 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushpak Bhattacharyya
Relation extraction between the clinical entities based on the shortest dependency path based LSTM
Mar 24, 2019
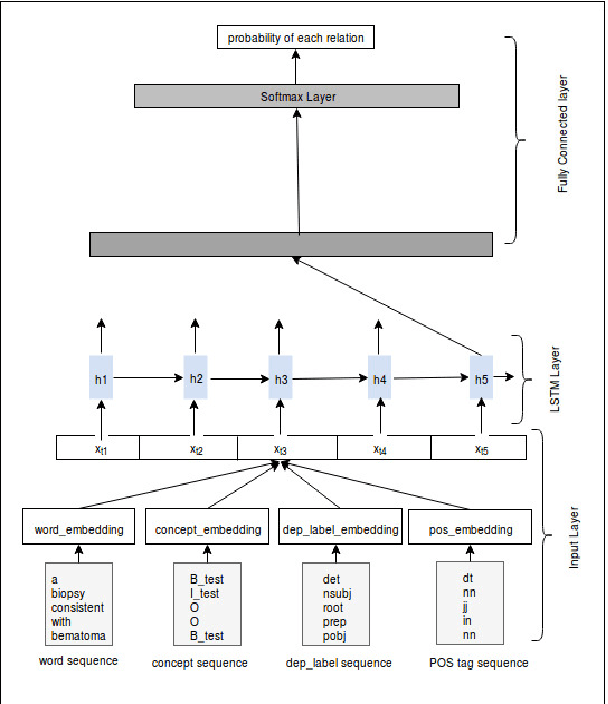

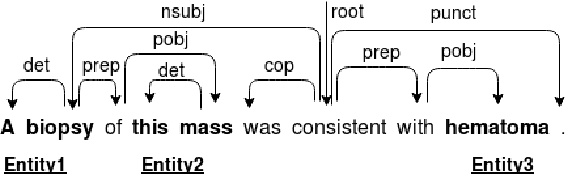
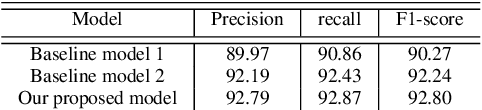
Owing to the exponential rise in the electronic medical records, information extraction in this domain is becoming an important area of research in recent years. Relation extraction between the medical concepts such as medical problem, treatment, and test etc. is also one of the most important tasks in this area. In this paper, we present an efficient relation extraction system based on the shortest dependency path (SDP) generated from the dependency parsed tree of the sentence. Instead of relying on many handcrafted features and the whole sequence of tokens present in a sentence, our system relies only on the SDP between the target entities. For every pair of entities, the system takes only the words in the SDP, their dependency labels, Part-of-Speech information and the types of the entities as the input. We develop a dependency parser for extracting dependency information. We perform our experiments on the benchmark i2b2 dataset for clinical relation extraction challenge 2010. Experimental results show that our system outperforms the existing systems.
A Deep Ensemble Framework for Fake News Detection and Classification
Nov 12, 2018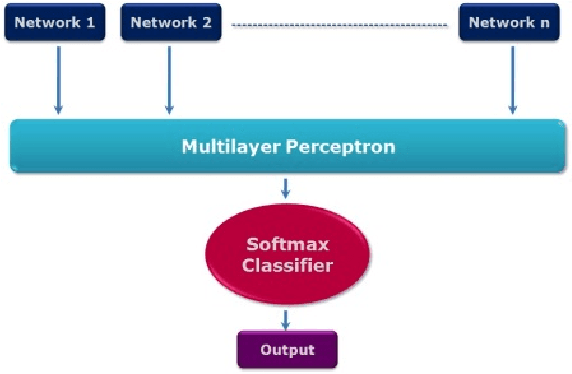
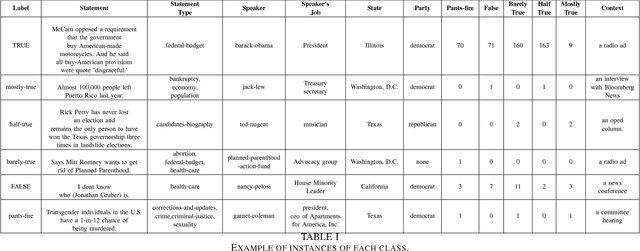
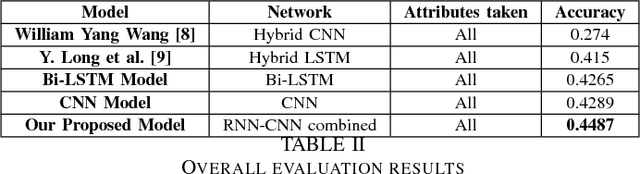
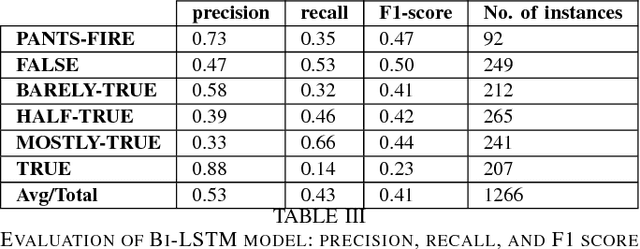
Fake news, rumor, incorrect information, and misinformation detection are nowadays crucial issues as these might have serious consequences for our social fabrics. The rate of such information is increasing rapidly due to the availability of enormous web information sources including social media feeds, news blogs, online newspapers etc. In this paper, we develop various deep learning models for detecting fake news and classifying them into the pre-defined fine-grained categories. At first, we develop models based on Convolutional Neural Network (CNN) and Bi-directional Long Short Term Memory (Bi-LSTM) networks. The representations obtained from these two models are fed into a Multi-layer Perceptron Model (MLP) for the final classification. Our experiments on a benchmark dataset show promising results with an overall accuracy of 44.87\%, which outperforms the current state of the art.
Addressing word-order Divergence in Multilingual Neural Machine Translation for extremely Low Resource Languages
Nov 01, 2018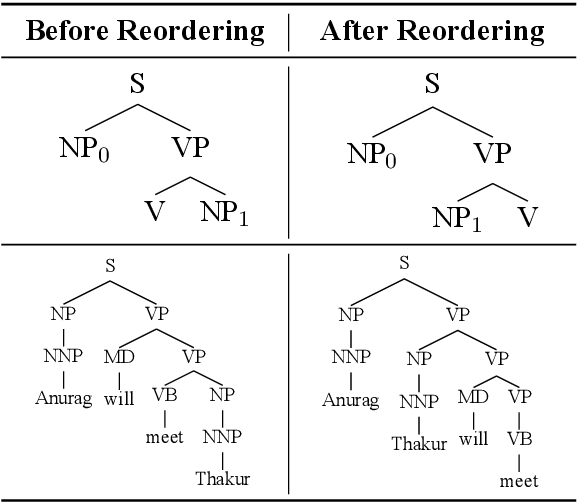
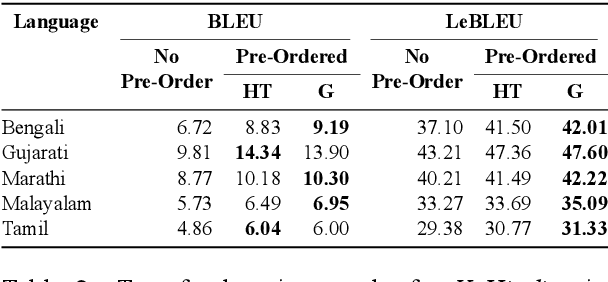
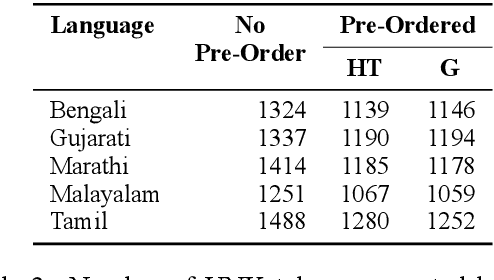
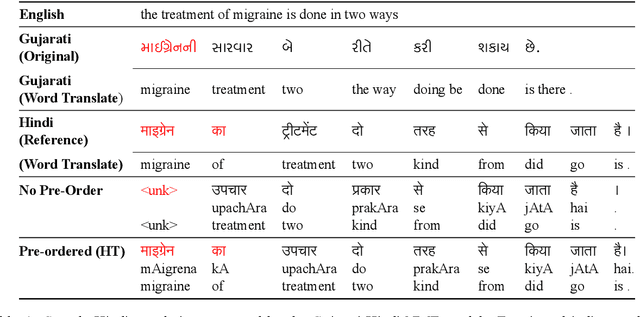
Transfer learning approaches for Neural Machine Translation (NMT) train a NMT model on the assisting-target language pair (parent model) which is later fine-tuned for the source-target language pair of interest (child model), with the target language being the same. In many cases, the assisting language has a different word order from the source language. We show that divergent word order adversely limits the benefits from transfer learning when little to no parallel corpus between the source and target language is available. To bridge this divergence, We propose to pre-order the assisting language sentence to match the word order of the source language and train the parent model. Our experiments on many language pairs show that bridging the word order gap leads to significant improvement in the translation quality.
Helping each Other: A Framework for Customer-to-Customer Suggestion Mining using a Semi-supervised Deep Neural Network
Nov 01, 2018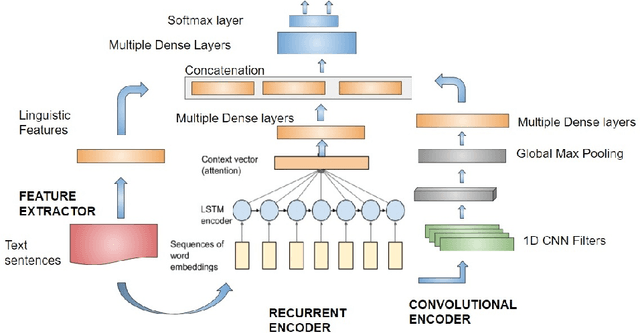
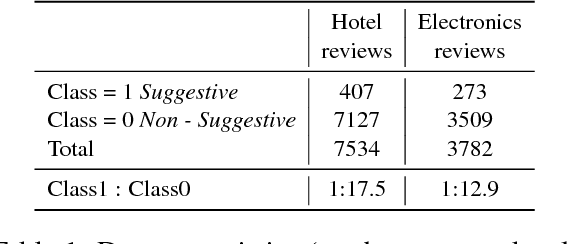
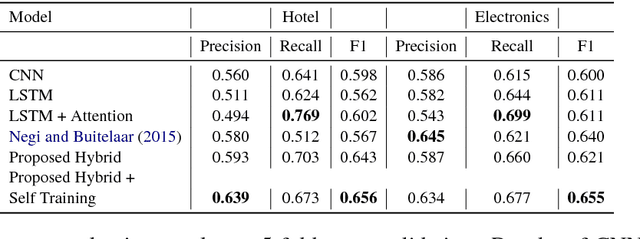
Suggestion mining is increasingly becoming an important task along with sentiment analysis. In today's cyberspace world, people not only express their sentiments and dispositions towards some entities or services, but they also spend considerable time sharing their experiences and advice to fellow customers and the product/service providers with two-fold agenda: helping fellow customers who are likely to share a similar experience, and motivating the producer to bring specific changes in their offerings which would be more appreciated by the customers. In our current work, we propose a hybrid deep learning model to identify whether a review text contains any suggestion. The model employs semi-supervised learning to leverage the useful information from the large amount of unlabeled data. We evaluate the performance of our proposed model on a benchmark customer review dataset, comprising of the reviews of Hotel and Electronics domains. Our proposed approach shows the F-scores of 65.6% and 65.5% for the Hotel and Electronics review datasets, respectively. These performances are significantly better compared to the existing state-of-the-art system.
A Multi-task Ensemble Framework for Emotion, Sentiment and Intensity Prediction
Oct 15, 2018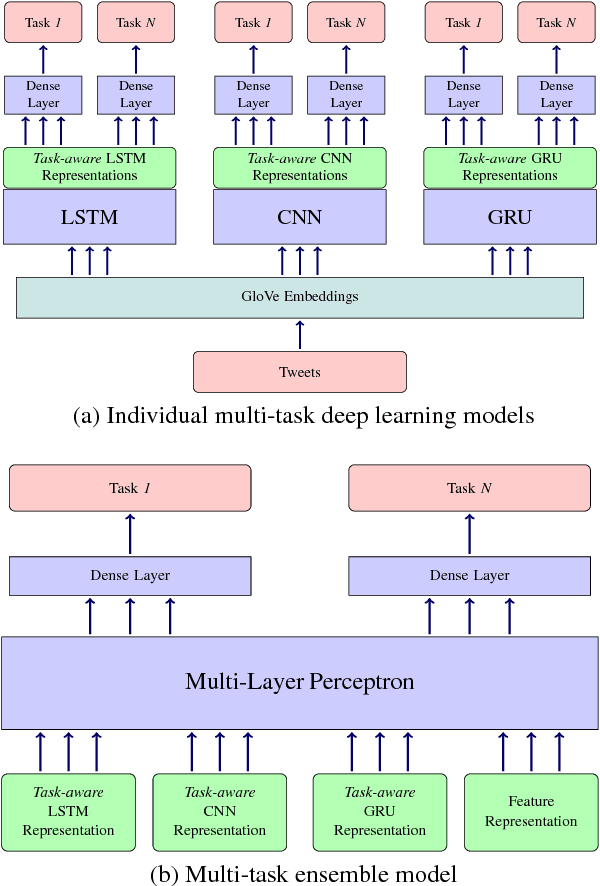

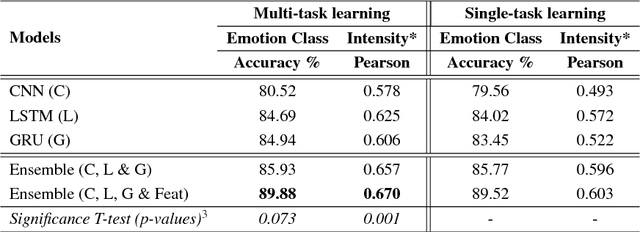
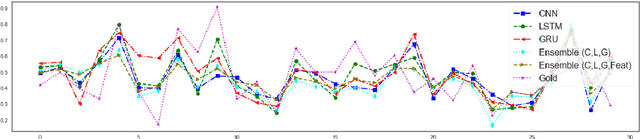
In this paper, through multi-task ensemble framework we address three problems of emotion and sentiment analysis i.e. "emotion classification & intensity", "valence, arousal & dominance for emotion" and "valence & arousal} for sentiment". The underlying problems cover two granularities (i.e. coarse-grained and fine-grained) and a diverse range of domains (i.e. tweets, Facebook posts, news headlines, blogs, letters etc.). The ensemble model aims to leverage the learned representations of three deep learning models (i.e. CNN, LSTM and GRU) and a hand-crafted feature representation for the predictions. Experimental results on the benchmark datasets show the efficacy of our proposed multi-task ensemble frameworks. We obtain the performance improvement of 2-3 points on an average over single-task systems for most of the problems and domains.
Eyes are the Windows to the Soul: Predicting the Rating of Text Quality Using Gaze Behaviour
Oct 11, 2018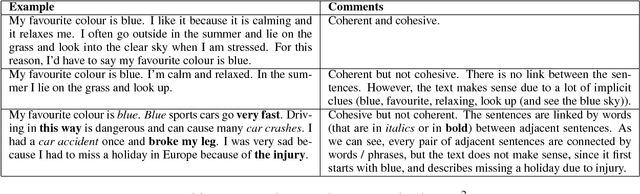


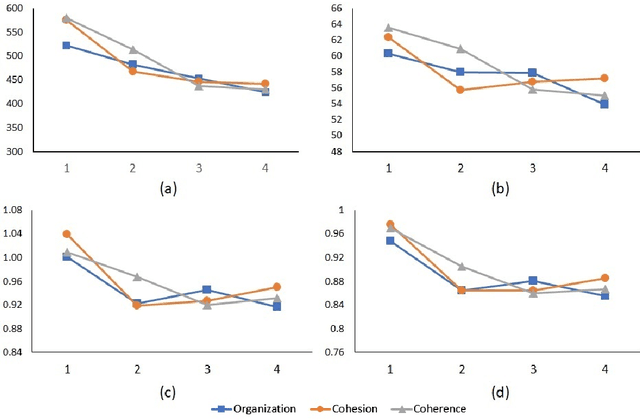
Predicting a reader's rating of text quality is a challenging task that involves estimating different subjective aspects of the text, like structure, clarity, etc. Such subjective aspects are better handled using cognitive information. One such source of cognitive information is gaze behaviour. In this paper, we show that gaze behaviour does indeed help in effectively predicting the rating of text quality. To do this, we first model text quality as a function of three properties - organization, coherence and cohesion. Then, we demonstrate how capturing gaze behaviour helps in predicting each of these properties, and hence the overall quality, by reporting improvements obtained by adding gaze features to traditional textual features for score prediction. We also hypothesize that if a reader has fully understood the text, the corresponding gaze behaviour would give a better indication of the assigned rating, as opposed to partial understanding. Our experiments validate this hypothesis by showing greater agreement between the given rating and the predicted rating when the reader has a full understanding of the text.
Is your Statement Purposeless? Predicting Computer Science Graduation Admission Acceptance based on Statement Of Purpose
Oct 09, 2018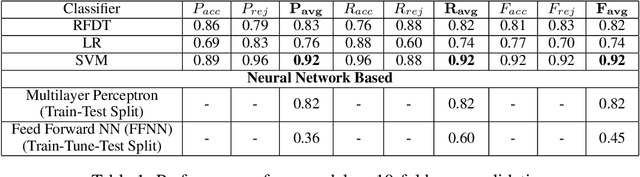
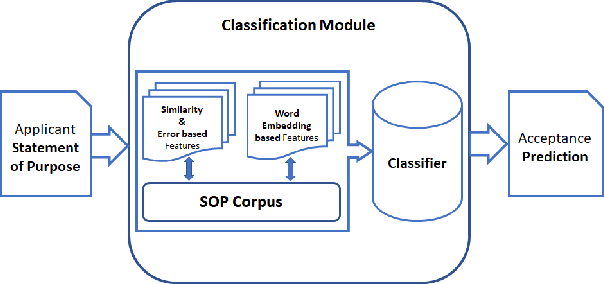
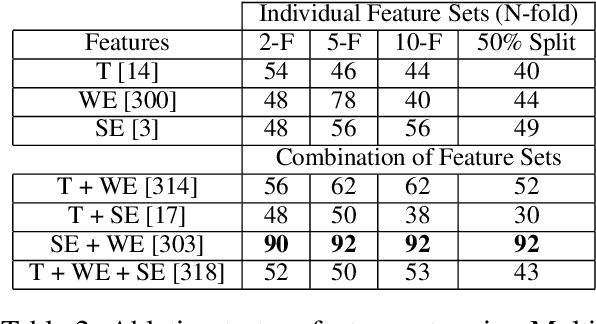
We present a quantitative, data-driven machine learning approach to mitigate the problem of unpredictability of Computer Science Graduate School Admissions. In this paper, we discuss the possibility of a system which may help prospective applicants evaluate their Statement of Purpose (SOP) based on our system output. We, then, identify feature sets which can be used to train a predictive model. We train a model over fifty manually verified SOPs for which it uses an SVM classifier and achieves the highest accuracy of 92% with 10-fold cross-validation. We also perform experiments to establish that Word Embedding based features and Document Similarity-based features outperform other identified feature combinations. We plan to deploy our application as a web service and release it as a FOSS service.
Combining Graph-based Dependency Features with Convolutional Neural Network for Answer Triggering
Aug 05, 2018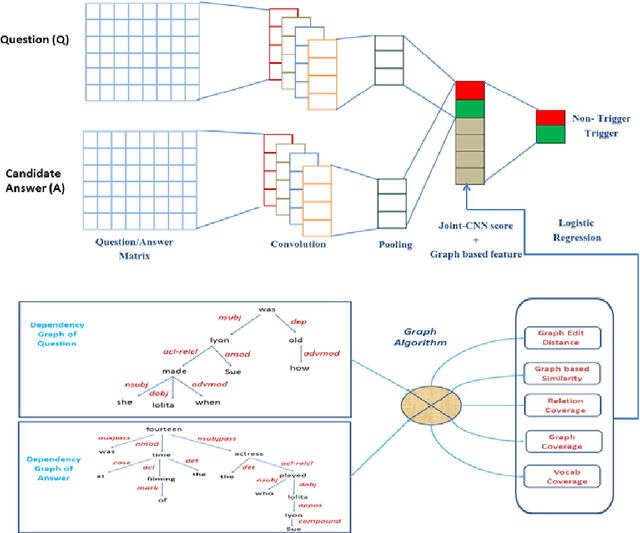

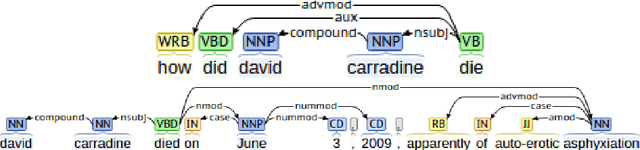
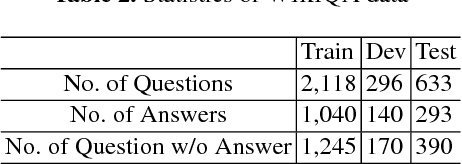
Answer triggering is the task of selecting the best-suited answer for a given question from a set of candidate answers if exists. In this paper, we present a hybrid deep learning model for answer triggering, which combines several dependency graph based alignment features, namely graph edit distance, graph-based similarity and dependency graph coverage, with dense vector embeddings from a Convolutional Neural Network (CNN). Our experiments on the WikiQA dataset show that such a combination can more accurately trigger a candidate answer compared to the previous state-of-the-art models. Comparative study on WikiQA dataset shows 5.86% absolute F-score improvement at the question level.
Leveraging Medical Sentiment to Understand Patients Health on Social Media
Jul 30, 2018
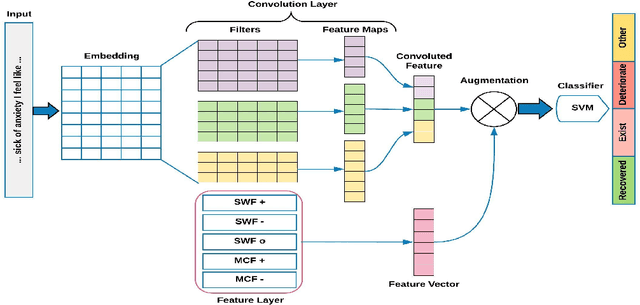


The unprecedented growth of Internet users in recent years has resulted in an abundance of unstructured information in the form of social media text. A large percentage of this population is actively engaged in health social networks to share health-related information. In this paper, we address an important and timely topic by analyzing the users' sentiments and emotions w.r.t their medical conditions. Towards this, we examine users on popular medical forums (Patient.info,dailystrength.org), where they post on important topics such as asthma, allergy, depression, and anxiety. First, we provide a benchmark setup for the task by crawling the data, and further define the sentiment specific fine-grained medical conditions (Recovered, Exist, Deteriorate, and Other). We propose an effective architecture that uses a Convolutional Neural Network (CNN) as a data-driven feature extractor and a Support Vector Machine (SVM) as a classifier. We further develop a sentiment feature which is sensitive to the medical context. Here, we show that the use of medical sentiment feature along with extracted features from CNN improves the model performance. In addition to our dataset, we also evaluate our approach on the benchmark "CLEF eHealth 2014" corpora and show that our model outperforms the state-of-the-art techniques.
Feature Assisted bi-directional LSTM Model for Protein-Protein Interaction Identification from Biomedical Texts
Jul 05, 2018
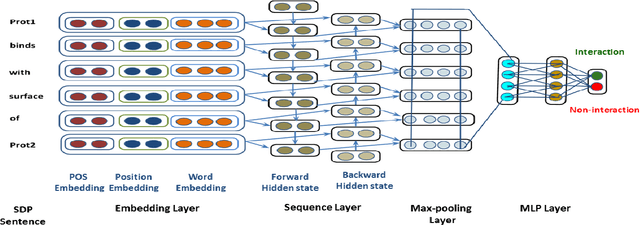


Knowledge about protein-protein interactions is essential in understanding the biological processes such as metabolic pathways, DNA replication, and transcription etc. However, a majority of the existing Protein-Protein Interaction (PPI) systems are dependent primarily on the scientific literature, which is yet not accessible as a structured database. Thus, efficient information extraction systems are required for identifying PPI information from the large collection of biomedical texts. Most of the existing systems model the PPI extraction task as a classification problem and are tailored to the handcrafted feature set including domain dependent features. In this paper, we present a novel method based on deep bidirectional long short-term memory (B-LSTM) technique that exploits word sequences and dependency path related information to identify PPI information from text. This model leverages joint modeling of proteins and relations in a single unified framework, which we name as Shortest Dependency Path B-LSTM (sdpLSTM) model. We perform experiments on two popular benchmark PPI datasets, namely AiMed & BioInfer. The evaluation shows the F1-score values of 86.45% and 77.35% on AiMed and BioInfer, respectively. Comparisons with the existing systems show that our proposed approach attains state-of-the-art performance.