 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

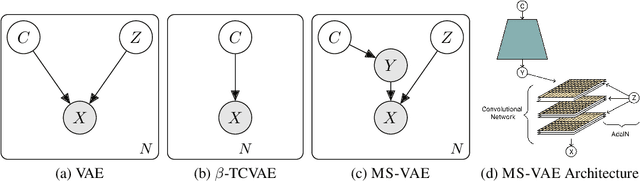

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
not-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
Sep 09, 2020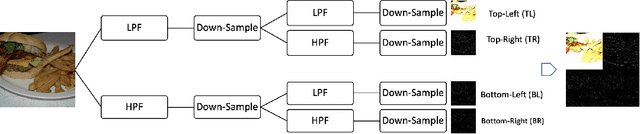
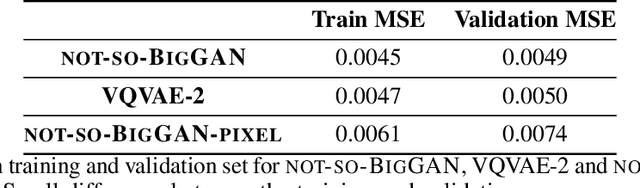
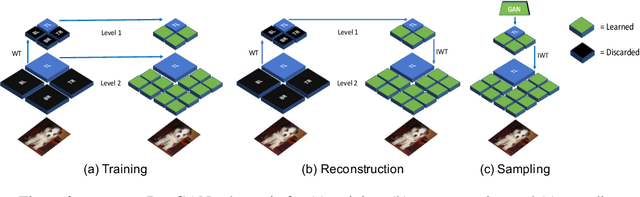
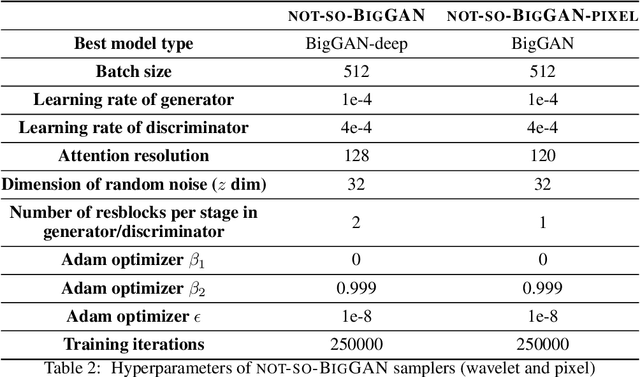
BigGAN is the state-of-the-art in high-resolution image generation, successfully leveraging advancements in scalable computing and theoretical understanding of generative adversarial methods to set new records in conditional image generation. A major part of BigGAN's success is due to its use of large mini-batch sizes during training in high dimensions. While effective, this technique requires an incredible amount of compute resources and/or time (256 TPU-v3 Cores), putting the model out of reach for the larger research community. In this paper, we present not-so-BigGAN, a simple and scalable framework for training deep generative models on high-dimensional natural images. Instead of modelling the image in pixel space like in BigGAN, not-so-BigGAN uses wavelet transformations to bypass the curse of dimensionality, reducing the overall compute requirement significantly. Through extensive empirical evaluation, we demonstrate that for a fixed compute budget, not-so-BigGAN converges several times faster than BigGAN, reaching competitive image quality with an order of magnitude lower compute budget (4 Telsa-V100 GPUs).
Optimizing Mode Connectivity via Neuron Alignment
Sep 05, 2020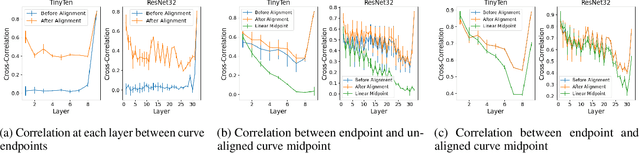
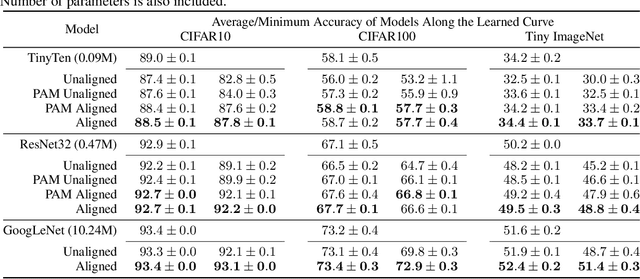
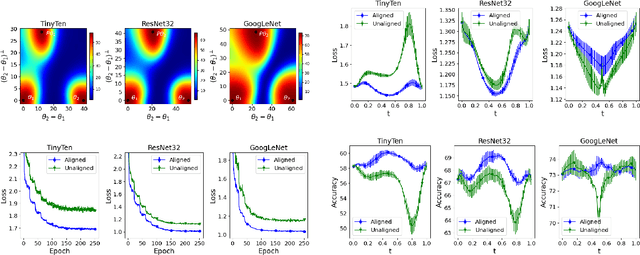
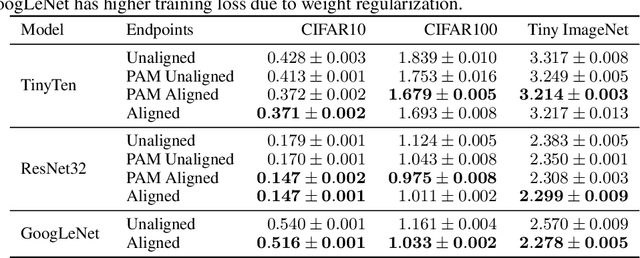
The loss landscapes of deep neural networks are not well understood due to their high nonconvexity. Empirically, the local minima of these loss functions can be connected by a learned curve in model space, along which the loss remains nearly constant; a feature known as mode connectivity. Yet, current curve finding algorithms do not consider the influence of symmetry in the loss surface created by model weight permutations. We propose a more general framework to investigate the effect of symmetry on landscape connectivity by accounting for the weight permutations of the networks being connected. To approximate the optimal permutation, we introduce an inexpensive heuristic referred to as neuron alignment. Neuron alignment promotes similarity between the distribution of intermediate activations of models along the curve. We provide theoretical analysis establishing the benefit of alignment to mode connectivity based on this simple heuristic. We empirically verify that the permutation given by alignment is locally optimal via a proximal alternating minimization scheme. Empirically, optimizing the weight permutation is critical for efficiently learning a simple, planar, low-loss curve between networks that successfully generalizes. Our alignment method can significantly alleviate the recently identified robust loss barrier on the path connecting two adversarial robust models and find more robust and accurate models on the path.
OnlineAugment: Online Data Augmentation with Less Domain Knowledge
Aug 22, 2020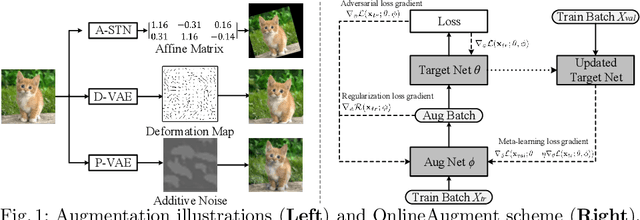
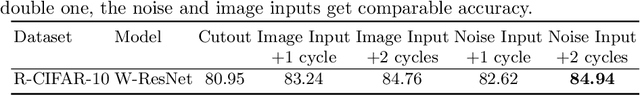
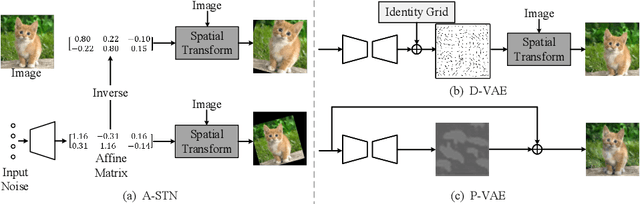

Data augmentation is one of the most important tools in training modern deep neural networks. Recently, great advances have been made in searching for optimal augmentation policies in the image classification domain. However, two key points related to data augmentation remain uncovered by the current methods. First is that most if not all modern augmentation search methods are offline and learning policies are isolated from their usage. The learned policies are mostly constant throughout the training process and are not adapted to the current training model state. Second, the policies rely on class-preserving image processing functions. Hence applying current offline methods to new tasks may require domain knowledge to specify such kind of operations. In this work, we offer an orthogonal online data augmentation scheme together with three new augmentation networks, co-trained with the target learning task. It is both more efficient, in the sense that it does not require expensive offline training when entering a new domain, and more adaptive as it adapts to the learner state. Our augmentation networks require less domain knowledge and are easily applicable to new tasks. Extensive experiments demonstrate that the proposed scheme alone performs on par with the state-of-the-art offline data augmentation methods, as well as improving upon the state-of-the-art in combination with those methods. Code is available at https://github.com/zhiqiangdon/online-augment .
AR-Net: Adaptive Frame Resolution for Efficient Action Recognition
Jul 31, 2020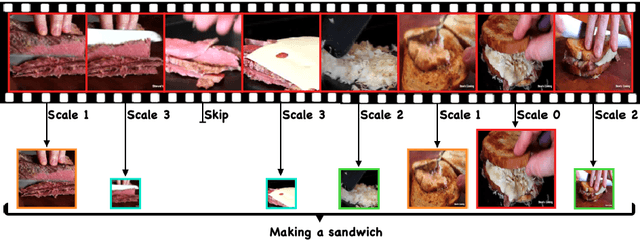
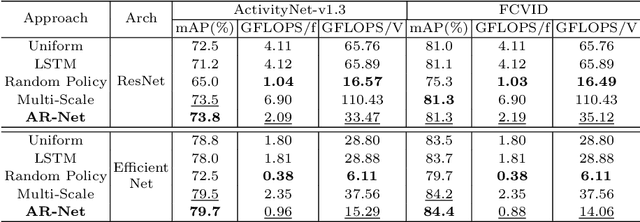

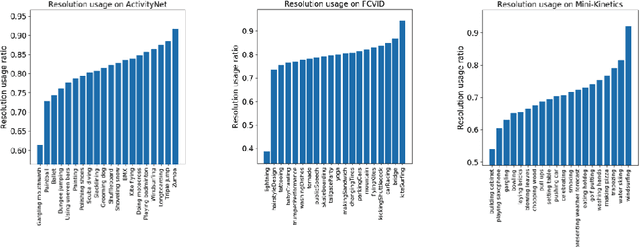
Action recognition is an open and challenging problem in computer vision. While current state-of-the-art models offer excellent recognition results, their computational expense limits their impact for many real-world applications. In this paper, we propose a novel approach, called AR-Net (Adaptive Resolution Network), that selects on-the-fly the optimal resolution for each frame conditioned on the input for efficient action recognition in long untrimmed videos. Specifically, given a video frame, a policy network is used to decide what input resolution should be used for processing by the action recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on several challenging action recognition benchmark datasets well demonstrate the efficacy of our proposed approach over state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AR-Net
Fair Data Integration
Jun 10, 2020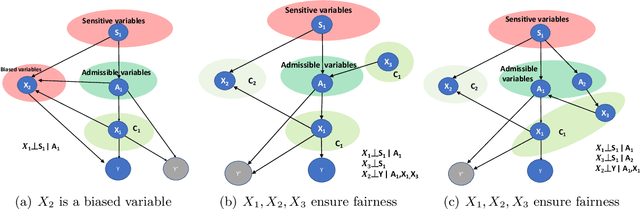
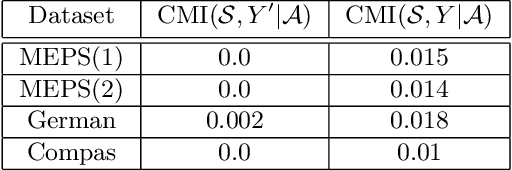
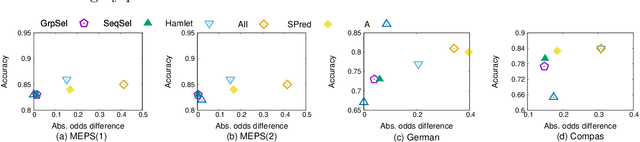
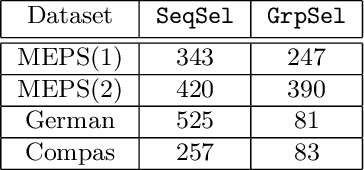
The use of machine learning (ML) in high-stakes societal decisions has encouraged the consideration of fairness throughout the ML lifecycle. Although data integration is one of the primary steps to generate high quality training data, most of the fairness literature ignores this stage. In this work, we consider fairness in the integration component of data management, aiming to identify features that improve prediction without adding any bias to the dataset. We work under the causal interventional fairness paradigm. Without requiring the underlying structural causal model a priori, we propose an approach to identify a sub-collection of features that ensure the fairness of the dataset by performing conditional independence tests between different subsets of features. We use group testing to improve the complexity of the approach. We theoretically prove the correctness of the proposed algorithm to identify features that ensure interventional fairness and show that sub-linear conditional independence tests are sufficient to identify these variables. A detailed empirical evaluation is performed on real-world datasets to demonstrate the efficacy and efficiency of our technique.
Calibrating Healthcare AI: Towards Reliable and Interpretable Deep Predictive Models
Apr 27, 2020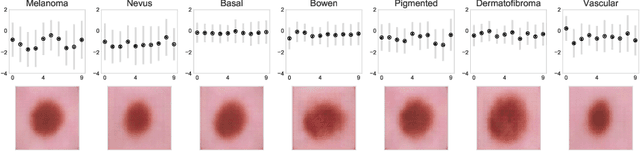
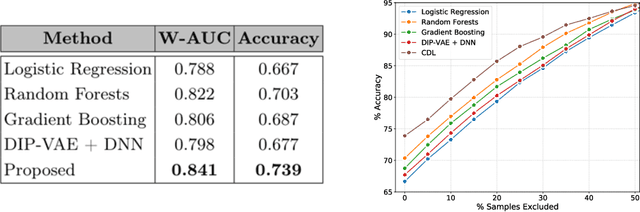
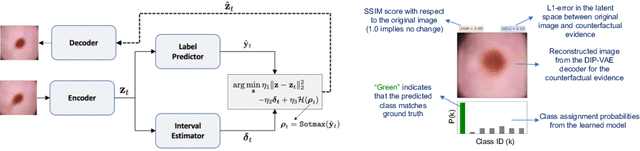
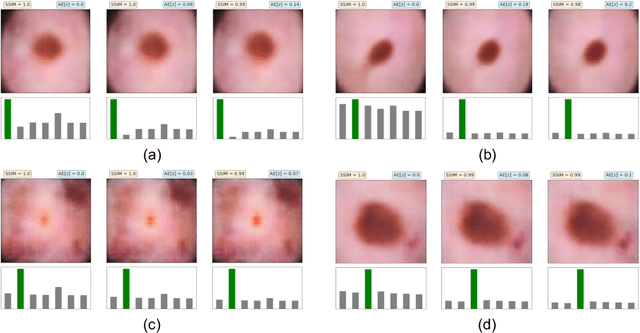
The wide-spread adoption of representation learning technologies in clinical decision making strongly emphasizes the need for characterizing model reliability and enabling rigorous introspection of model behavior. While the former need is often addressed by incorporating uncertainty quantification strategies, the latter challenge is addressed using a broad class of interpretability techniques. In this paper, we argue that these two objectives are not necessarily disparate and propose to utilize prediction calibration to meet both objectives. More specifically, our approach is comprised of a calibration-driven learning method, which is also used to design an interpretability technique based on counterfactual reasoning. Furthermore, we introduce \textit{reliability plots}, a holistic evaluation mechanism for model reliability. Using a lesion classification problem with dermoscopy images, we demonstrate the effectiveness of our approach and infer interesting insights about the model behavior.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020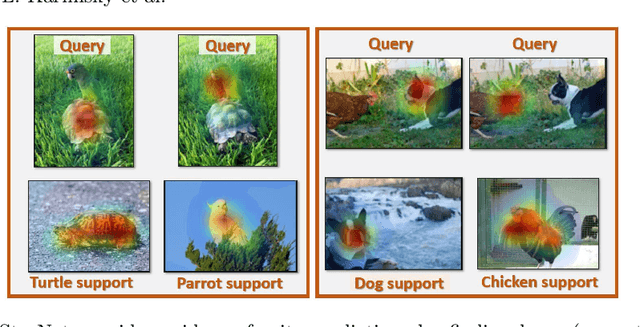
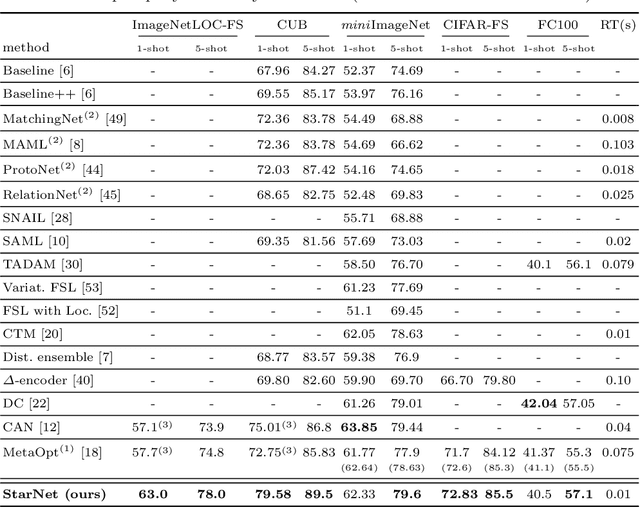
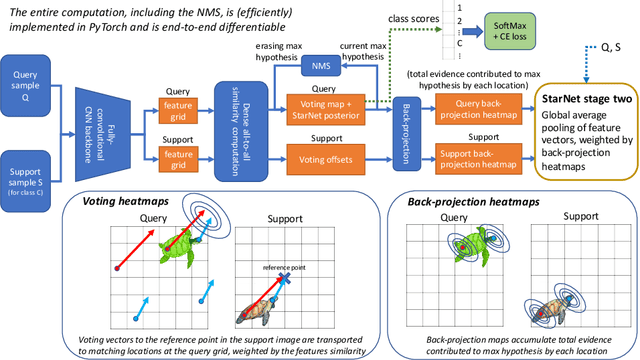
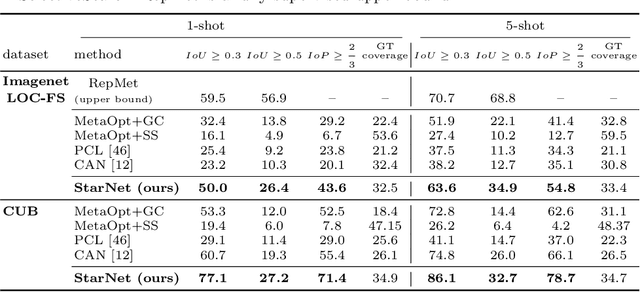
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
TAFSSL: Task-Adaptive Feature Sub-Space Learning for few-shot classification
Mar 14, 2020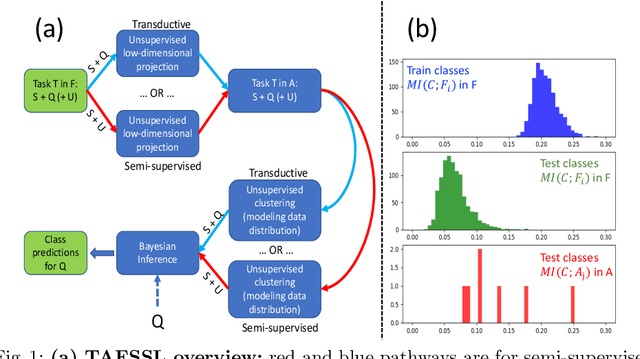
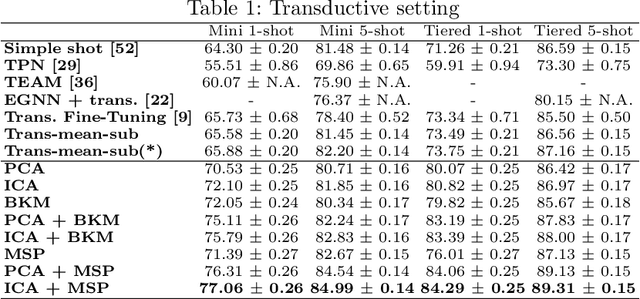
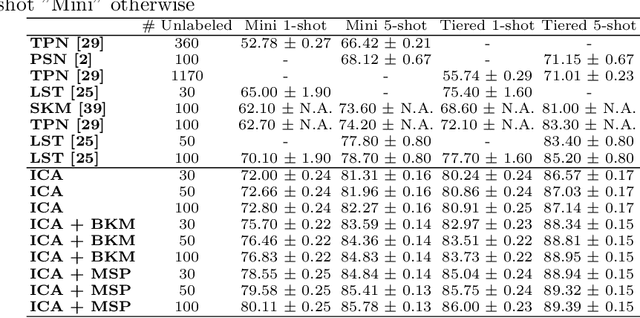
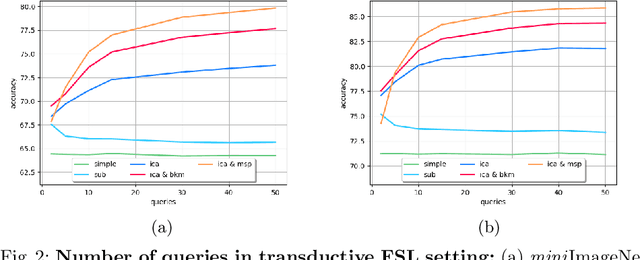
The field of Few-Shot Learning (FSL), or learning from very few (typically $1$ or $5$) examples per novel class (unseen during training), has received a lot of attention and significant performance advances in the recent literature. While number of techniques have been proposed for FSL, several factors have emerged as most important for FSL performance, awarding SOTA even to the simplest of techniques. These are: the backbone architecture (bigger is better), type of pre-training on the base classes (meta-training vs regular multi-class, currently regular wins), quantity and diversity of the base classes set (the more the merrier, resulting in richer and better adaptive features), and the use of self-supervised tasks during pre-training (serving as a proxy for increasing the diversity of the base set). In this paper we propose yet another simple technique that is important for the few shot learning performance - a search for a compact feature sub-space that is discriminative for a given few-shot test task. We show that the Task-Adaptive Feature Sub-Space Learning (TAFSSL) can significantly boost the performance in FSL scenarios when some additional unlabeled data accompanies the novel few-shot task, be it either the set of unlabeled queries (transductive FSL) or some additional set of unlabeled data samples (semi-supervised FSL). Specifically, we show that on the challenging miniImageNet and tieredImageNet benchmarks, TAFSSL can improve the current state-of-the-art in both transductive and semi-supervised FSL settings by more than $5\%$, while increasing the benefit of using unlabeled data in FSL to above $10\%$ performance gain.
Calibrate and Prune: Improving Reliability of Lottery Tickets Through Prediction Calibration
Feb 11, 2020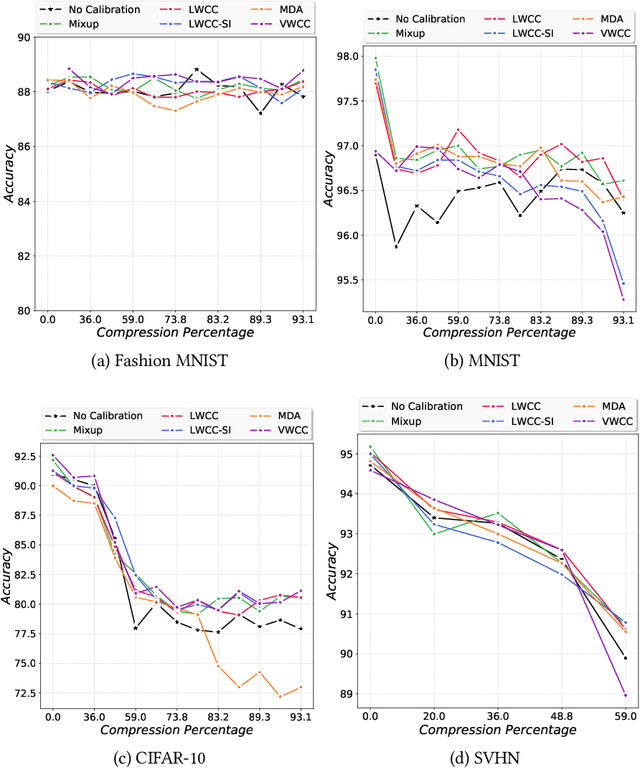
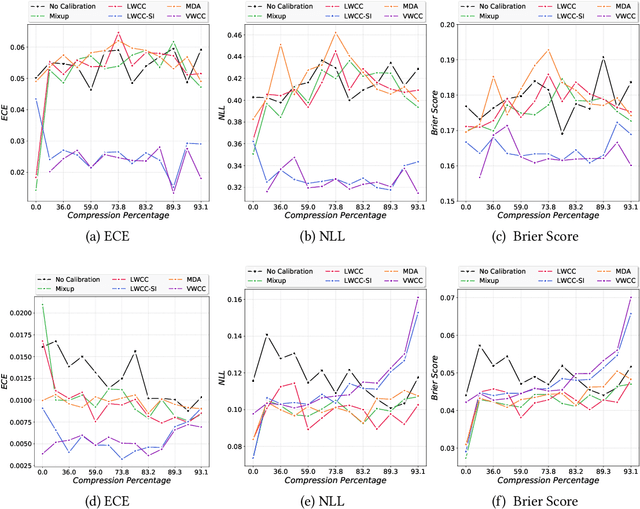
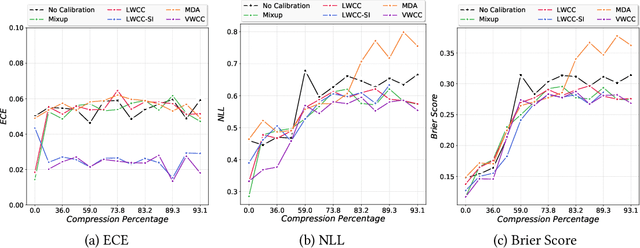
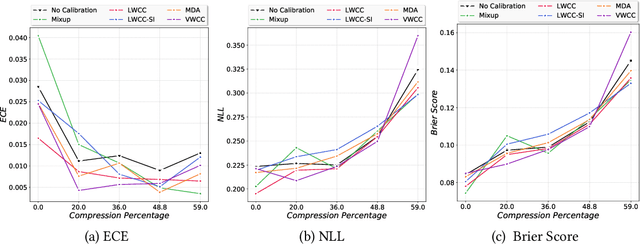
The hypothesis that sub-network initializations (lottery) exist within the initializations of over-parameterized networks, which when trained in isolation produce highly generalizable models, has led to crucial insights into network initialization and has enabled computationally efficient inferencing. In order to realize the full potential of these pruning strategies, particularly when utilized in transfer learning scenarios, it is necessary to understand the behavior of winning tickets when they might overfit to the dataset characteristics. In supervised and semi-supervised learning, prediction calibration is a commonly adopted strategy to handle such inductive biases in models. In this paper, we study the impact of incorporating calibration strategies during model training on the quality of the resulting lottery tickets, using several evaluation metrics. More specifically, we incorporate a suite of calibration strategies to different combinations of architectures and datasets, and evaluate the fidelity of sub-networks retrained based on winning tickets. Furthermore, we report the generalization performance of tickets across distributional shifts, when the inductive biases are explicitly controlled using calibration mechanisms. Finally, we provide key insights and recommendations for obtaining reliable lottery tickets, which we demonstrate to achieve improved generalization.