta training are usually sampled randomly from a task distribution for an iterative model update, leading to high labeling costs and computational overhead in meta-training. We propose a novel uncertainty-aware task selection model for label efficient meta-learning. The proposed model formulates a multidimensional belief measure, which can quantify the known uncertainty and lower bound the unknown uncertainty of any given task. Our theoretical result establishes an important relationship between the conflicting belief and the incorrect belief. The theoretical result allows us to estimate the total uncertainty of a task, which provides a principled criterion for task selection. A novel multi-query task formulation is further developed to improve both the computational and labeling efficiency of meta-learning. Experiments conducted over multiple real-world few-shot image classification tasks demonstrate the effectiveness of the proposed model.
OpenTAL: Towards Open Set Temporal Action Localization
Mar 10, 2022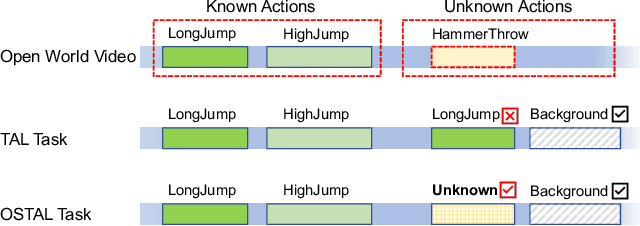

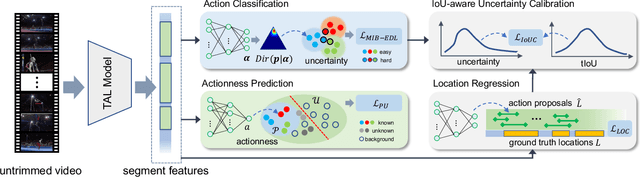

Temporal Action Localization (TAL) has experienced remarkable success under the supervised learning paradigm. However, existing TAL methods are rooted in the closed set assumption, which cannot handle the inevitable unknown actions in open-world scenarios. In this paper, we, for the first time, step toward the Open Set TAL (OSTAL) problem and propose a general framework OpenTAL based on Evidential Deep Learning (EDL). Specifically, the OpenTAL consists of uncertainty-aware action classification, actionness prediction, and temporal location regression. With the proposed importance-balanced EDL method, classification uncertainty is learned by collecting categorical evidence majorly from important samples. To distinguish the unknown actions from background video frames, the actionness is learned by the positive-unlabeled learning. The classification uncertainty is further calibrated by leveraging the guidance from the temporal localization quality. The OpenTAL is general to enable existing TAL models for open set scenarios, and experimental results on THUMOS14 and ActivityNet1.3 benchmarks show the effectiveness of our method. The code and pre-trained models are released at https://www.rit.edu/actionlab/opental.
Deep Reinforced Attention Regression for Partial Sketch Based Image Retrieval
Nov 21, 2021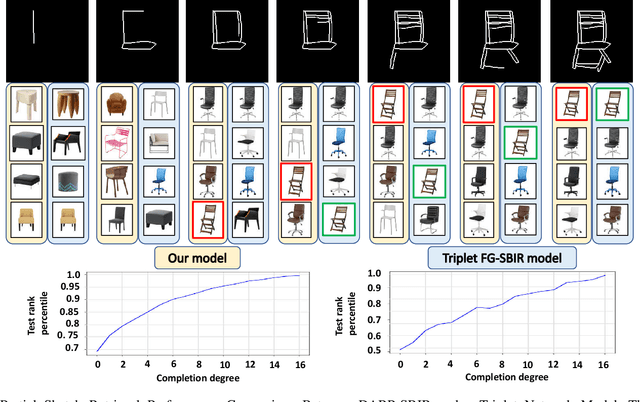
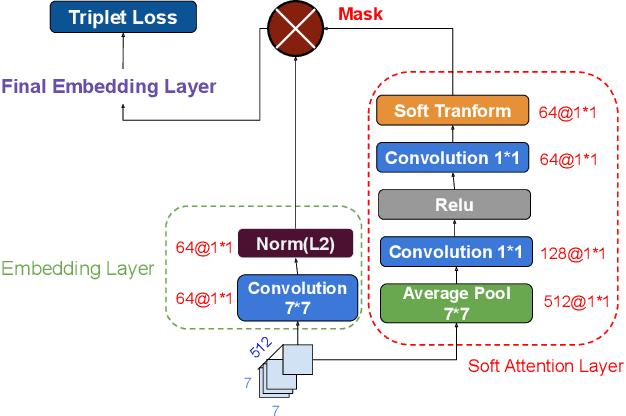
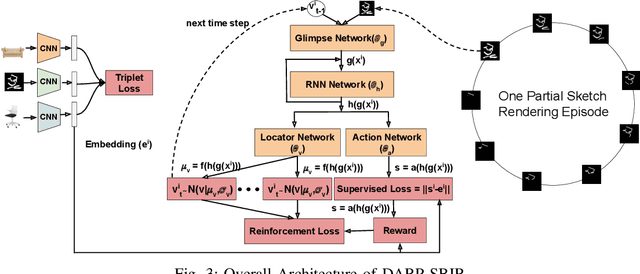
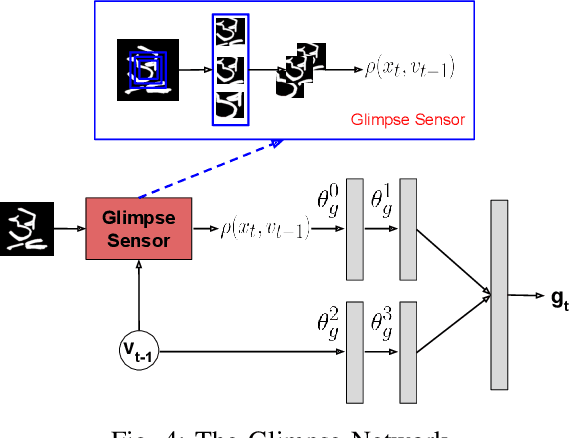
Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) aims at finding a specific image from a large gallery given a query sketch. Despite the widespread applicability of FG-SBIR in many critical domains (e.g., crime activity tracking), existing approaches still suffer from a low accuracy while being sensitive to external noises such as unnecessary strokes in the sketch. The retrieval performance will further deteriorate under a more practical on-the-fly setting, where only a partially complete sketch with only a few (noisy) strokes are available to retrieve corresponding images. We propose a novel framework that leverages a uniquely designed deep reinforcement learning model that performs a dual-level exploration to deal with partial sketch training and attention region selection. By enforcing the model's attention on the important regions of the original sketches, it remains robust to unnecessary stroke noises and improve the retrieval accuracy by a large margin. To sufficiently explore partial sketches and locate the important regions to attend, the model performs bootstrapped policy gradient for global exploration while adjusting a standard deviation term that governs a locator network for local exploration. The training process is guided by a hybrid loss that integrates a reinforcement loss and a supervised loss. A dynamic ranking reward is developed to fit the on-the-fly image retrieval process using partial sketches. The extensive experimentation performed on three public datasets shows that our proposed approach achieves the state-of-the-art performance on partial sketch based image retrieval.