 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"A Little is Enough": Few-Shot Quality Estimation based Corpus Filtering improves Machine Translation
Jun 06, 2023Quality Estimation (QE) is the task of evaluating the quality of a translation when reference translation is not available. The goal of QE aligns with the task of corpus filtering, where we assign the quality score to the sentence pairs present in the pseudo-parallel corpus. We propose a Quality Estimation based Filtering approach to extract high-quality parallel data from the pseudo-parallel corpus. To the best of our knowledge, this is a novel adaptation of the QE framework to extract quality parallel corpus from the pseudo-parallel corpus. By training with this filtered corpus, we observe an improvement in the Machine Translation (MT) system's performance by up to 1.8 BLEU points, for English-Marathi, Chinese-English, and Hindi-Bengali language pairs, over the baseline model. The baseline model is the one that is trained on the whole pseudo-parallel corpus. Our Few-shot QE model transfer learned from the English-Marathi QE model and fine-tuned on only 500 Hindi-Bengali training instances, shows an improvement of up to 0.6 BLEU points for Hindi-Bengali language pair, compared to the baseline model. This demonstrates the promise of transfer learning in the setting under discussion. QE systems typically require in the order of (7K-25K) of training data. Our Hindi-Bengali QE is trained on only 500 instances of training that is 1/40th of the normal requirement and achieves comparable performance. All the scripts and datasets utilized in this study will be publicly available.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023



Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
A Match Made in Heaven: A Multi-task Framework for Hyperbole and Metaphor Detection
May 30, 2023Hyperbole and metaphor are common in day-to-day communication (e.g., "I am in deep trouble": how does trouble have depth?), which makes their detection important, especially in a conversational AI setting. Existing approaches to automatically detect metaphor and hyperbole have studied these language phenomena independently, but their relationship has hardly, if ever, been explored computationally. In this paper, we propose a multi-task deep learning framework to detect hyperbole and metaphor simultaneously. We hypothesize that metaphors help in hyperbole detection, and vice-versa. To test this hypothesis, we annotate two hyperbole datasets- HYPO and HYPO-L- with metaphor labels. Simultaneously, we annotate two metaphor datasets- TroFi and LCC- with hyperbole labels. Experiments using these datasets give an improvement of the state of the art of hyperbole detection by 12%. Additionally, our multi-task learning (MTL) approach shows an improvement of up to 17% over single-task learning (STL) for both hyperbole and metaphor detection, supporting our hypothesis. To the best of our knowledge, ours is the first demonstration of computational leveraging of linguistic intimacy between metaphor and hyperbole, leading to showing the superiority of MTL over STL for hyperbole and metaphor detection.
DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction
May 26, 2023

Conversational speech often consists of deviations from the speech plan, producing disfluent utterances that affect downstream NLP tasks. Removing these disfluencies is necessary to create fluent and coherent speech. This paper presents DisfluencyFixer, a tool that performs speech-to-speech disfluency correction in English and Hindi using a pipeline of Automatic Speech Recognition (ASR), Disfluency Correction (DC) and Text-To-Speech (TTS) models. Our proposed system removes disfluencies from input speech and returns fluent speech as output along with its transcript, disfluency type and total disfluency count in source utterance, providing a one-stop destination for language learners to improve the fluency of their speech. We evaluate the performance of our tool subjectively and receive scores of 4.26, 4.29 and 4.42 out of 5 in ASR performance, DC performance and ease-of-use of the system. Our tool can be accessed openly at the following link.
VAKTA-SETU: A Speech-to-Speech Machine Translation Service in Select Indic Languages
May 21, 2023



In this work, we present our deployment-ready Speech-to-Speech Machine Translation (SSMT) system for English-Hindi, English-Marathi, and Hindi-Marathi language pairs. We develop the SSMT system by cascading Automatic Speech Recognition (ASR), Disfluency Correction (DC), Machine Translation (MT), and Text-to-Speech Synthesis (TTS) models. We discuss the challenges faced during the research and development stage and the scalable deployment of the SSMT system as a publicly accessible web service. On the MT part of the pipeline too, we create a Text-to-Text Machine Translation (TTMT) service in all six translation directions involving English, Hindi, and Marathi. To mitigate data scarcity, we develop a LaBSE-based corpus filtering tool to select high-quality parallel sentences from a noisy pseudo-parallel corpus for training the TTMT system. All the data used for training the SSMT and TTMT systems and the best models are being made publicly available. Users of our system are (a) Govt. of India in the context of its new education policy (NEP), (b) tourists who criss-cross the multilingual landscape of India, (c) Indian Judiciary where a leading cause of the pendency of cases (to the order of 10 million as on date) is the translation of case papers, (d) farmers who need weather and price information and so on. We also share the feedback received from various stakeholders when our SSMT and TTMT systems were demonstrated in large public events.
Denoising-based UNMT is more robust to word-order divergence than MASS-based UNMT
Mar 02, 2023



We aim to investigate whether UNMT approaches with self-supervised pre-training are robust to word-order divergence between language pairs. We achieve this by comparing two models pre-trained with the same self-supervised pre-training objective. The first model is trained on language pairs with different word-orders, and the second model is trained on the same language pairs with source language re-ordered to match the word-order of the target language. Ideally, UNMT approaches which are robust to word-order divergence should exhibit no visible performance difference between the two configurations. In this paper, we investigate two such self-supervised pre-training based UNMT approaches, namely Masked Sequence-to-Sequence Pre-Training, (MASS) (which does not have shuffling noise) and Denoising AutoEncoder (DAE), (which has shuffling noise). We experiment with five English$\rightarrow$Indic language pairs, i.e., en-hi, en-bn, en-gu, en-kn, and en-ta) where word-order of the source language is SVO (Subject-Verb-Object), and the word-order of the target languages is SOV (Subject-Object-Verb). We observed that for these language pairs, DAE-based UNMT approach consistently outperforms MASS in terms of translation accuracies. Moreover, bridging the word-order gap using reordering improves the translation accuracy of MASS-based UNMT models, while it cannot improve the translation accuracy of DAE-based UNMT models. This observation indicates that DAE-based UNMT is more robust to word-order divergence than MASS-based UNMT. Word-shuffling noise in DAE approach could be the possible reason for the approach being robust to word-order divergence.
Improving Machine Translation with Phrase Pair Injection and Corpus Filtering
Jan 19, 2023In this paper, we show that the combination of Phrase Pair Injection and Corpus Filtering boosts the performance of Neural Machine Translation (NMT) systems. We extract parallel phrases and sentences from the pseudo-parallel corpus and augment it with the parallel corpus to train the NMT models. With the proposed approach, we observe an improvement in the Machine Translation (MT) system for 3 low-resource language pairs, Hindi-Marathi, English-Marathi, and English-Pashto, and 6 translation directions by up to 2.7 BLEU points, on the FLORES test data. These BLEU score improvements are over the models trained using the whole pseudo-parallel corpus augmented with the parallel corpus.
There is No Big Brother or Small Brother: Knowledge Infusion in Language Models for Link Prediction and Question Answering
Jan 10, 2023The integration of knowledge graphs with deep learning is thriving in improving the performance of various natural language processing (NLP) tasks. In this paper, we focus on knowledge-infused link prediction and question answering using language models, T5, and BLOOM across three domains: Aviation, Movie, and Web. In this context, we infuse knowledge in large and small language models and study their performance, and find the performance to be similar. For the link prediction task on the Aviation Knowledge Graph, we obtain a 0.2 hits@1 score using T5-small, T5-base, T5-large, and BLOOM. Using template-based scripts, we create a set of 1 million synthetic factoid QA pairs in the aviation domain from National Transportation Safety Board (NTSB) reports. On our curated QA pairs, the three models of T5 achieve a 0.7 hits@1 score. We validate out findings with the paired student t-test and Cohen's kappa scores. For link prediction on Aviation Knowledge Graph using T5-small and T5-large, we obtain a Cohen's kappa score of 0.76, showing substantial agreement between the models. Thus, we infer that small language models perform similar to large language models with the infusion of knowledge.
Knowledge Graph Construction and Its Application in Automatic Radiology Report Generation from Radiologist's Dictation
Jun 14, 2022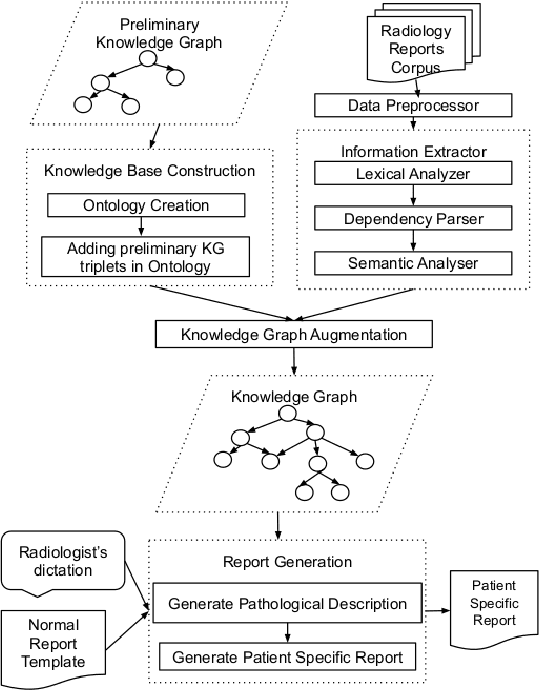
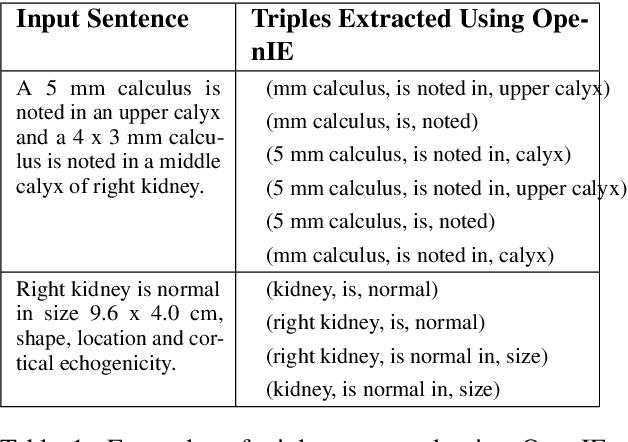
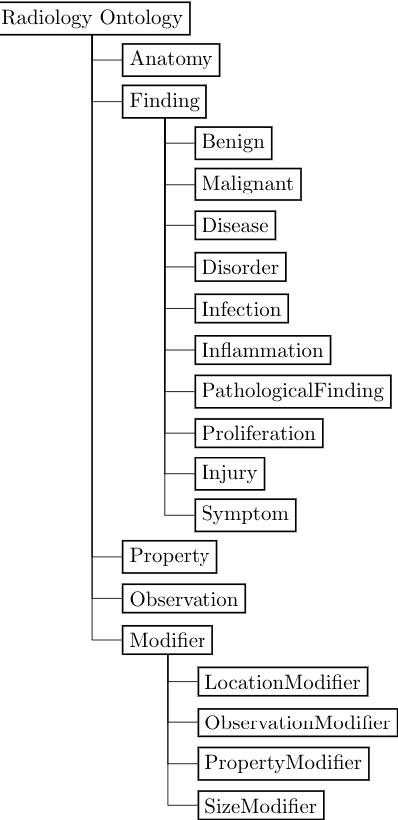

Conventionally, the radiologist prepares the diagnosis notes and shares them with the transcriptionist. Then the transcriptionist prepares a preliminary formatted report referring to the notes, and finally, the radiologist reviews the report, corrects the errors, and signs off. This workflow causes significant delays and errors in the report. In current research work, we focus on applications of NLP techniques like Information Extraction (IE) and domain-specific Knowledge Graph (KG) to automatically generate radiology reports from radiologist's dictation. This paper focuses on KG construction for each organ by extracting information from an existing large corpus of free-text radiology reports. We develop an information extraction pipeline that combines rule-based, pattern-based, and dictionary-based techniques with lexical-semantic features to extract entities and relations. Missing information in short dictation can be accessed from the KGs to generate pathological descriptions and hence the radiology report. Generated pathological descriptions evaluated using semantic similarity metrics, which shows 97% similarity with gold standard pathological descriptions. Also, our analysis shows that our IE module is performing better than the OpenIE tool for the radiology domain. Furthermore, we include a manual qualitative analysis from radiologists, which shows that 80-85% of the generated reports are correctly written, and the remaining are partially correct.
A Multimodal Corpus for Emotion Recognition in Sarcasm
Jun 05, 2022
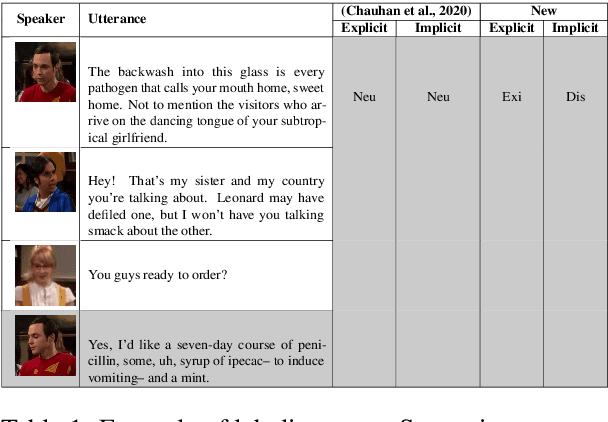
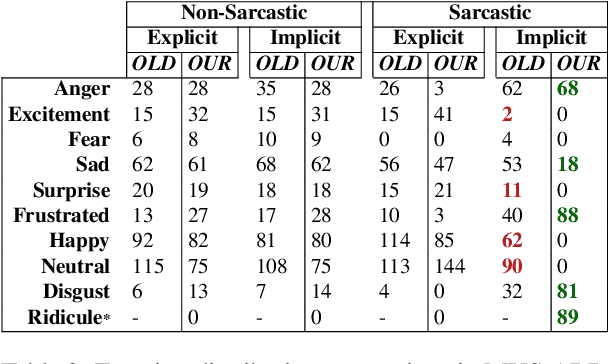
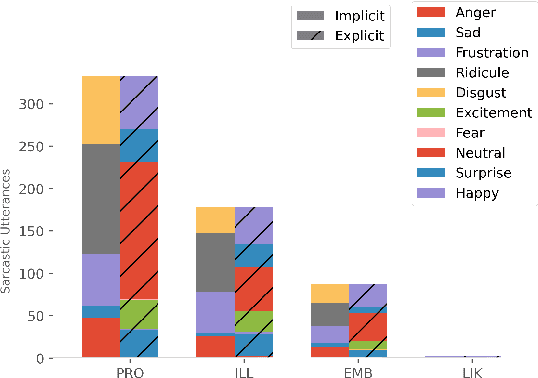
While sentiment and emotion analysis have been studied extensively, the relationship between sarcasm and emotion has largely remained unexplored. A sarcastic expression may have a variety of underlying emotions. For example, "I love being ignored" belies sadness, while "my mobile is fabulous with a battery backup of only 15 minutes!" expresses frustration. Detecting the emotion behind a sarcastic expression is non-trivial yet an important task. We undertake the task of detecting the emotion in a sarcastic statement, which to the best of our knowledge, is hitherto unexplored. We start with the recently released multimodal sarcasm detection dataset (MUStARD) pre-annotated with 9 emotions. We identify and correct 343 incorrect emotion labels (out of 690). We double the size of the dataset, label it with emotions along with valence and arousal which are important indicators of emotional intensity. Finally, we label each sarcastic utterance with one of the four sarcasm types-Propositional, Embedded, Likeprefixed and Illocutionary, with the goal of advancing sarcasm detection research. Exhaustive experimentation with multimodal (text, audio, and video) fusion models establishes a benchmark for exact emotion recognition in sarcasm and outperforms the state-of-art sarcasm detection. We release the dataset enriched with various annotations and the code for research purposes: https://github.com/apoorva-nunna/MUStARD_Plus_Plus