 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient RGB-Only Action Recognition for Edge Deployment
Feb 11, 2026Action recognition on edge devices poses stringent constraints on latency, memory, storage, and power consumption. While auxiliary modalities such as skeleton and depth information can enhance recognition performance, they often require additional sensors or computationally expensive pose-estimation pipelines, limiting practicality for edge use. In this work, we propose a compact RGB-only network tailored for efficient on-device inference. Our approach builds upon an X3D-style backbone augmented with Temporal Shift, and further introduces selective temporal adaptation and parameter-free attention. Extensive experiments on the NTU RGB+D 60 and 120 benchmarks demonstrate a strong accuracy-efficiency balance. Moreover, deployment-level profiling on the Jetson Orin Nano verifies a smaller on-device footprint and practical resource utilization compared to existing RGB-based action recognition techniques.
From Prompts to Deployment: Auto-Curated Domain-Specific Dataset Generation via Diffusion Models
Jan 13, 2026In this paper, we present an automated pipeline for generating domain-specific synthetic datasets with diffusion models, addressing the distribution shift between pre-trained models and real-world deployment environments. Our three-stage framework first synthesizes target objects within domain-specific backgrounds through controlled inpainting. The generated outputs are then validated via a multi-modal assessment that integrates object detection, aesthetic scoring, and vision-language alignment. Finally, a user-preference classifier is employed to capture subjective selection criteria. This pipeline enables the efficient construction of high-quality, deployable datasets while reducing reliance on extensive real-world data collection.
Effective Slogan Generation with Noise Perturbation
Oct 12, 2023



Slogans play a crucial role in building the brand's identity of the firm. A slogan is expected to reflect firm's vision and brand's value propositions in memorable and likeable ways. Automating the generation of slogans with such characteristics is challenging. Previous studies developted and tested slogan generation with syntactic control and summarization models which are not capable of generating distinctive slogans. We introduce a a novel apporach that leverages pre-trained transformer T5 model with noise perturbation on newly proposed 1:N matching pair dataset. This approach serves as a contributing fator in generting distinctive and coherent slogans. Turthermore, the proposed approach incorporates descriptions about the firm and brand into the generation of slogans. We evaluate generated slogans based on ROUGE1, ROUGEL and Cosine Similarity metrics and also assess them with human subjects in terms of slogan's distinctiveness, coherence, and fluency. The results demonstrate that our approach yields better performance than baseline models and other transformer-based models.
Technical Report for CVPR 2022 LOVEU AQTC Challenge
Jun 29, 2022

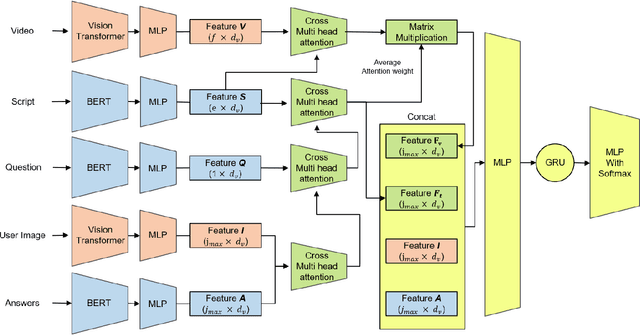
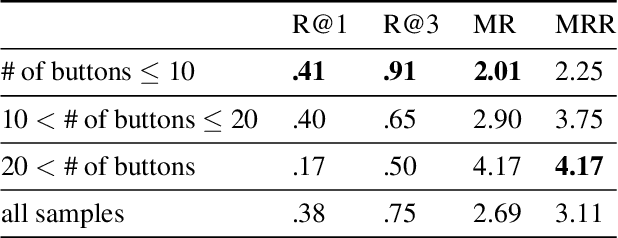
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.
Learning Symbolic Expressions: Mixed-Integer Formulations, Cuts, and Heuristics
Feb 24, 2021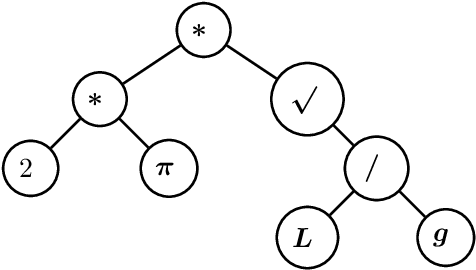
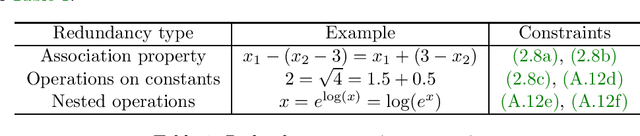
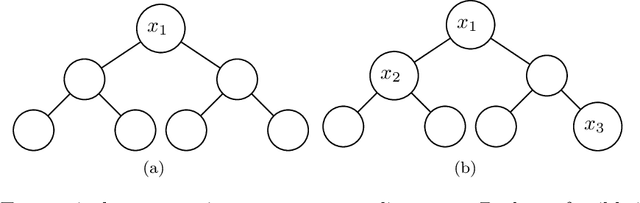
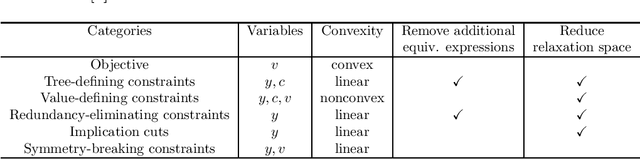
In this paper we consider the problem of learning a regression function without assuming its functional form. This problem is referred to as symbolic regression. An expression tree is typically used to represent a solution function, which is determined by assigning operators and operands to the nodes. The symbolic regression problem can be formulated as a nonconvex mixed-integer nonlinear program (MINLP), where binary variables are used to assign operators and nonlinear expressions are used to propagate data values through nonlinear operators such as square, square root, and exponential. We extend this formulation by adding new cuts that improve the solution of this challenging MINLP. We also propose a heuristic that iteratively builds an expression tree by solving a restricted MINLP. We perform computational experiments and compare our approach with a mixed-integer program-based method and a neural-network-based method from the literature.