 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing NOMA Transmissions to Advance Federated Learning in Vehicular Networks
Aug 06, 2024



Diverse critical data, such as location information and driving patterns, can be collected by IoT devices in vehicular networks to improve driving experiences and road safety. However, drivers are often reluctant to share their data due to privacy concerns. The Federated Vehicular Network (FVN) is a promising technology that tackles these concerns by transmitting model parameters instead of raw data, thereby protecting the privacy of drivers. Nevertheless, the performance of Federated Learning (FL) in a vehicular network depends on the joining ratio, which is restricted by the limited available wireless resources. To address these challenges, this paper proposes to apply Non-Orthogonal Multiple Access (NOMA) to improve the joining ratio in a FVN. Specifically, a vehicle selection and transmission power control algorithm is developed to exploit the power domain differences in the received signal to ensure the maximum number of vehicles capable of joining the FVN. Our simulation results demonstrate that the proposed NOMA-based strategy increases the joining ratio and significantly enhances the performance of the FVN.
A Deep Reinforcement Learning based Approach for NOMA-based Random Access Network with Truncated Channel Inversion Power Control
Feb 22, 2022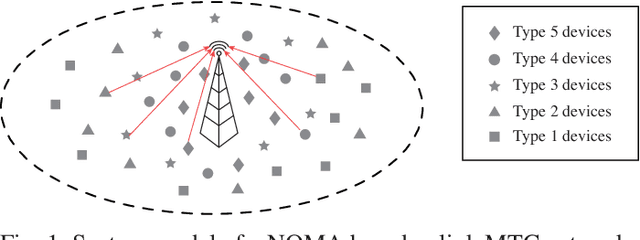
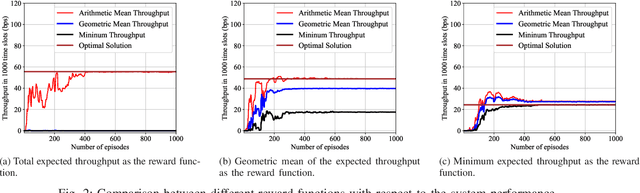

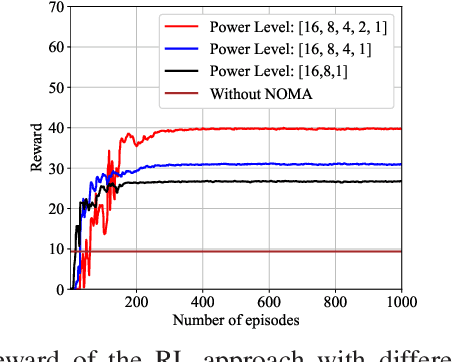
As a main use case of 5G and Beyond wireless network, the ever-increasing machine type communications (MTC) devices pose critical challenges over MTC network in recent years. It is imperative to support massive MTC devices with limited resources. To this end, Non-orthogonal multiple access (NOMA) based random access network has been deemed as a prospective candidate for MTC network. In this paper, we propose a deep reinforcement learning (RL) based approach for NOMA-based random access network with truncated channel inversion power control. Specifically, each MTC device randomly selects a pre-defined power level with a certain probability for data transmission. Devices are using channel inversion power control yet subject to the upper bound of the transmission power. Due to the stochastic feature of the channel fading and the limited transmission power, devices with different achievable power levels have been categorized as different types of devices. In order to achieve high throughput with considering the fairness between all devices, two objective functions are formulated. One is to maximize the minimum long-term expected throughput of all MTC devices, the other is to maximize the geometric mean of the long-term expected throughput for all MTC devices. A Policy based deep reinforcement learning approach is further applied to tune the transmission probabilities of each device to solve the formulated optimization problems. Extensive simulations are conducted to show the merits of our proposed approach.
Responsive Regulation of Dynamic UAV Communication Networks Based on Deep Reinforcement Learning
Aug 25, 2021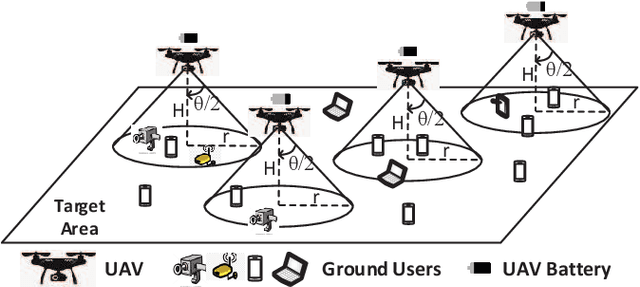
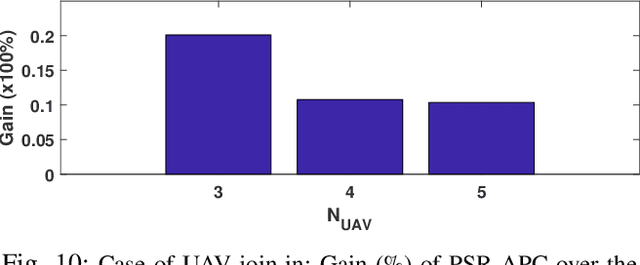
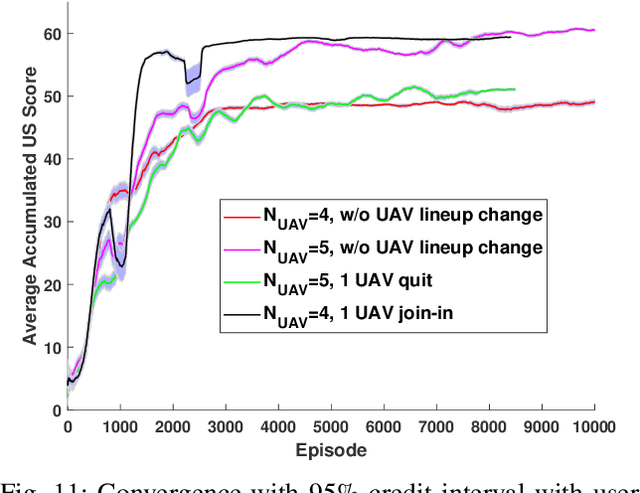
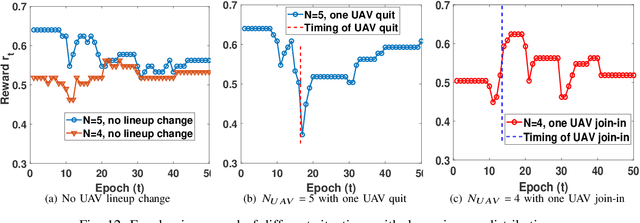
In this chapter, the regulation of Unmanned Aerial Vehicle (UAV) communication network is investigated in the presence of dynamic changes in the UAV lineup and user distribution. We target an optimal UAV control policy which is capable of identifying the upcoming change in the UAV lineup (quit or join-in) or user distribution, and proactively relocating the UAVs ahead of the change rather than passively dispatching the UAVs after the change. Specifically, a deep reinforcement learning (DRL)-based UAV control framework is developed to maximize the accumulated user satisfaction (US) score for a given time horizon which is able to handle the change in both the UAV lineup and user distribution. The framework accommodates the changed dimension of the state-action space before and after the UAV lineup change by deliberate state transition design. In addition, to handle the continuous state and action space, deep deterministic policy gradient (DDPG) algorithm, which is an actor-critic based DRL, is exploited. Furthermore, to promote the learning exploration around the timing of the change, the original DDPG is adapted into an asynchronous parallel computing (APC) structure which leads to a better training performance in both the critic and actor networks. Finally, extensive simulations are conducted to validate the convergence of the proposed learning approach, and demonstrate its capability in jointly handling the dynamics in UAV lineup and user distribution as well as its superiority over a passive reaction method.
Learning-Based Distributed Random Access for Multi-Cell IoT Networks with NOMA
Jan 02, 2021
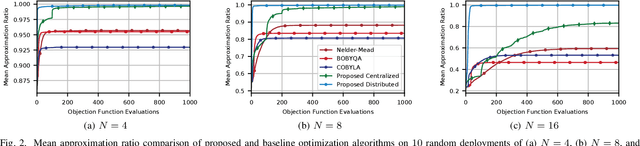
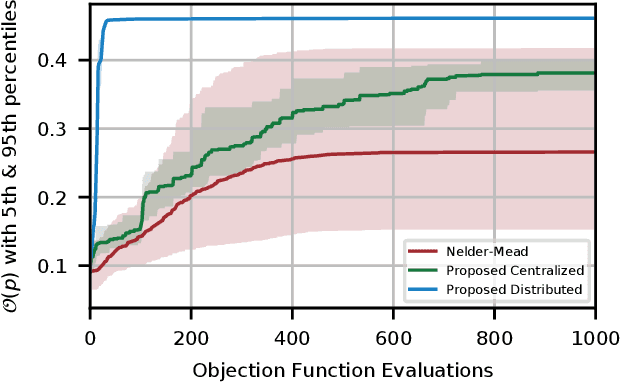
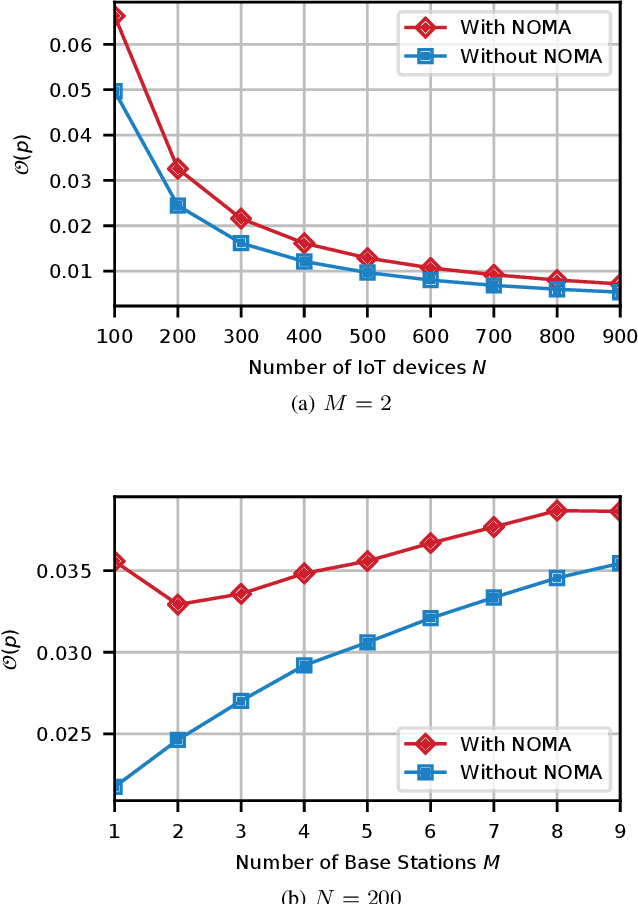
Non-orthogonal multiple access (NOMA) is a key technology to enable massive machine type communications (mMTC) in 5G networks and beyond. In this paper, NOMA is applied to improve the random access efficiency in high-density spatially-distributed multi-cell wireless IoT networks, where IoT devices contend for accessing the shared wireless channel using an adaptive p-persistent slotted Aloha protocol. To enable a capacity-optimal network, a novel formulation of random channel access with NOMA is proposed, in which the transmission probability of each IoT device is tuned to maximize the geometric mean of users' expected capacity. It is shown that the network optimization objective is high dimensional and mathematically intractable, yet it admits favourable mathematical properties that enable the design of efficient learning-based algorithmic solutions. To this end, two algorithms, i.e., a centralized model-based algorithm and a scalable distributed model-free algorithm, are proposed to optimally tune the transmission probabilities of IoT devices to attain the maximum capacity. The convergence of the proposed algorithms to the optimal solution is further established based on convex optimization and game-theoretic analysis. Extensive simulations demonstrate the merits of the novel formulation and the efficacy of the proposed algorithms.
SREC: Proactive Self-Remedy of Energy-Constrained UAV-Based Networks via Deep Reinforcement Learning
Sep 17, 2020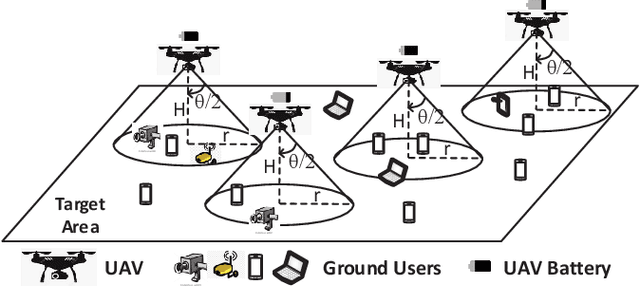
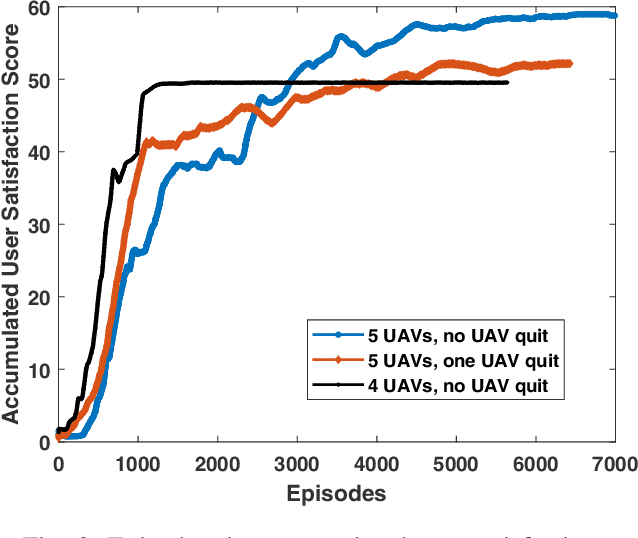
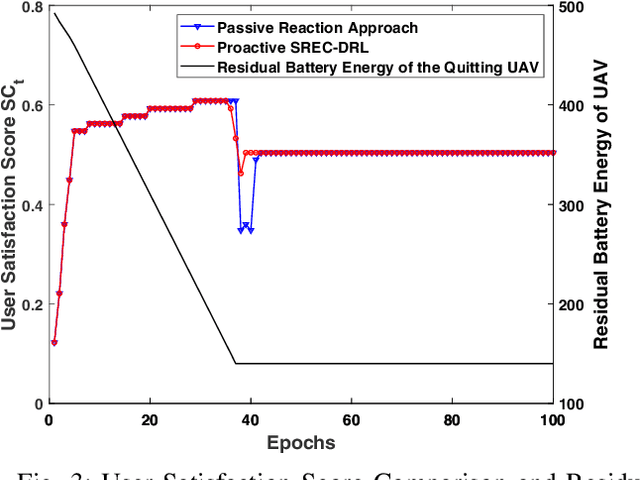
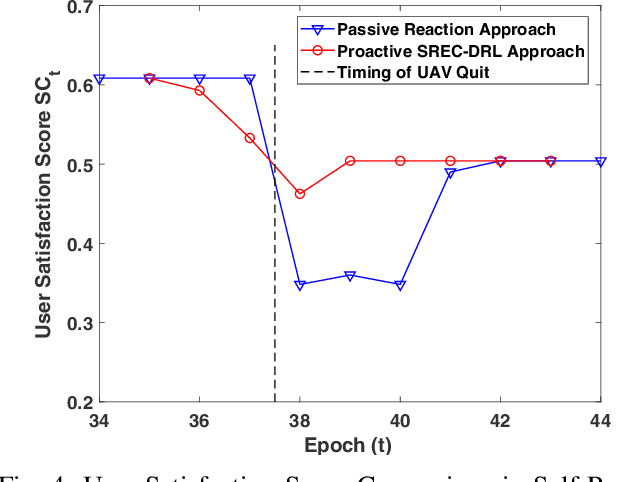
Energy-aware control for multiple unmanned aerial vehicles (UAVs) is one of the major research interests in UAV based networking. Yet few existing works have focused on how the network should react around the timing when the UAV lineup is changed. In this work, we study proactive self-remedy of energy-constrained UAV networks when one or more UAVs are short of energy and about to quit for charging. We target at an energy-aware optimal UAV control policy which proactively relocates the UAVs when any UAV is about to quit the network, rather than passively dispatches the remaining UAVs after the quit. Specifically, a deep reinforcement learning (DRL)-based self remedy approach, named SREC-DRL, is proposed to maximize the accumulated user satisfaction scores for a certain period within which at least one UAV will quit the network. To handle the continuous state and action space in the problem, the state-of-the-art algorithm of the actor-critic DRL, i.e., deep deterministic policy gradient (DDPG), is applied with better convergence stability. Numerical results demonstrate that compared with the passive reaction method, the proposed SREC-DRL approach shows a $12.12\%$ gain in accumulative user satisfaction score during the remedy period.
A Gradient-Aware Search Algorithm for Constrained Markov Decision Processes
May 07, 2020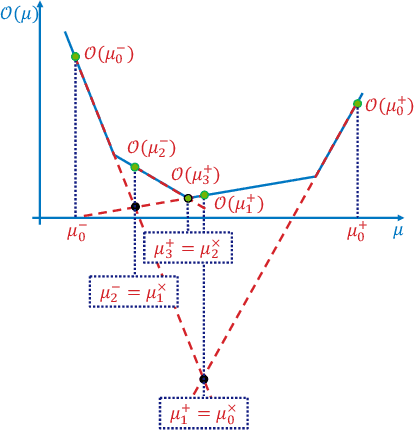
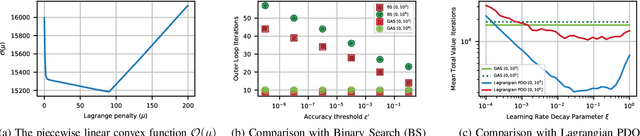

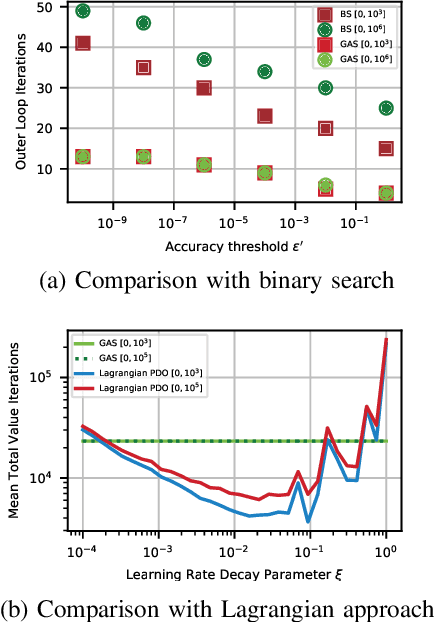
The canonical solution methodology for finite constrained Markov decision processes (CMDPs), where the objective is to maximize the expected infinite-horizon discounted rewards subject to the expected infinite-horizon discounted costs constraints, is based on convex linear programming. In this brief, we first prove that the optimization objective in the dual linear program of a finite CMDP is a piece-wise linear convex function (PWLC) with respect to the Lagrange penalty multipliers. Next, we propose a novel two-level Gradient-Aware Search (GAS) algorithm which exploits the PWLC structure to find the optimal state-value function and Lagrange penalty multipliers of a finite CMDP. The proposed algorithm is applied in two stochastic control problems with constraints: robot navigation in a grid world and solar-powered unmanned aerial vehicle (UAV)-based wireless network management. We empirically compare the convergence performance of the proposed GAS algorithm with binary search (BS), Lagrangian primal-dual optimization (PDO), and Linear Programming (LP). Compared with benchmark algorithms, it is shown that the proposed GAS algorithm converges to the optimal solution faster, does not require hyper-parameter tuning, and is not sensitive to initialization of the Lagrange penalty multiplier.
Constrained Deep Reinforcement Learning for Energy Sustainable Multi-UAV based Random Access IoT Networks with NOMA
Feb 05, 2020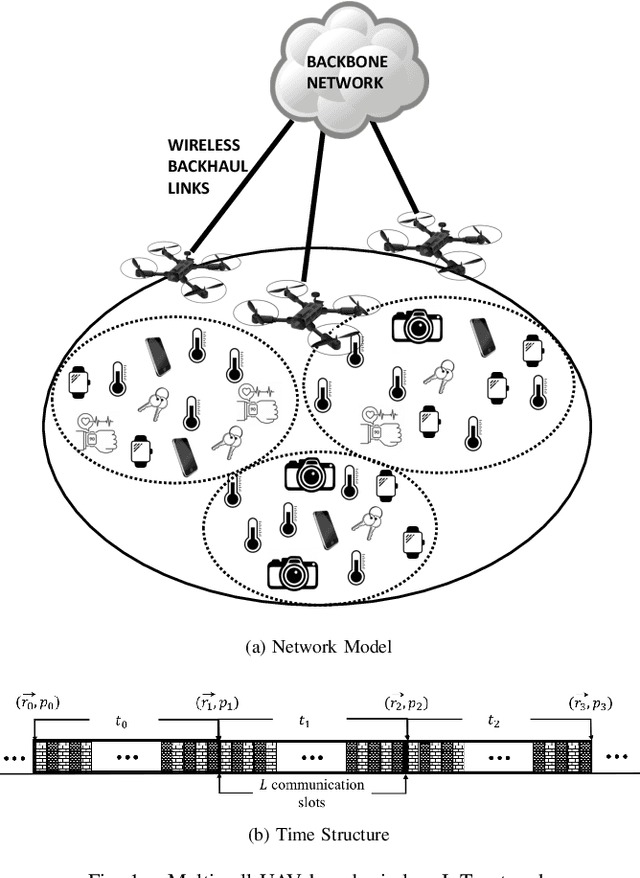
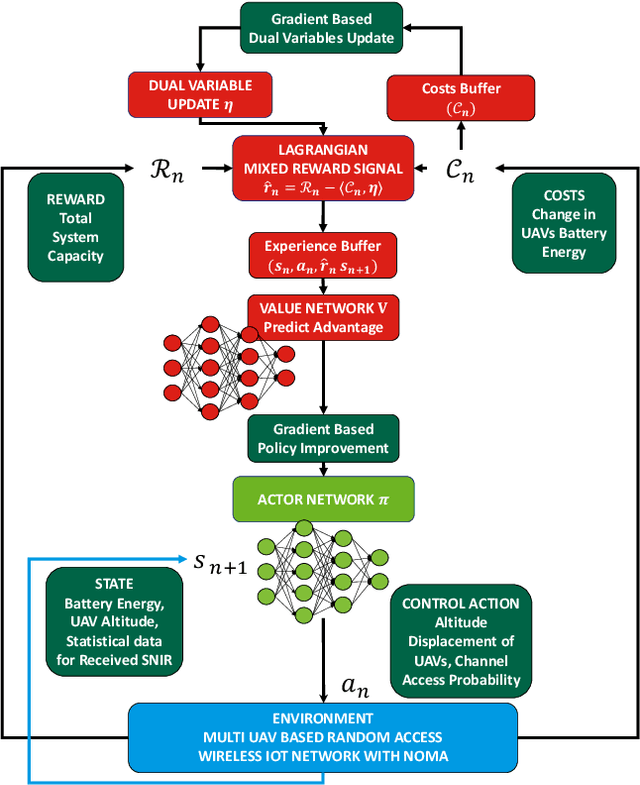
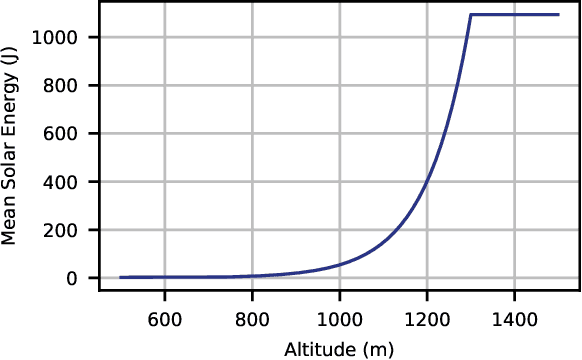
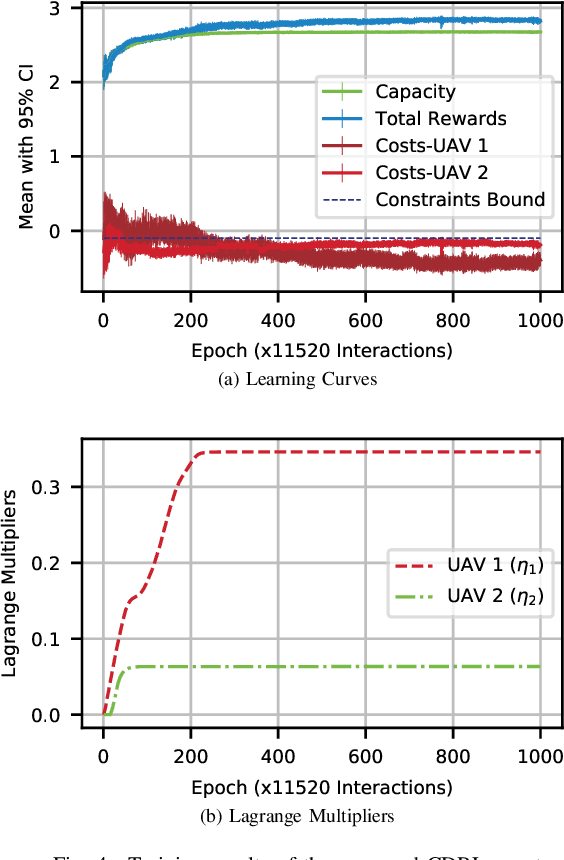
In this paper, we apply the Non-Orthogonal Multiple Access (NOMA) technique to improve the massive channel access of a wireless IoT network where solar-powered Unmanned Aerial Vehicles (UAVs) relay data from IoT devices to remote servers. Specifically, IoT devices contend for accessing the shared wireless channel using an adaptive $p$-persistent slotted Aloha protocol; and the solar-powered UAVs adopt Successive Interference Cancellation (SIC) to decode multiple received data from IoT devices to improve access efficiency. To enable an energy-sustainable capacity-optimal network, we study the joint problem of dynamic multi-UAV altitude control and multi-cell wireless channel access management of IoT devices as a stochastic control problem with multiple energy constraints. To learn an optimal control policy, we first formulate this problem as a Constrained Markov Decision Process (CMDP), and propose an online model-free Constrained Deep Reinforcement Learning (CDRL) algorithm based on Lagrangian primal-dual policy optimization to solve the CMDP. Extensive simulations demonstrate that our proposed algorithm learns a cooperative policy among UAVs in which the altitude of UAVs and channel access probability of IoT devices are dynamically and jointly controlled to attain the maximal long-term network capacity while maintaining energy sustainability of UAVs. The proposed algorithm outperforms Deep RL based solutions with reward shaping to account for energy costs, and achieves a temporal average system capacity which is $82.4\%$ higher than that of a feasible DRL based solution, and only $6.47\%$ lower compared to that of the energy-constraint-free system.