 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs and Heterogeneous Knowledge Graphs for Persona-Driven Session-Based Recommendation
Apr 08, 2026Session-based recommendation systems (SBRS) aim to capture user's short-term intent from interaction sequences. However, the common assumption of anonymous sessions limits personalization, particularly under sparse or cold-start conditions. Recent advances in LLM-augmented recommendation have shown that LLMs can generate rich item representations, but modeling user personas with LLMs remains challenging due to anonymous sessions. In this work, we propose a persona-driven SBRS framework that explicitly models latent user personas inferred from a heterogeneous knowledge graph (KG) and integrates them into a data-driven recommendation pipeline.Our framework adopts a two-stage architecture consisting of personalized information extraction and personalized information utilization, inspired by recent chain-of-thought recommendation approaches. In the personalized information extraction stage, we construct a heterogeneous KG that integrates time-independent user-item, item-item, item-feature association, and metadata from DBpedia. We then learn latent user personas in an unsupervised manner using a Heterogeneous Deep Graph Infomax (HDGI) objective over a KG initialized with LLM-derived item embeddings. In the personalized information utilization stage, the learned persona representations together with LLM-derived item embeddings are incorporated into a modified architecture of data-driven SBRS to generate a candidate set of relevant items, followed by reranking using the base sequential model to emphasize short-term session intent. Unlike prior approaches that rely solely on sequence modeling or text-based user representations, our method grounds user persona modeling in structured relational signals derived from a KG. Experiments on Amazon Books and Amazon Movies & TV demonstrate that our approach consistently improves over sequential models with user embeddings derived using session history.
Defend: Automated Rebuttals for Peer Review with Minimal Author Guidance
Mar 28, 2026Rebuttal generation is a critical component of the peer review process for scientific papers, enabling authors to clarify misunderstandings, correct factual inaccuracies, and guide reviewers toward a more accurate evaluation. We observe that Large Language Models (LLMs) often struggle to perform targeted refutation and maintain accurate factual grounding when used directly for rebuttal generation, highlighting the need for structured reasoning and author intervention. To address this, in the paper, we introduce DEFEND an LLM based tool designed to explicitly execute the underlying reasoning process of automated rebuttal generation, while keeping the author-in-the-loop. As opposed to writing the rebuttals from scratch, the author needs to only drive the reasoning process with minimal intervention, leading an efficient approach with minimal effort and less cognitive load. We compare DEFEND against three other paradigms: (i) Direct rebuttal generation using LLM (DRG), (ii) Segment-wise rebuttal generation using LLM (SWRG), and (iii) Sequential approach (SA) of segment-wise rebuttal generation without author intervention. To enable finegrained evaluation, we extend the ReviewCritique dataset, creating review segmentation, deficiency, error type annotations, rebuttal-action labels, and mapping to gold rebuttal segments. Experimental results and a user study demonstrate that directly using LLMs perform poorly in factual correctness and targeted refutation. Segment-wise generation and the automated sequential approach with author-in-the-loop, substantially improve factual correctness and strength of refutation.
HiNER: A Large Hindi Named Entity Recognition Dataset
Apr 28, 2022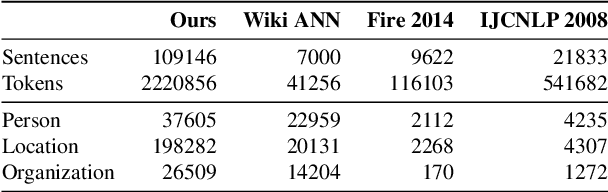
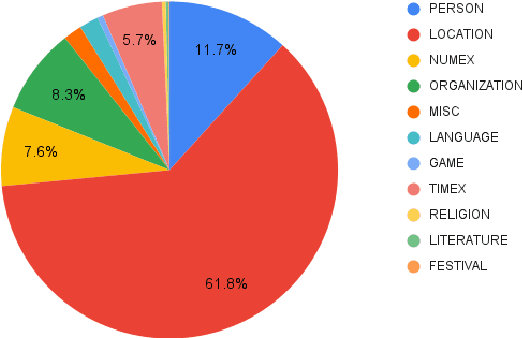
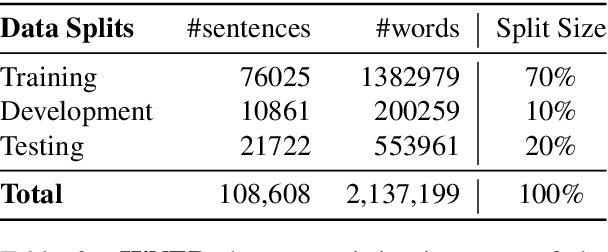
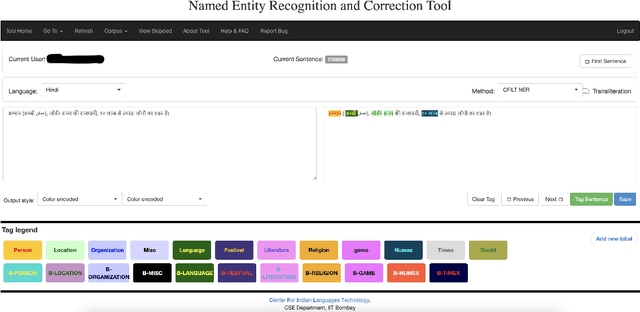
Named Entity Recognition (NER) is a foundational NLP task that aims to provide class labels like Person, Location, Organisation, Time, and Number to words in free text. Named Entities can also be multi-word expressions where the additional I-O-B annotation information helps label them during the NER annotation process. While English and European languages have considerable annotated data for the NER task, Indian languages lack on that front -- both in terms of quantity and following annotation standards. This paper releases a significantly sized standard-abiding Hindi NER dataset containing 109,146 sentences and 2,220,856 tokens, annotated with 11 tags. We discuss the dataset statistics in all their essential detail and provide an in-depth analysis of the NER tag-set used with our data. The statistics of tag-set in our dataset show a healthy per-tag distribution, especially for prominent classes like Person, Location and Organisation. Since the proof of resource-effectiveness is in building models with the resource and testing the model on benchmark data and against the leader-board entries in shared tasks, we do the same with the aforesaid data. We use different language models to perform the sequence labelling task for NER and show the efficacy of our data by performing a comparative evaluation with models trained on another dataset available for the Hindi NER task. Our dataset helps achieve a weighted F1 score of 88.78 with all the tags and 92.22 when we collapse the tag-set, as discussed in the paper. To the best of our knowledge, no available dataset meets the standards of volume (amount) and variability (diversity), as far as Hindi NER is concerned. We fill this gap through this work, which we hope will significantly help NLP for Hindi. We release this dataset with our code and models at https://github.com/cfiltnlp/HiNER