 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Ensemble-Based Uncertainty Quantification in Spatiotemporal Graph Neural Networks for Traffic Forecasting
Apr 05, 2022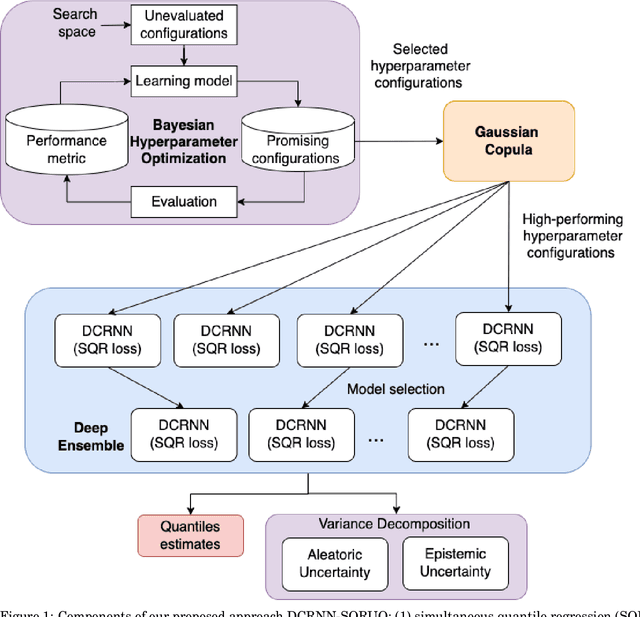
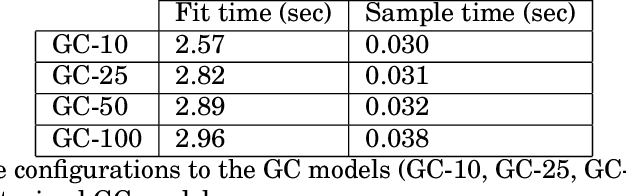
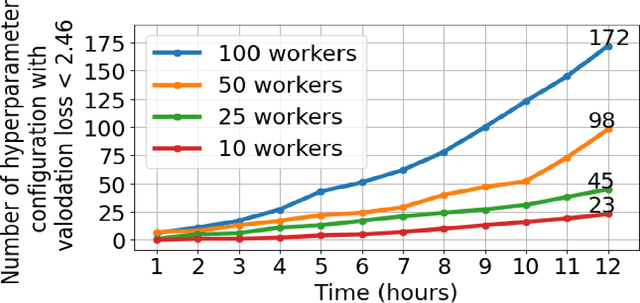
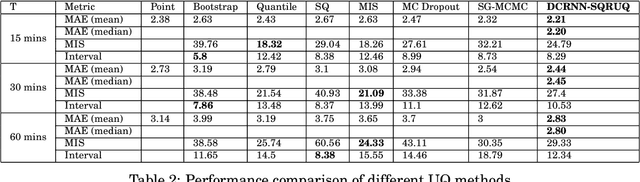
Deep-learning-based data-driven forecasting methods have produced impressive results for traffic forecasting. A major limitation of these methods, however, is that they provide forecasts without estimates of uncertainty, which are critical for real-time deployments. We focus on a diffusion convolutional recurrent neural network (DCRNN), a state-of-the-art method for short-term traffic forecasting. We develop a scalable deep ensemble approach to quantify uncertainties for DCRNN. Our approach uses a scalable Bayesian optimization method to perform hyperparameter optimization, selects a set of high-performing configurations, fits a generative model to capture the joint distributions of the hyperparameter configurations, and trains an ensemble of models by sampling a new set of hyperparameter configurations from the generative model. We demonstrate the efficacy of the proposed methods by comparing them with other uncertainty estimation techniques. We show that our generic and scalable approach outperforms the current state-of-the-art Bayesian and a number of other commonly used frequentist techniques.
Stabilized Neural Ordinary Differential Equations for Long-Time Forecasting of Dynamical Systems
Mar 29, 2022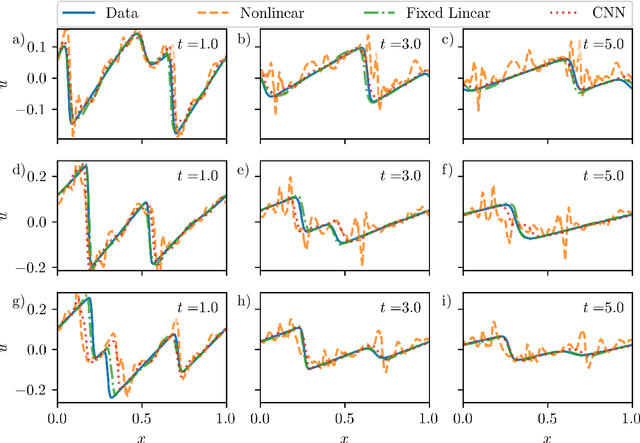
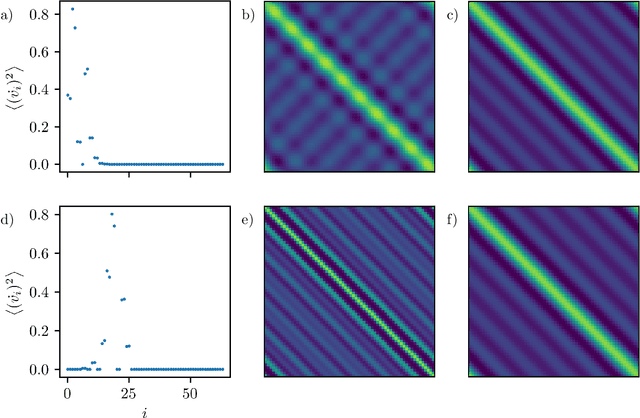
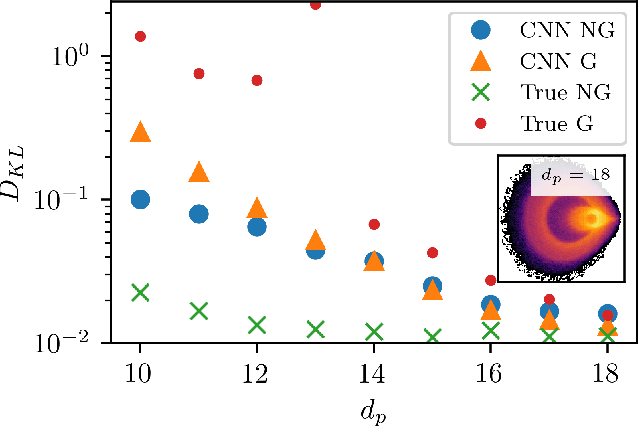
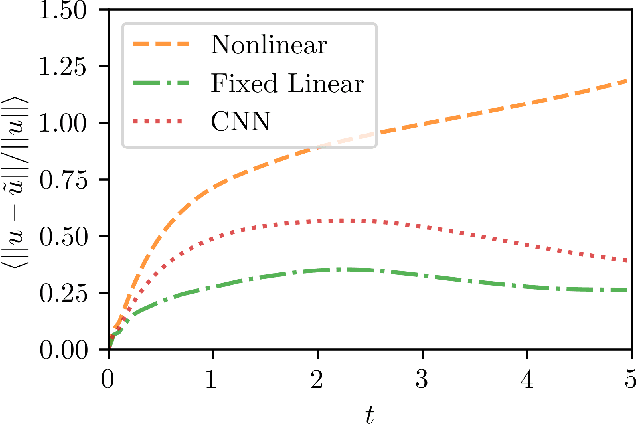
In data-driven modeling of spatiotemporal phenomena careful consideration often needs to be made in capturing the dynamics of the high wavenumbers. This problem becomes especially challenging when the system of interest exhibits shocks or chaotic dynamics. We present a data-driven modeling method that accurately captures shocks and chaotic dynamics by proposing a novel architecture, stabilized neural ordinary differential equation (ODE). In our proposed architecture, we learn the right-hand-side (RHS) of an ODE by adding the outputs of two NN together where one learns a linear term and the other a nonlinear term. Specifically, we implement this by training a sparse linear convolutional NN to learn the linear term and a dense fully-connected nonlinear NN to learn the nonlinear term. This is in contrast with the standard neural ODE which involves training only a single NN for learning the RHS. We apply this setup to the viscous Burgers equation, which exhibits shocked behavior, and show better short-time tracking and prediction of the energy spectrum at high wavenumbers than a standard neural ODE. We also find that the stabilized neural ODE models are much more robust to noisy initial conditions than the standard neural ODE approach. We also apply this method to chaotic trajectories of the Kuramoto-Sivashinsky equation. In this case, stabilized neural ODEs keep long-time trajectories on the attractor, and are highly robust to noisy initial conditions, while standard neural ODEs fail at achieving either of these results. We conclude by demonstrating how stabilizing neural ODEs provide a natural extension for use in reduced-order modeling by projecting the dynamics onto the eigenvectors of the learned linear term.
Sparsity-Inducing Categorical Prior Improves Robustness of the Information Bottleneck
Mar 04, 2022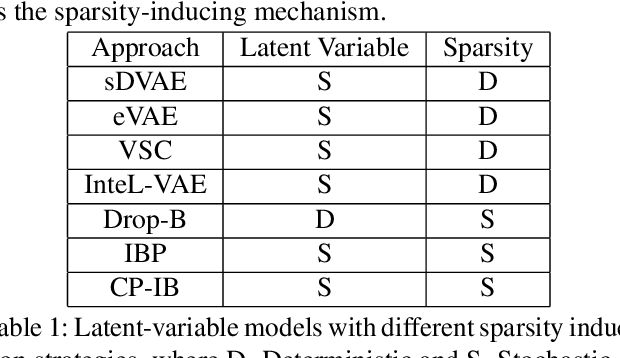
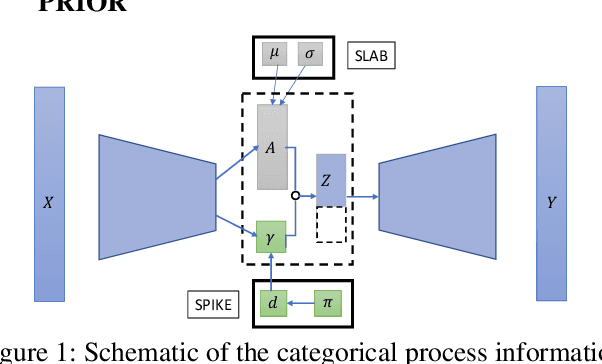
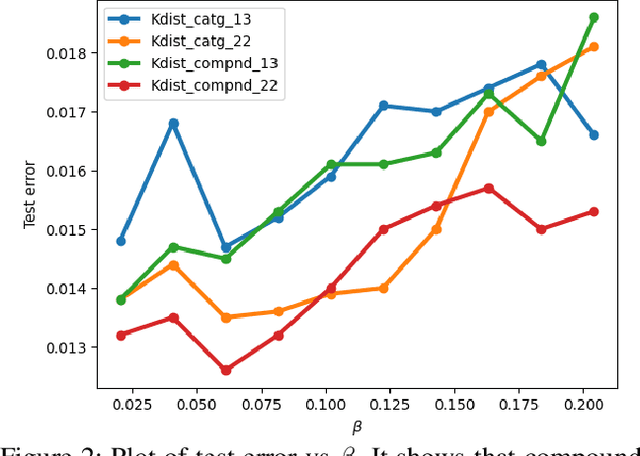
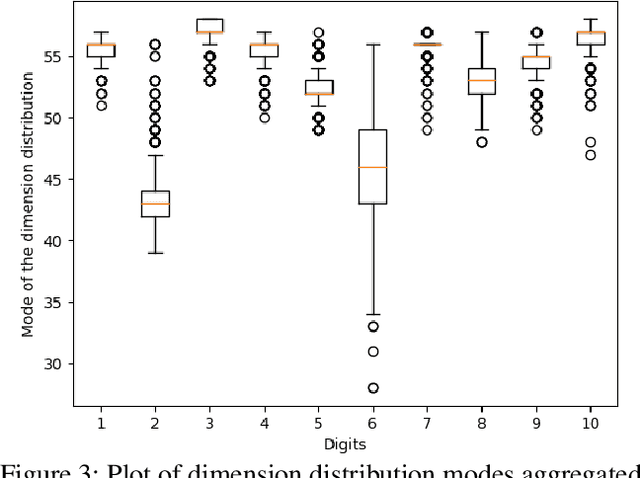
The information bottleneck framework provides a systematic approach to learn representations that compress nuisance information in inputs and extract semantically meaningful information about the predictions. However, the choice of the prior distribution that fix the dimensionality across all the data can restrict the flexibility of this approach to learn robust representations. We present a novel sparsity-inducing spike-slab prior that uses sparsity as a mechanism to provide flexibility that allows each data point to learn its own dimension distribution. In addition, it provides a mechanism to learn a joint distribution of the latent variable and the sparsity. Thus, unlike other approaches, it can account for the full uncertainty in the latent space. Through a series of experiments using in-distribution and out-of-distribution learning scenarios on the MNIST and Fashion-MNIST data we show that the proposed approach improves the accuracy and robustness compared with the traditional fixed -imensional priors as well as other sparsity-induction mechanisms proposed in the literature.
Multi-fidelity reinforcement learning framework for shape optimization
Feb 22, 2022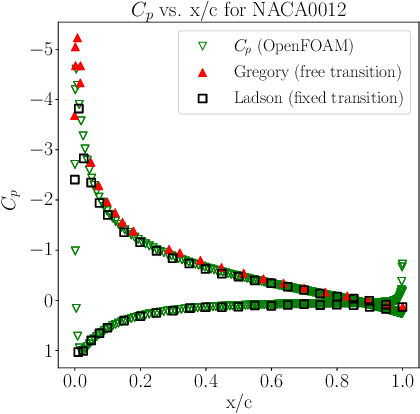
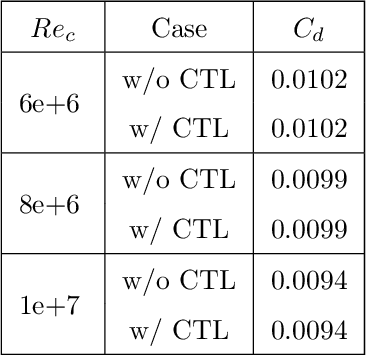
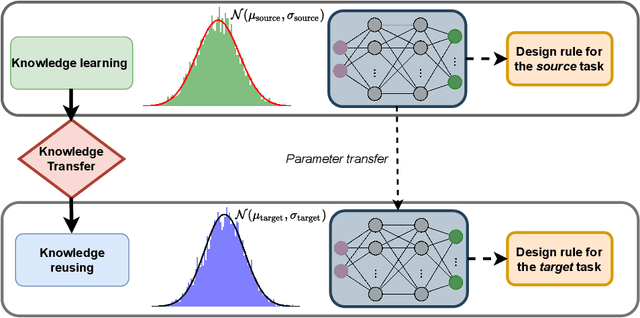
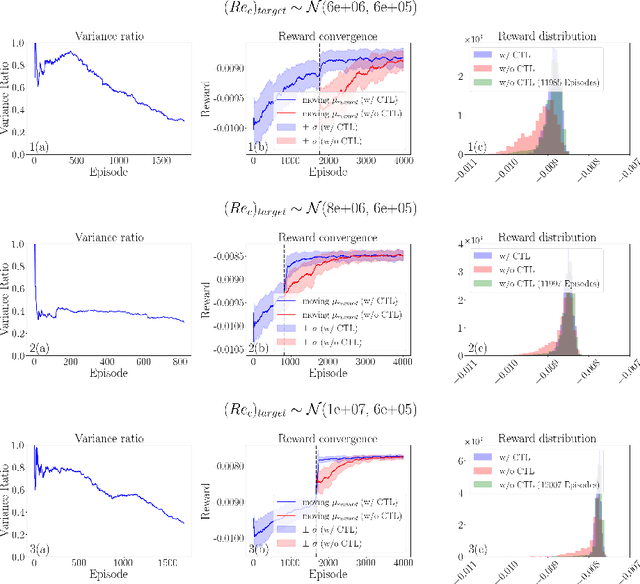
Deep reinforcement learning (DRL) is a promising outer-loop intelligence paradigm which can deploy problem solving strategies for complex tasks. Consequently, DRL has been utilized for several scientific applications, specifically in cases where classical optimization or control methods are limited. One key limitation of conventional DRL methods is their episode-hungry nature which proves to be a bottleneck for tasks which involve costly evaluations of a numerical forward model. In this article, we address this limitation of DRL by introducing a controlled transfer learning framework that leverages a multi-fidelity simulation setting. Our strategy is deployed for an airfoil shape optimization problem at high Reynolds numbers, where our framework can learn an optimal policy for generating efficient airfoil shapes by gathering knowledge from multi-fidelity environments and reduces computational costs by over 30\%. Furthermore, our formulation promotes policy exploration and generalization to new environments, thereby preventing over-fitting to data from solely one fidelity. Our results demonstrate this framework's applicability to other scientific DRL scenarios where multi-fidelity environments can be used for policy learning.
A data-centric weak supervised learning for highway traffic incident detection
Dec 17, 2021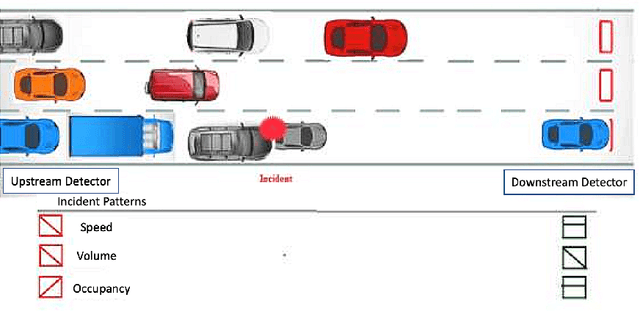
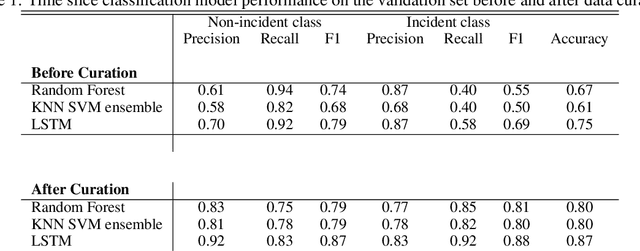
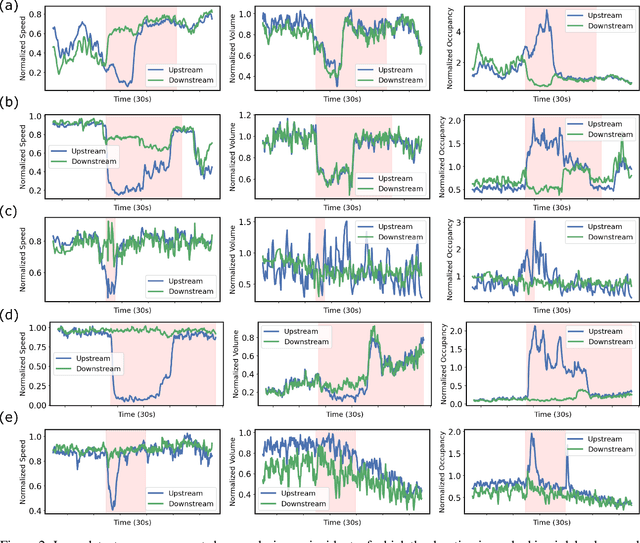
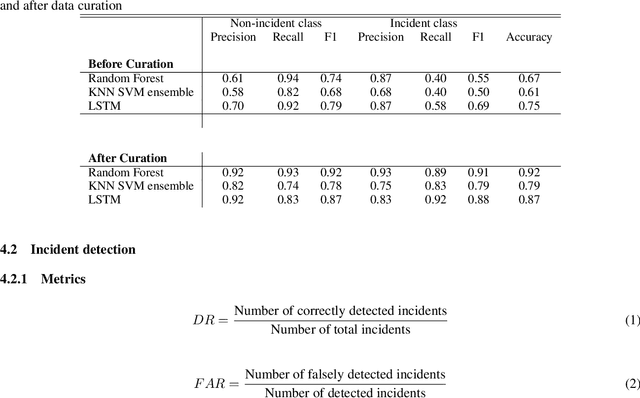
Using the data from loop detector sensors for near-real-time detection of traffic incidents in highways is crucial to averting major traffic congestion. While recent supervised machine learning methods offer solutions to incident detection by leveraging human-labeled incident data, the false alarm rate is often too high to be used in practice. Specifically, the inconsistency in the human labeling of the incidents significantly affects the performance of supervised learning models. To that end, we focus on a data-centric approach to improve the accuracy and reduce the false alarm rate of traffic incident detection on highways. We develop a weak supervised learning workflow to generate high-quality training labels for the incident data without the ground truth labels, and we use those generated labels in the supervised learning setup for final detection. This approach comprises three stages. First, we introduce a data preprocessing and curation pipeline that processes traffic sensor data to generate high-quality training data through leveraging labeling functions, which can be domain knowledge-related or simple heuristic rules. Second, we evaluate the training data generated by weak supervision using three supervised learning models -- random forest, k-nearest neighbors, and a support vector machine ensemble -- and long short-term memory classifiers. The results show that the accuracy of all of the models improves significantly after using the training data generated by weak supervision. Third, we develop an online real-time incident detection approach that leverages the model ensemble and the uncertainty quantification while detecting incidents. Overall, we show that our proposed weak supervised learning workflow achieves a high incident detection rate (0.90) and low false alarm rate (0.08).
Modeling Design and Control Problems Involving Neural Network Surrogates
Nov 20, 2021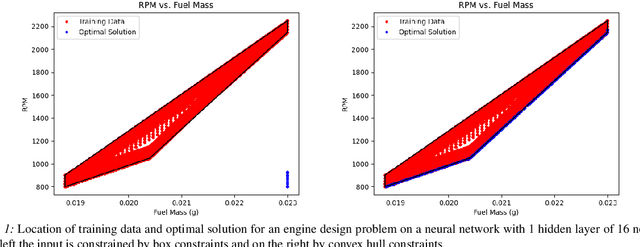
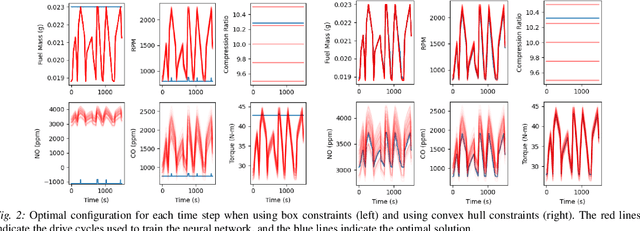

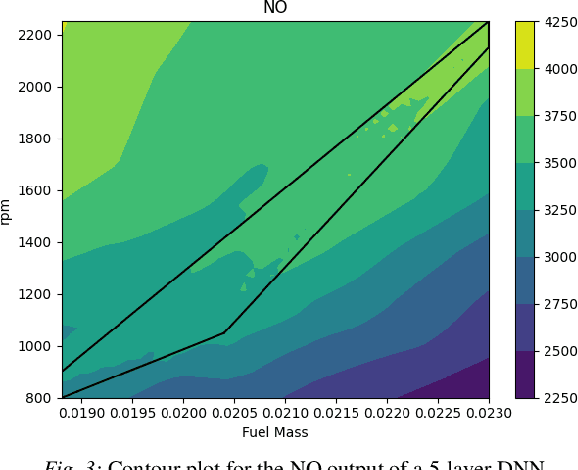
We consider nonlinear optimization problems that involve surrogate models represented by neural networks. We demonstrate first how to directly embed neural network evaluation into optimization models, highlight a difficulty with this approach that can prevent convergence, and then characterize stationarity of such models. We then present two alternative formulations of these problems in the specific case of feedforward neural networks with ReLU activation: as a mixed-integer optimization problem and as a mathematical program with complementarity constraints. For the latter formulation we prove that stationarity at a point for this problem corresponds to stationarity of the embedded formulation. Each of these formulations may be solved with state-of-the-art optimization methods, and we show how to obtain good initial feasible solutions for these methods. We compare our formulations on three practical applications arising in the design and control of combustion engines, in the generation of adversarial attacks on classifier networks, and in the determination of optimal flows in an oil well network.
AutoDEUQ: Automated Deep Ensemble with Uncertainty Quantification
Oct 26, 2021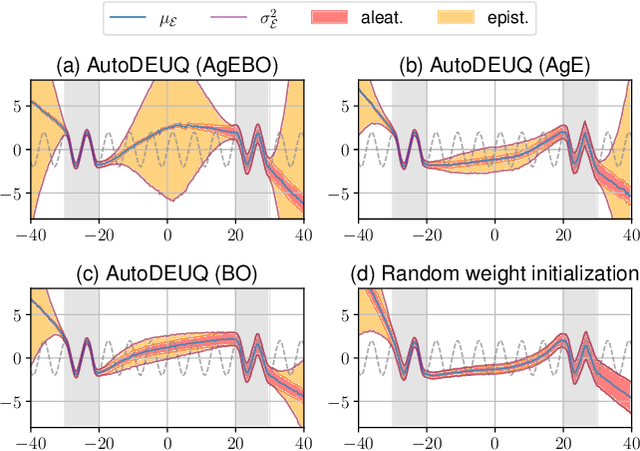
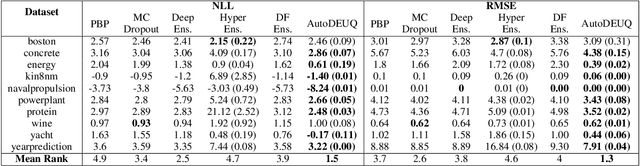
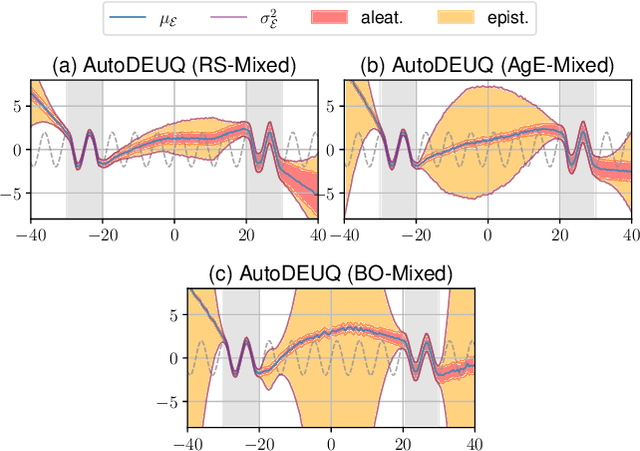
Deep neural networks are powerful predictors for a variety of tasks. However, they do not capture uncertainty directly. Using neural network ensembles to quantify uncertainty is competitive with approaches based on Bayesian neural networks while benefiting from better computational scalability. However, building ensembles of neural networks is a challenging task because, in addition to choosing the right neural architecture or hyperparameters for each member of the ensemble, there is an added cost of training each model. We propose AutoDEUQ, an automated approach for generating an ensemble of deep neural networks. Our approach leverages joint neural architecture and hyperparameter search to generate ensembles. We use the law of total variance to decompose the predictive variance of deep ensembles into aleatoric (data) and epistemic (model) uncertainties. We show that AutoDEUQ outperforms probabilistic backpropagation, Monte Carlo dropout, deep ensemble, distribution-free ensembles, and hyper ensemble methods on a number of regression benchmarks.
Formalizing the Generalization-Forgetting Trade-off in Continual Learning
Oct 05, 2021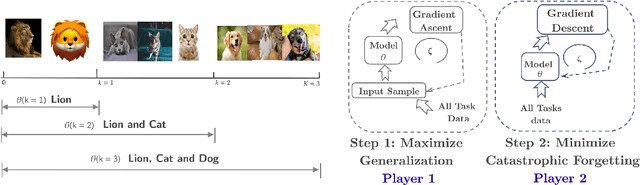
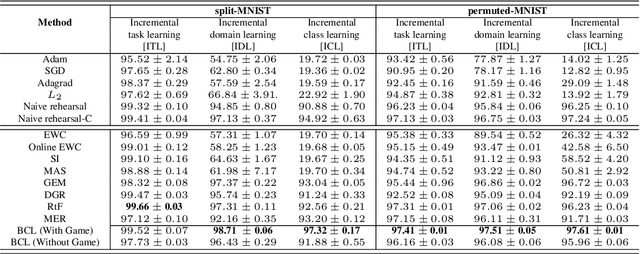
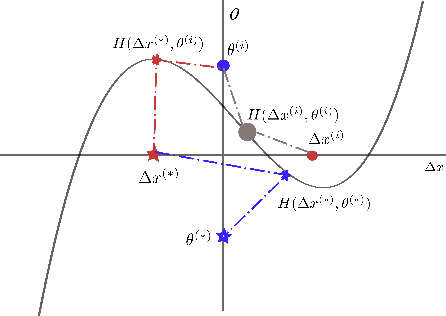
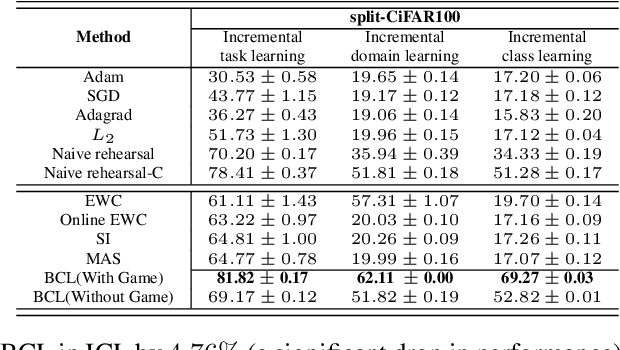
We formulate the continual learning (CL) problem via dynamic programming and model the trade-off between catastrophic forgetting and generalization as a two-player sequential game. In this approach, player 1 maximizes the cost due to lack of generalization whereas player 2 minimizes the cost due to catastrophic forgetting. We show theoretically that a balance point between the two players exists for each task and that this point is stable (once the balance is achieved, the two players stay at the balance point). Next, we introduce balanced continual learning (BCL), which is designed to attain balance between generalization and forgetting and empirically demonstrate that BCL is comparable to or better than the state of the art.
AutoPhaseNN: Unsupervised Physics-aware Deep Learning of 3D Nanoscale Coherent Imaging
Sep 28, 2021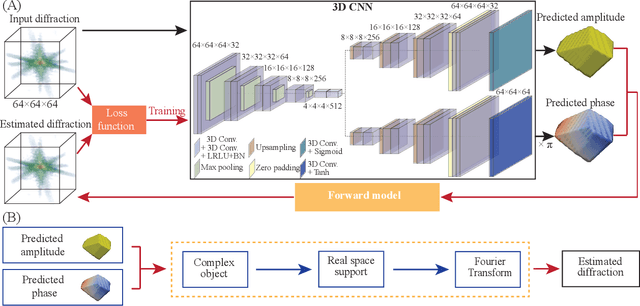
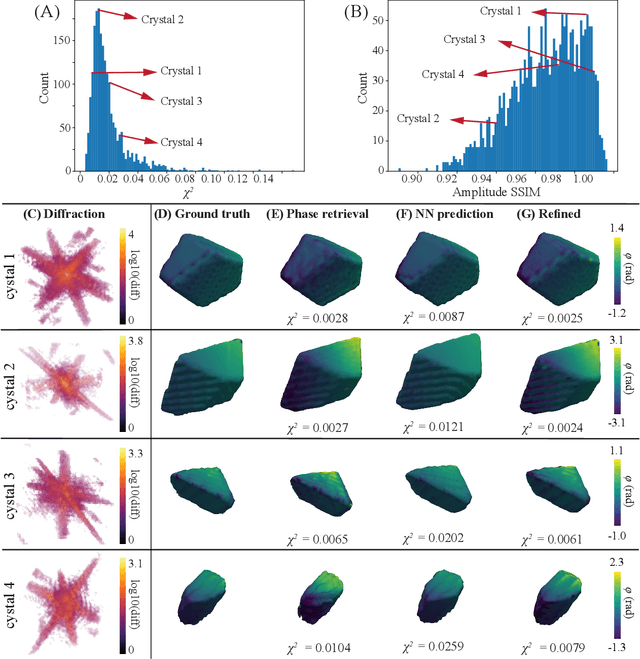
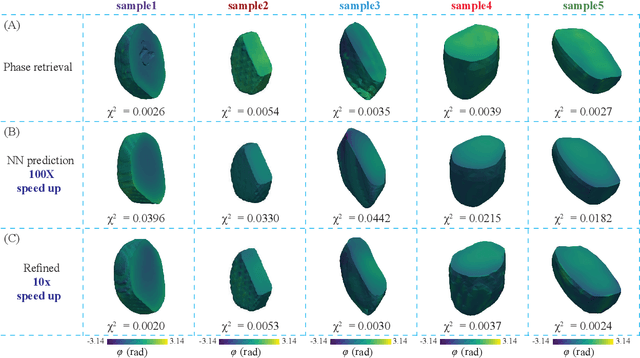
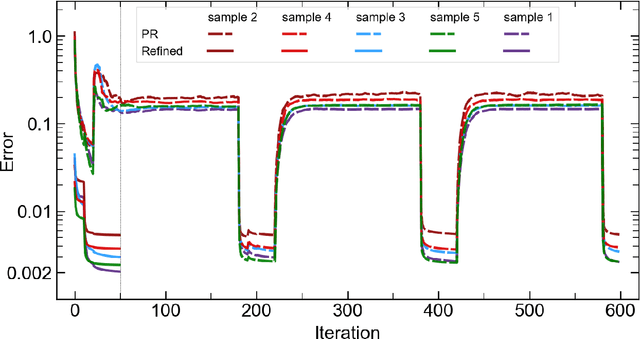
The problem of phase retrieval, or the algorithmic recovery of lost phase information from measured intensity alone, underlies various imaging methods from astronomy to nanoscale imaging. Traditional methods of phase retrieval are iterative in nature, and are therefore computationally expensive and time consuming. More recently, deep learning (DL) models have been developed to either provide learned priors to iterative phase retrieval or in some cases completely replace phase retrieval with networks that learn to recover the lost phase information from measured intensity alone. However, such models require vast amounts of labeled data, which can only be obtained through simulation or performing computationally prohibitive phase retrieval on hundreds of or even thousands of experimental datasets. Using a 3D nanoscale X-ray imaging modality (Bragg Coherent Diffraction Imaging or BCDI) as a representative technique, we demonstrate AutoPhaseNN, a DL-based approach which learns to solve the phase problem without labeled data. By incorporating the physics of the imaging technique into the DL model during training, AutoPhaseNN learns to invert 3D BCDI data from reciprocal space to real space in a single shot without ever being shown real space images. Once trained, AutoPhaseNN is about one hundred times faster than traditional iterative phase retrieval methods while providing comparable image quality.
Customized Monte Carlo Tree Search for LLVM/Polly's Composable Loop Optimization Transformations
May 10, 2021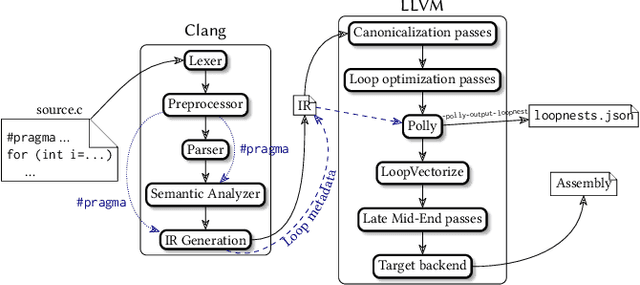
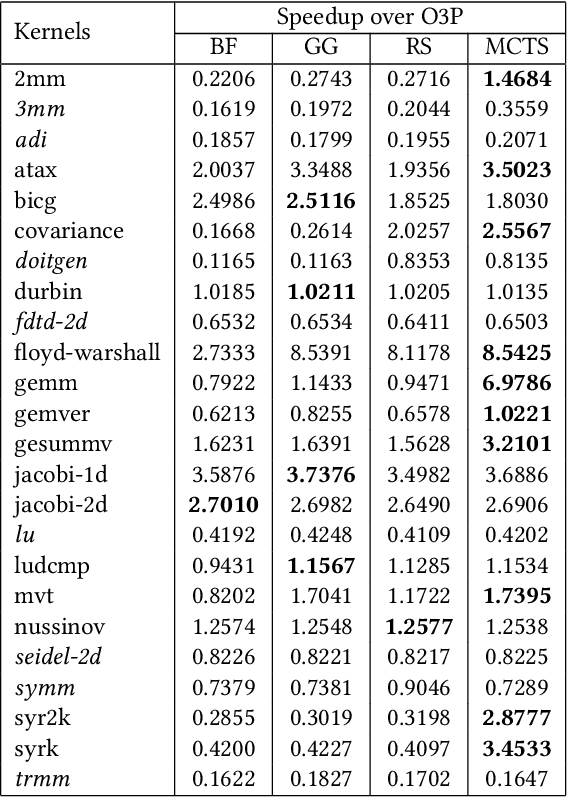
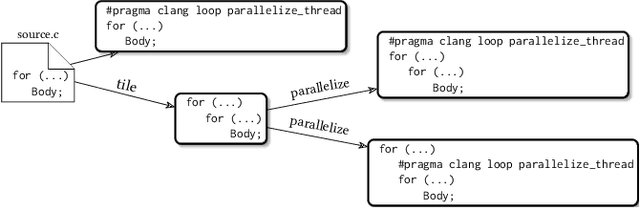
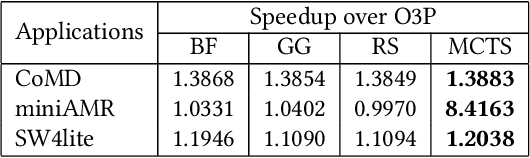
Polly is the LLVM project's polyhedral loop nest optimizer. Recently, user-directed loop transformation pragmas were proposed based on LLVM/Clang and Polly. The search space exposed by the transformation pragmas is a tree, wherein each node represents a specific combination of loop transformations that can be applied to the code resulting from the parent node's loop transformations. We have developed a search algorithm based on Monte Carlo tree search (MCTS) to find the best combination of loop transformations. Our algorithm consists of two phases: exploring loop transformations at different depths of the tree to identify promising regions in the tree search space and exploiting those regions by performing a local search. Moreover, a restart mechanism is used to avoid the MCTS getting trapped in a local solution. The best and worst solutions are transferred from the previous phases of the restarts to leverage the search history. We compare our approach with random, greedy, and breadth-first search methods on PolyBench kernels and ECP proxy applications. Experimental results show that our MCTS algorithm finds pragma combinations with a speedup of 2.3x over Polly's heuristic optimizations on average.