 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Language Models: Advancing Cooperation, Coordination, and Adaptation
Jun 11, 2025Modern Large Language Models (LLMs) exhibit impressive zero-shot and few-shot generalization capabilities across complex natural language tasks, enabling their widespread use as virtual assistants for diverse applications such as translation and summarization. Despite being trained solely on large corpora of text without explicit supervision on author intent, LLMs appear to infer the underlying meaning of textual interactions. This raises a fundamental question: can LLMs model and reason about the intentions of others, i.e., do they possess a form of theory of mind? Understanding other's intentions is crucial for effective collaboration, which underpins human societal success and is essential for cooperative interactions among multiple agents, including humans and autonomous systems. In this work, we investigate the theory of mind in LLMs through the lens of cooperative multi-agent reinforcement learning (MARL), where agents learn to collaborate via repeated interactions, mirroring human social reasoning. Our approach aims to enhance artificial agent's ability to adapt and cooperate with both artificial and human partners. By leveraging LLM-based agents capable of natural language interaction, we move towards creating hybrid human-AI systems that can foster seamless collaboration, with broad implications for the future of human-artificial interaction.
Language Model-In-The-Loop: Data Optimal Approach to Learn-To-Recommend Actions in Text Games
Nov 13, 2023



Large Language Models (LLMs) have demonstrated superior performance in language understanding benchmarks. CALM, a popular approach, leverages linguistic priors of LLMs -- GPT-2 -- for action candidate recommendations to improve the performance in text games in Jericho without environment-provided actions. However, CALM adapts GPT-2 with annotated human gameplays and keeps the LLM fixed during the learning of the text based games. In this work, we explore and evaluate updating LLM used for candidate recommendation during the learning of the text based game as well to mitigate the reliance on the human annotated gameplays, which are costly to acquire. We observe that by updating the LLM during learning using carefully selected in-game transitions, we can reduce the dependency on using human annotated game plays for fine-tuning the LLMs. We conducted further analysis to study the transferability of the updated LLMs and observed that transferring in-game trained models to other games did not result in a consistent transfer.
Feature diversity in self-supervised learning
Sep 02, 2022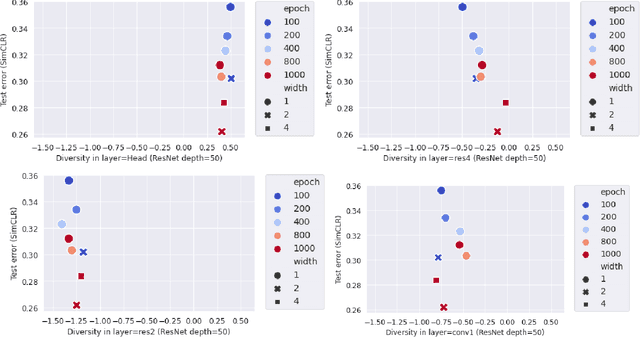
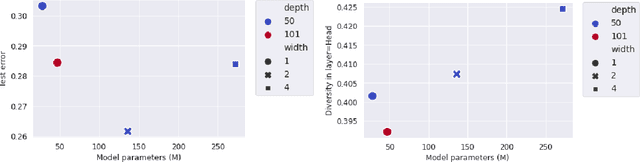
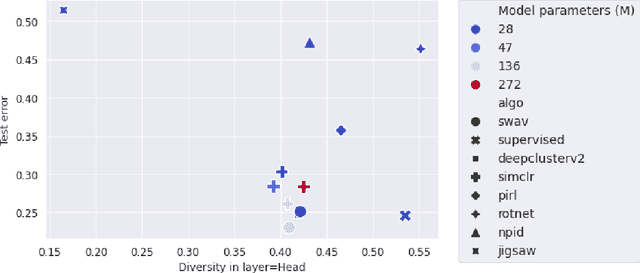
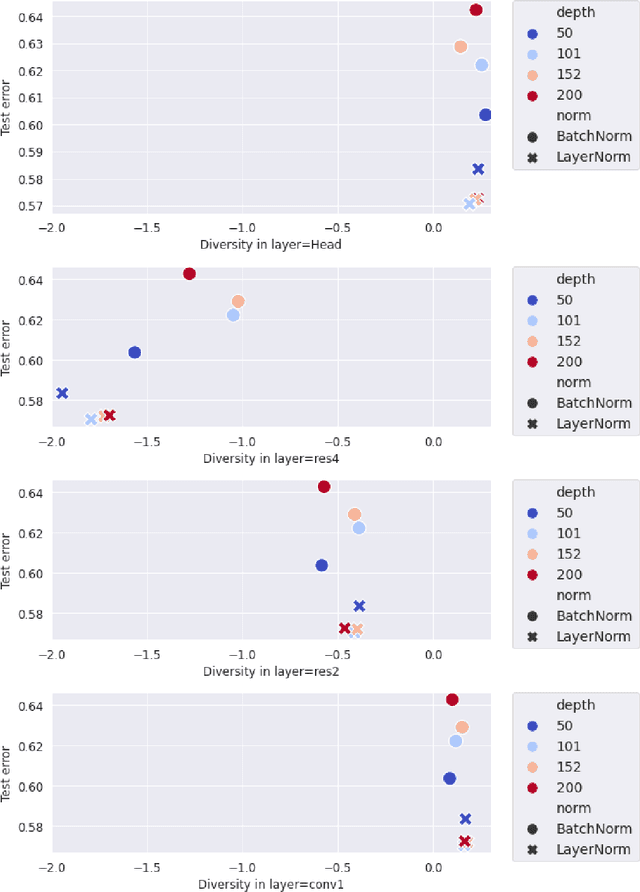
Many studies on scaling laws consider basic factors such as model size, model shape, dataset size, and compute power. These factors are easily tunable and represent the fundamental elements of any machine learning setup. But researchers have also employed more complex factors to estimate the test error and generalization performance with high predictability. These factors are generally specific to the domain or application. For example, feature diversity was primarily used for promoting syn-to-real transfer by Chen et al. (2021). With numerous scaling factors defined in previous works, it would be interesting to investigate how these factors may affect overall generalization performance in the context of self-supervised learning with CNN models. How do individual factors promote generalization, which includes varying depth, width, or the number of training epochs with early stopping? For example, does higher feature diversity result in higher accuracy held in complex settings other than a syn-to-real transfer? How do these factors depend on each other? We found that the last layer is the most diversified throughout the training. However, while the model's test error decreases with increasing epochs, its diversity drops. We also discovered that diversity is directly related to model width.