 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022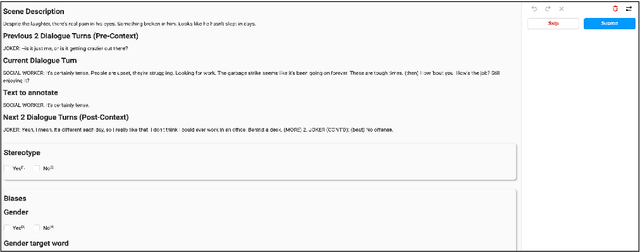
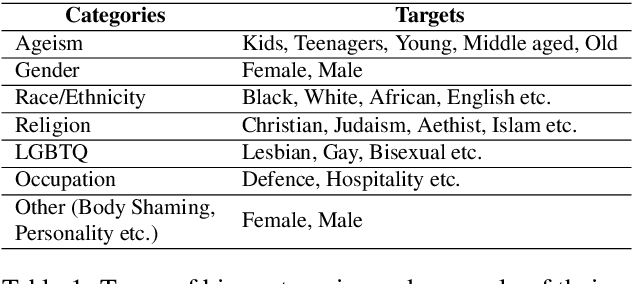

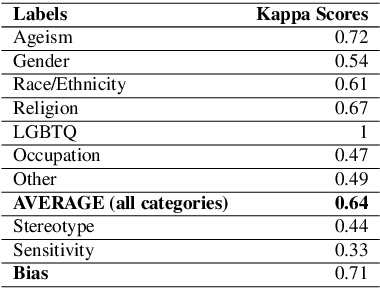
Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.
Knowledge Graph -- Deep Learning: A Case Study in Question Answering in Aviation Safety Domain
May 31, 2022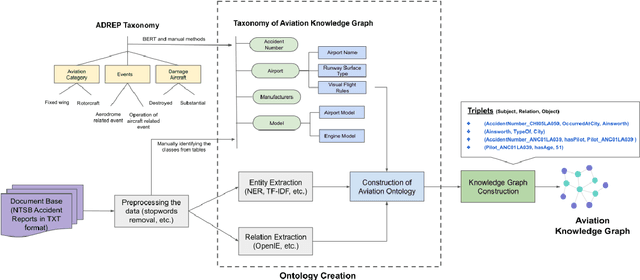
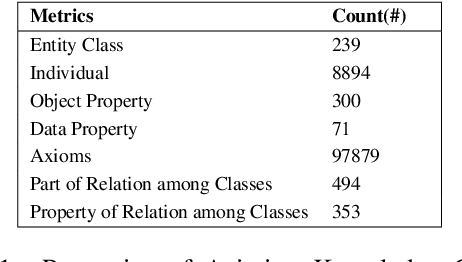
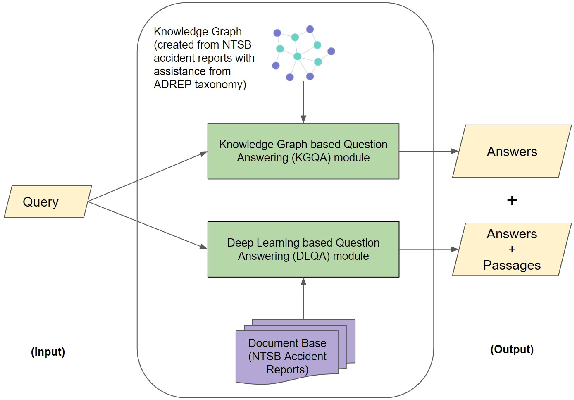
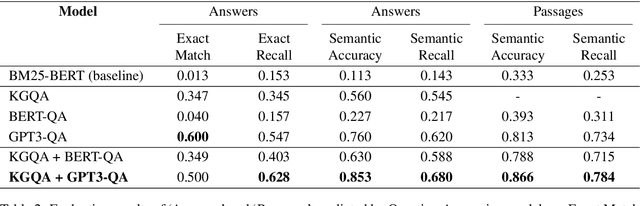
In the commercial aviation domain, there are a large number of documents, like, accident reports (NTSB, ASRS) and regulatory directives (ADs). There is a need for a system to access these diverse repositories efficiently in order to service needs in the aviation industry, like maintenance, compliance, and safety. In this paper, we propose a Knowledge Graph (KG) guided Deep Learning (DL) based Question Answering (QA) system for aviation safety. We construct a Knowledge Graph from Aircraft Accident reports and contribute this resource to the community of researchers. The efficacy of this resource is tested and proved by the aforesaid QA system. Natural Language Queries constructed from the documents mentioned above are converted into SPARQL (the interface language of the RDF graph database) queries and answered. On the DL side, we have two different QA models: (i) BERT QA which is a pipeline of Passage Retrieval (Sentence-BERT based) and Question Answering (BERT based), and (ii) the recently released GPT-3. We evaluate our system on a set of queries created from the accident reports. Our combined QA system achieves 9.3% increase in accuracy over GPT-3 and 40.3% increase over BERT QA. Thus, we infer that KG-DL performs better than either singly.
EmoInHindi: A Multi-label Emotion and Intensity Annotated Dataset in Hindi for Emotion Recognition in Dialogues
May 27, 2022
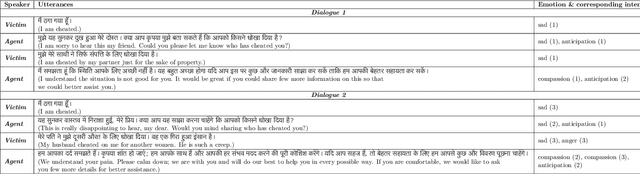
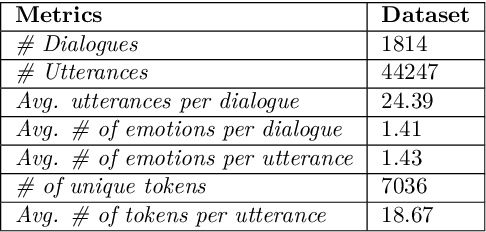
The long-standing goal of Artificial Intelligence (AI) has been to create human-like conversational systems. Such systems should have the ability to develop an emotional connection with the users, hence emotion recognition in dialogues is an important task. Emotion detection in dialogues is a challenging task because humans usually convey multiple emotions with varying degrees of intensities in a single utterance. Moreover, emotion in an utterance of a dialogue may be dependent on previous utterances making the task more complex. Emotion recognition has always been in great demand. However, most of the existing datasets for multi-label emotion and intensity detection in conversations are in English. To this end, we create a large conversational dataset in Hindi named EmoInHindi for multi-label emotion and intensity recognition in conversations containing 1,814 dialogues with a total of 44,247 utterances. We prepare our dataset in a Wizard-of-Oz manner for mental health and legal counselling of crime victims. Each utterance of the dialogue is annotated with one or more emotion categories from the 16 emotion classes including neutral, and their corresponding intensity values. We further propose strong contextual baselines that can detect emotion(s) and the corresponding intensity of an utterance given the conversational context.
HiNER: A Large Hindi Named Entity Recognition Dataset
Apr 28, 2022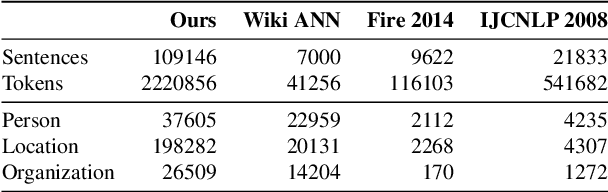
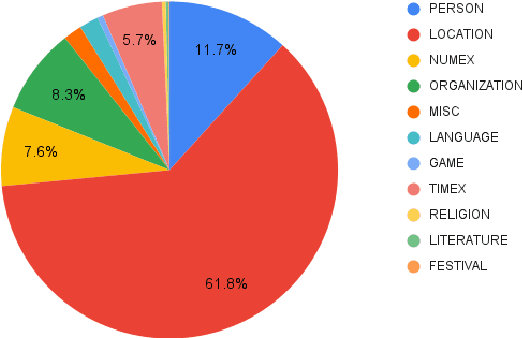
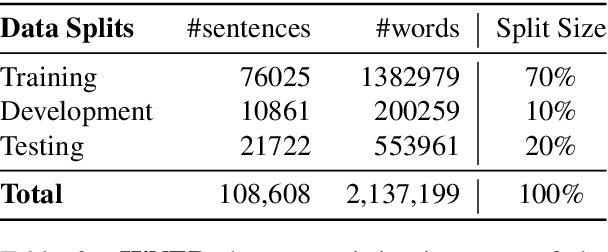
Named Entity Recognition (NER) is a foundational NLP task that aims to provide class labels like Person, Location, Organisation, Time, and Number to words in free text. Named Entities can also be multi-word expressions where the additional I-O-B annotation information helps label them during the NER annotation process. While English and European languages have considerable annotated data for the NER task, Indian languages lack on that front -- both in terms of quantity and following annotation standards. This paper releases a significantly sized standard-abiding Hindi NER dataset containing 109,146 sentences and 2,220,856 tokens, annotated with 11 tags. We discuss the dataset statistics in all their essential detail and provide an in-depth analysis of the NER tag-set used with our data. The statistics of tag-set in our dataset show a healthy per-tag distribution, especially for prominent classes like Person, Location and Organisation. Since the proof of resource-effectiveness is in building models with the resource and testing the model on benchmark data and against the leader-board entries in shared tasks, we do the same with the aforesaid data. We use different language models to perform the sequence labelling task for NER and show the efficacy of our data by performing a comparative evaluation with models trained on another dataset available for the Hindi NER task. Our dataset helps achieve a weighted F1 score of 88.78 with all the tags and 92.22 when we collapse the tag-set, as discussed in the paper. To the best of our knowledge, no available dataset meets the standards of volume (amount) and variability (diversity), as far as Hindi NER is concerned. We fill this gap through this work, which we hope will significantly help NLP for Hindi. We release this dataset with our code and models at https://github.com/cfiltnlp/HiNER
Indian Language Wordnets and their Linkages with Princeton WordNet
Jan 09, 2022
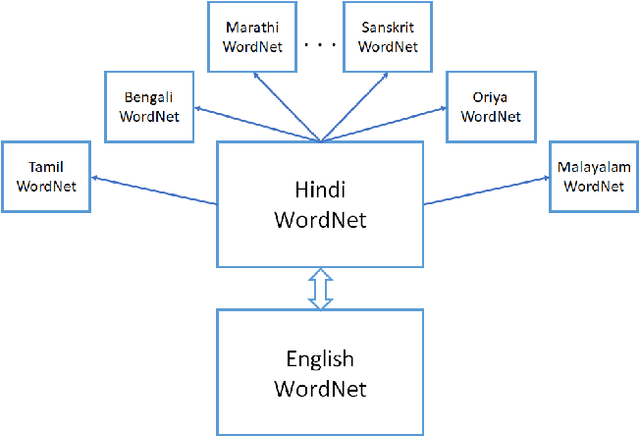
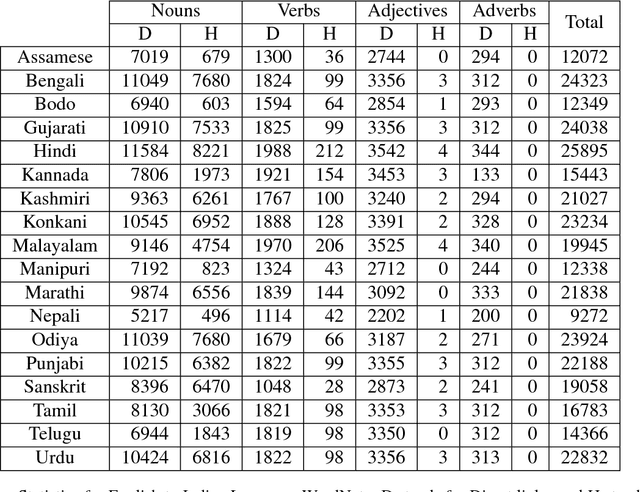
Wordnets are rich lexico-semantic resources. Linked wordnets are extensions of wordnets, which link similar concepts in wordnets of different languages. Such resources are extremely useful in many Natural Language Processing (NLP) applications, primarily those based on knowledge-based approaches. In such approaches, these resources are considered as gold standard/oracle. Thus, it is crucial that these resources hold correct information. Thereby, they are created by human experts. However, human experts in multiple languages are hard to come by. Thus, the community would benefit from sharing of such manually created resources. In this paper, we release mappings of 18 Indian language wordnets linked with Princeton WordNet. We believe that availability of such resources will have a direct impact on the progress in NLP for these languages.
Semi-automatic WordNet Linking using Word Embeddings
Jan 05, 2022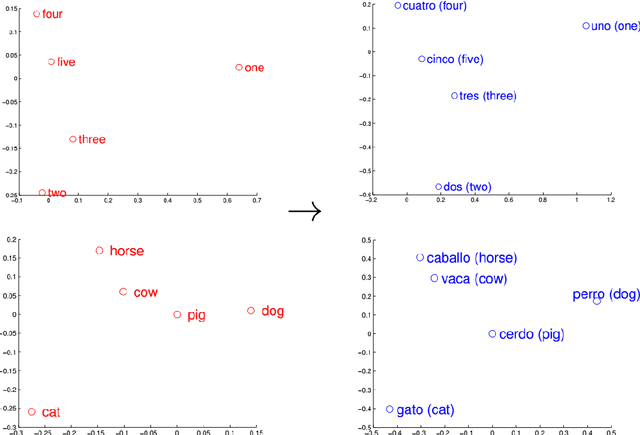
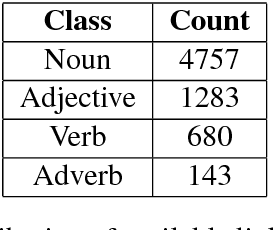
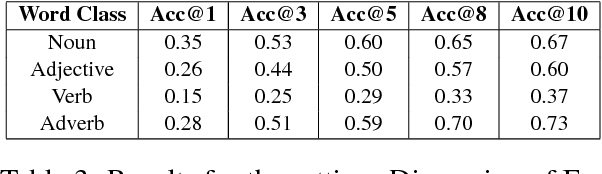
Wordnets are rich lexico-semantic resources. Linked wordnets are extensions of wordnets, which link similar concepts in wordnets of different languages. Such resources are extremely useful in many Natural Language Processing (NLP) applications, primarily those based on knowledge-based approaches. In such approaches, these resources are considered as gold standard/oracle. Thus, it is crucial that these resources hold correct information. Thereby, they are created by human experts. However, manual maintenance of such resources is a tedious and costly affair. Thus techniques that can aid the experts are desirable. In this paper, we propose an approach to link wordnets. Given a synset of the source language, the approach returns a ranked list of potential candidate synsets in the target language from which the human expert can choose the correct one(s). Our technique is able to retrieve a winner synset in the top 10 ranked list for 60% of all synsets and 70% of noun synsets.
Strategies of Effective Digitization of Commentaries and Sub-commentaries: Towards the Construction of Textual History
Jan 05, 2022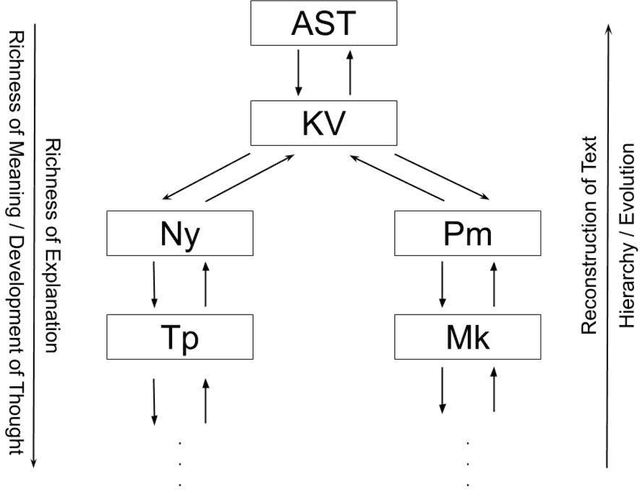
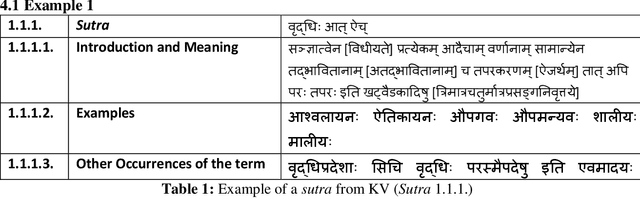

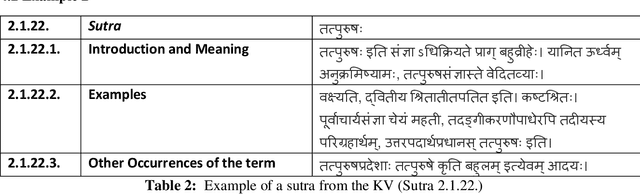
This paper describes additional aspects of a digital tool called the 'Textual History Tool'. We describe its various salient features with special reference to those of its features that may help the philologist digitize commentaries and sub-commentaries on a text. This tool captures the historical evolution of a text through various temporal stages, and interrelated data culled from various types of related texts. We use the text of the K\=a\'sik\=avrtti (KV) as a sample text, and with the help of philologists, we digitize the commentaries available to us. We digitize the Ny\=asa (Ny), the Padama\~njar\=i (Pm) and sub commentaries on the KV text known as the Tantraprad\=ipa (Tp), and the Makaranda (Mk). We divide each commentary and sub-commentary into functional units and describe the methodology and motivation behind the functional unit division. Our functional unit division helps generate more accurate phylogenetic trees for the text, based on distance methods using the data entered in the tool.
A Survey on Using Gaze Behaviour for Natural Language Processing
Jan 03, 2022
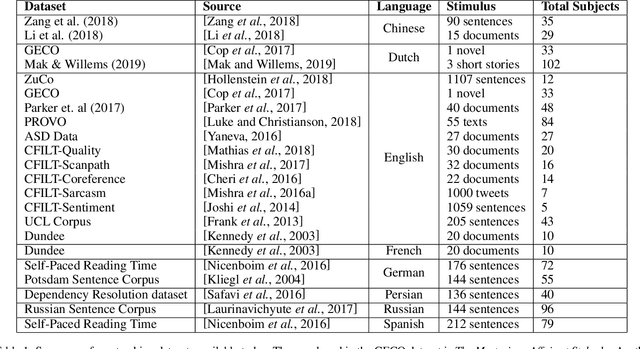

Gaze behaviour has been used as a way to gather cognitive information for a number of years. In this paper, we discuss the use of gaze behaviour in solving different tasks in natural language processing (NLP) without having to record it at test time. This is because the collection of gaze behaviour is a costly task, both in terms of time and money. Hence, in this paper, we focus on research done to alleviate the need for recording gaze behaviour at run time. We also mention different eye tracking corpora in multiple languages, which are currently available and can be used in natural language processing. We conclude our paper by discussing applications in a domain - education - and how learning gaze behaviour can help in solving the tasks of complex word identification and automatic essay grading.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021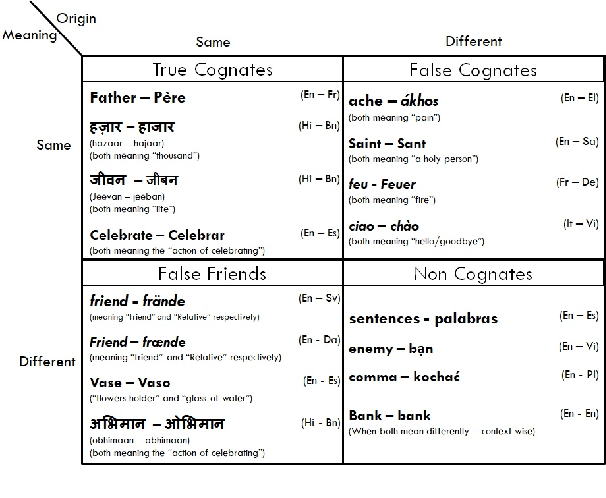
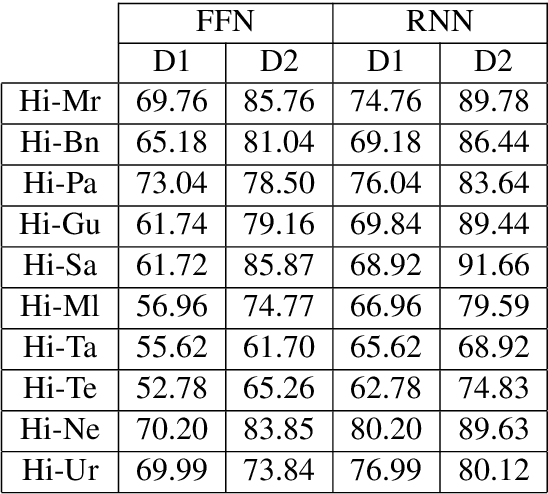
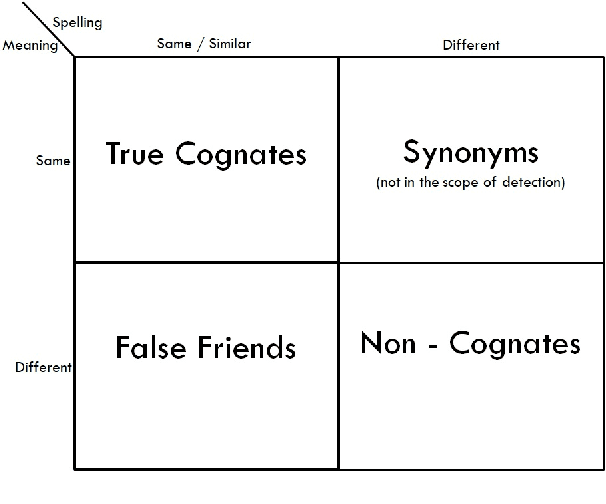
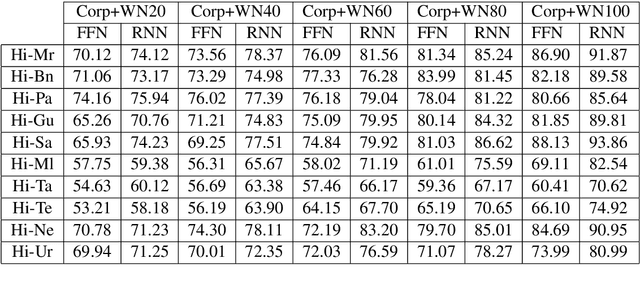
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
"A Passage to India": Pre-trained Word Embeddings for Indian Languages
Dec 27, 2021Dense word vectors or 'word embeddings' which encode semantic properties of words, have now become integral to NLP tasks like Machine Translation (MT), Question Answering (QA), Word Sense Disambiguation (WSD), and Information Retrieval (IR). In this paper, we use various existing approaches to create multiple word embeddings for 14 Indian languages. We place these embeddings for all these languages, viz., Assamese, Bengali, Gujarati, Hindi, Kannada, Konkani, Malayalam, Marathi, Nepali, Odiya, Punjabi, Sanskrit, Tamil, and Telugu in a single repository. Relatively newer approaches that emphasize catering to context (BERT, ELMo, etc.) have shown significant improvements, but require a large amount of resources to generate usable models. We release pre-trained embeddings generated using both contextual and non-contextual approaches. We also use MUSE and XLM to train cross-lingual embeddings for all pairs of the aforementioned languages. To show the efficacy of our embeddings, we evaluate our embedding models on XPOS, UPOS and NER tasks for all these languages. We release a total of 436 models using 8 different approaches. We hope they are useful for the resource-constrained Indian language NLP. The title of this paper refers to the famous novel 'A Passage to India' by E.M. Forster, published initially in 1924.